Eine Umfrage zur Datenauswahl für Sprachmodelle
Dieses Repo ist eine bequeme Auflistung von Arbeiten, die in allen Trainingsstufen für die Datenauswahl für Sprachmodelle relevant sind. Dies soll eine Ressource für die Community sein. Bitte tragen Sie dazu bei, wenn Sie etwas fehlen!
Weitere Informationen zu diesen Arbeiten und mehr finden Sie in unserem Umfragepapier: Eine Umfrage zur Datenauswahl für Sprachmodelle. Von diesem unglaublichen Team: Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Haschimoto, William Yang Wango
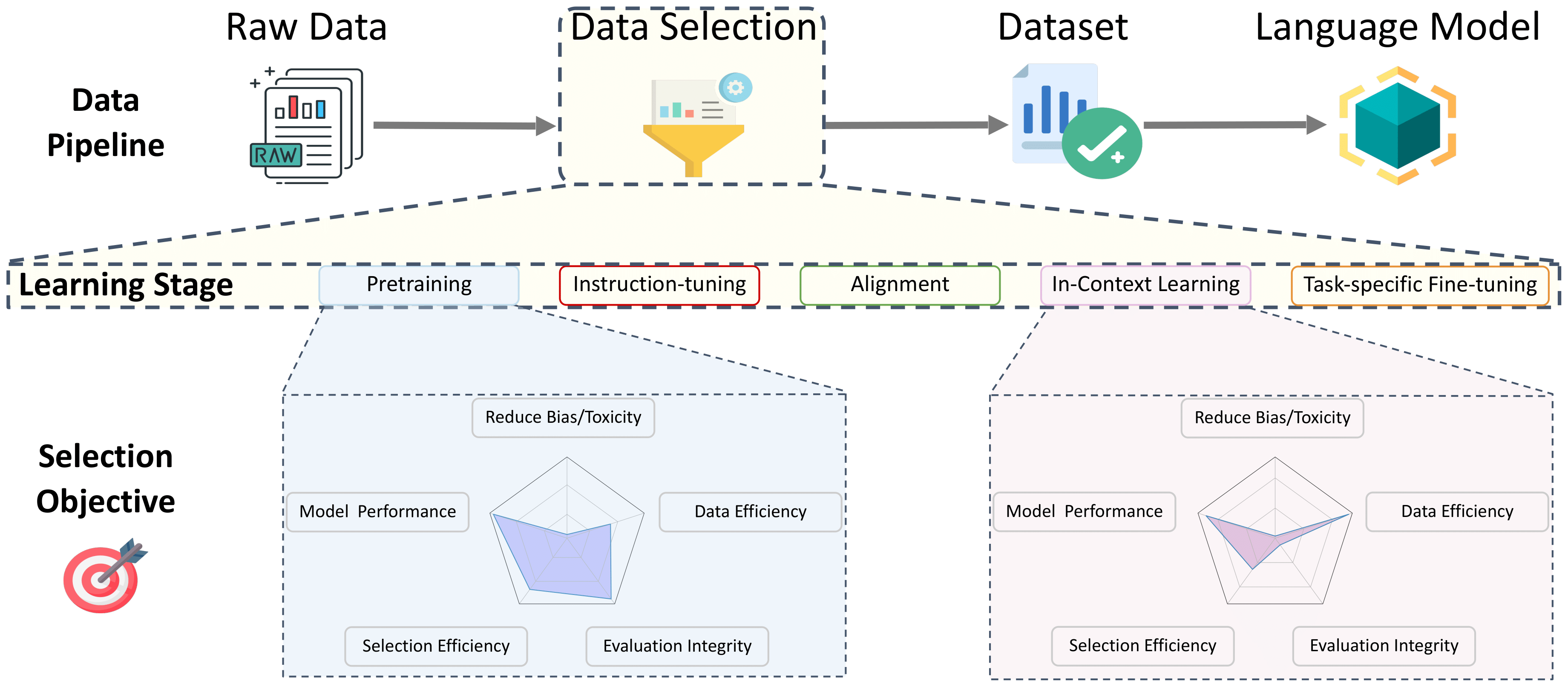
Inhaltsverzeichnis
- Datenauswahl für die Vorbereitung
- Sprachfilterung
- Heuristische Ansätze
- Datenqualität
- Domänenspezifische Auswahl
- Datendingung
- Filterung des toxischen und expliziten Inhalts
- Spezielle Auswahl für mehrsprachige Modelle
- Datenmischung
- Datenauswahl für Anweisungsabbau und Multitasking-Training
- Datenauswahl für die Feinabstimmungsausrichtung der Präferenz
- Datenauswahl für das Lernen in Kontext
- Datenauswahl für aufgabenspezifische Feinabstimmungen
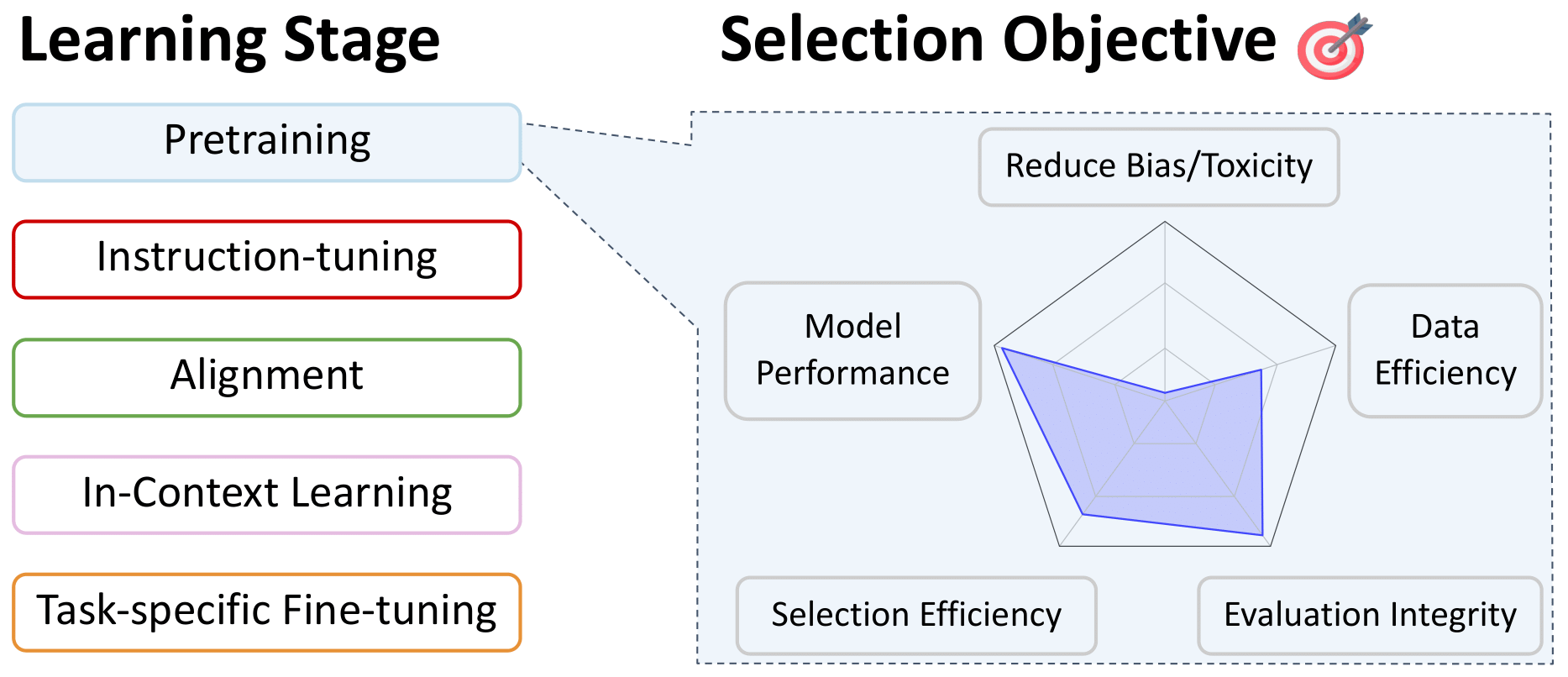
Datenauswahl für die Vorbereitung
Sprachfilterung
Zurück zum Inhaltsverzeichnis
- FastText.zip: Komprimierende Textklassifizierungsmodelle: 2016
Armand Joulin und Edouard Grave und Piotr Bojanowski und Matthijs Douze und Hérve Jégou und Tomas Mikolov
- Lernwortvektoren für 157 Sprachen: 2018
Grab, Edouard und Bojanowski, Piotr und Gupta, Prakhar und Joulin, Armand und Mikolov, Tomas
- Cross-Langual Language Model Vorabbau: 2019
Conneau, Alexis und Lampe, Guillaume
- Erforschung der Grenzen des Transferlernens mit einem einheitlichen Text-zu-Text-Transformator: 2020
Raffel, Colin und Sholeer, Noam und Roberts, Adam ... 3 Hidden ... Zhou, Yanqi und Li, Wei und Liu, Peter J.
