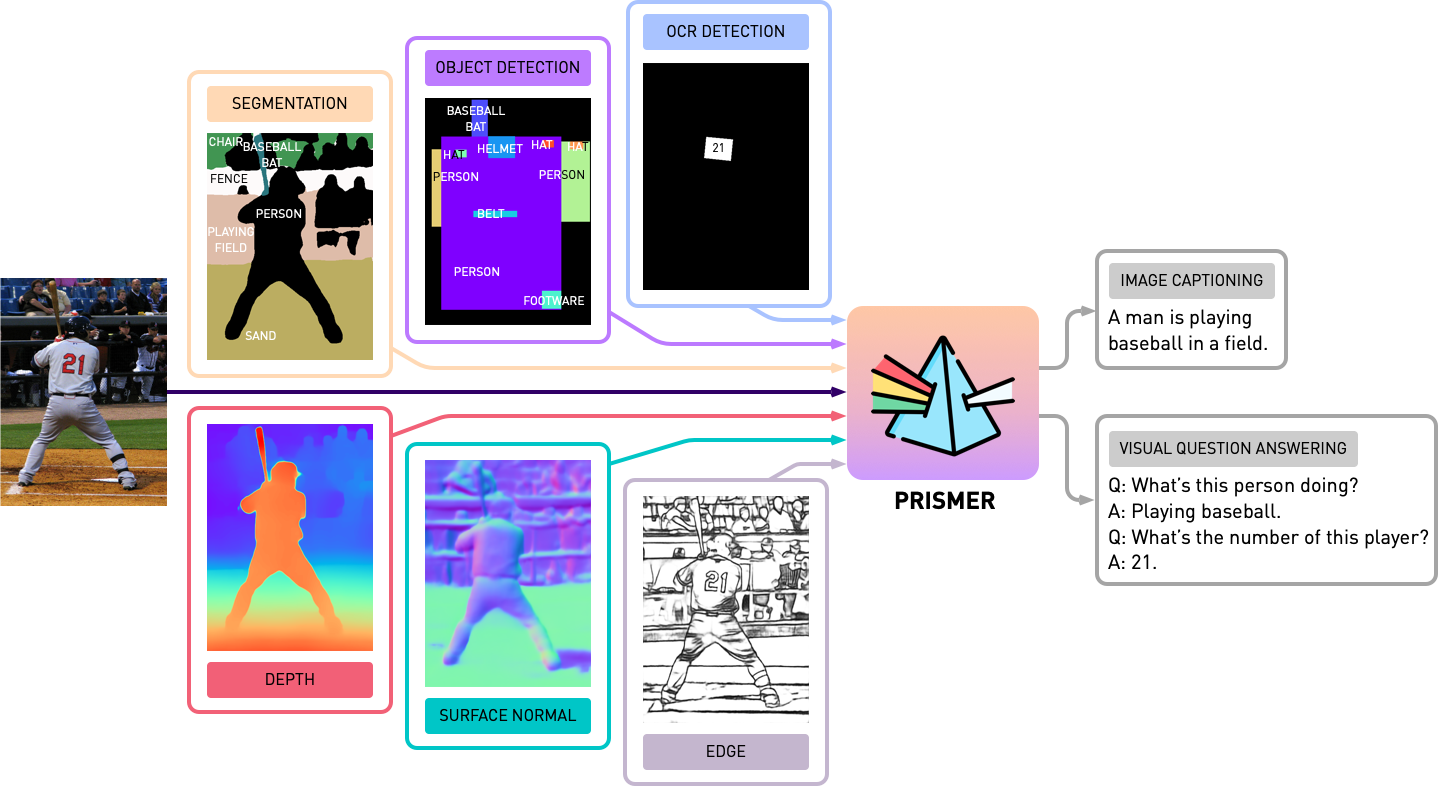
prismer
1.0.0
該存儲庫包含Prismer和Prismerz的源代碼,Prismer:具有多任務專家的視覺語言模型。查看我們在Huggingface Space的正式演示,並在Replicate上查看第三方演示。
transformers軟件包的張量不匹配問題。該實現基於PyTorch 1.13 ,並與HuggingFace accelerate Toolkit高度集成,用於可讀和優化的多節點多GPU培訓。
首先,讓我們通過運行安裝所有軟件包依賴項
pip install -r requirements.txt然後,我們根據您的培訓服務器配置生成相應的accelerate配置。對於單個節點多GPU和多節點的多GPU培訓,只需運行並按照說明進行操作,
accelerate config我們與五個廣泛使用的圖像alt/文本數據集的組合預先培訓Prismer/Prismerz,並提供了以下預先組織的數據列表。
Web數據集(CC3M,SGU,CC12M)由圖像URL組成。強烈建議使用IMG2DATASET,這是一種高度優化的工具包,用於大規模網絡刮擦以下載這些圖像。下面提供了使用img2dataset下載cc12m數據集的示例BASH腳本。
img2dataset --url_list filtered_cc12m.json --input_format " json " --url_col " url " --caption_col " caption " --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256注意:預計下載的圖像的數量小於JSON文件中圖像的數量,因為某些URL可能無效或需要長時間加載時間。
我們在兩個數據集(可可2014年和NOCAPS)上評估圖像字幕性能;和VQAV2數據集上的VQA性能。在VQA任務中,我們還通過視覺基因組質量質量質量質量質量質量質量質量質量質量增加了訓練數據。同樣,我們已經準備好並組織了下面提供的培訓和評估數據列表。
在使用Prismer進行任何實驗之前,我們需要首先預先生成模式專家標籤,因此我們可以構建一個多標籤數據集。在experts文件夾中,我們包括了我們在論文中介紹的所有6個專家。我們已經用共享且簡單的API組織了每個專家的代碼庫。
注意:專門針對細分專家,請首先安裝cd experts/segmentation/mask2former/modeling/pixel_decoder/ops和Run sh make.sh的可變形卷積操作。
要下載預訓練的模式專家,請運行
python download_checkpoints.py --download_experts=True要生成專家標籤,只需編輯configs/experts.yaml
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.py注意:專家標籤生成僅是Prismer模型所必需的,而不是Prismerz模型。
我們已經為Prismer和Prismerz提供了預先訓練的檢查點(用於零照片的圖像字幕),以及VQAV2和COCO數據集的罰款調整檢查點。使用這些檢查點,應期望重現下面列出的確切性能。
| 模型 | 預訓練[零射] | 可可[微調] | VQAV2 [微調] |
|---|---|---|---|
| Prismerz-base | 可可蘋果酒[109.6] | 可可蘋果酒[133.7] | Test-Dev [76.58] |
| Prismer基地 | 可可蘋果酒[122.6] | 可可蘋果酒[135.1] | Test-Dev [76.84] |
| Prismerz-large | 可可蘋果酒[124.8] | 可可蘋果酒[135.7] | Test-Dev [77.49] |
| Prismer-large | 可可蘋果酒[129.7] | 可可蘋果酒[136.5] | Test-Dev [78.42] |
要下載預訓練/罰款的檢查點,請運行
# to download all model checkpoints (12 models in total)
python download_checkpoints.py --download_models=True
