Uma pesquisa sobre seleção de dados para modelos de idiomas
Este repositório é uma lista conveniente de trabalhos relevantes para a seleção de dados para modelos de idiomas, durante todas as etapas do treinamento. Isso deve ser um recurso para a comunidade; portanto, contribua se você vir algo faltando!
Para obter mais detalhes sobre esses trabalhos e muito mais, consulte nosso documento de pesquisa: uma pesquisa sobre seleção de dados para modelos de idiomas. By this incredible team: Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Hashimoto, William Yang Wang
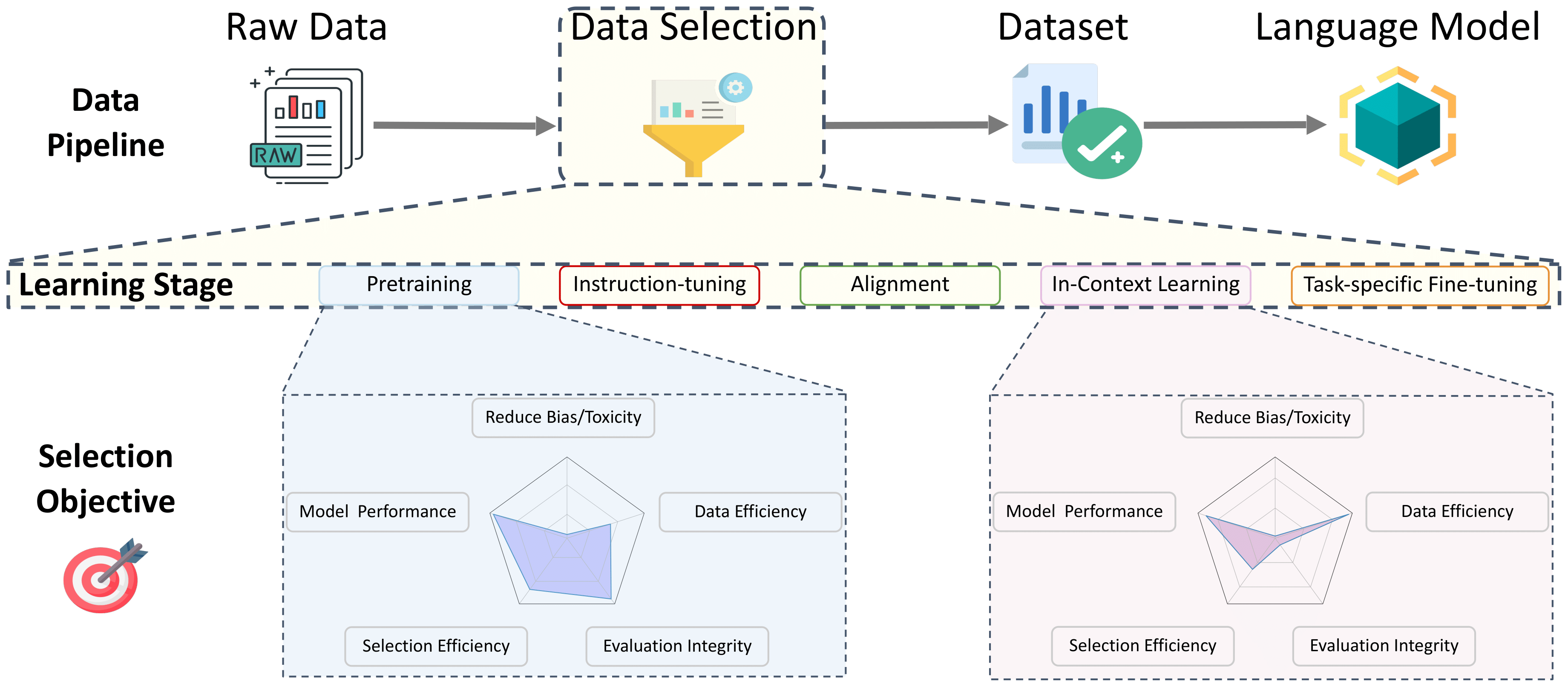
Índice
- Seleção de dados para pré -treinamento
- Filtragem de idiomas
- Abordagens heurísticas
- Qualidade de dados
- Seleção específica do domínio
- Desduplicação de dados
- Filtrando conteúdo tóxico e explícito
- Seleção especializada para modelos multilíngues
- Mixagem de dados
- Seleção de dados para ajuste de instrução e treinamento com várias tarefas
- Seleção de dados para alinhamento de ajuste fino de preferência
- Seleção de dados para aprendizado no contexto
- Seleção de dados para ajuste fino específico da tarefa
Seleção de dados para pré -treinamento
Filtragem de idiomas
Voltar para o índice
- FastText.zip: Compressionando modelos de classificação de texto: 2016
Armand Joulin e Edouard Grave e Piotr Bojanowski e Matthijs Douze e Hérve Jégou e Tomas Mikolov
- Aprendendo vetores de palavras para 157 idiomas: 2018
Sepultura, Edouard e Bojanowski, Piotr e Gupta, Prakhar e Joulin, Armand e Mikolov, Tomas
- Modelo de idioma transversal de idioma pré-treinamento: 2019
Conneau, Alexis e Lample, Guillaume
- Explorando os limites do aprendizado de transferência com um transformador de texto em texto unificado: 2020
Raffel, Colin e Orheador, Noam e Roberts, Adam ... 3 Hidden ... Zhou, Yanqi e Li, Wei e Liu, Peter J.