- Sprach-ID in freier Wildbahn: Unerwartete Herausforderungen auf dem Weg zu tausendsprachigen Web Text Corpus: 2020
Caswell, Isaac und Breiner, Theresa und Van Esch, Daan und Bapna, Ankur
- Unaufsicht
Conneau, Alexis und Khandelwal, Kartikay und Goyal, Naman ... 4 Hidden ... Ott, Myle und Zettlemoyer, Luke und Stoyanov, Veselin
- CCNET: Extrahieren hochwertiger monolingualer Datensätze aus Webcrawl -Daten: 2020
Wenzek, Guillaume und Lachaux, Marie-Anne und Conneau, Alexis ... 1 versteckt ... Guzm'an, Francisco und Joulin, Armand und Grab, Edouard
- Eine Reproduktion der bidirektionalen LSTM-Modelle von Apple für die Sprachidentifizierung in kurzen Zeichenfolgen: 2021
Toftrup, Mads und Asger Sorensen, Soren und Ciosici, Manuel R. und Zustimmung, IRA
- Bewertung von großsprachigen Modellen, die auf Code trainiert wurden: 2021
Mark Chen und Jerry Tarrek und Heewoo Jun ... 52 Hidden ... Sam McCandlish und Ilya Sutskever und Wojciech Zaremba
- MT5: Ein massiv mehrsprachiger vorgeschriebener Text-zu-Text-Transformator: 2021
Xue, Linie und Konstant, Noah und Roberts, Adam ... 2 Hidden ... Siddhant, Aditya und Barua, Aditya und Raffel, Colin
- Code-Generierung auf Wettbewerbsebene mit Alphacode: 2022
Li, Yujia und Choi, David und Chung, Junyoung ... 20 versteckt ... de Freitas, Nando und Kavukcuoglu, Koray und Vinyals, Oriol
- Palm: Skalierungssprachmodellierung mit Pfaden: 2022
Aakanksha Chowdhery und Sharan Narang und Jacob Devlin ... 61 Hidden ... Jeff Dean und Slav Petrov und Noah Fiedel
- The BigScience Roots Corpus: Ein 1,6 -TB -Verbundwerkstoff mehrsprachiger Datensatz: 2022
Laurenccon, Hugo und Saulnier, Lucile und Wang, Thomas ... 48 Hidden ... Mitchell, Margaret und Luccioni, Sasha Alexandra und Jernite, Yacine
- Schreibsystem und Lautsprechermetadaten für mehr als 2.800 Sprachsorten: 2022
Van Esch, Daan und Lucassen, Tamar und Ruder, Sebastian und Caswell, Isaac und Rivera, Clara
- Fingpt: Große generative Modelle für eine kleine Sprache: 2023
Luukkonen, Risto und Komulainen, Ville und Luoma, Jouni ... 5 Hidden ... Muennighoff, Niklas und Piktus, Aleksandra und andere
- MC^ 2: Ein mehrsprachiger Korpus von Minderheitensprachen in China: 2023
Zhang, Chen und Tao, Mingxu und Huang, Quzhe und Lin, Jiuheng und Chen, Zhibin und Feng, Yansong
- Madlad-400: Ein großer geprüfter Datensatz auf mehrsprachiger und dokumentaler Ebene: 2023
Kudugunta, Sneha und Caswell, Isaac und Zhang, Biao ... 5 Hidden ... Stella, Romi und Bapna, Ankur und andere
- Der RefinedWeb -Datensatz für Falcon LLM: Übertreibende kuratierte Corpora mit Webdaten und nur Webdaten: 2023
Guilherme Penedo und Quentin Malartic und Daniel Hesslow ... 3 Hidden ... Baptiste Pannier und Ebtesam Almazrouei und Julien Launay
- Dolma: Ein offener Korpus von drei Billionen Token für Sprachmodell -Vorbereitungsforschung: 2024
Luca Soldaini und Rodney Kinney und Akshita Bhagia ... 30 versteckt ... Dirk GroenEeld und Jesse Dodge und Kyle Lo
Heuristische Ansätze
Zurück zum Inhaltsverzeichnis
- Erforschung der Grenzen des Transferlernens mit einem einheitlichen Text-zu-Text-Transformator: 2020
Raffel, Colin und Sholeer, Noam und Roberts, Adam ... 3 Hidden ... Zhou, Yanqi und Li, Wei und Liu, Peter J.
- Sprachmodelle sind nur wenige Lernende: 2020
Brown, Tom und Mann, Benjamin und Ryder, Nick ... 25 versteckt ... Radford, Alec und Sutskever, Ilya und Amodei, Dario
- Der Stapel: ein 800 -GB -Datensatz mit vielfältigem Text für die Sprachmodellierung: 2020
Leo Gao und Stella Biderman und Sid Black ... 6 versteckt ... Noa Nabeshima und Shawn Pressers und Connor Leahy
- Bewertung von großsprachigen Modellen, die auf Code trainiert wurden: 2021
Mark Chen und Jerry Tarrek und Heewoo Jun ... 52 Hidden ... Sam McCandlish und Ilya Sutskever und Wojciech Zaremba
- MT5: Ein massiv mehrsprachiger vorgeschriebener Text-zu-Text-Transformator: 2021
Xue, Linie und Konstant, Noah und Roberts, Adam ... 2 Hidden ... Siddhant, Aditya und Barua, Aditya und Raffel, Colin
- Skalierungssprachmodelle: Methoden, Analyse und Erkenntnisse aus dem Training Gopher: 2022
Jack W. Rae und Sebastian Borgeaud und Trevor Cai ... 74 Hidden ... Demis Hassabis und Koray Kavukcuoglu und Geoffrey Irving
- The BigScience Roots Corpus: Ein 1,6 -TB -Verbundwerkstoff mehrsprachiger Datensatz: 2022
Laurenccon, Hugo und Saulnier, Lucile und Wang, Thomas ... 48 Hidden ... Mitchell, Margaret und Luccioni, Sasha Alexandra und Jernite, Yacine
- HTLM: Hyper-Text-Vorverbrauch und Aufforderung von Sprachmodellen: 2022
Armen Aghajanyan und Dmytro Okhonko und Mike Lewis ... 1 versteckt ... Hu Xu und Gargi Ghosh und Luke Zettlemoyer
- LAMA: Offene und effiziente Foundation -Sprachmodelle: 2023
Hugo Touvron und Thibaut Lavril und Gautier Izacard ... 8 versteckt ... Armand Joulin und Edouard Grave und Guillaume Lampe
- Der RefinedWeb -Datensatz für Falcon LLM: Übertreibende kuratierte Corpora mit Webdaten und nur Webdaten: 2023
Guilherme Penedo und Quentin Malartic und Daniel Hesslow ... 3 Hidden ... Baptiste Pannier und Ebtesam Almazrouei und Julien Launay
- Der Stiftungsmodelltransparenzindex: 2023
Bommasani, Rishi und Klyman, Kevin und Longpre, Shayne ... 2 Hidden ... Xiong, Betty und Zhang, Daniel und Liang, Percy
- Dolma: Ein offener Korpus von drei Billionen Token für Sprachmodell -Vorbereitungsforschung: 2024
Luca Soldaini und Rodney Kinney und Akshita Bhagia ... 30 versteckt ... Dirk GroenEeld und Jesse Dodge und Kyle Lo
Datenqualität
Zurück zum Inhaltsverzeichnis
- Kenlm: Schnellere und kleinere Sprachmodellfragen: 2011
Heaff, Kenneth
- FastText.zip: Komprimierende Textklassifizierungsmodelle: 2016
Armand Joulin und Edouard Grave und Piotr Bojanowski und Matthijs Douze und Hérve Jégou und Tomas Mikolov
- Lernwortvektoren für 157 Sprachen: 2018
Grab, Edouard und Bojanowski, Piotr und Gupta, Prakhar und Joulin, Armand und Mikolov, Tomas
- Sprachmodelle sind unbeaufsichtigte Multitasking -Lernende: 2019
Alec Radford und Jeff Wu und Rewon Child sowie David Luan und Dario Amodei und Ilya Sutskever
- Sprachmodelle sind nur wenige Lernende: 2020
Brown, Tom und Mann, Benjamin und Ryder, Nick ... 25 versteckt ... Radford, Alec und Sutskever, Ilya und Amodei, Dario
- Der Stapel: ein 800 -GB -Datensatz mit vielfältigem Text für die Sprachmodellierung: 2020
Leo Gao und Stella Biderman und Sid Black ... 6 versteckt ... Noa Nabeshima und Shawn Pressers und Connor Leahy
- CCNET: Extrahieren hochwertiger monolingualer Datensätze aus Webcrawl -Daten: 2020
Wenzek, Guillaume und Lachaux, Marie-Anne und Conneau, Alexis ... 1 versteckt ... Guzm'an, Francisco und Joulin, Armand und Grab, Edouard
- Entgiftende Sprachmodelle Risiken riskieren marginalisierende Minderheitenstimmen: 2021
Xu, Albert und Pathak, Eshaan und Wallace, Eric und Gururangan, Suchin und Sap, Maarten und Klein, Dan
- Palm: Skalierungssprachmodellierung mit Pfaden: 2022
Aakanksha Chowdhery und Sharan Narang und Jacob Devlin ... 61 Hidden ... Jeff Dean und Slav Petrov und Noah Fiedel
- Skalierungssprachmodelle: Methoden, Analyse und Erkenntnisse aus dem Training Gopher: 2022
Jack W. Rae und Sebastian Borgeaud und Trevor Cai ... 74 Hidden ... Demis Hassabis und Koray Kavukcuoglu und Geoffrey Irving
- Wessen Sprache zählt als hohe Qualität? Messung der Sprachideologien in der Auswahl der Textdaten: 2022
Gururangan, Suchin und Card, Dallas und Dreier, Sarah ... 2 versteckt ... Wang, Zeyu und Zettlemoyer, Luke und Smith, Noah A.