# to download specific checkpoints (Prismer-Base for fine-tuned VQA) in this example
python download_checkpoints.py --download_models= " vqa_prismer_base "注意:請記住,要通過sudo apt-get install default-jre安裝java,這是運行官方可可字幕評估腳本所需的。
要評估模型檢查點,請運行
# zero-shot image captioning (remember to remove caption prefix in the config files)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# fine-tuned image captioning
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# fine-tuned VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate要預先培訓或微調任何具有或沒有檢查點的模型,請運行
# to train/fine-tuning from scratch
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# to train/fine-tuning from the latest checkpoints (saved every epoch)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint 我們還通過Pytorch的官方FSDP插件將模型碎片包括在當前培訓腳本中。借助相同的訓練命令,還添加--shard_grad_op for Zero-2 sharding(漸變 +優化器狀態)或--full_shard for-forl_shard for Zero-3 Sharding(Zero-2 +網絡參數)。
注意:您應該期望VQAV2 ACC的錯誤範圍。小於0.1;對於可可/nocaps的蘋果酒評分小於1.0。
最後,我們提供了一個最小的示例,可以使用我們的微調Prismer/Prismerz檢查點在單個GPU中執行圖像字幕。只需將圖像放在helpers/images (支持.jpg , .jpeg和.png圖像)下,然後運行
python demo.py --exp_name {MODEL_NAME}然後,您可以在helpers/labels文件夾中看到所有生成的模式專家標籤以及helpers/images文件夾中生成的字幕。
特別是對於Prismer模型,我們還提供了一個簡單的腳本來使生成的專家標籤貼上。為了使專家標籤及其預測的標題效果和可視化,請運行
python demo_vis.py注意:請記住在configs/caption.yaml演示部分中設置相應的配置。默認的演示模型配置適用於Prismer bas。
如果您發現此代碼/工作在您自己的研究中很有用,請考慮引用以下內容:
@article { liu2024prismer ,
title = { Prismer: A Vision-Language Model with Multi-Task Experts } ,
author = { Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima } ,
journal = { Transactions on Machine Learning Research } ,
year = { 2024 }
}版權所有©2023,Nvidia Corporation。版權所有。
這項工作可根據NVIDIA源代碼許可-NC提供。
模型檢查點在CC-BY-NC-SA-4.0下共享。如果您在材料上進行混音,轉換或構建,則必須在與原件相同的許可下分發捐款。
有關業務查詢,請訪問我們的網站並提交表格:NVIDIA研究許可。
我們要感謝所有開源工作以使該項目成為可能的研究人員。 @bjoernpl用於貢獻自動檢查點下載腳本。
如有任何疑問,請聯繫[email protected] 。


