prismer
1.0.0
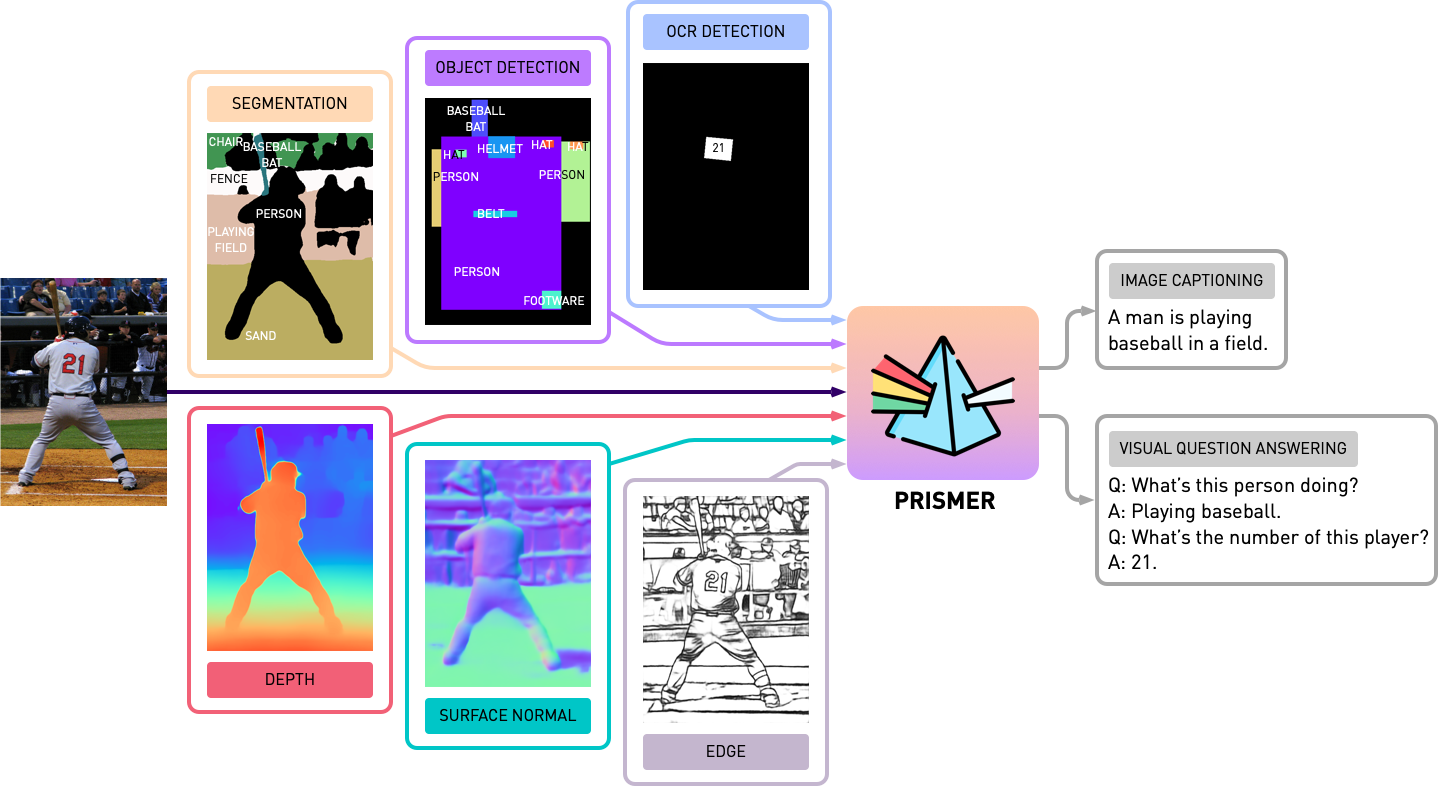
Ce référentiel contient le code source de Prismer et Prismerz de l'article, Prismer: un modèle de vision en langue avec des experts multi-tâches. Découvrez notre démo officielle dans HuggingFace Space et une démo tierce à la réplique.
transformers mis à jour. L'implémentation est basée sur PyTorch 1.13 et hautement intégrée à la boîte à outils accelerate HuggingFace pour une formation multi-GPU lisible et optimisable.
Tout d'abord, installons toutes les dépendances du package en exécutant
pip install -r requirements.txt Ensuite, nous générons la configuration accelerate correspondante en fonction de la configuration de votre serveur de formation. Pour une formation multi-GPU multi-GPU et multi-nœuds et multi-nœuds, exécutez simplement et suivez les instructions avec,
accelerate configNous pré-entraînons Prismer / Prismerz avec une combinaison de cinq ensembles de données d'image-ALT / Texte largement utilisés, avec des listes de données pré-organisées fournies ci-dessous.
Les ensembles de données Web (CC3M, SGU, CC12M) sont composés avec des URL d'image. Il est fortement recommandé d'utiliser IMG2DATASET, une boîte à outils hautement optimisée pour le grattage Web à grande échelle pour télécharger ces images. Un exemple de script bash de l'utilisation img2dataset pour télécharger un ensemble de données cc12m est fourni ci-dessous.
img2dataset --url_list filtered_cc12m.json --input_format " json " --url_col " url " --caption_col " caption " --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256Remarque: Il est prévu que le nombre d'images téléchargées soit inférieure au nombre d'images dans le fichier JSON, car certaines URL peuvent ne pas être valides ou nécessiter un temps de chargement long.