- Glamour: Effiziente Skalierung von Sprachmodellen mit Expertenmischungen: 2022
Du, Nan und Huang, Yanping und Dai, Andrew M ... 21 Hidden ... Wu, Yonghui und Chen, Zhifeng und Cui, Claire
- Ein Anleitungsleitfaden für die Schulung für Schulungsdaten: Messung der Auswirkungen von Datenalter, Domänenabdeckung, Qualität und Toxizität: 2023
Shayne Longpre und Gregory Yauney und Emily Reif ... 5 Hidden ... Kevin Robinson und David Mimno und Daphne Ippolito
- Datenauswahl für Sprachmodelle durch Bedeutung Resampling: 2023
Sang Michael Xie und Shibani Santurkar und Tengyu Ma und Percy Liang
- Der RefinedWeb -Datensatz für Falcon LLM: Übertreibende kuratierte Corpora mit Webdaten und nur Webdaten: 2023
Guilherme Penedo und Quentin Malartic und Daniel Hesslow ... 3 Hidden ... Baptiste Pannier und Ebtesam Almazrouei und Julien Launay
- Dolma: Ein offener Korpus von drei Billionen Token für Sprachmodell -Vorbereitungsforschung: 2024
Luca Soldaini und Rodney Kinney und Akshita Bhagia ... 30 versteckt ... Dirk GroenEeld und Jesse Dodge und Kyle Lo
- Programmieren Sie jedes Beispiel: Heben von Datenqualität vor dem Training wie Experten in Skala: 2024
Fan Zhou und Zengzhi Wang und Qian Liu und Junlong Li und Pengfei Liu
Domänenspezifische Auswahl
Zurück zum Inhaltsverzeichnis
- Textdatenerfassung für domänenspezifische Sprachmodelle: 2006
Sethy, Abhinav und Georgiou, Panayiotis G. und Narayanan, Shrikanth
- Intelligente Auswahl von Sprachmodell -Trainingsdaten: 2010
Moore, Robert C. und Lewis, William
- Zynische Auswahl von Sprachmodelltrainingsdaten: 2017
Amittai Axelrod
- Automatische Dokumentenauswahl für effiziente Encoder -Vorbauer: 2022
Feng, Yukun und Xia, Patrick und Van Durme, Benjamin und Sedoc, Jo ~ ao
- Datenauswahl für Sprachmodelle durch Bedeutung Resampling: 2023
Sang Michael Xie und Shibani Santurkar und Tengyu Ma und Percy Liang
- DSDM: modellbewusste Datensatzauswahl mit Datamodels: 2024
Logan Engstrom und Axel Feldmann und Aleksander Madry
Datendingung
Zurück zum Inhaltsverzeichnis
- Raum-/Zeit-Kompromisse in der Hash-Codierung mit zulässigen Fehlern: 1970
Bloom, Burton H.
- Suffix-Arrays: Eine neue Methode für Online-String-Suche: 1993
Manber, Udi und Myers, Gene
- Über die Ähnlichkeit und Eindämmung von Dokumenten: 1997
Broder, AZ
- Ähnlichkeitsschätzungstechniken aus Rundalgorithmen: 2002
Charikar, Moses S.
- URL-Normalisierung für die Entdeckung von Webseiten: 2009
Agarwal, Amit und Koppula, Hema Swetha und Leela, Krishna P .... 3 Hidden ... Haty, Chittaranjan und Roy, Anirban und Sasturkar, Amit, Amit
- Asynchrone Pipelines zur Verarbeitung großer Korpora für mittelgroße bis niedrige Ressourceninfrastrukturen: 2019
Pedro Javier Ortiz Su'arez und Beno^It Sagot und Laurent Romary
- Sprachmodelle sind nur wenige Lernende: 2020
Brown, Tom und Mann, Benjamin und Ryder, Nick ... 25 versteckt ... Radford, Alec und Sutskever, Ilya und Amodei, Dario
- Der Stapel: ein 800 -GB -Datensatz mit vielfältigem Text für die Sprachmodellierung: 2020
Leo Gao und Stella Biderman und Sid Black ... 6 versteckt ... Noa Nabeshima und Shawn Pressers und Connor Leahy
- CCNET: Extrahieren hochwertiger monolingualer Datensätze aus Webcrawl -Daten: 2020
Wenzek, Guillaume und Lachaux, Marie-Anne und Conneau, Alexis ... 1 versteckt ... Guzm'an, Francisco und Joulin, Armand und Grab, Edouard
- Über neuronale Skalierungsgesetze hinaus: Übertreffen des Stromrechts über Datenbeschneidung: 2022
Ben Sorscher und Robert Geirhos und Shashank Shekhar und Surya Ganguli und Ari S. Morcos
- Deduplicating Trainingsdaten macht Sprachmodelle besser: 2022
Lee, Katherine und Ippolito, Daphne und Nystrom, Andrew ... 1 Hidden ... Eck, Douglas und Callison-Burch, Chris und Carlini, Nicholas
- MTEB: Massive Texteinbettungsbenchmark: 2022
Muennighoff, Niklas und Tazi, Nouamane und Magne, Lo "IC und Reimers, Nils
- Palm: Skalierungssprachmodellierung mit Pfaden: 2022
Aakanksha Chowdhery und Sharan Narang und Jacob Devlin ... 61 Hidden ... Jeff Dean und Slav Petrov und Noah Fiedel
- Skalierungssprachmodelle: Methoden, Analyse und Erkenntnisse aus dem Training Gopher: 2022
Jack W. Rae und Sebastian Borgeaud und Trevor Cai ... 74 Hidden ... Demis Hassabis und Koray Kavukcuoglu und Geoffrey Irving
- SGPT: GPT -Satz Einbettung für semantische Suche: 2022
Muennighoff, Niklas
- The BigScience Roots Corpus: Ein 1,6 -TB -Verbundwerkstoff mehrsprachiger Datensatz: 2022
Laurenccon, Hugo und Saulnier, Lucile und Wang, Thomas ... 48 Hidden ... Mitchell, Margaret und Luccioni, Sasha Alexandra und Jernite, Yacine
- C-Pack: Verpackte Ressourcen zur Fortschritt der allgemeinen chinesischen Einbettung: 2023
Xiao, Shitao und Liu, Zheng und Zhang, Peitianer und Muennighoff, Niklas
- D4: Verbesserung der LLM-Vorbereitung durch Dokumentenentdutz und Diversifizierung: 2023
Kushal Tirumala und Daniel Simig sowie Armen Aghajanyan und Ari S. Morcos
- Große Beinahe-Dekplikation hinter BigCode: 2023
Mou, Chenghao
- Paloma: Ein Benchmark für die Bewertung des Sprachmodells Anpassung: 2023
Ian Magnusson und Akshita Bhagia und Valentin Hofmann ... 10 Hidden ... Noah A. Smith und Kyle Richardson und Jesse Dodge
- Quantifizierung des Auswendiglernens über neuronale Sprachmodelle: 2023
Nicholas Carlini und Daphne Ippolito und Matthew Jagielski sowie Katherine Lee und Florian Tramer und Chiyuan Zhang
- Semgedup: dateneffizient
Abbas, Amro und Tirumala, Kushal und Simig, D'Aniel und Ganguli, Surya und Morcos, Ari s
- Der RefinedWeb -Datensatz für Falcon LLM: Übertreibende kuratierte Corpora mit Webdaten und nur Webdaten: 2023
Guilherme Penedo und Quentin Malartic und Daniel Hesslow ... 3 Hidden ... Baptiste Pannier und Ebtesam Almazrouei und Julien Launay
- Was ist in meinen Big Data ?: 2023
Elazar, Yanai und Bhagia, Akshita und Magnusson, Ian ... 5 versteckt ... Soldaini, Luca und Singh, Sameer und andere
- Dolma: Ein offener Korpus von drei Billionen Token für Sprachmodell -Vorbereitungsforschung: 2024
Luca Soldaini und Rodney Kinney und Akshita Bhagia ... 30 versteckt ... Dirk GroenEeld und Jesse Dodge und Kyle Lo
- Generative Repräsentationsanweisung Tuning: 2024
Muennighoff, Niklas und Su, Hongjin und Wang, Liang ... 2 versteckt ... Yu, Tao und Singh, Amanpreet und Kiela, Douwe
Filterung des toxischen und expliziten Inhalts
Zurück zum Inhaltsverzeichnis
- Erforschung der Grenzen des Transferlernens mit einem einheitlichen Text-zu-Text-Transformator: 2020
Raffel, Colin und Sholeer, Noam und Roberts, Adam ... 3 Hidden ... Zhou, Yanqi und Li, Wei und Liu, Peter J.