- ID do idioma na natureza: desafios inesperados no caminho para mil idiomas da web corpus: 2020
Caswell, Isaac e Breiner, Theresa e Van Esch, Daan e Bapna, Ankur
- Aprendizagem de representação cruzada não supervisionada em escala: 2020
Conneau, Alexis e Khandelwal, Kartikay e Goyal, Naman ... 4 Hidden ... Ott, Myle e Zettlemoyer, Luke e Stoyanov, Veselin
- CCNET: Extraindo conjuntos de dados monolíngues de alta qualidade dos dados da Web Crawl: 2020
Wenzek, Guillaume e Lachaux, Marie-Anne e Connaune, Alexis ... 1 Hidden ... Guzm'an, Francisco e Joulin, Armand e Grave, Edouard
- Uma reprodução dos modelos LSTM bidirecionais da Apple para identificação de idiomas em cordas curtas: 2021
Toftrup, Mads e Asger Sorensen, Soren e Ciosici, Manuel R. e Consent, Ira
- Avaliando grandes modelos de linguagem treinados no código: 2021
Mark Chen e Jerry Tworek e Heewoo Jun ... 52 Hidden ... Sam McCandlish e Ilya Sutskever e Wojciech Zaremba
- MT5: Um transformador de texto em texto pré-treinado multilíngue massivamente multilíngue: 2021
Xue, Linering e Constant, Noah e Roberts, Adam ... 2 Hidden ... Siddhant, Aditya e Barua, Aditya e Raffel, Colin
- Geração de código no nível da competição com alfacode: 2022
Li, Yujia e Choi, David e Chung, Junyoung ... 20 Hidden ... De Freitas, Nando e Kavukcuoglu, Koray e Vinyals, Oriol
- Palm: escala de modelagem de linguagem com caminhos: 2022
Aakanksha Chowdhery e Sharan Narang e Jacob Devlin ... 61 Hidden ... Jeff Dean e Slav Petrov e Noah Fiedel
- The Bigscience Roots Corpus: um conjunto de dados multilíngue composto de 1,6 TB: 2022
Laurenccon, Hugo e Saulnier, Lucile e Wang, Thomas ... 48 Hidden ... Mitchell, Margaret e Luccioni, Sasha Alexandra e Jernite, Yacine
- Sistema de escrita e metadados do alto -falante para mais de 2.800 variedades de idiomas: 2022
Van Esch, Daan e Lucaassen, Tamar e Ruder, Sebastian e Caswell, Isaac e Rivera, Clara
- Fingpt: grandes modelos generativos para uma pequena linguagem: 2023
Luukkonen, Risto e Komulainen, Ville e Luoma, Jouni ... 5 Hidden ... Muennighff, Niklas e Piktus, Aleksandra e outros
- Mc^ 2: Um corpus multilíngue de idiomas minoritários na China: 2023
Zhang, Chen e Tao, Mingxu e Huang, Quzhe e Lin, Jiuheng e Chen, Zhibin e Feng, Yansong
- Madlad-400: Um conjunto de dados auditado de nível multilíngue e de documentos: 2023
Kudugunta, Sneha e Caswell, Isaac e Zhang, Biao ... 5 Hidden ... Stella, Romi e Bapna, Ankur e outros
- O conjunto de dados RefinedWeb para Falcon LLM: superando corpora com curadoria com dados da Web e apenas dados da Web: 2023
Guilherme Penedo e Quentin Malartic e Daniel Hesslow ... 3 Hidden ... Baptiste Pannier e Ebtsam Almazrouei e Julien Launay
- Dolma: um corpus aberto de três trilhões de tokens para o modelo de idioma Pesquisa de pré -treinamento: 2024
Luca Soldaini e Rodney Kinney e Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld e Jesse Dodge e Kyle Lo
Abordagens heurísticas
Voltar para o índice
- Explorando os limites do aprendizado de transferência com um transformador de texto em texto unificado: 2020
Raffel, Colin e Orheador, Noam e Roberts, Adam ... 3 Hidden ... Zhou, Yanqi e Li, Wei e Liu, Peter J.
- Modelos de idiomas são poucos alunos: 2020
Brown, Tom e Mann, Benjamin e Ryder, Nick ... 25 Hidden ... Radford, Alec e Sutskever, Ilya e Amodei, Dario
- A pilha: um conjunto de dados de 800 GB de texto diversificado para modelagem de idiomas: 2020
Leo Gao e Stella Biderman e Sid Black ... 6 escondidos ... Noa Nabeshima e Shawn Pressser e Connor Leahy
- Avaliando grandes modelos de linguagem treinados no código: 2021
Mark Chen e Jerry Tworek e Heewoo Jun ... 52 Hidden ... Sam McCandlish e Ilya Sutskever e Wojciech Zaremba
- MT5: Um transformador de texto em texto pré-treinado multilíngue massivamente multilíngue: 2021
Xue, Linering e Constant, Noah e Roberts, Adam ... 2 Hidden ... Siddhant, Aditya e Barua, Aditya e Raffel, Colin
- Modelos de linguagem de escala: Métodos, Análise e Insights do Treinamento Gopher: 2022
Jack W. Rae e Sebastian Borgeaud e Trevor Cai ... 74 Hidden ... Demis Hassabis e Koray Kavukcuoglu e Geoffrey Irving
- The Bigscience Roots Corpus: um conjunto de dados multilíngue composto de 1,6 TB: 2022
Laurenccon, Hugo e Saulnier, Lucile e Wang, Thomas ... 48 Hidden ... Mitchell, Margaret e Luccioni, Sasha Alexandra e Jernite, Yacine
- HTLM: pré-treinamento de hiper-texto e solicitação de modelos de idiomas: 2022
Armen Aghajanyan e Dmytro Okhonko e Mike Lewis ... 1 Hidden ... Hu Xu e Gargi Ghosh e Luke Zettlemoyer
- LLAMA: Modelos de idiomas de fundação abertos e eficientes: 2023
Hugo Touvron e Thibaut Lavril e Gautier Izacard ... 8 Hidden ... Armand Joulin e Edouard Grave e Guillaume Lample
- O conjunto de dados RefinedWeb para Falcon LLM: superando corpora com curadoria com dados da Web e apenas dados da Web: 2023
Guilherme Penedo e Quentin Malartic e Daniel Hesslow ... 3 Hidden ... Baptiste Pannier e Ebtsam Almazrouei e Julien Launay
- O Índice de Transparência do Modelo de Fundação: 2023
Bommasani, Rishi e Klyman, Kevin e Longpre, Shayne ... 2 Hidden ... Xiong, Betty e Zhang, Daniel e Liang, Percy
- Dolma: um corpus aberto de três trilhões de tokens para o modelo de idioma Pesquisa de pré -treinamento: 2024
Luca Soldaini e Rodney Kinney e Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld e Jesse Dodge e Kyle Lo
Qualidade de dados
Voltar para o índice
- Kenlm: Modelo de linguagem mais rápido e menor consultas: 2011
HEFIEFED, KENNETH
- FastText.zip: Compressionando modelos de classificação de texto: 2016
Armand Joulin e Edouard Grave e Piotr Bojanowski e Matthijs Douze e Hérve Jégou e Tomas Mikolov
- Aprendendo vetores de palavras para 157 idiomas: 2018
Sepultura, Edouard e Bojanowski, Piotr e Gupta, Prakhar e Joulin, Armand e Mikolov, Tomas
- Modelos de idiomas são aprendizes multitarefa sem supervisão: 2019
Alec Radford e Jeff Wu e Rewon Child e David Luan e Dario Amodei e Ilya Sutskever
- Modelos de idiomas são poucos alunos: 2020
Brown, Tom e Mann, Benjamin e Ryder, Nick ... 25 Hidden ... Radford, Alec e Sutskever, Ilya e Amodei, Dario
- A pilha: um conjunto de dados de 800 GB de texto diversificado para modelagem de idiomas: 2020
Leo Gao e Stella Biderman e Sid Black ... 6 escondidos ... Noa Nabeshima e Shawn Pressser e Connor Leahy
- CCNET: Extraindo conjuntos de dados monolíngues de alta qualidade dos dados da Web Crawl: 2020
Wenzek, Guillaume e Lachaux, Marie-Anne e Connaune, Alexis ... 1 Hidden ... Guzm'an, Francisco e Joulin, Armand e Grave, Edouard
- Modelos de linguagem desintoxicantes arrisquem marginalizar vozes minoritárias: 2021
Xu, Albert e Pathak, Eshaan e Wallace, Eric e Gururangan, Suchin e Sap, Maarten e Klein, Dan
- Palm: escala de modelagem de linguagem com caminhos: 2022
Aakanksha Chowdhery e Sharan Narang e Jacob Devlin ... 61 Hidden ... Jeff Dean e Slav Petrov e Noah Fiedel
- Modelos de linguagem de escala: Métodos, Análise e Insights do Treinamento Gopher: 2022
Jack W. Rae e Sebastian Borgeaud e Trevor Cai ... 74 Hidden ... Demis Hassabis e Koray Kavukcuoglu e Geoffrey Irving
- Cuja linguagem conta como alta qualidade? Medição das ideologias da linguagem na seleção de dados de texto: 2022
Gururangan, Suchin e Card, Dallas e Dreier, Sarah ... 2 Hidden ... Wang, Zeyu e Zettlemoyer, Luke e Smith, Noah A.
