prismer
1.0.0
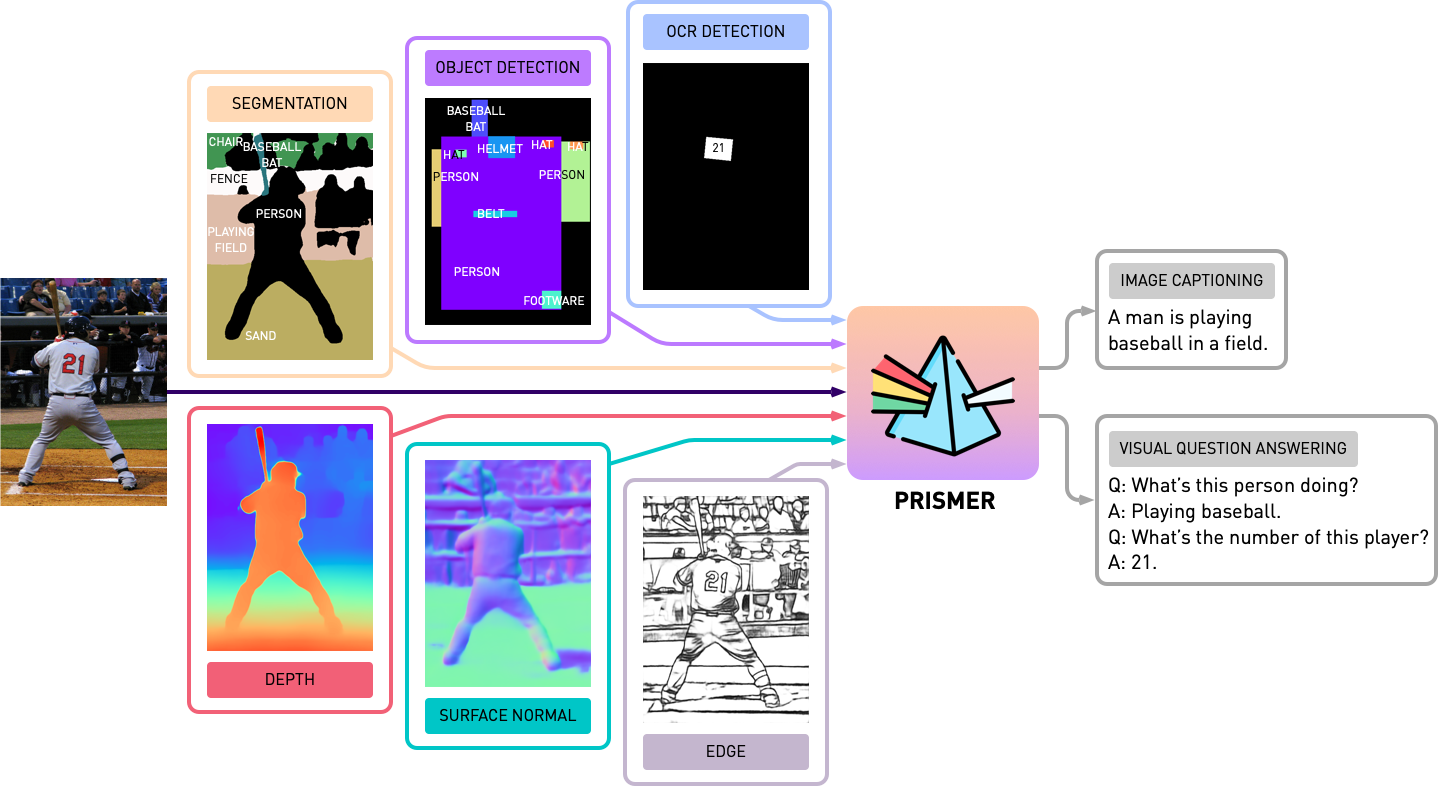
Este repositório contém o código-fonte de Prismer e Prismerz do artigo, Prismer: um modelo de linguagem de visão com especialistas em várias tarefas. Confira nossa demonstração oficial no Hugging Space Space e uma demonstração de terceiros na REPLICACE.
transformers atualizados. A implementação é baseada no PyTorch 1.13 e altamente integrada ao kit de ferramentas accelerate do HuggingFace para treinamento multi-GPU legível e otimizado.
Primeiro, vamos instalar todas as dependências do pacote executando
pip install -r requirements.txt Em seguida, geramos a configuração de accelerate correspondente com base na configuração do seu servidor de treinamento. Para o treinamento multi-GPU e multi-GPU de vários nó, basta executar e seguir as instruções com,
accelerate configPré-trep, Prismer/Prismerz, com uma combinação de cinco conjuntos de dados de imagem/text de imagem/texto amplamente utilizados, com listas de dados pré-organizadas fornecidas abaixo.
Os conjuntos de dados da Web (CC3M, SGU, CC12M) são compostos com URLs de imagem. É altamente recomendável usar o IMG2DataSet, um kit de ferramentas altamente otimizado para raspagem na web em larga escala para baixar essas imagens. Um exemplo de script bash do uso img2dataset para baixar o conjunto de dados cc12m é fornecido abaixo.
img2dataset --url_list filtered_cc12m.json --input_format " json " --url_col " url " --caption_col " caption " --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256Nota: Espera -se que o número de imagens baixadas seja menor que o número de imagens no arquivo JSON, porque alguns URLs podem não ser válidos ou exigir tempo de carregamento longo.
