prismer
1.0.0
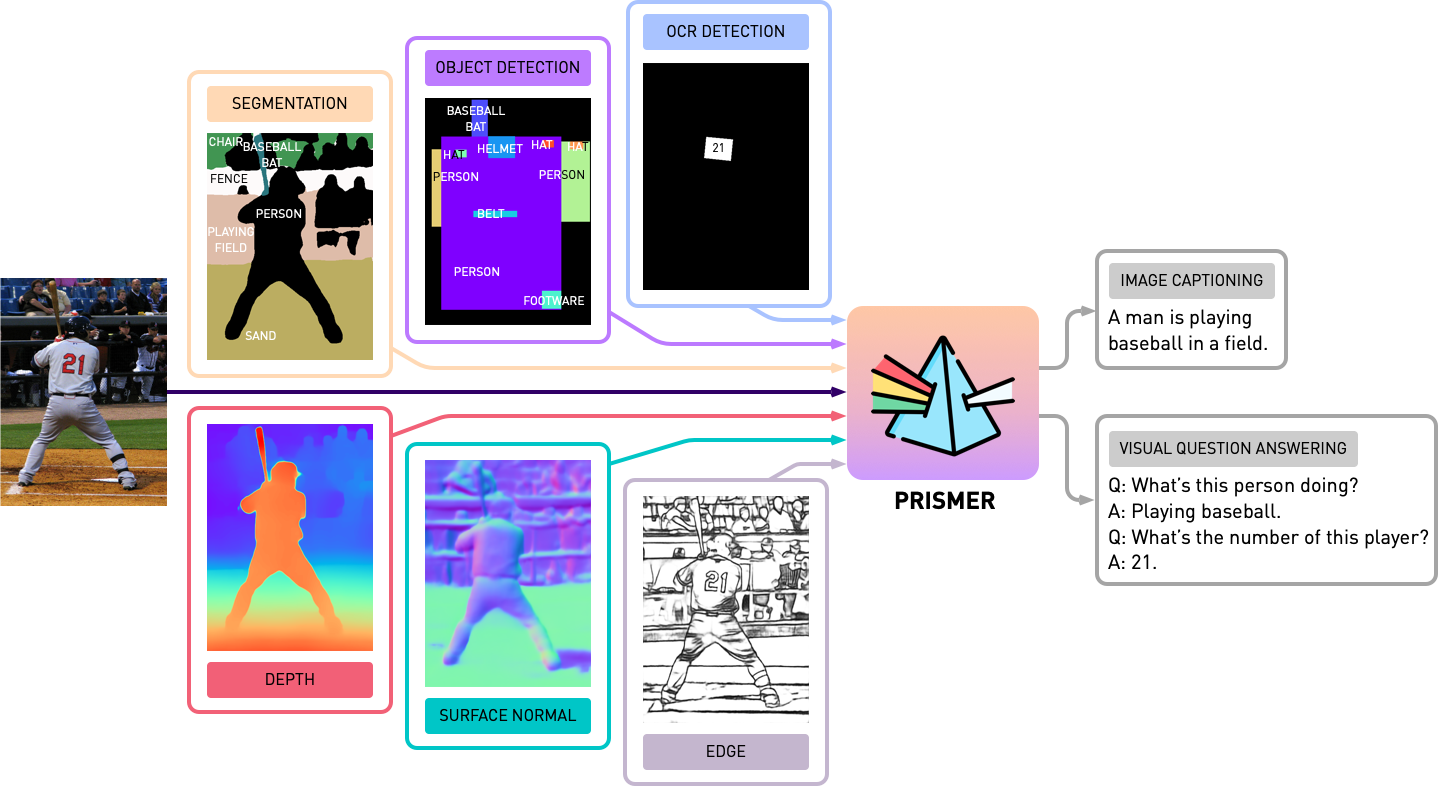
Este repositorio contiene el código fuente de Prismer y Prismerz del documento, Prismer: un modelo en idioma de visión con expertos en varias tareas. Echa un vistazo a nuestra demostración oficial en Huggingface Space y una demostración de terceros en Replicate.
transformers actualizado. La implementación se basa en PyTorch 1.13 y altamente integrada con Huggingface accelerate Toolkit para capacitación multi-GPU de nodos legible y optimizado.
Primero, instalemos todas las dependencias de paquetes ejecutando
pip install -r requirements.txt Luego generamos la configuración de accelerate correspondiente basada en la configuración de su servidor de entrenamiento. Tanto para el entrenamiento multi-GPU de un solo nodo como para el entrenamiento de múltiples nodos múltiples, simplemente ejecute y siga las instrucciones con,
accelerate configPre-entrenamos Prismer/Prismerz con una combinación de cinco conjuntos de datos de imágenes/texto ampliamente utilizados, con listas de datos preorganizadas que se proporcionan a continuación.
Los conjuntos de datos web (CC3M, SGU, CC12M) están compuestos con URL de imagen. Se recomienda usar IMG2Dataset, un kit de herramientas altamente optimizado para el raspado web a gran escala para descargar estas imágenes. A continuación se proporciona un script de ejemplo de BASH de usar img2dataset para descargar el conjunto de datos cc12m .
img2dataset --url_list filtered_cc12m.json --input_format " json " --url_col " url " --caption_col " caption " --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256Nota: Se espera que el número de imágenes descargadas sea menor que el número de imágenes en el archivo JSON, porque algunas URL pueden no ser válidas o requerir un tiempo de carga largo.