- Glam: escala eficiente de modelos de linguagem com mistura de especialistas: 2022
Du, Nan e Huang, Yanping e Dai, Andrew M ... 21 Hidden ... Wu, Yonghui e Chen, Zhifeng e Cui, Claire
- Um guia de pré -trainer para o treinamento de dados: medindo os efeitos da idade dos dados, cobertura de domínio, qualidade e toxicidade: 2023
Shayne Longpre e Gregory Yauney e Emily Reif ... 5 Hidden ... Kevin Robinson e David Mimno e Daphne Ippolito
- Seleção de dados para modelos de idiomas por meio de reamostragem de importância: 2023
Sang Michael Xie e Shibani Santurkar e Tengyu Ma e Percy Liang
- O conjunto de dados RefinedWeb para Falcon LLM: superando corpora com curadoria com dados da Web e apenas dados da Web: 2023
Guilherme Penedo e Quentin Malartic e Daniel Hesslow ... 3 Hidden ... Baptiste Pannier e Ebtsam Almazrouei e Julien Launay
- Dolma: um corpus aberto de três trilhões de tokens para o modelo de idioma Pesquisa de pré -treinamento: 2024
Luca Soldaini e Rodney Kinney e Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld e Jesse Dodge e Kyle Lo
- Programando todos os exemplos: levantando a qualidade dos dados pré-treinamento, como especialistas em escala: 2024
Fan Zhou e Zengzhi Wang e Qian Liu e Junlong Li e Pengfei Liu
Seleção específica do domínio
Voltar para o índice
- Aquisição de dados de texto para modelos de idiomas específicos de domínio: 2006
Sethy, Abhinav e Georgiou, Panayiotis G. e Narayanan, Shrikanth
- Seleção inteligente de dados de treinamento de modelos de idiomas: 2010
Moore, Robert C. e Lewis, William
- Seleção cínica de dados de treinamento de modelos de idiomas: 2017
AMITAI AXELROD
- Seleção automática de documentos para o codificador eficiente pré -treinamento: 2022
Feng, Yukun e Xia, Patrick e Van Durme, Benjamin e Sedoc, Jo ~ Ao
- Seleção de dados para modelos de idiomas por meio de reamostragem de importância: 2023
Sang Michael Xie e Shibani Santurkar e Tengyu Ma e Percy Liang
- DSDM: Seleção de conjunto de dados com reconhecimento de modelo com Datamodels: 2024
Logan Engstrom e Axel Feldmann e Aleksander Madry
Desduplicação de dados
Voltar para o índice
- Trade-offs espaciais/tempo na codificação de hash com erros permitidos: 1970
Bloom, Burton H.
- Matrizes de sufixo: um novo método para pesquisas de string on-line: 1993
Manber, Udi e Myers, Gene
- Sobre a semelhança e contenção de documentos: 1997
Broder, AZ
- Técnicas de estimativa de similaridade de algoritmos de arredondamento: 2002
Charikar, Moses S.
- Normalização da URL para desduplicação de páginas da web: 2009
Agarwal, Amit e Koppula, Hema Swetha e Leela, Krishna P .... 3 Hidden ... Haty, Chittaranjan e Roy, Anirban e Sasturkar, Amit Amit
- Oleodutos assíncronos para processar grandes corpora em infraestruturas de recursos médios a baixos: 2019
Pedro Javier Ortiz Su'arez e Beno^It Sagot e Laurent Romary
- Modelos de idiomas são poucos alunos: 2020
Brown, Tom e Mann, Benjamin e Ryder, Nick ... 25 Hidden ... Radford, Alec e Sutskever, Ilya e Amodei, Dario
- A pilha: um conjunto de dados de 800 GB de texto diversificado para modelagem de idiomas: 2020
Leo Gao e Stella Biderman e Sid Black ... 6 escondidos ... Noa Nabeshima e Shawn Pressser e Connor Leahy
- CCNET: Extraindo conjuntos de dados monolíngues de alta qualidade dos dados da Web Crawl: 2020
Wenzek, Guillaume e Lachaux, Marie-Anne e Connaune, Alexis ... 1 Hidden ... Guzm'an, Francisco e Joulin, Armand e Grave, Edouard
- Além das leis de escala neural: espancar a escala da lei de poder via prumagem de dados: 2022
Ben Sorscher e Robert Geirhos e Shashank Shekhar e Surya Gangus e Ari S. Morcos
- Dados de treinamento para desduplicar melhoram os modelos de idiomas: 2022
Lee, Katherine e Ippolito, Daphne e Nystrom, Andrew ... 1 Hidden ... Eck, Douglas e Callison-Burch, Chris e Carlini, Nicholas
- MTEB: Benchmark de incorporação de texto maciço: 2022
Muennighff, Niklas e Tazi, Nouamane e Magne, Lo "IC e Reimers, Nils
- Palm: escala de modelagem de linguagem com caminhos: 2022
Aakanksha Chowdhery e Sharan Narang e Jacob Devlin ... 61 Hidden ... Jeff Dean e Slav Petrov e Noah Fiedel
- Modelos de linguagem de escala: Métodos, Análise e Insights do Treinamento Gopher: 2022
Jack W. Rae e Sebastian Borgeaud e Trevor Cai ... 74 Hidden ... Demis Hassabis e Koray Kavukcuoglu e Geoffrey Irving
- SGPT: Sentença GPT INCEGIDAS PARA PARCENDO SEMUSTIC: 2022
Muennighff, Niklas
- The Bigscience Roots Corpus: um conjunto de dados multilíngue composto de 1,6 TB: 2022
Laurenccon, Hugo e Saulnier, Lucile e Wang, Thomas ... 48 Hidden ... Mitchell, Margaret e Luccioni, Sasha Alexandra e Jernite, Yacine
- C-Pack: Recursos embalados para avançar a incorporação geral chinesa: 2023
Xiao, Shitao e Liu, Zheng e Zhang, Peitian e Muennighff, Niklas
- D4: Melhorando a pré-treinamento de LLM via desduplicação e diversificação de documentos: 2023
Kushal Tirumala e Daniel Simig e Armen Aghajanyan e Ari S. Morcos
- Perto deduplicação em larga escala atrás do BigCode: 2023
MoU, Chenghao
- Paloma: uma referência para avaliar o modelo de modelo de idioma: 2023
Ian Magnusson e Akshita Bhagia e Valentin Hofmann ... 10 Hidden ... Noah A. Smith e Kyle Richardson e Jesse Dodge
- Quantificando memorização entre modelos de idiomas neurais: 2023
Nicholas Carlini e Daphne Ippolito e Matthew Jagielski e Katherine Lee e Florian Tramer e Chiyuan Zhang
- Semedup: aprendizado com eficiência de dados na escala da Web através da desduplicação semântica: 2023
Abbas, Amro e Tirumala, Kushal e Simig, D'Niel e Ganguli, Surya e Morcos, Ari S
- O conjunto de dados RefinedWeb para Falcon LLM: superando corpora com curadoria com dados da Web e apenas dados da Web: 2023
Guilherme Penedo e Quentin Malartic e Daniel Hesslow ... 3 Hidden ... Baptiste Pannier e Ebtsam Almazrouei e Julien Launay
- O que há no meu big data?: 2023
Elazar, Yanai e Bhagia, Akshita e Magnusson, Ian ... 5 Hidden ... Soldaini, Luca e Singh, Sameer e outros
- Dolma: um corpus aberto de três trilhões de tokens para o modelo de idioma Pesquisa de pré -treinamento: 2024
Luca Soldaini e Rodney Kinney e Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld e Jesse Dodge e Kyle Lo
- Instrução representacional generativa Tuning: 2024
Muennighff, Niklas e Su, Hongjin e Wang, Liang ... 2 Hidden ... Yu, Tao e Singh, Amanpreet e Kiela, Douwe
Filtrando conteúdo tóxico e explícito
Voltar para o índice
- Explorando os limites do aprendizado de transferência com um transformador de texto em texto unificado: 2020
Raffel, Colin e Orheador, Noam e Roberts, Adam ... 3 Hidden ... Zhou, Yanqi e Li, Wei e Liu, Peter J.