- MT5: Ein massiv mehrsprachiger vorgeschriebener Text-zu-Text-Transformator: 2021
Xue, Linie und Konstant, Noah und Roberts, Adam ... 2 Hidden ... Siddhant, Aditya und Barua, Aditya und Raffel, Colin
- Verblüfft von Qualität: Eine Verwirrigkeitsmethode zur Erkennung von erwachsenen und schädlichen Inhalten in mehrsprachigen heterogenen Webdaten: 2022
Tim Jansen und Yangling Tong und Victoria Zevallos und Pedro Ortiz Suarez
- Skalierungssprachmodelle: Methoden, Analyse und Erkenntnisse aus dem Training Gopher: 2022
Jack W. Rae und Sebastian Borgeaud und Trevor Cai ... 74 Hidden ... Demis Hassabis und Koray Kavukcuoglu und Geoffrey Irving
- The BigScience Roots Corpus: Ein 1,6 -TB -Verbundwerkstoff mehrsprachiger Datensatz: 2022
Laurenccon, Hugo und Saulnier, Lucile und Wang, Thomas ... 48 Hidden ... Mitchell, Margaret und Luccioni, Sasha Alexandra und Jernite, Yacine
- Wessen Sprache zählt als hohe Qualität? Messung der Sprachideologien in der Auswahl der Textdaten: 2022
Gururangan, Suchin und Card, Dallas und Dreier, Sarah ... 2 versteckt ... Wang, Zeyu und Zettlemoyer, Luke und Smith, Noah A.
- Ein Anleitungsleitfaden für die Schulung für Schulungsdaten: Messung der Auswirkungen von Datenalter, Domänenabdeckung, Qualität und Toxizität: 2023
Shayne Longpre und Gregory Yauney und Emily Reif ... 5 Hidden ... Kevin Robinson und David Mimno und Daphne Ippolito
- KI Image Training Dataset enthält für sexuelle Missbrauch von Kindern: 2023
David, Emilia
- Erkennen personenbezogener Daten in der Schulung Korpora: Eine Analyse: 2023
Subramani, Nishant und Luccioni, Sasha und Dodge, Jesse und Mitchell, Margaret
- GPT-4-Technischer Bericht: 2023
Openai und: und Josh Achiam ... 276 Hidden ... Juntang Zhuang und William Zhuk und Barret Zoph
- Santacoder: Greifen Sie nicht nach den Sternen !: 2023
Allal, Loubna Ben und Li, Raymond und Kocetkov, Denis ... 5 versteckt ... Gu, Alex und Dey, Manan und andere
- Der RefinedWeb -Datensatz für Falcon LLM: Übertreibende kuratierte Corpora mit Webdaten und nur Webdaten: 2023
Guilherme Penedo und Quentin Malartic und Daniel Hesslow ... 3 Hidden ... Baptiste Pannier und Ebtesam Almazrouei und Julien Launay
- Der Stiftungsmodelltransparenzindex: 2023
Bommasani, Rishi und Klyman, Kevin und Longpre, Shayne ... 2 Hidden ... Xiong, Betty und Zhang, Daniel und Liang, Percy
- Was ist in meinen Big Data ?: 2023
Elazar, Yanai und Bhagia, Akshita und Magnusson, Ian ... 5 versteckt ... Soldaini, Luca und Singh, Sameer und andere
- Dolma: Ein offener Korpus von drei Billionen Token für Sprachmodell -Vorbereitungsforschung: 2024
Luca Soldaini und Rodney Kinney und Akshita Bhagia ... 30 versteckt ... Dirk GroenEeld und Jesse Dodge und Kyle Lo
- Olmo: Beschleunigung der Wissenschaft der Sprachmodelle: 2024
Groeneveld, Dirk und Beltagy, IZ und Walsh, Pete ... 5 Hidden ... Magnusson, Ian und Wang, Yizhong und andere
Spezielle Auswahl für mehrsprachige Modelle
Zurück zum Inhaltsverzeichnis
- Blüte: Ein 176B-Parameter Open-Access mehrsprachiger Sprachmodell: 2022
Workshop, BigScience und Scao, Teven Le und Fan, Angela ... 5 Hidden ... Luccioni, Alexandra Sasha und Yvon, Franccois und andere
- Qualität auf einen Blick: Eine Prüfung von webkrawierten mehrsprachigen Datensätzen: 2022
Kreutzer, Julia und Caswell, Isaac und Wang, Lisa ... 46 Hidden ... Ahia, Oghenefego und Agrawal, Sweta und Adeyemi, Mofetoluwa
- The BigScience Roots Corpus: Ein 1,6 -TB -Verbundwerkstoff mehrsprachiger Datensatz: 2022
Laurenccon, Hugo und Saulnier, Lucile und Wang, Thomas ... 48 Hidden ... Mitchell, Margaret und Luccioni, Sasha Alexandra und Jernite, Yacine
- Welches Sprachmodell zu trainieren, wenn Sie eine Million GPU -Stunden haben ?: 2022
Scao, Teven Le und Wang, Thomas und Hesslow, Daniel ... 5 Hidden ... Muennighoff, Niklas und Phang, Jason und andere
- Madlad-400: Ein großer geprüfter Datensatz auf mehrsprachiger und dokumentaler Ebene: 2023
Kudugunta, Sneha und Caswell, Isaac und Zhang, Biao ... 5 Hidden ... Stella, Romi und Bapna, Ankur und andere
- Skalierung mehrsprachiger Sprachmodelle unter eingeschränkten Daten: 2023
Scao, Teven Le
- AYA-Datensatz: Eine Open-Access-Sammlung für mehrsprachige Anweisungen: 2024
Shivalika Singh und Freddie Vargus und Daniel Dsouza ... 27 versteckt ... Ahmet Üstün und Marzieh Fadaee und Sara Hooker
Datenmischung
Zurück zum Inhaltsverzeichnis
- Das nicht stochastische Multiarmed -Banditenproblem: 2002
Auer, Peter und Cesa-Bianchi, Nicol`o und Freund, Yoav und Schapire, Robert E.
- Verteilungsverteidiger Sprachmodellierung: 2019
Oren, Yonatan und Sagawa, Shiori und Hashimoto, Tatsunori B. und Liang, Percy
- Verteilend robuste neuronale Netze: 2020
Shiori Sagawa und Pang Wei Koh und Tatsunori B. Hashimoto und Percy Liang
- Erforschung der Grenzen des Transferlernens mit einem einheitlichen Text-zu-Text-Transformator: 2020
Raffel, Colin und Sholeer, Noam und Roberts, Adam ... 3 Hidden ... Zhou, Yanqi und Li, Wei und Liu, Peter J.
