prismer
1.0.0
Dieses Repository enthält den Quellcode von Prismer und Prismerz aus dem Papier, Prismer: Ein visuelles Modell mit Multitask-Experten. Schauen Sie sich unsere offizielle Demo in Huggingface Space und eine Demo von Drittanbietern bei Replicate an.
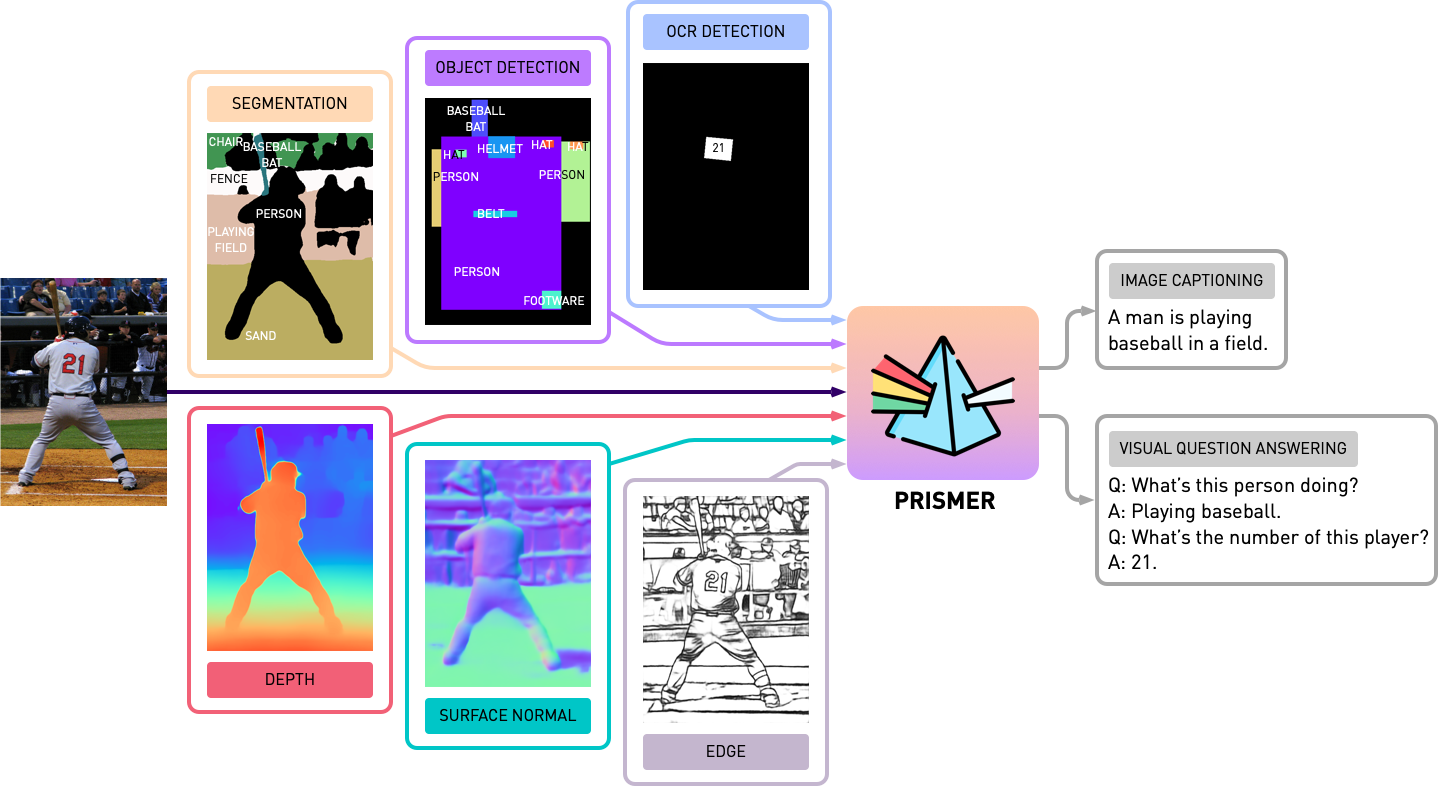
transformers -Paket. Die Implementierung basiert auf PyTorch 1.13 und in stark integriertem Integration in das Huggingface- accelerate -Toolkit für lesbare und optimierte Multi-Node-Multi-GPU-Schulungen.