- MT5: Um transformador de texto em texto pré-treinado multilíngue massivamente multilíngue: 2021
Xue, Linering e Constant, Noah e Roberts, Adam ... 2 Hidden ... Siddhant, Aditya e Barua, Aditya e Raffel, Colin
- Perplexo com a qualidade: um método baseado em perplexidade para detecção de conteúdo adulto e prejudicial em dados da Web heterogêneos multilíngues: 2022
Tim Jansen e Yangling Tong e Victoria Zevallos e Pedro Ortiz Suarez
- Modelos de linguagem de escala: Métodos, Análise e Insights do Treinamento Gopher: 2022
Jack W. Rae e Sebastian Borgeaud e Trevor Cai ... 74 Hidden ... Demis Hassabis e Koray Kavukcuoglu e Geoffrey Irving
- The Bigscience Roots Corpus: um conjunto de dados multilíngue composto de 1,6 TB: 2022
Laurenccon, Hugo e Saulnier, Lucile e Wang, Thomas ... 48 Hidden ... Mitchell, Margaret e Luccioni, Sasha Alexandra e Jernite, Yacine
- Cuja linguagem conta como alta qualidade? Medição das ideologias da linguagem na seleção de dados de texto: 2022
Gururangan, Suchin e Card, Dallas e Dreier, Sarah ... 2 Hidden ... Wang, Zeyu e Zettlemoyer, Luke e Smith, Noah A.
- Um guia de pré -trainer para o treinamento de dados: medindo os efeitos da idade dos dados, cobertura de domínio, qualidade e toxicidade: 2023
Shayne Longpre e Gregory Yauney e Emily Reif ... 5 Hidden ... Kevin Robinson e David Mimno e Daphne Ippolito
- Conjunto de dados de treinamento de imagem de IA encontrado para incluir imagens de abuso sexual infantil: 2023
David, Emilia
- Detectar informações pessoais em treinamento corporal: uma análise: 2023
Subramani, Nishant e Luccioni, Sasha e Dodge, Jesse e Mitchell, Margaret
- Relatório Técnico GPT-4: 2023
Openai e: e Josh Achiam ... 276 Hidden ... Juntang Zhuang e William Zhuk e Barret Zoph
- Santacoder: Não pegue as estrelas!: 2023
Allal, Loubna Ben e Li, Raymond e Kocetkov, Denis ... 5 Hidden ... Gu, Alex e Dey, Manan e outros
- O conjunto de dados RefinedWeb para Falcon LLM: superando corpora com curadoria com dados da Web e apenas dados da Web: 2023
Guilherme Penedo e Quentin Malartic e Daniel Hesslow ... 3 Hidden ... Baptiste Pannier e Ebtsam Almazrouei e Julien Launay
- O Índice de Transparência do Modelo de Fundação: 2023
Bommasani, Rishi e Klyman, Kevin e Longpre, Shayne ... 2 Hidden ... Xiong, Betty e Zhang, Daniel e Liang, Percy
- O que há no meu big data?: 2023
Elazar, Yanai e Bhagia, Akshita e Magnusson, Ian ... 5 Hidden ... Soldaini, Luca e Singh, Sameer e outros
- Dolma: um corpus aberto de três trilhões de tokens para o modelo de idioma Pesquisa de pré -treinamento: 2024
Luca Soldaini e Rodney Kinney e Akshita Bhagia ... 30 Hidden ... Dirk Groeneveld e Jesse Dodge e Kyle Lo
- Olmo: acelerando a ciência dos modelos de idiomas: 2024
Groeneveld, Dirk e Beltagy, Iz e Walsh, Pete ... 5 Hidden ... Magnusson, Ian e Wang, Yizhong e outros
Seleção especializada para modelos multilíngues
Voltar para o índice
- Bloom: Um Modelo de Linguagem Multilíngue de Acesso Aberto de 176b-Parâmetro: 2022
Workshop, Bigscience e Scao, Teven Le e Fan, Angela ... 5 Hidden ... Luccioni, Alexandra Sasha e Yvon, Franccois e outros
- Qualidade de relance: uma auditoria de conjuntos de dados multilíngues de rastreamento na web: 2022
Kreutzer, Julia e Caswell, Isaac e Wang, Lisa ... 46 Hidden ... Ahia, Oghenefego e Agrawal, Sweta e Adeyemi, Mofetoluwa
- The Bigscience Roots Corpus: um conjunto de dados multilíngue composto de 1,6 TB: 2022
Laurenccon, Hugo e Saulnier, Lucile e Wang, Thomas ... 48 Hidden ... Mitchell, Margaret e Luccioni, Sasha Alexandra e Jernite, Yacine
- Que modelo de idioma para treinar se você tiver um milhão de horas de GPU?: 2022
Scao, Teven Le e Wang, Thomas e Hesslow, Daniel ... 5 Hidden ... Muennighff, Niklas e Phang, Jason e outros
- Madlad-400: Um conjunto de dados auditado de nível multilíngue e de documentos: 2023
Kudugunta, Sneha e Caswell, Isaac e Zhang, Biao ... 5 Hidden ... Stella, Romi e Bapna, Ankur e outros
- Modelos de linguagem multilíngue em escala em dados restritos: 2023
Scao, Teven Le
- DataSet AYA: Uma coleção de acesso aberto para instrução multilíngue Tuning: 2024
Shivalika Singh e Freddie Vargus e Daniel Dsouza ... 27 Hidden ... Ahmet üstün e Marzieh Fadaee e Sara Hooker
Mixagem de dados
Voltar para o índice
- O não -estocástico Bandit Bandit Problem: 2002
Auer, Peter e Cesa-Bianchi, Nicol`o e Freund, Yoav e Schapire, Robert E.