- Der Stapel: ein 800 -GB -Datensatz mit vielfältigem Text für die Sprachmodellierung: 2020
Leo Gao und Stella Biderman und Sid Black ... 6 versteckt ... Noa Nabeshima und Shawn Pressers und Connor Leahy
- Skalierungssprachmodelle: Methoden, Analyse und Erkenntnisse aus dem Training Gopher: 2022
Jack W. Rae und Sebastian Borgeaud und Trevor Cai ... 74 Hidden ... Demis Hassabis und Koray Kavukcuoglu und Geoffrey Irving
- Glamour: Effiziente Skalierung von Sprachmodellen mit Expertenmischungen: 2022
Du, Nan und Huang, Yanping und Dai, Andrew M ... 21 Hidden ... Wu, Yonghui und Chen, Zhifeng und Cui, Claire
- Die bringliche Überwachung verbessert Großsprachenmodelle vor dem Training: 2023
Andrea Schioppa und Xavier Garcia und Orhan Firat
- [DOGE: Domain -Wiedergewicht mit der Verallgemeinerungsschätzung] (https://arxiv.org/abs/arxiv Preprint): 2023
Simin Fan und Matteo Pagliardini und Martin Jaggi
- Doremi: Die Optimierung von Datenmischungen beschleunigt das Sprachmodell Vorbau: 2023
Sang Michael Xie und Hieu Pham und Xuanyi Dong ... 4 Hidden ... Quoc gegen Le und Tengyu Ma und Adams Wei Yu
- Effiziente Online-Datenmischung für das Sprachmodell vor dem Training: 2023
Alon Albalak und Liangming Pan und Colin Raffel und William Yang Wang
- LAMA: Offene und effiziente Foundation -Sprachmodelle: 2023
Hugo Touvron und Thibaut Lavril und Gautier Izacard ... 8 versteckt ... Armand Joulin und Edouard Grave und Guillaume Lampe
- Pythien: Eine Suite zur Analyse von großsprachigen Modellen in Training und Skalierung: 2023
Biderman, Stella und Schoelkopf, Hailey und Anthony, Quentin Gregory ... 7 Hidden ... Skowron, Aviya und Sutawika, Lintang und Van der Wal, Oskar
- Skalierung von datenbeschränkten Sprachmodellen: 2023
Niklas Muennighoff und Alexander M Rush und Boaz Barak ... 3 Hidden ... Sampo Pyysalo und Thomas Wolf und Colin Raffel
- Scherte Lama: Beschleunigen des Sprachmodells vor dem Training über strukturiertes Beschneiden: 2023
Mengzhou Xia und Tianyu Gao und Zhiyuan Zeng und Danqi Chen
- Geschicklichkeit! Ein datengesteuerter Skills-Rahmen für Verständnis und Trainingssprachmodelle: 2023
Mayee F. Chen und Nicholas Roberts und Kush Bhatia ... 1 versteckt ... CE Zhang und Frederic Sala und Christopher Ré
Datenauswahl für Anweisungsabbau und Multitasking-Training
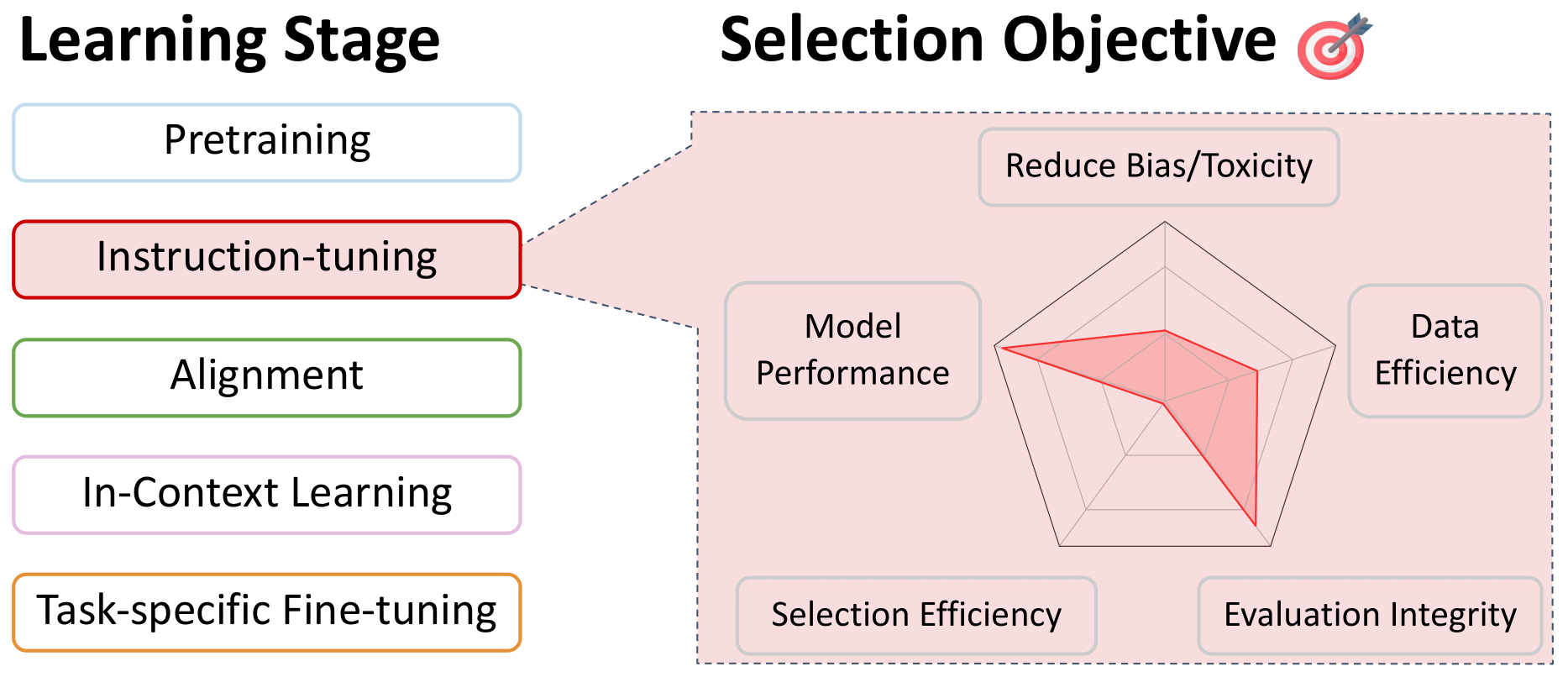
Zurück zum Inhaltsverzeichnis
- Die natürliche Sprache Decathlon: Multitasking Lernen als Frage Beantwortung: 2018
McCann, Bryan und Keskar, Nitish Shirish und Xiong, Caiming und Socker, Richard
- Einheitliche Fragenbeantwortung, Textklassifizierung und Regression über Span -Extraktion: 2019
Keskar, Nitish Shirish und McCann, Bryan und Xiong, Caiming und Socker, Richard
- Multitasking Deep Neural Networks für natürliches Sprachverständnis: 2019
Liu, Xiaodong und er, Pengcheng und Chen, Weizhu und Gao, Jianfeng
- UnifiedQA: Überqueren der Formatgrenzen mit einem einzigen QA -System: 2020
Khashabi, Daniel und Min, Sewon und Khot, Tushar ... 1 versteckt ... Tafjord, Oyvind und Clark, Peter und Hajishirzi, Hannaneh
- Erforschung der Grenzen des Transferlernens mit einem einheitlichen Text-zu-Text-Transformator: 2020
Raffel, Colin und Sholeer, Noam und Roberts, Adam ... 3 Hidden ... Zhou, Yanqi und Li, Wei und Liu, Peter J.
- Muppet: Massive Multitasking-Darstellungen mit Pre-Finetuning: 2021
Aghajanyan, Armen und Gupta, Anchit und Shrivastava, Akshat und Chen, Xilun und Zettlemoyer, Luke und Gupta, Sonal
- Figuned-Sprachmodelle sind Null-Shot-Lernende: 2021
Wei, Jason und Bosma, Maarten und Zhao, Vincent Y .... 3 Hidden ... du, Nan und Dai, Andrew M. und Le, Quoc V.