Avaliamos o desempenho da legenda da imagem em dois conjuntos de dados, Coco 2014 e NOCAPS; e desempenho VQA no conjunto de dados VQAV2. Nas tarefas VQA, aumentamos adicionalmente os dados de treinamento com controle de qualidade do genoma visual, seguindo o BLIP. Novamente, preparamos e organizamos as listas de dados de treinamento e avaliação fornecidas abaixo.
Antes de iniciar quaisquer experimentos com o Prismer, precisamos primeiro pré-generalizar os rótulos de especialistas em modalidade, para que possamos construir um conjunto de dados com vários rótulos. Na pasta experts , incluímos todos os 6 especialistas que introduzimos em nosso artigo. Organizamos a base de código de cada especialista com uma API compartilhada e simples.
Nota: Especificamente para especialistas em segmentação, primeiro instale operações deformáveis de convolução por cd experts/segmentation/mask2former/modeling/pixel_decoder/ops e run sh make.sh
Para baixar especialistas em modalidade pré-treinados, execute
python download_checkpoints.py --download_experts=True Para gerar os rótulos de especialistas, basta editar as configs/experts.yaml com os caminhos de dados correspondentes e executar
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.pyNOTA: A geração de etiquetas de especialistas é necessária apenas para modelos Prismer, não para modelos Prismerz.
Fornecemos prismer e prismerz para pontos de verificação pré-treinados (para legendas de imagem com tiro zero), bem como pontos de verificação ajustados nos conjuntos de dados VQAV2 e Coco. Com esses pontos de verificação, deve -se esperar reproduzir o desempenho exato listado abaixo.
| Modelo | Pré-treinado [zero tiro] | Coco [ajustado fino] | VQAV2 [ajustado fino] |
|---|---|---|---|
| Prismerz-Base | Cidra Coco [109.6] | Cidra Coco [133.7] | Test-Dev [76.58] |
| Prismer-Base | Cidra Coco [122.6] | Cidra Coco [135.1] | teste-dev [76,84] |
| Prismerz-Large | Cidra Coco [124.8] | Cidra Coco [135.7] | teste-dev [77.49] |
| Prismer-grande | Cidra Coco [129.7] | Cidra Coco [136.5] | teste-dev [78.42] |
Para baixar pontos de verificação pré-treinados/multados, execute
# to download all model checkpoints (12 models in total)
python download_checkpoints.py --download_models=True
# to download specific checkpoints (Prismer-Base for fine-tuned VQA) in this example
python download_checkpoints.py --download_models= " vqa_prismer_base " NOTA: Lembre-se de instalar o Java via sudo apt-get install default-jre , que é necessário para executar os scripts oficiais de avaliação de legendas de coco.
Para avaliar os pontos de verificação do modelo, execute
# zero-shot image captioning (remember to remove caption prefix in the config files)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# fine-tuned image captioning
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# fine-tuned VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluatePara pré-treinar ou ajustar qualquer modelo com ou sem postos de controle, execute
# to train/fine-tuning from scratch
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# to train/fine-tuning from the latest checkpoints (saved every epoch)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint Também incluímos sharding modelo no script de treinamento atual através do plug -in oficial do FSDP da Pytorch. Com os mesmos comandos de treinamento, adicione adicionalmente --shard_grad_op para sharding zero-2 (gradientes + estados do otimizador) ou --full_shard para zero-3 sharding (parâmetros de rede zero-2 +).
NOTA: Você deve esperar o intervalo de erros do VQAV2 ACC. ser menor que 0,1; Para a pontuação da cidra Coco/Nocaps, seja menor que 1,0.
Por fim, oferecemos um exemplo mínimo para executar a legenda da imagem em uma única GPU com nosso ponto de verificação Prismer/Prismerz ajustado. Basta colocar suas imagens em helpers/images (suportar imagens .jpg , .jpeg e .png ) e executar
python demo.py --exp_name {MODEL_NAME} Você pode ver todos os rótulos de especialistas em modalidade gerada na pasta helpers/labels e as legendas geradas na pasta helpers/images .
Particularmente para os modelos Prismer, também oferecemos um script simples para prettificar os rótulos de especialistas gerados. Pretificar e visualizar os rótulos de especialistas e suas legendas previstas, execute
python demo_vis.py NOTA: Lembre -se de configurar a configuração correspondente na seção de demonstração configs/caption.yaml . A configuração do modelo de demonstração padrão é para prismer-Base.
Se você encontrou este código/trabalho para ser útil em sua própria pesquisa, considerando citar o seguinte:
@article { liu2024prismer ,
title = { Prismer: A Vision-Language Model with Multi-Task Experts } ,
author = { Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima } ,
journal = { Transactions on Machine Learning Research } ,
year = { 2024 }
}Copyright © 2023, Nvidia Corporation. Todos os direitos reservados.
Este trabalho é disponibilizado sob a NVIDIA Source Code License-NC.
Os pontos de verificação do modelo são compartilhados em CC-BY-NC-SA-4.0. Se você remixar, transformar ou desenvolver o material, deverá distribuir suas contribuições sob a mesma licença que a original.
Para consultas de negócios, visite nosso site e envie o formulário: licenciamento de pesquisa da NVIDIA.
Gostaríamos de agradecer a todos os pesquisadores que abrem seus trabalhos para tornar esse projeto possível. @BJoernpl para contribuir com um script de download automatizado de ponto de verificação.
Se você tiver alguma dúvida, entre em contato com [email protected] .