- Modelagem de idiomas robustos distribuídos: 2019
Oren, Yonatan e Sagawa, Shiori e Hashimoto, Tatsunori B. e Liang, Percy
- Redes neurais robustas distribuídas: 2020
Shiori Sagawa e Pang Wei Koh e Tatsunori B. Hashimoto e Percy Liang
- Explorando os limites do aprendizado de transferência com um transformador de texto em texto unificado: 2020
Raffel, Colin e Orheador, Noam e Roberts, Adam ... 3 Hidden ... Zhou, Yanqi e Li, Wei e Liu, Peter J.
- A pilha: um conjunto de dados de 800 GB de texto diversificado para modelagem de idiomas: 2020
Leo Gao e Stella Biderman e Sid Black ... 6 escondidos ... Noa Nabeshima e Shawn Pressser e Connor Leahy
- Modelos de linguagem de escala: Métodos, Análise e Insights do Treinamento Gopher: 2022
Jack W. Rae e Sebastian Borgeaud e Trevor Cai ... 74 Hidden ... Demis Hassabis e Koray Kavukcuoglu e Geoffrey Irving
- Glam: escala eficiente de modelos de linguagem com mistura de especialistas: 2022
Du, Nan e Huang, Yanping e Dai, Andrew M ... 21 Hidden ... Wu, Yonghui e Chen, Zhifeng e Cui, Claire
- A supervisão transversal melhora os grandes modelos de idiomas pré-treinamento: 2023
Andrea Schioppa e Xavier Garcia e Orhan Firat
- [DOGE: Recundações de domínio com estimativa de generalização] (https://arxiv.org/abs/arxiv pré -impressão): 2023
Simin Fan e Matteo Pagliardini e Martin Jaggi
- Doremi: otimizando a mistura de dados acelera o modelo de idioma pré -treinamento: 2023
Sang Michael Xie e Hieu Pham e Xuanyi Dong ... 4 Hidden ... Quoc V Le e Tengyu Ma e Adams Wei Yu
- Mixagem de dados on-line eficiente para modelo de idioma pré-treinamento: 2023
Alon Albalak e Liangming Pan e Colin Raffel e William Yang Wang
- LLAMA: Modelos de idiomas de fundação abertos e eficientes: 2023
Hugo Touvron e Thibaut Lavril e Gautier Izacard ... 8 Hidden ... Armand Joulin e Edouard Grave e Guillaume Lample
- Pythia: uma suíte para analisar grandes modelos de idiomas em treinamento e escala: 2023
Biderman, Stella e Schoelkopf, Hailey e Anthony, Quentin Gregory ... 7 Hidden ... Skowron, Aviya e Sutawika, Lintang e Van Der Wal, Oskar
- Modelos de linguagem com restrição de dados: 2023
Niklas Muennighff e Alexander M Rush e Boaz Barak ... 3 Hidden ... Sampo Pyysalo e Thomas Wolf e Colin Raffel
- Lhama cisalhada: Acelerando o modelo de linguagem pré-treinamento via poda estruturada: 2023
Mengzhou Xia e Tianyu Gao e Zhiyuan Zeng e Danqi Chen
- Habilidade-it! Uma estrutura de habilidades orientada a dados para entender e treinar modelos de idiomas: 2023
Mayee F. Chen e Nicholas Roberts e Kush Bhatia ... 1 Hidden ... CE Zhang e Frederic Sala e Christopher Ré
Seleção de dados para ajuste de instrução e treinamento com várias tarefas
Voltar para o índice
- O Decatlo de Língua Natura
McCann, Bryan e Keskar, Nitish Shirish e Xiong, Caiming e Socher, Richard
- Unificar perguntas de resposta, classificação de texto e regressão por extração de span: 2019
Keskar, Nitish Shirish e McCann, Bryan e Xiong, Caiming e Socher, Richard
- Redes neurais profundas de várias tarefas para compreensão da linguagem natural: 2019
Liu, Xiaodong e ele, Pengcheng e Chen, Weizhu e Gao, Jianfeng
- UnifiedQa: cruzando os limites do formato com um único sistema de controle de qualidade: 2020
Khashabi, Daniel e Min, Sewon e Khot, Tushar ... 1 escondido ... Tafjord, Oyvind e Clark, Peter e Hajishirzi, Hannaneh
- Explorando os limites do aprendizado de transferência com um transformador de texto em texto unificado: 2020
Raffel, Colin e Orheador, Noam e Roberts, Adam ... 3 Hidden ... Zhou, Yanqi e Li, Wei e Liu, Peter J.
- Muppet: Representações múltiplas massivas com pré-finetuning: 2021
Aghajanyan, Armen e Gupta, Anchit e Shrivastava, Akshat e Chen, Xilun e Zettlemoyer, Luke e Gupta, Sonal
- Os modelos de idiomas Finetuned são aprendizes de tiro zero: 2021
Wei, Jason e Bosma, Maarten e Zhao, Vincent Y .... 3 Hidden ... Du, Nan e Dai, Andrew M. e Le, Quoc V.
- Generalização cruzada via idioma natural Crowdsourcing Instruções: 2021
Mishra, Swaroop e Khashabi, Daniel e Baral, Chitta e Hajishirzi, Hannaneh
- NL-Augmenter: Uma estrutura para aumento da linguagem natural sensível à tarefa: 2021
Dhole, Kaustubh D e Gangal, Varun e Gehrmann, Sebastian ... 5 Hidden ... Shrivastava, Ashish e Tan, Samson e outros
- Ext5: em direção à escala extrema de várias tarefas para aprendizado de transferência: 2021
Aribandi, Vamsi e Tay, Yi e Schuster, Tal ... 5 Hidden ... Bahri, Dara e Ni, Jianmo e outros
- Supernaturalinstructions: generalização por meio de instruções declarativas em 1600+ tarefas de NLP: 2022
Wang, Yizhong e Mishra, Swaroop e Alipoormolabashi, PEGAH ... 29 Hidden ... Patro, Sumanta e Dixit, Tanay e Shen, Xudong
- Modelos de idiomas de instrução de escala Finetuned: 2022
Chung, Hyung Won e Hou, Le e Longpre, Shayne ... 5 Hidden ... Dehghani, Mostafa e Brahma, Siddhartha e outros
- Bloom+ 1: Adicionando suporte à linguagem ao Bloom para zero tiro de tiro: 2022
Yong, Zheng-Xin e Schoelkopf, Hailey e Muennighff, Niklas ... 5 Hidden ... Kasai, Jungo e Baruwa, Ahmed e outros
- OPT-IML: Escalando a instrução Modelo de linguagem Meta Learning através da lente da generalização: 2022
Srinivasan Iyer e Xi Victoria Lin e Ramakanth Pasunuru ... 12 Hidden ... Asli Celikyilmaz e Luke Zettlemoyer e Ves Stoyanov
- METAICL: Aprendendo a aprender no contexto: 2022
Min, Sewon e Lewis, Mike e Zettlemoyer, Luke e Hajishirzi, Hannaneh
- Instruções não naturais: Ajustando modelos de linguagem com (quase) nenhum trabalho humano: 2022
Honovich, ou e Scialom, Thomas e Levy, Omer e Schick, Timo
- Generalização cruzada por meio da multitarefa Finetuning: 2022
Muennighff, Niklas e Wang, Thomas e Sutawika, Lintang ... 5 Hidden ... Yong, Zheng-Xin e Schoelkopf, Hailey e outros
- O treinamento solicitado por várias tarefas permite a generalização de tarefas zero: 2022
Victor Sanh e Albert Webson e Colin Raffel ... 34 Hidden ... Leo Gao e Thomas Wolf e Alexander M Rush
- Prometheus: Induzindo a capacidade de avaliação de granulação fina em modelos de idiomas: 2023
Kim, Seungone e Shin, Jamin e Cho, Yejin ... 5 Hidden ... Kim, Sungdong e Thorne, James e outros
- Slimorca: um conjunto de dados aberto do GPT-4 Flan Raciacing Rastrening, com verificação: 2023
Wing Lian e Guan Wang e Bleys Goodson ... 1 escondido ... Austin Cook e Chanvichet Vong e "Teknium"
- A IA Art está roubando artistas?: 2023
Chayka, Kyle
- Paul Tremblay, Mona Awad vs. Openai, Inc., et al.: 2023
Saveri, Joseph R. e Zirpoli, Cadio e Young, Christopher KL e McMahon, Kathleen J.
