prismer
1.0.0
Этот репозиторий содержит исходный код Prismer и Prismerz из статьи, Prismer: модель на языке зрения с экспертами с несколькими задачами. Проверьте нашу официальную демонстрацию в Space uggingface и стороннюю демонстрацию в Replicate.
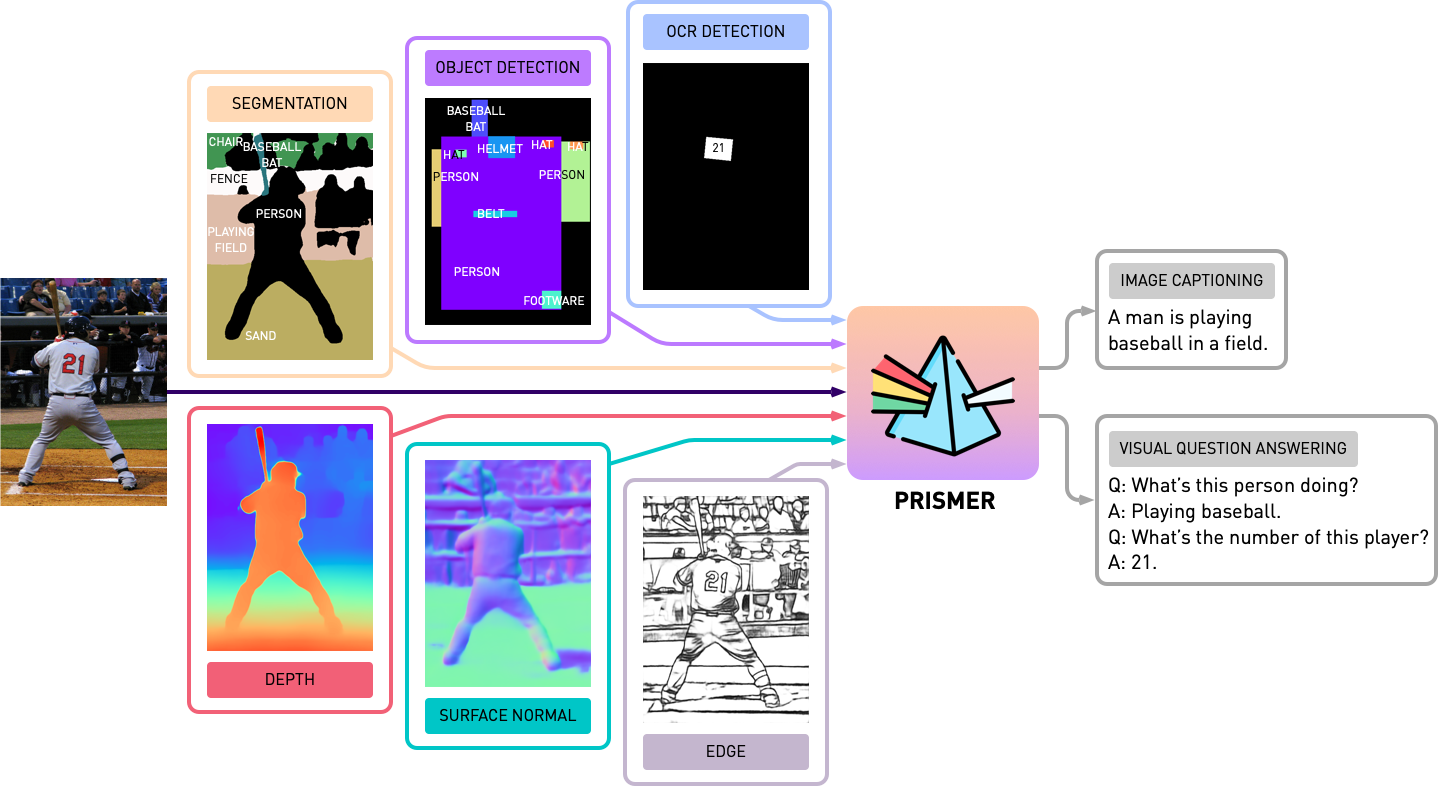
transformers . Реализация основана на PyTorch 1.13 и сильно интегрирована с инструментарием accelerate HuggingFace для читаемого и оптимизированного многоузвучного обучения с несколькими GPU.
Во -первых, давайте установим все зависимости от пакетов, запустив
pip install -r requirements.txt Затем мы генерируем соответствующую конфигурацию accelerate на основе конфигурации вашего обучающего сервера. Как для однокно-мульти-GPU, так и для мульти-GPU обучения, просто запустите и следуйте инструкциям с,
accelerate configМы готовим Prismer/Prismerz с комбинацией из пяти широко используемых наборов данных Image-Alt/Text, с предварительно организованными списками данных, представленными ниже.
Веб -данные (CC3M, SGU, CC12M) состоит из URL -адресов изображения. Настоятельно рекомендуется использовать IMG2Dataset, высоко оптимизированный инструментарий для крупномасштабного сетевого соскоба для загрузки этих изображений. Пример Bash Script of Использования img2dataset для загрузки набора данных cc12m представлен ниже.
img2dataset --url_list filtered_cc12m.json --input_format " json " --url_col " url " --caption_col " caption " --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256Примечание. Ожидается, что количество загруженных изображений меньше количества изображений в файле JSON, потому что некоторые URL -адреса могут быть недопустимыми или потребовать длительного времени загрузки.