Lassen Sie uns zunächst alle Paketabhängigkeiten durch Ausführen installieren
pip install -r requirements.txt Anschließend generieren wir die entsprechende accelerate basierend auf Ihrer Trainingsserverkonfiguration. Führen Sie einfach für Multi-GPU- und Multi-Knoten-Multi-GPU-Schulungen für ein Knoten ein und befolgen Sie die Anweisungen mit.
accelerate configWir haben Prismer/Prismerz mit einer Kombination aus fünf weit verbreiteten Bild-Alt-/Text-Datensätzen mit vororganisierten Datenlisten.
Die Webdatensätze (CC3M, SGU, CC12M) sind mit Bild -URLs komponiert. Es wird dringend empfohlen, IMG2Dataset zu verwenden, ein hoch optimiertes Toolkit für groß angelegte Web-Scraping, um diese Bilder herunterzuladen. Ein Beispiel -Bash -Skript für die Verwendung von img2dataset zum Herunterladen cc12m -Datensatz ist unten angegeben.
img2dataset --url_list filtered_cc12m.json --input_format " json " --url_col " url " --caption_col " caption " --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256Hinweis: Es wird erwartet, dass die Anzahl der heruntergeladenen Bilder geringer ist als die Anzahl der Bilder in der JSON -Datei, da einige URLs möglicherweise nicht gültig sind oder eine lange Ladezeit erfordern.
Wir bewerten die Bildunterschriftenleistung auf zwei Datensätzen, Coco 2014 und Nocaps. und VQA -Leistung auf VQAV2 -Datensatz. Bei VQA -Aufgaben erweitern wir die Trainingsdaten mit visuellem Genom -QA nach Blip. Auch hier haben wir die unten angegebenen Schulungs- und Bewertungsdatenlisten vorbereitet und organisiert.
Bevor wir Experimente mit Prismer beginnen, müssen wir zunächst die Modalitätsexperten-Etiketten vor generieren, damit wir einen Multi-Label-Datensatz erstellen können. Im experts -Ordner haben wir alle 6 Experten aufgenommen, die wir in unser Papier eingeführt haben. Wir haben die Codebasis jedes Experten mit einer gemeinsamen und einfachen API organisiert.
HINWEIS: Installieren Sie speziell für Segmentierungsexperten zuerst verformbare Faltungsvorgänge nach cd experts/segmentation/mask2former/modeling/pixel_decoder/ops und run sh make.sh
Zum Herunterladen von Experten vor ausgebildeter Modalität leiten Sie
python download_checkpoints.py --download_experts=True Um die Expertenbezeichnungen zu generieren, bearbeiten Sie einfach die configs/experts.yaml mit den entsprechenden Datenpfaden und führen Sie aus
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.pyHinweis: Die Experten -Etikettengenerierung ist nur für Prismer -Modelle erforderlich, nicht für Prismerz -Modelle.
Wir haben sowohl Prismer als auch Prismerz für vorgebreitete Checkpoints (für die Bildunterschriften mit Null-Shot-Bild) sowie für Geldbuße auf VQAV2- und Coco-Datensätze mit Geldbuße abgestimmt. Bei diesen Kontrollpunkten ist zu erwarten, dass die genau unten aufgeführte genaue Leistung reproduziert.