- Fazendo grandes modelos de idiomas melhores criadores de dados: 2023
Lee, Dong-ho e Pujara, Jay e Sewak, Mohit e White, Ryen e Jauhar, Sujay
- A coleção de flan: projetando dados e métodos para uma instrução eficaz ajustando: 2023
Shayne Longpre e Le Hou e Tu Vu ... 5 Hidden ... Barret Zoph e Jason Wei e Adam Roberts
- Assistente: capacitar grandes modelos de idiomas para seguir instruções complexas: 2023
Xu, Can e Sun, Qingfeng e Zheng, Kai ... 2 Hidden ... Feng, Jiazhan e Tao, Chongyang e Jiang, Daxin
- Lima: Menos é mais para o alinhamento: 2023
Chunting Zhou e Pengfei Liu e Puxin Xu ... 9 Hidden ... Mike Lewis e Luke Zettlemoyer e Omer Levy
- Camelos em um clima em mudança: aprimorando a adaptação LM com Tulu 2: 2023
Hamish Ivison e Yizhong Wang e Valentina Pyatkin ... 5 Hidden ... Noah A. Smith e Iz Beltagy e Hannaneh Hajishirzi
- Auto-instrução: alinhando modelos de linguagem com instruções auto-geradas: 2023
Wang, Yizhong e Kordi, Yeganeh e Mishra, Swaroop ... 1 Hidden ... Smith, Noah A. e Khashabi, Daniel e Hajishirzi, Hannaneh
- O que faz bons dados para o alinhamento? Um estudo abrangente da seleção automática de dados em Instrução Tuning: 2023
Liu, Wei e Zeng, Weihao e ele, Keqing e Jiang, Yong e ele, Junxian
- Ajuste de instrução para grandes modelos de idiomas: uma pesquisa: 2023
Shengyu Zhang e Linfeng Dong e Xiaoya Li ... 5 Hidden ... Tianwei Zhang e Fei Wu e Guoyin Wang
- Stanford Alpaca: Um modelo de llama que segue a instrução: 2023
Rohan Taori e Ishaan Gulrajani e Tianyi Zhang ... 2 Hidden ... Carlos Guestrin e Percy Liang e Tatsunori B. Hashimoto
- Até onde os camelos podem ir? Explorando o estado de instrução Tuning on Open Resources: 2023
Yizhong Wang e Hamish Ivison e Pradeep Dasigi ... 5 Hidden ... Noah A. Smith e Iz Beltagy e Hannaneh Hajishirzi
- Conversas abertas-Democratizando o Alinhamento de Modelo de Linguagem: 2023
K "Opf, Andreas e Kilcher, Yannic e Von R" Utte, Dimitri ... 5 Hidden ... Stanley, Oliver e Nagyfi, Rich'ard e outros
- Octopack: Código de ajuste de instrução Modelos de idiomas grandes: 2023
Niklas Muennighff e Qian Liu e Armel Zebaze ... 4 Hidden ... Xiangru Tang e Leandro von Werra e Shayne Longpre
- Self: Auto-evolução orientada para a linguagem para grande idioma Modelo: 2023
Lu, Jianqiao e Zhong, Wanjun e Huang, Wenyong ... 3 Hidden ... Wang, Weichao e Shang, Lifeng e Liu, Qun
- A coleção de flan: projetando dados e métodos para uma instrução eficaz ajustando: 2023
Longpre, Shayne e Hou, Le e Vu, Tu ... 5 Hidden ... Zoph, Barret e Wei, Jason e Roberts, Adam
- #Instag: marcação de instruções para analisar o ajuste fino supervisionado de grandes modelos de idiomas: 2023
Keming Lu e Hongyi Yuan e Zheng Yuan ... 2 Hidden ... Chuanqi Tan e Chang Zhou e Jingren Zhou
- Mineração de instruções: quando a mineração de dados atende ao grande modelo de idioma Finetuning: 2023
Yihan Cao e Yanbin Kang e Chi Wang e Lichao Sun
- Instrução ativa Ajuste: Melhorando a generalização entre tarefas ao treinamento em tarefas sensíveis prontas: 2023
Po-Nien Kung e Fan Yin e Di Wu e Kai-Wei Chang e Nanyun Peng
- A iniciativa de proveniência de dados: uma auditoria em larga escala de licenciamento e atribuição de dados em IA: 2023
Longpre, Shayne e Mahari, Robert e Chen, Anthony ... 5 Hidden ... Kabbara, Jad e Perisetla, Kartik e outros
- DataSet AYA: Uma coleção de acesso aberto para instrução multilíngue Tuning: 2024
Shivalika Singh e Freddie Vargus e Daniel Dsouza ... 27 Hidden ... Ahmet üstün e Marzieh Fadaee e Sara Hooker
- Astraios: Código de ajuste de instrução com eficiência de parâmetro Modelos de idiomas grandes: 2024
Zhuo, Terry Yue e Zebaze, Armel e Supattarachai, Nitchakarn ... 1 Hidden ... De Vries, Harm e Liu, Qian e Muennighff, Niklas
- Modelo AYA: uma instrução FinetUned Acessor de acesso aberto Modelo de linguagem: 2024
"Ust" un, Ahmet e Aryabumi, Viraat e Yong, Zheng-Xin ... 5 Hidden ... ooi, Hui-Lee e Kayid, Amr e outros
- Modelos de idiomas menores são capazes de selecionar dados de treinamento de ajuste de instrução para modelos de idiomas maiores: 2024
Dheeraj Mekala e Alex Nguyen e Jingbo Shang
- Curadoria de dados automatizada para modelo de linguagem robusta Fine Tuning: 2024
Jihai Chen e Jonas Mueller
Seleção de dados para ajuste fino de preferência: alinhamento
Voltar para o índice
- WebGPT: Pergunta assistida por navegador-Responsando com feedback humano: 2021
Nakano, Reiichiro e Hilton, Jacob e Balaji, Suchir ... 5 Hidden ... Kosaraju, Vineet e Saunders, William e outros
- Treinando um assistente útil e inofensivo com o aprendizado de reforço com o feedback humano: 2022
Bai, Yuntao e Jones, Andy e Ndousse, Kamal ... 5 Hidden ... Gangus, Deep e Henighan, Tom e outros
- Entendendo a dificuldade do conjunto de dados com $ mathcalv $-Informações usáveis: 2022
Etayarajh, Kawin e Choi, Yejin e Swayamdipta, Swabha
- Ai constitucional: inofensidade da IA Feedback: 2022
Bai, Yuntao e Kadavath, Saurav e Kundu, Sandipan ... 5 Hidden ... Mirhoseini, Azalia e McKinnon, Cameron e outros
- Prometheus: Induzindo a capacidade de avaliação de granulação fina em modelos de idiomas: 2023
Kim, Seungone e Shin, Jamin e Cho, Yejin ... 5 Hidden ... Kim, Sungdong e Thorne, James e outros
- NOTUS: 2023
Alvaro Bartolome e Gabriel Martin e Daniel Vila
- Ultrafeedback: Modelos de linguagem de impulso com feedback de alta qualidade: 2023
Ganqu Cui e Lifan Yuan e Ning Ding ... 3 escondidos ... Guotong Xie e Zhiyuan Liu e Maosong Sun
- Exploração com Princípios para Diversas AI Supervisão: 2023
Liu, Hao e Zaharia, Matei e Abbeel, Pieter
- Wizardlm: Empowering large language models to follow complex instructions: 2023