Evaluamos el rendimiento de subtítulos de imágenes en dos conjuntos de datos, Coco 2014 y Nocaps; y el rendimiento de VQA en el conjunto de datos VQAV2. En las tareas de VQA, también aumentamos los datos de entrenamiento con el Genoma Visual Genome QA, después de BLIP. Nuevamente, hemos preparado y organizado las listas de datos de capacitación y evaluación que se proporcionan a continuación.
Antes de comenzar cualquier experimento con Prismer, primero necesitamos pregenerar las etiquetas de expertos en modalidad, por lo que podemos construir un conjunto de datos de etiqueta múltiple. En la carpeta experts , hemos incluido los 6 expertos que presentamos en nuestro artículo. Hemos organizado la base de código de cada experto con una API compartida y simple.
Nota: Específicamente para expertos en segmentación, primero instale operaciones de convolución deformables por cd experts/segmentation/mask2former/modeling/pixel_decoder/ops y ejecute sh make.sh
Para descargar expertos en modalidad previamente capacitados, ejecute
python download_checkpoints.py --download_experts=True Para generar las etiquetas de expertos, simplemente edite las configs/experts.yaml con las rutas de datos correspondientes y ejecute
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.pyNota: La generación de etiquetas expertas solo se requiere para los modelos Prismer, no para los modelos Prismerz.
Hemos proporcionado tanto a Prismer como Prismerz para los puntos de control previamente capacitados (para subtítulos de imágenes de disparo cero), así como puntos de control ajustados en VQAV2 y conjuntos de datos de Coco. Con estos puntos de control, se espera que reproduzca el rendimiento exacto que se enumera a continuación.
| Modelo | Pretratado [cero-shot] | Coco [ajustado] | VQAV2 [ajustado] |
|---|---|---|---|
| Base prismerz | Coco sidra [109.6] | Coco sidra [133.7] | prueba-dev [76.58] |
| Base prismer | Cidra de coco [122.6] | Coco sidra [135.1] | prueba-dev [76.84] |
| Prismerz-larga | Coco sidra [124.8] | Coco sidra [135.7] | prueba-dev [77.49] |
| Prismer-grande | COCO CIDER [129.7] | Coco sidra [136.5] | prueba-dev [78.42] |
Para descargar puntos de control previamente capacitados/sintonizados, ejecutar
# to download all model checkpoints (12 models in total)
python download_checkpoints.py --download_models=True
# to download specific checkpoints (Prismer-Base for fine-tuned VQA) in this example
python download_checkpoints.py --download_models= " vqa_prismer_base " NOTA: Recuerde instalar Java a través de sudo apt-get install default-jre que se requiere para ejecutar los scripts oficiales de evaluación de subtítulos.
Para evaluar los puntos de control del modelo, ejecute
# zero-shot image captioning (remember to remove caption prefix in the config files)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# fine-tuned image captioning
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# fine-tuned VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluatePara pre-entrengar o ajustar cualquier modelo con o sin puntos de control, ejecute
# to train/fine-tuning from scratch
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# to train/fine-tuning from the latest checkpoints (saved every epoch)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint También hemos incluido el fragmento de modelos en el script de capacitación actual a través del complemento FSDP oficial de Pytorch. Con los mismos comandos de entrenamiento, agregue adicionalmente --shard_grad_op para fragmentos cero-2 (gradientes + estados optimizadores), o --full_shard para cero-3 fragmentos (parámetros de red cero-2 +).
Nota: debe esperar el rango de error para VQAV2 ACC. ser menos de 0.1; para que la puntuación de sidra Coco/Nocaps sea inferior a 1.0.
Finalmente, hemos ofrecido un ejemplo mínimo para realizar subtítulos en una sola GPU con nuestro punto de control Prismer/Prismerz sintonizado. Simplemente coloque sus imágenes en helpers/images (soporte .jpg , .jpeg y .png imágenes), y ejecute
python demo.py --exp_name {MODEL_NAME} Luego puede ver todas las etiquetas de expertos en modalidad generadas en la carpeta de helpers/labels y los subtítulos generados en la carpeta de helpers/images .
Particularmente para los modelos Prismer, también hemos ofrecido un script simple para pretificar las etiquetas de expertos generadas. Para pretificar y visualizar las etiquetas expertas, así como sus subtítulos predichos, ejecutar
python demo_vis.py NOTA: Recuerde configurar la configuración correspondiente en la sección configs/caption.yaml Demo. La configuración de modelo de demostración predeterminada es para Prismer-Base.
Si encontró que este código/trabajo es útil en su propia investigación, considere citar lo siguiente:
@article { liu2024prismer ,
title = { Prismer: A Vision-Language Model with Multi-Task Experts } ,
author = { Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima } ,
journal = { Transactions on Machine Learning Research } ,
year = { 2024 }
}Copyright © 2023, Nvidia Corporation. Reservados todos los derechos.
Este trabajo está disponible bajo la licencia del código fuente NVIDIA-NC.
Los puntos de control del modelo se comparten en CC-by-NC-SA-4.0. Si remezcla, transforma o se basa en el material, debe distribuir sus contribuciones bajo la misma licencia que la original.
Para consultas comerciales, visite nuestro sitio web y envíe el formulario: Licencias de investigación de NVIDIA.
Nos gustaría agradecer a todos los investigadores que están abiertos sus trabajos para hacer posible este proyecto. @BJoERNPL para contribuir con un script de descarga automatizada de punto de control.
Si tiene alguna pregunta, comuníquese con [email protected] .