- Durchlaufverallgemeinerung über natürliche Sprache Crowdsourcing-Anweisungen: 2021
Mishra, Swaroop und Khashabi, Daniel und Baral, Chitta und Hajishirzi, Hannaneh
- NL-Augmenter: Ein Rahmen für die aufgabenempfindliche Vergrößerung der natürlichen Sprache: 2021
Dhole, Kaustubh D und Gangal, Varun und Gehrmann, Sebastian ... 5 Hidden ... Shrivastava, Ashish und Tan, Samson und andere
- Ext5: Auf dem Weg zu extremer Multitasking-Skalierung zum Transferlernen: 2021
Aribandi, Vamsi und Tay, Yi und Schuster, Tal ... 5 Hidden ... Bahri, Dara und Ni, Jianmo und andere
- Super-naturalinstructions: Verallgemeinerung durch deklarative Anweisungen zu über 1600 NLP-Aufgaben: 2022
Wang, Yizhong und Mishra, Swaroop und Alipoormolabashi, Pegah ... 29 Hidden ... Patro, Sumanta und Dixit, Tanay und Shen, Xudong
- Skalierung der Sprachmodelle mit Anweisungsfinetune: 2022
Chung, Hyung Won und Hou, Le und Longpre, Shayne ... 5 versteckt ... Dehghani, Mostafa und Brahma, Siddhartha und andere
- Blüte+ 1: Hinzufügen von Sprachunterstützung zum Blühen für Null-Shot-Aufforderung: 2022
Yong, Zheng-Xin und Schoelkopf, Hailey und Muennighoff, Niklas ... 5 Hidden ... Kasai, Jungo und Baruwa, Ahmed und andere
- OPT-IML: Skalierung des Sprachmodell-Anweisung Meta-Lernen durch die Verallgemeinerungslinie: 2022
Srinivasan Iyer und Xi Victoria Lin und Ramakanth Pasunuru ... 12 versteckt ... Asli Celikyilmaz und Luke Zettlemoyer und Ves Stoyanov
- Metaicl: Lernen im Kontext lernen: 2022
Min, Sewon und Lewis, Mike und Zettlemoyer, Luke und Hajishirzi, Hannaneh
- Unnatürliche Anweisungen: Stimmen von Sprachmodellen mit (fast) ohne menschliche Arbeit: 2022
Honovich oder und Scialom, Thomas und Levy, Omer und Schick, Timo
- Kreuzlingsverallgemeinerung durch Multitasking -Finetuning: 2022
Muennighoff, Niklas und Wang, Thomas und Sutawika, Lintang ... 5 Hidden ... Yong, Zheng-Xin und Schoelkopf, Hailey und andere
- Multitasking zum Training ermöglicht die Verallgemeinerung der Aufgabe von Null-Shot: 2022
Victor Sanh und Albert Webson und Colin Raffel ... 34 Hidden ... Leo Gao und Thomas Wolf und Alexander M. Rush
- Prometheus: Induzieren feinkörniger Bewertungsfähigkeit in Sprachmodellen: 2023
Kim, Seungone und Shin, Jamin und Cho, Yejin ... 5 versteckt ... Kim, Sungdong und Thorne, James und andere
- Slimorca: Ein offener Datensatz von GPT-4 Augmented Flan Argumenting Traces mit Überprüfung: 2023
Flügel Lian und Guan Wang und Bleys Goodson ... 1 versteckt ... Austin Cook und Chanvichet -Spong und "Teknium"
- Stiehlt KI -Kunst von Künstlern ?: 2023
Chayka, Kyle
- Paul Tremblay, Mona Awad gegen Openai, Inc., et al.: 2023
Saveri, Joseph R. und Zirpoli, Cadio und Young, Christopher KL und McMahon, Kathleen J.
- Machen Sie Großsprachmodelle zu besseren Datenerstellern: 2023
Lee, Dong-ho und Pujara, Jay und Sewak, Mohit und White, Ryen und Jauhar, Sujay
- Die FLAN -Sammlung: Entwerfen von Daten und Methoden für die effektive Anweisungsabstimmung: 2023
Shayne Longpre und Le Hou und Tu Vu ... 5 versteckt ... Barret Zoph und Jason Wei und Adam Roberts
- WizardLM: Ermächtigung großer Sprachmodelle, komplexe Anweisungen zu befolgen: 2023
Xu, Can und Sun, Qingfeng und Zheng, Kai ... 2 Hidden ... Feng, Jiazhan und Tao, Chongjang und Jiang, Daxin
- Lima: Weniger ist mehr für die Ausrichtung: 2023
Chunting Zhou und Pengfei Liu und Puxin Xu ... 9 Hidden ... Mike Lewis und Luke Zettlemoyer und Omer Levy
- Kamele in einem sich verändernden Klima: Verbesserung der LM -Anpassung mit Tulu 2: 2023
Hamish Ivison und Yizhong Wang und Valentina Pyatkin ... 5 versteckt ... Noah A. Smith und Iz Beltagy und Hannaneh Hajishirzi
- Selbsteinbau: Sprachmodelle mit selbst erzeugten Anweisungen ausrichten: 2023
Wang, Yizhong und Kordi, Yeganeh und Mishra, Swaroop ... 1 versteckt ... Smith, Noah A. und Khashabi, Daniel und Hajishirzi, Hannaneh
- Was macht gute Daten für die Ausrichtung aus? Eine umfassende Untersuchung der automatischen Datenauswahl in der Anweisungsabstimmung: 2023
Liu, Wei und Zeng, Weihao und er, Keqing und Jiang, Yong und er, Junxian
- Anweisungsabstimmung für große Sprachmodelle: Eine Umfrage: 2023
Shengyu Zhang und Linfeng Dong und Xiaoya Li ... 5 Hidden ... Tianwei Zhang und Fei Wu und Guoyin Wang
- Stanford Alpaka: Ein Anweisungsverfolgungs-Lama-Modell: 2023
Rohan Taori und Ishaan Gulrajani und Tianyi Zhang ... 2 versteckt ... Carlos Guestrin und Percy Liang und Tatsunori B. Hashimoto
- Wie weit können Kamele gehen? Untersuchung des Standes des Unterrichts auf offene Ressourcen: 2023
Yizhong Wang und Hamish Ivison und Pradeep Dassigi ... 5 versteckt ... Noah A. Smith und Iz Beltagy und Hannaneh Hajishirzi
- OpenSectionant Conversations-Demokratisierende Großsprachenmodellausrichtung: 2023
K "OPF, Andreas und Kilcher, Yannic und von R" Utte, Dimitri ... 5 Hidden ... Stanley, Oliver und Nagyfi, Rich'ard und andere
- Octopack: Anweisungscode große Sprachmodelle: 2023
Niklas Muennighoff und Qian Liu und Armel Zebaze ... 4 versteckt ... Xiangru Tang und Leandro von Werra und Shayne Longpre
- Selbst: Sprachgetriebene Selbstevolution für Großsprachenmodell: 2023
Lu, Jianqiao und Zhong, Wanjun und Huang, Wenyong ... 3 versteckt ... Wang, Weichao und Shang, Lifeng und Liu, Qun
- Die FLAN -Sammlung: Entwerfen von Daten und Methoden für die effektive Anweisungsabstimmung: 2023
Longpre, Shayne und Hou, Le und Vu, Tu ... 5 Hidden ... Zoph, Barret und Wei, Jason und Roberts, Adam
- #Instag: Anleitungs-Tagging zur Analyse der beaufsichtigten Feinabstimmung von großsprachigen Modellen: 2023
Keming Lu und Hongyi Yuan und Zheng Yuan ... 2 Hidden ... Chuanqi Tan und Chang Zhou und Jingren Zhou
- Anleitungsmining: Wenn Data Mining auf ein großes Sprachmodell -Finetuning trifft: 2023
Yihan Cao und Yanbin Kang und Chi Wang und Lichao Sun
- Aktive Anweisungsabstimmung: Verbesserung der Verallgemeinerung der Kreuzung durch Training auf schnellen sensiblen Aufgaben: 2023
Po-Nien Kung und Fan Yin und Di Wu und Kai-Wei Chang und Nanyun Peng
- Die Datenproduktionsinitiative: Eine große Prüfung der Datensatzlizenzierung und -zuordnung in AI: 2023
Longpre, Shayne und Mahari, Robert und Chen, Anthony ... 5 versteckt ... Kabbara, Jad und Perisetla, Kartik und andere
- AYA-Datensatz: Eine Open-Access-Sammlung für mehrsprachige Anweisungen: 2024
Shivalika Singh und Freddie Vargus und Daniel Dsouza ... 27 versteckt ... Ahmet Üstün und Marzieh Fadaee und Sara Hooker
- Astraios: Parameter-effizientes Anweisungscode Großsprachen Modelle: 2024
Zhuo, Terry Yue und Zebaze, Armel und Suppattarachai, Nitchakarn ... 1 versteckt ... de Vries, Schaden und Liu, Qian und Muennighoff, Niklas