Xu, Can and Sun, Qingfeng and Zheng, Kai... 2 hidden ... Feng, Jiazhan and Tao, Chongyang and Jiang, Daxin
- LIMA: Less Is More for Alignment: 2023
Chunting Zhou and Pengfei Liu and Puxin Xu... 9 hidden ... Mike Lewis and Luke Zettlemoyer and Omer Levy
- Shepherd: A Critic for Language Model Generation: 2023
Tianlu Wang and Ping Yu and Xiaoqing Ellen Tan... 4 hidden ... Luke Zettlemoyer and Maryam Fazel-Zarandi and Asli Celikyilmaz
- No Robots: 2023
Nazneen Rajani and Lewis Tunstall and Edward Beeching and Nathan Lambert and Alexander M. Rush and Thomas Wolf
- Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF: 2023
Zhu, Banghua and Frick, Evan and Wu, Tianhao and Zhu, Hanlin and Jiao, Jiantao
- Scaling laws for reward model overoptimization: 2023
Gao, Leo and Schulman, John and Hilton, Jacob
- SALMON: Self-Alignment with Principle-Following Reward Models: 2023
Zhiqing Sun and Yikang Shen and Hongxin Zhang... 2 hidden ... David Cox and Yiming Yang and Chuang Gan
- Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback: 2023
Stephen Casper and Xander Davies and Claudia Shi... 26 hidden ... David Krueger and Dorsa Sadigh and Dylan Hadfield-Menell
- Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2: 2023
Hamish Ivison and Yizhong Wang and Valentina Pyatkin... 5 hidden ... Noah A. Smith and Iz Beltagy and Hannaneh Hajishirzi
- Llama 2: Open Foundation and Fine-Tuned Chat Models: 2023
Hugo Touvron and Louis Martin and Kevin Stone... 62 hidden ... Robert Stojnic and Sergey Edunov and Thomas Scialom
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning: 2023
Liu, Wei and Zeng, Weihao and He, Keqing and Jiang, Yong and He, Junxian
- HuggingFace H4 Stack Exchange Preference Dataset: 2023
Lambert, Nathan and Tunstall, Lewis and Rajani, Nazneen and Thrush, Tristan
- Textbooks Are All You Need: 2023
Gunasekar, Suriya and Zhang, Yi and Aneja, Jyoti... 5 hidden ... de Rosa, Gustavo and Saarikivi, Olli and others
- Quality-Diversity through AI Feedback: 2023
Herbie Bradley and Andrew Dai and Hannah Teufel... 4 hidden ... Kenneth Stanley and Grégory Schott and Joel Lehman
- Direct preference optimization: Your language model is secretly a reward model: 2023
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D and Finn, Chelsea
- Scaling relationship on learning mathematical reasoning with large language models: 2023
Yuan, Zheng and Yuan, Hongyi and Li, Chengpeng and Dong, Guanting and Tan, Chuanqi and Zhou, Chang
- The History and Risks of Reinforcement Learning and Human Feedback: 2023
Lambert, Nathan and Gilbert, Thomas Krendl and Zick, Tom
- Zephyr: Direct distillation of lm alignment: 2023
Tunstall, Lewis and Beeching, Edward and Lambert, Nathan... 5 hidden ... Fourrier, Cl'ementine and Habib, Nathan and others
- Perils of Self-Feedback: Self-Bias Amplifies in Large Language Models: 2024
Wenda Xu and Guanglei Zhu and Xuandong Zhao and Liangming Pan and Lei Li and William Yang Wang
- Suppressing Pink Elephants with Direct Principle Feedback: 2024
Louis Castricato and Nathan Lile and Suraj Anand and Hailey Schoelkopf and Siddharth Verma and Stella Biderman
- West-of-N: Synthetic Preference Generation for Improved Reward Modeling: 2024
Alizée Pace and Jonathan Mallinson and Eric Malmi and Sebastian Krause and Aliaksei Severyn
- Statistical Rejection Sampling Improves Preference Optimization: 2024
Liu, Tianqi and Zhao, Yao and Joshi, Rishabh... 1 hidden ... Saleh, Mohammad and Liu, Peter J and Liu, Jialu
- Self-play fine-tuning converts weak language models to strong language models: 2024
Chen, Zixiang and Deng, Yihe and Yuan, Huizhuo and Ji, Kaixuan and Gu, Quanquan
- Self-Rewarding Language Models: 2024
Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston
- Theoretical guarantees on the best-of-n alignment policy: 2024
Beirami, Ahmad and Agarwal, Alekh and Berant, Jonathan... 1 hidden ... Eisenstein, Jacob and Nagpal, Chirag and Suresh, Ananda Theertha
- KTO: Model Alignment as Prospect Theoretic Optimization: 2024
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe
Data Selection for In-Context Learning
Voltar para o índice
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks: 2019
Reimers, Nils and Gurevych, Iryna
- Language Models are Few-Shot Learners: 2020
Brown, Tom and Mann, Benjamin and Ryder, Nick... 25 hidden ... Radford, Alec and Sutskever, Ilya and Amodei, Dario
- True Few-Shot Learning with Language Models: 2021
Ethan Perez and Douwe Kiela and Kyunghyun Cho
- Active Example Selection for In-Context Learning: 2022
Zhang, Yiming and Feng, Shi and Tan, Chenhao
- Careful Data Curation Stabilizes In-context Learning: 2022
Chang, Ting-Yun and Jia, Robin
- Learning To Retrieve Prompts for In-Context Learning: 2022
Rubin, Ohad and Herzig, Jonathan and Berant, Jonathan
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity: 2022
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus
- What Makes Good In-Context Examples for GPT-3?: 2022
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu
- MetaICL: Learning to Learn In Context: 2022
Min, Sewon and Lewis, Mike and Zettlemoyer, Luke and Hajishirzi, Hannaneh
- Unified Demonstration Retriever for In-Context Learning: 2023
Li, Xiaonan and Lv, Kai and Yan, Hang... 3 hidden ... Xie, Guotong and Wang, Xiaoling and Qiu, Xipeng
- Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection: 2023
Mavromatis, Costas and Srinivasan, Balasubramaniam and Shen, Zhengyuan... 1 hidden ... Rangwala, Huzefa and Faloutsos, Christos and Karypis, George
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning: 2023
Xinyi Wang and Wanrong Zhu and Michael Saxon and Mark Steyvers and William Yang Wang