Мы оцениваем производительность подписания изображения на двух наборах данных, Coco 2014 и NOCAPS; и производительность VQA в наборе данных VQAV2. В задачах VQA мы дополнительно увеличиваем учебные данные с помощью QA Visual Genome, после BLIP. Опять же, мы подготовили и организовали списки данных обучения и оценки, представленные ниже.
Перед началом каких-либо экспериментов с Prismer мы должны сначала предварительно генерировать этикетки экспертов по модальности, чтобы мы могли построить многопользовательский набор данных. В папку experts мы включили все 6 экспертов, которые мы представили в нашу статью. Мы организовали кодовую базу каждого эксперта с общим и простым API.
Примечание. Специально для экспертов по сегментации, сначала установите деформируемые операции свертки cd experts/segmentation/mask2former/modeling/pixel_decoder/ops и запуск sh make.sh
Чтобы загрузить предварительно обученные эксперты по модальности, запустить
python download_checkpoints.py --download_experts=True Чтобы сгенерировать этикетки экспертов, просто отредактируйте configs/experts.yaml с соответствующими путями данных и запустите
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.pyПримечание: генерация экспертных ярлыков требуется только для моделей Prismer, а не для моделей Prismerz.
Мы предоставили как Prismer, так и Prismerz для предварительно обученных контрольных точек (для подписания с нулевым выстрелом), а также штрафные контрольные точки на наборах данных VQAV2 и COCO. С этими контрольно -пропускными пунктами следует ожидать, что это будет воспроизвести точную производительность, перечисленную ниже.
| Модель | Предварительно обучен [нулевой выстрел] | Коко [тонко настроенный] | Vqav2 [тонко настроенный] |
|---|---|---|---|
| Prismerz-Base | Коко -сидр [109,6] | Коко -сидр [133,7] | ТЕСТ-ДЕВ [76.58] |
| База-база | Coco Cider [122.6] | Коко Сидр [135.1] | ТЕСТ-ДЕВ [76.84] |
| Prismerz-Large | Коко Сидр [124.8] | Коко -сидр [135,7] | ТЕСТ-ДЕВ [77.49] |
| ПРИСМЕР-ЛАРЖ | Коко -сидр [129,7] | Coco Cider [136.5] | ТЕСТ-ДЕВ [78.42] |
Чтобы загрузить предварительно обученные/штрафные контрольные точки, запустить
# to download all model checkpoints (12 models in total)
python download_checkpoints.py --download_models=True
# to download specific checkpoints (Prismer-Base for fine-tuned VQA) in this example
python download_checkpoints.py --download_models= " vqa_prismer_base " Примечание. Не забудьте установить Java через sudo apt-get install default-jre , который необходим для запуска официальных сценариев оценки подписи Coco.
Чтобы оценить модель контрольно -пропускных пунктов, пожалуйста, запустите
# zero-shot image captioning (remember to remove caption prefix in the config files)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# fine-tuned image captioning
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# fine-tuned VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluateЧтобы предварительно тренировать или настраивать любую модель с или без контрольных точек, пожалуйста, запустите
# to train/fine-tuning from scratch
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# to train/fine-tuning from the latest checkpoints (saved every epoch)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint Мы также включили модель Sharding в текущий учебный сценарий через официальный плагин FSDP от Pytorch. С теми же командами обучения, дополнительно добавьте --shard_grad_op для Zero-2 Sharding (градиенты + состояния оптимизатора) или --full_shard для Sharding Zero-3 (параметры сети Zero-2 +).
Примечание. Вы должны ожидать диапазона ошибок для VQAV2 ACC. быть менее 0,1; Для балла сидра Coco/NOCAPS будет менее 1,0.
Наконец, мы предложили минимальный пример для выполнения подписания изображения в одном графическом процессоре с нашим тонким настраиваемым Prismer/Prismerz Checkpoint. Проще говоря, поместите свои изображения под helpers/images (поддержка .jpg , .jpeg и .png Images) и запустить
python demo.py --exp_name {MODEL_NAME} Затем вы можете увидеть все сгенерированные маркировки экспертов модальности в папке helpers/labels и сгенерированные подписи в папке helpers/images .
В частности, для моделей Prismer, мы также предложили простой сценарий, чтобы предварительно определить сгенерированные экспертные этикетки. Чтобы приточить и визуализировать экспертные этикетки, а также предсказанные подписи, запустите
python demo_vis.py Примечание. Не забудьте настроить соответствующую конфигурацию в демо -разделе configs/caption.yaml . Конфигурация демо-модели по умолчанию предназначена для Prismer-Base.
Если вы обнаружили, что этот код/работа будет полезна в собственном исследовании, пожалуйста, рассмотрим следующее:
@article { liu2024prismer ,
title = { Prismer: A Vision-Language Model with Multi-Task Experts } ,
author = { Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima } ,
journal = { Transactions on Machine Learning Research } ,
year = { 2024 }
}Copyright © 2023, Nvidia Corporation. Все права защищены.
Эта работа предоставляется в соответствии с лицензией NVIDIA Source Code-NC.
Модель контрольно-пропускные пункты разделяются в соответствии с CC-By-NC-SA-4.0. Если вы ремикс, преобразовываете или опираетесь на материал, вы должны распространять свои взносы по той же лицензии, что и оригинал.
Для запросов на деловые запросы, пожалуйста, посетите наш веб -сайт и отправьте форму: Nvidia Research Licensing.
Мы хотели бы поблагодарить всех исследователей, которые открывают свои работы, чтобы сделать этот проект возможным. @bjoernpl для получения автоматического скрипта загрузки контрольной точки.
Если у вас есть какие -либо вопросы, пожалуйста, свяжитесь с [email protected] .