- AYA-Modell: Ein Befehlsfunduned Open-Access mehrsprachiger Sprachmodell: 2024
"Ust" Un, Ahmet und Aryabumi, Viraat und Yong, Zheng-Xin ... 5 Hidden ... ooi, Hui-Lee und Kayid, AMR und andere
- Kleinere Sprachmodelle können Trainingsdaten für Anweisungen für größere Sprachmodelle auswählen: 2024
Dheeraj Mekala und Alex Nguyen und Jingbo Shang
- Automatisierte Datenkuration für robustes Sprachmodell Feinabstimmung: 2024
Jihai Chen und Jonas Müller
Datenauswahl für die Feinabstimmung: Ausrichtung
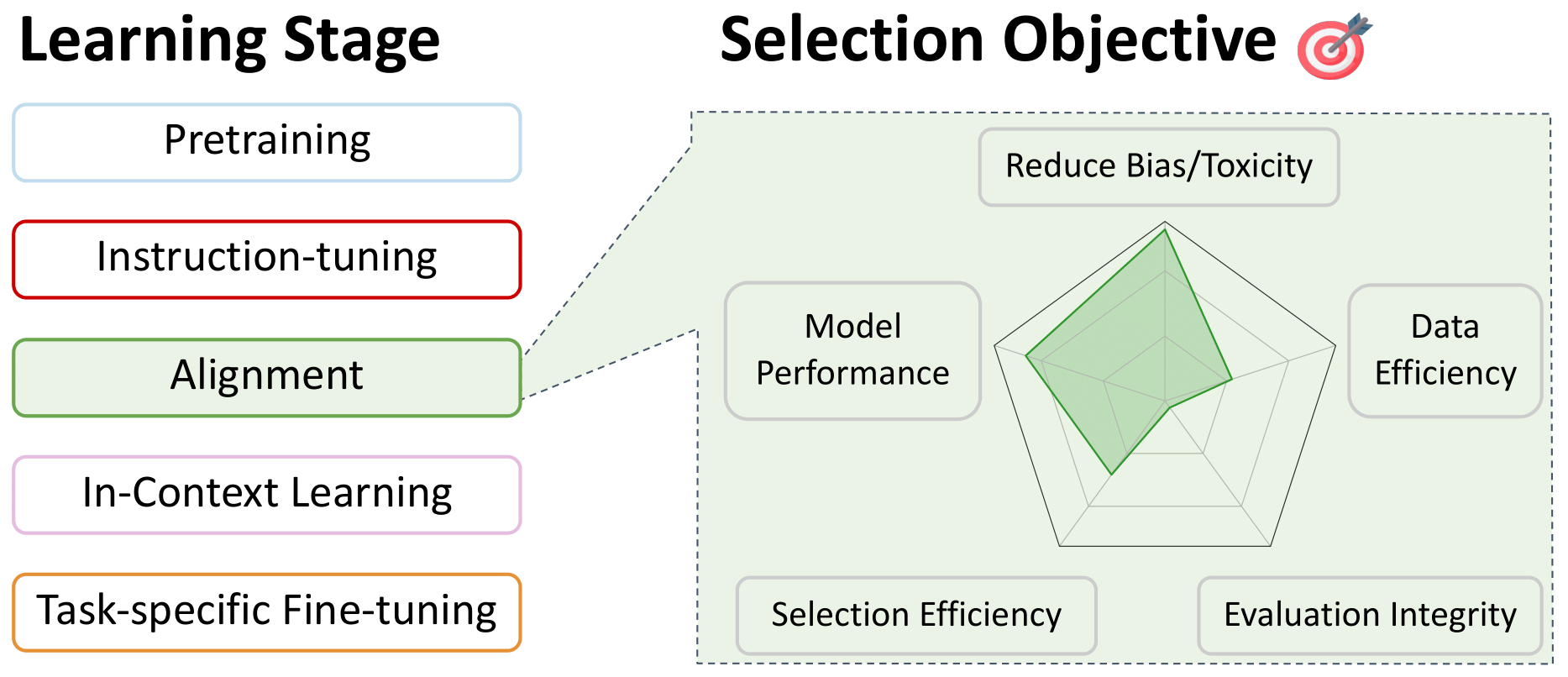
Zurück zum Inhaltsverzeichnis
- WebGPT: Browser-stützte Frage-Beantwortung mit menschlichem Feedback: 2021
Nakano, Reiichiro und Hilton, Jacob und Balaji, Suchir ... 5 Hidden ... Kosaraju, Vineet und Saunders, William und andere
- Training eines hilfsbereiten und harmlosen Assistenten mit Verstärkungslernen aus menschlichem Feedback: 2022
Bai, Yuntao und Jones, Andy und Ndousse, Kamal ... 5 versteckt ... Ganguli, Deep und Henighan, Tom und andere
- Verständnis der Datensatzschwierigkeit mit $ mathCalv $ -Verweicher Informationen: 2022
Ethayarajh, Kawin und Choi, Yejin und Swayamdipta, Swabha
- Konstitutionelle KI: Harmlosigkeit durch KI -Feedback: 2022
Bai, Yuntao und Kadavath, Saurav und Kundu, Sandipan ... 5 Hidden ... Mirhoseeini, Azalia und McKinnon, Cameron und andere
- Prometheus: Induzieren feinkörniger Bewertungsfähigkeit in Sprachmodellen: 2023
Kim, Seungone und Shin, Jamin und Cho, Yejin ... 5 versteckt ... Kim, Sungdong und Thorne, James und andere
- Notus: 2023
Alvaro Bartolome und Gabriel Martin und Daniel Vila
- Ultrafeedback: Steigern Sie Sprachmodelle mit hochwertigem Feedback: 2023
Ganqu Cui and Lifan Yuan and Ning Ding... 3 hidden ... Guotong Xie and Zhiyuan Liu and Maosong Sun
- Exploration with Principles for Diverse AI Supervision: 2023
Liu, Hao and Zaharia, Matei and Abbeel, Pieter
- Wizardlm: Empowering large language models to follow complex instructions: 2023
Xu, Can and Sun, Qingfeng and Zheng, Kai... 2 hidden ... Feng, Jiazhan and Tao, Chongyang and Jiang, Daxin
- LIMA: Less Is More for Alignment: 2023
Chunting Zhou and Pengfei Liu and Puxin Xu... 9 hidden ... Mike Lewis and Luke Zettlemoyer and Omer Levy
- Shepherd: A Critic for Language Model Generation: 2023
Tianlu Wang and Ping Yu and Xiaoqing Ellen Tan... 4 hidden ... Luke Zettlemoyer and Maryam Fazel-Zarandi and Asli Celikyilmaz
- No Robots: 2023
Nazneen Rajani and Lewis Tunstall and Edward Beeching and Nathan Lambert and Alexander M. Rush and Thomas Wolf
- Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF: 2023
Zhu, Banghua and Frick, Evan and Wu, Tianhao and Zhu, Hanlin and Jiao, Jiantao
- Scaling laws for reward model overoptimization: 2023
Gao, Leo and Schulman, John and Hilton, Jacob
- SALMON: Self-Alignment with Principle-Following Reward Models: 2023
Zhiqing Sun and Yikang Shen and Hongxin Zhang... 2 hidden ... David Cox and Yiming Yang and Chuang Gan
- Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback: 2023
Stephen Casper and Xander Davies and Claudia Shi... 26 hidden ... David Krueger and Dorsa Sadigh and Dylan Hadfield-Menell
- Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2: 2023
Hamish Ivison and Yizhong Wang and Valentina Pyatkin... 5 hidden ... Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi
- Llama 2: Open Foundation and Fine-Tuned Chat Models: 2023
Hugo Touvron and Louis Martin and Kevin Stone... 62 hidden ... Robert Stojnic and Sergey Edunov and Thomas Scialom
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning: 2023
Liu, Wei and Zeng, Weihao and He, Keqing and Jiang, Yong and He, Junxian
- HuggingFace H4 Stack Exchange Preference Dataset: 2023
Lambert, Nathan and Tunstall, Lewis and Rajani, Nazneen and Thrush, Tristan
- Textbooks Are All You Need: 2023
Gunasekar, Suriya and Zhang, Yi and Aneja, Jyoti... 5 hidden ... de Rosa, Gustavo and Saarikivi, Olli and others
- Quality-Diversity through AI Feedback: 2023
Herbie Bradley and Andrew Dai and Hannah Teufel... 4 hidden ... Kenneth Stanley and Grégory Schott and Joel Lehman
- Direct preference optimization: Your language model is secretly a reward model: 2023
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D and Finn, Chelsea
- Scaling relationship on learning mathematical reasoning with large language models: 2023
Yuan, Zheng and Yuan, Hongyi and Li, Chengpeng and Dong, Guanting and Tan, Chuanqi and Zhou, Chang
- The History and Risks of Reinforcement Learning and Human Feedback: 2023
Lambert, Nathan and Gilbert, Thomas Krendl and Zick, Tom
- Zephyr: Direct distillation of lm alignment: 2023
Tunstall, Lewis and Beeching, Edward and Lambert, Nathan... 5 hidden ... Fourrier, Cl'ementine and Habib, Nathan and others
- Perils of Self-Feedback: Self-Bias Amplifies in Large Language Models: 2024
Wenda Xu and Guanglei Zhu and Xuandong Zhao and Liangming Pan and Lei Li and William Yang Wang
- Suppressing Pink Elephants with Direct Principle Feedback: 2024
Louis Castricato and Nathan Lile and Suraj Anand and Hailey Schoelkopf and Siddharth Verma and Stella Biderman
- West-of-N: Synthetic Preference Generation for Improved Reward Modeling: 2024
Alizée Pace and Jonathan Mallinson and Eric Malmi and Sebastian Krause and Aliaksei Severyn
- Statistical Rejection Sampling Improves Preference Optimization: 2024
Liu, Tianqi and Zhao, Yao and Joshi, Rishabh... 1 hidden ... Saleh, Mohammad and Liu, Peter J and Liu, Jialu
- Self-play fine-tuning converts weak language models to strong language models: 2024
Chen, Zixiang and Deng, Yihe and Yuan, Huizhuo and Ji, Kaixuan and Gu, Quanquan
- Self-Rewarding Language Models: 2024
Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston
- Theoretical guarantees on the best-of-n alignment policy: 2024
Beirami, Ahmad and Agarwal, Alekh and Berant, Jonathan... 1 hidden ... Eisenstein, Jacob and Nagpal, Chirag and Suresh, Ananda Theertha
- KTO: Model Alignment as Prospect Theoretic Optimization: 2024
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe
Data Selection for In-Context Learning
Back to Table of Contents
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks: 2019
Reimers, Nils and Gurevych, Iryna
- Language Models are Few-Shot Learners: 2020
Brown, Tom and Mann, Benjamin and Ryder, Nick... 25 hidden ... Radford, Alec and Sutskever, Ilya and Amodei, Dario
- True Few-Shot Learning with Language Models: 2021
Ethan Perez and Douwe Kiela and Kyunghyun Cho
- Active Example Selection for In-Context Learning: 2022
Zhang, Yiming and Feng, Shi and Tan, Chenhao
- Careful Data Curation Stabilizes In-context Learning: 2022
Chang, Ting-Yun and Jia, Robin