- Selective Annotation Makes Language Models Better Few-Shot Learners: 2023
Hongjin SU and Jungo Kasai and Chen Henry Wu... 5 hidden ... Luke Zettlemoyer and Noah A. Smith and Tao Yu
- In-context Example Selection with Influences: 2023
Nguyen, Tai and Wong, Eric
- Coverage-based Example Selection for In-Context Learning: 2023
Gupta, Shivanshu and Singh, Sameer and Gardner, Matt
- Compositional exemplars for in-context learning: 2023
Ye, Jiacheng and Wu, Zhiyong and Feng, Jiangtao and Yu, Tao and Kong, Lingpeng
- Take one step at a time to know incremental utility of demonstration: An analysis on reranking for few-shot in-context learning: 2023
Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- Ambiguity-aware in-context learning with large language models: 2023
Gao, Lingyu and Chaudhary, Aditi and Srinivasan, Krishna and Hashimoto, Kazuma and Raman, Karthik and Bendersky, Michael
- IDEAL: Influence-Driven Selective Annotations Empower In-Context Learners in Large Language Models: 2023
Zhang, Shaokun and Xia, Xiaobo and Wang, Zhaoqing... 1 hidden ... Liu, Jiale and Wu, Qingyun and Liu, Tongliang
- ScatterShot: Interactive In-context Example Curation for Text Transformation: 2023
Wu, Sherry and Shen, Hua and Weld, Daniel S and Heer, Jeffrey and Ribeiro, Marco Tulio
- Diverse Demonstrations Improve In-context Compositional Generalization: 2023
Levy, Itay and Bogin, Ben and Berant, Jonathan
- Finding supporting examples for in-context learning: 2023
Li, Xiaonan and Qiu, Xipeng
- Misconfidence-based Demonstration Selection for LLM In-Context Learning: 2024
Xu, Shangqing and Zhang, Chao
- In-context Learning with Retrieved Demonstrations for Language Models: A Survey: 2024
Xu, Xin and Liu, Yue and Pasupat, Panupong and Kazemi, Mehran and others
Data Selection for Task-specific Fine-tuning
Voltar para o índice
- A large annotated corpus for learning natural language inference: 2015
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D.
- GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding: 2018
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel
- A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference: 2018
Williams, Adina and Nangia, Nikita and Bowman, Samuel
- Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks: 2019
Jason Phang and Thibault Févry and Samuel R. Bowman
- Distributionally Robust Neural Networks: 2020
Shiori Sagawa and Pang Wei Koh and Tatsunori B. Hashimoto and Percy Liang
- Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics: 2020
Swayamdipta, Swabha and Schwartz, Roy and Lourie, Nicholas... 1 hidden ... Hajishirzi, Hannaneh and Smith, Noah A. and Choi, Yejin
- Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?: 2020
Pruksachatkun, Yada and Phang, Jason and Liu, Haokun... 3 hidden ... Vania, Clara and Kann, Katharina and Bowman, Samuel R.
- On the Complementarity of Data Selection and Fine Tuning for Domain Adaptation: 2021
Dan Iter and David Grangier
- FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue: 2022
Albalak, Alon and Tuan, Yi-Lin and Jandaghi, Pegah... 3 hidden ... Getoor, Lise and Pujara, Jay and Wang, William Yang
- LoRA: Low-Rank Adaptation of Large Language Models: 2022
Edward J Hu and yelong shen and Phillip Wallis... 2 hidden ... Shean Wang and Lu Wang and Weizhu Chen
- Training Subset Selection for Weak Supervision: 2022
Lang, Hunter and Vijayaraghavan, Aravindan and Sontag, David
- On-Demand Sampling: Learning Optimally from Multiple Distributions: 2022
Haghtalab, Nika and Jordan, Michael and Zhao, Eric
- The Trade-offs of Domain Adaptation for Neural Language Models: 2022
Grangier, David and Iter, Dan
- Data Pruning for Efficient Model Pruning in Neural Machine Translation: 2023
Azeemi, Abdul and Qazi, Ihsan and Raza, Agha
- Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models: 2023
Mayee F. Chen and Nicholas Roberts and Kush Bhatia... 1 hidden ... Ce Zhang and Frederic Sala and Christopher Ré
- D2 Pruning: Message Passing for Balancing Diversity and Difficulty in Data Pruning: 2023
Adyasha Maharana and Prateek Yadav and Mohit Bansal
- Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data: 2023
Alon Albalak and Colin Raffel and William Yang Wang
- Efficient Online Data Mixing For Language Model Pre-Training: 2023
Alon Albalak and Liangming Pan and Colin Raffel and William Yang Wang
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors: 2023
Ivison, Hamish and Smith, Noah A. and Hajishirzi, Hannaneh and Dasigi, Pradeep
- Make Every Example Count: On the Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets: 2023
Bejan, Irina and Sokolov, Artem and Filippova, Katja
- LESS: Selecting Influential Data for Targeted Instruction Tuning: 2024
Mengzhou Xia and Sadhika Malladi and Suchin Gururangan and Sanjeev Arora and Danqi Chen
Contribuição
There are likely some amazing works in the field that we missed, so please contribute to the repo.
Feel free to open a pull request with new papers or create an issue and we can add them for you. Thank you in advance for your efforts!
Citação
We hope this work serves as inspiration for many impactful future works. If you found our work useful, please cite this paper as:
@article{albalak2024survey,
title={A Survey on Data Selection for Language Models},
author={Alon Albalak and Yanai Elazar and Sang Michael Xie and Shayne Longpre and Nathan Lambert and Xinyi Wang and Niklas Muennighoff and Bairu Hou and Liangming Pan and Haewon Jeong and Colin Raffel and Shiyu Chang and Tatsunori Hashimoto and William Yang Wang},
year={2024},
journal={arXiv preprint arXiv:2402.16827},
note={url{https://arxiv.org/abs/2402.16827}}
}