Nous évaluons les performances de sous-titrage de l'image sur deux ensembles de données, Coco 2014 et NOCAPS; et les performances VQA sur l'ensemble de données VQav2. Dans les tâches VQA, nous augmentons en outre les données de formation avec le génome visuel QA, après BLIP. Encore une fois, nous avons préparé et organisé les listes de données de formation et d'évaluation fournies ci-dessous.
Avant de démarrer des expériences avec Prismer, nous devons d'abord générer les étiquettes d'experts de la modalité, nous pouvons donc construire un ensemble de données multi-étiquettes. Dans le dossier experts , nous avons inclus les 6 experts que nous avons introduits dans notre article. Nous avons organisé la base de code de chaque expert avec une API partagée et simple.
Remarque: spécifiquement pour les experts de la segmentation, veuillez d'abord installer des opérations de convolution déformable par cd experts/segmentation/mask2former/modeling/pixel_decoder/ops et run sh make.sh
Pour télécharger des experts en modalité pré-formés, exécuter
python download_checkpoints.py --download_experts=True Pour générer les étiquettes d'experts, modifiez simplement les configs/experts.yaml
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.pyRemarque: la génération d'étiquettes d'experts n'est requise que pour les modèles Prismer, pas pour les modèles Prismerz.
Nous avons fourni à la fois Prismer et Prismerz pour les points de contrôle pré-formés (pour le sous-titrage de l'image), ainsi que les points de contrôle à réglage amendé sur les ensembles de données VQav2 et CoCo. Avec ces points de contrôle, il faut s'attendre à ce qu'il reproduire les performances exactes énumérées ci-dessous.
| Modèle | Pré-formé [zéro-shot] | Coco [affiné] | VQav2 [affinés] |
|---|---|---|---|
| Bassin de prismerz | Cidre de coco [109.6] | Cidre de coco [133,7] | Test-DEV [76.58] |
| Bassin de prison | Cidre de coco [122,6] | Cidre de coco [135.1] | Test-DEV [76.84] |
| Primaire | Cidre de coco [124.8] | Cidre de coco [135.7] | Test-DEV [77.49] |
| Primaire | Cidre de coco [129.7] | Cidre de coco [136.5] | Test-DEV [78.42] |
Pour télécharger des points de contrôle pré-formés / amendés, exécutez
# to download all model checkpoints (12 models in total)
python download_checkpoints.py --download_models=True
# to download specific checkpoints (Prismer-Base for fine-tuned VQA) in this example
python download_checkpoints.py --download_models= " vqa_prismer_base " Remarque: N'oubliez pas d'installer Java via sudo apt-get install default-jre qui est nécessaire pour exécuter les scripts officiels d'évaluation de la légende CoCo.
Pour évaluer les points de contrôle du modèle, veuillez exécuter
# zero-shot image captioning (remember to remove caption prefix in the config files)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# fine-tuned image captioning
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# fine-tuned VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluatePour pré-entraîner ou affiner n'importe quel modèle avec ou sans points de contrôle, veuillez exécuter
# to train/fine-tuning from scratch
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# to train/fine-tuning from the latest checkpoints (saved every epoch)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint Nous avons également inclus le fragment des modèles dans le script de formation actuel via le plugin FSDP officiel de Pytorch. Avec les mêmes commandes de formation, ajoutez en outre --shard_grad_op pour le sharding zéro-2 (gradients + états d'optimisation), ou --full_shard pour zéro-3 sharding (paramètres de réseau zéro-2 +).
Remarque: vous devez vous attendre à la plage d'erreur pour VQav2 ACC. être inférieur à 0,1; Pour le score de cidre Coco / Nocaps à moins de 1,0.
Enfin, nous avons offert un exemple minimal pour effectuer un sous-titrage d'image dans un seul GPU avec notre point de contrôle Prismer / Prismerz réglé. Mettez simplement vos images sous helpers/images (support .jpg , .jpeg et .png images) et exécuter
python demo.py --exp_name {MODEL_NAME} Vous pouvez ensuite voir toutes les étiquettes d'experts de modalité générées dans le dossier helpers/labels et des légendes générées dans le dossier helpers/images .
En particulier pour les modèles Prismer, nous avons également proposé un script simple pour empêcher les étiquettes d'experts générées. Pour brasser et visualiser les étiquettes d'experts ainsi que ses légendes prévues, exécuter
python demo_vis.py Remarque: N'oubliez pas de configurer la configuration correspondante dans la section de démonstration configs/caption.yaml . La configuration du modèle de démonstration par défaut est pour la base de prismer.
Si vous avez trouvé ce code / travail utile dans vos propres recherches, veuillez envisager de citer ce qui suit:
@article { liu2024prismer ,
title = { Prismer: A Vision-Language Model with Multi-Task Experts } ,
author = { Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima } ,
journal = { Transactions on Machine Learning Research } ,
year = { 2024 }
}Copyright © 2023, Nvidia Corporation. Tous droits réservés.
Ce travail est mis à disposition dans le cadre de la licence de code source NVIDIA-NC.
Les points de contrôle du modèle sont partagés sous CC-BY-NC-SA-4.0. Si vous remixez, transformez ou s'appuyez sur le matériel, vous devez distribuer vos contributions sous la même licence que l'original.
Pour les demandes commerciales, veuillez visiter notre site Web et soumettre le formulaire: NVIDIA Research Licensing.
Nous tenons à remercier tous les chercheurs qui ont ouvert leurs œuvres pour rendre ce projet possible. @bjoernpl pour avoir contribué un script de téléchargement de point de contrôle automatisé.
Si vous avez des questions, veuillez contacter [email protected] .