- Learning To Retrieve Prompts for In-Context Learning: 2022
Rubin, Ohad and Herzig, Jonathan and Berant, Jonathan
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity: 2022
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus
- What Makes Good In-Context Examples for GPT-3?: 2022
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu
- MetaICL: Learning to Learn In Context: 2022
Min, Sewon and Lewis, Mike and Zettlemoyer, Luke and Hajishirzi, Hannaneh
- Unified Demonstration Retriever for In-Context Learning: 2023
Li, Xiaonan and Lv, Kai and Yan, Hang... 3 hidden ... Xie, Guotong and Wang, Xiaoling and Qiu, Xipeng
- Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection: 2023
Mavromatis, Costas and Srinivasan, Balasubramaniam and Shen, Zhengyuan... 1 hidden ... Rangwala, Huzefa and Faloutsos, Christos and Karypis, George
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning: 2023
Xinyi Wang and Wanrong Zhu and Michael Saxon and Mark Steyvers and William Yang Wang
- Selective Annotation Makes Language Models Better Few-Shot Learners: 2023
Hongjin SU and Jungo Kasai and Chen Henry Wu... 5 hidden ... Luke Zettlemoyer and Noah A. Smith and Tao Yu
- In-context Example Selection with Influences: 2023
Nguyen, Tai and Wong, Eric
- Coverage-based Example Selection for In-Context Learning: 2023
Gupta, Shivanshu and Singh, Sameer and Gardner, Matt
- Compositional exemplars for in-context learning: 2023
Ye, Jiacheng and Wu, Zhiyong and Feng, Jiangtao and Yu, Tao and Kong, Lingpeng
- Take one step at a time to know incremental utility of demonstration: An analysis on reranking for few-shot in-context learning: 2023
Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- Ambiguity-aware in-context learning with large language models: 2023
Gao, Lingyu and Chaudhary, Aditi and Srinivasan, Krishna and Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- IDEAL: Influence-Driven Selective Annotations Empower In-Context Learners in Large Language Models: 2023
Zhang, Shaokun and Xia, Xiaobo and Wang, Zhaoqing... 1 hidden ... Liu, Jiale and Wu, Qingyun and Liu, Tongliang
- ScatterShot: Interactive In-context Example Curation for Text Transformation: 2023
Wu, Sherry and Shen, Hua and Weld, Daniel S and Heer, Jeffrey and Ribeiro, Marco Tulio
- Diverse Demonstrations Improve In-context Compositional Generalization: 2023
Levy, Itay and Bogin, Ben and Berant, Jonathan
- Finding supporting examples for in-context learning: 2023
Li, Xiaonan and Qiu, Xipeng
- Misconfidence-based Demonstration Selection for LLM In-Context Learning: 2024
Xu, Shangqing and Zhang, Chao
- In-context Learning with Retrieved Demonstrations for Language Models: A Survey: 2024
Xu, Xin and Liu, Yue and Pasupat, Panupong and Kazemi, Mehran and others
Data Selection for Task-specific Fine-tuning
Back to Table of Contents
- A large annotated corpus for learning natural language inference: 2015
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D.
- GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding: 2018
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel
- A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference: 2018
Williams, Adina and Nangia, Nikita and Bowman, Samuel
- Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks: 2019
Jason Phang and Thibault Févry and Samuel R. Bowman
- Distributionally Robust Neural Networks: 2020
Shiori Sagawa and Pang Wei Koh and Tatsunori B. Hashimoto and Percy Liang
- Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics: 2020
Swayamdipta, Swabha and Schwartz, Roy and Lourie, Nicholas... 1 hidden ... Hajishirzi, Hannaneh and Smith, Noah A. and Choi, Yejin
- Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?: 2020
Pruksachatkun, Yada and Phang, Jason and Liu, Haokun... 3 hidden ... Vania, Clara and Kann, Katharina and Bowman, Samuel R.
- On the Complementarity of Data Selection and Fine Tuning for Domain Adaptation: 2021
Dan Iter and David Grangier
- FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue: 2022
Albalak, Alon and Tuan, Yi-Lin and Jandaghi, Pegah... 3 hidden ... Getoor, Lise and Pujara, Jay and Wang, William Yang
- LoRA: Low-Rank Adaptation of Large Language Models: 2022
Edward J Hu and yelong shen and Phillip Wallis... 2 hidden ... Shean Wang and Lu Wang and Weizhu Chen
- Training Subset Selection for Weak Supervision: 2022
Lang, Hunter and Vijayaraghavan, Aravindan and Sontag, David
- On-Demand Sampling: Learning Optimally from Multiple Distributions: 2022
Haghtalab, Nika and Jordan, Michael and Zhao, Eric
- The Trade-offs of Domain Adaptation for Neural Language Models: 2022
Grangier, David and Iter, Dan
- Data Pruning for Efficient Model Pruning in Neural Machine Translation: 2023
Azeemi, Abdul and Qazi, Ihsan and Raza, Agha
- Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models: 2023
Mayee F. Chen and Nicholas Roberts and Kush Bhatia... 1 hidden ... Ce Zhang and Frederic Sala and Christopher Ré
- D2 Pruning: Message Passing for Balancing Diversity and Difficulty in Data Pruning: 2023
Adyasha Maharana and Prateek Yadav and Mohit Bansal
- Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data: 2023
Alon Albalak and Colin Raffel and William Yang Wang
- Efficient Online Data Mixing For Language Model Pre-Training: 2023
Alon Albalak and Liangming Pan and Colin Raffel and William Yang Wang
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors: 2023
Ivison, Hamish and Smith, Noah A. and Hajishirzi, Hannaneh and Dasigi, Pradeep
- Make Every Example Count: On the Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets: 2023
Bejan, Irina and Sokolov, Artem and Filippova, Katja
- LESS: Selecting Influential Data for Targeted Instruction Tuning: 2024
Mengzhou Xia and Sadhika Malladi and Suchin Gururangan and Sanjeev Arora and Danqi Chen
Beitrag
There are likely some amazing works in the field that we missed, so please contribute to the repo.
Feel free to open a pull request with new papers or create an issue and we can add them for you. Thank you in advance for your efforts!
Zitat
We hope this work serves as inspiration for many impactful future works. If you found our work useful, please cite this paper as:
@article{albalak2024survey,
title={A Survey on Data Selection for Language Models},
author={Alon Albalak and Yanai Elazar and Sang Michael Xie and Shayne Longpre and Nathan Lambert and Xinyi Wang and Niklas Muennighoff and Bairu Hou and Liangming Pan and Haewon Jeong and Colin Raffel and Shiyu Chang and Tatsunori Hashimoto and William Yang Wang},
year={2024},
journal={arXiv preprint arXiv:2402.16827},
note={url{https://arxiv.org/abs/2402.16827}}
}