| Modell | Vorgebildet [Null-Shot] | Coco [Feinabstimmung] | VQAV2 [Feinabstimmung] |
|---|---|---|---|
| Prismerz-Base | Coco Cider [109,6] | Coco Cider [133.7] | Test-dev [76.58] |
| Prismer-Base | Coco Cider [122.6] | Coco Cider [135.1] | Test-dev [76,84] |
| Prismerz-large | Coco Cider [124.8] | Coco Cider [135.7] | Test-dev [77.49] |
| Prismer-large | Coco Cider [129.7] | Coco Cider [136.5] | Test-dev [78.42] |
Zum Herunterladen von vorgeborenen/Geldbuße abgestimmt
# to download all model checkpoints (12 models in total)
python download_checkpoints.py --download_models=True
# to download specific checkpoints (Prismer-Base for fine-tuned VQA) in this example
python download_checkpoints.py --download_models= " vqa_prismer_base " HINWEIS: Denken Sie daran, Java über sudo apt-get install default-jre , um die offiziellen Coco-Bildunterschriftenbewertungsskripte auszuführen.
Um die Modellkontrollpunkte zu bewerten, rennen Sie bitte
# zero-shot image captioning (remember to remove caption prefix in the config files)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# fine-tuned image captioning
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# fine-tuned VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluateUm ein Modell mit oder ohne Checkpoints vorzuziehen oder zu optimieren, reiten Sie bitte aus
# to train/fine-tuning from scratch
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# to train/fine-tuning from the latest checkpoints (saved every epoch)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint Wir haben auch Modell Sharding in das aktuelle Trainingsskript über das offizielle FSDP -Plugin von Pytorch aufgenommen. Fügen Sie mit denselben Trainingsbefehlungen zusätzlich --shard_grad_op für Zero-2 Sharding (Gradienten + Optimiererzustände) oder --full_shard für Zero-3 Sharding (Null-2 + -Netzwerkparameter) hinzu.
Hinweis: Sie sollten den Fehlerbereich für VQAV2 ACC erwarten. weniger als 0,1 sein; Damit Coco/Nocaps -Cider -Score weniger als 1,0 beträgt.
Schließlich haben wir ein minimales Beispiel für die Durchführung von Bildunterschriften in einer einzelnen GPU mit unserem fein abgestimmten Prismer/Prisronz-Checkpoint angeboten. Setzen Sie einfach Ihre Bilder unter helpers/images (Support .jpg , .jpeg und .png Bilder) und führen Sie aus
python demo.py --exp_name {MODEL_NAME} Anschließend können Sie alle generierten Modalitätsexperten im Ordner helpers/labels und die generierten Bildunterschriften im Ordner helpers/images sehen.
Insbesondere für die Prismer -Modelle haben wir auch ein einfaches Skript angeboten, um die generierten Expertenetiketten zu tun. Laufen
python demo_vis.py Hinweis: Denken Sie daran, die entsprechende Konfiguration im Abschnitt configs/caption.yaml Demo einzurichten. Die Standard-Demo-Modellkonfiguration ist für Prismer-Base.
Wenn Sie festgestellt haben, dass dieser Code/diese Arbeit in Ihrer eigenen Forschung nützlich ist, sollten Sie Folgendes in Betracht ziehen:
@article { liu2024prismer ,
title = { Prismer: A Vision-Language Model with Multi-Task Experts } ,
author = { Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima } ,
journal = { Transactions on Machine Learning Research } ,
year = { 2024 }
}Copyright © 2023, Nvidia Corporation. Alle Rechte vorbehalten.
Diese Arbeit wird im Rahmen der NVIDIA-Quellcode-Lizenz-NC zur Verfügung gestellt.
Die Modell-Checkpoints werden unter CC-by-nc-sa4.0 geteilt. Wenn Sie das Material remix, transformieren oder aufbauen, müssen Sie Ihre Beiträge unter derselben Lizenz wie das Original verteilen.
Für geschäftliche Anfragen besuchen Sie bitte unsere Website und senden Sie das Formular: NVIDIA Research Lizenzierung.
Wir möchten uns bei allen Forschern bedanken, die ihre Arbeiten für dieses Projekt ermöglichen. @bjoernpl zum Beitrag eines automatisierten Checkpoint -Download -Skripts.
Wenn Sie Fragen haben, wenden Sie sich bitte an [email protected] .


