prismer
1.0.0
Repositori ini berisi kode sumber Prismer dan Prismerz dari makalah ini, Prismer: model bahasa penglihatan dengan para ahli multi-tugas. Lihatlah demo resmi kami di Huggingface Space dan demo pihak ketiga di Replicate.
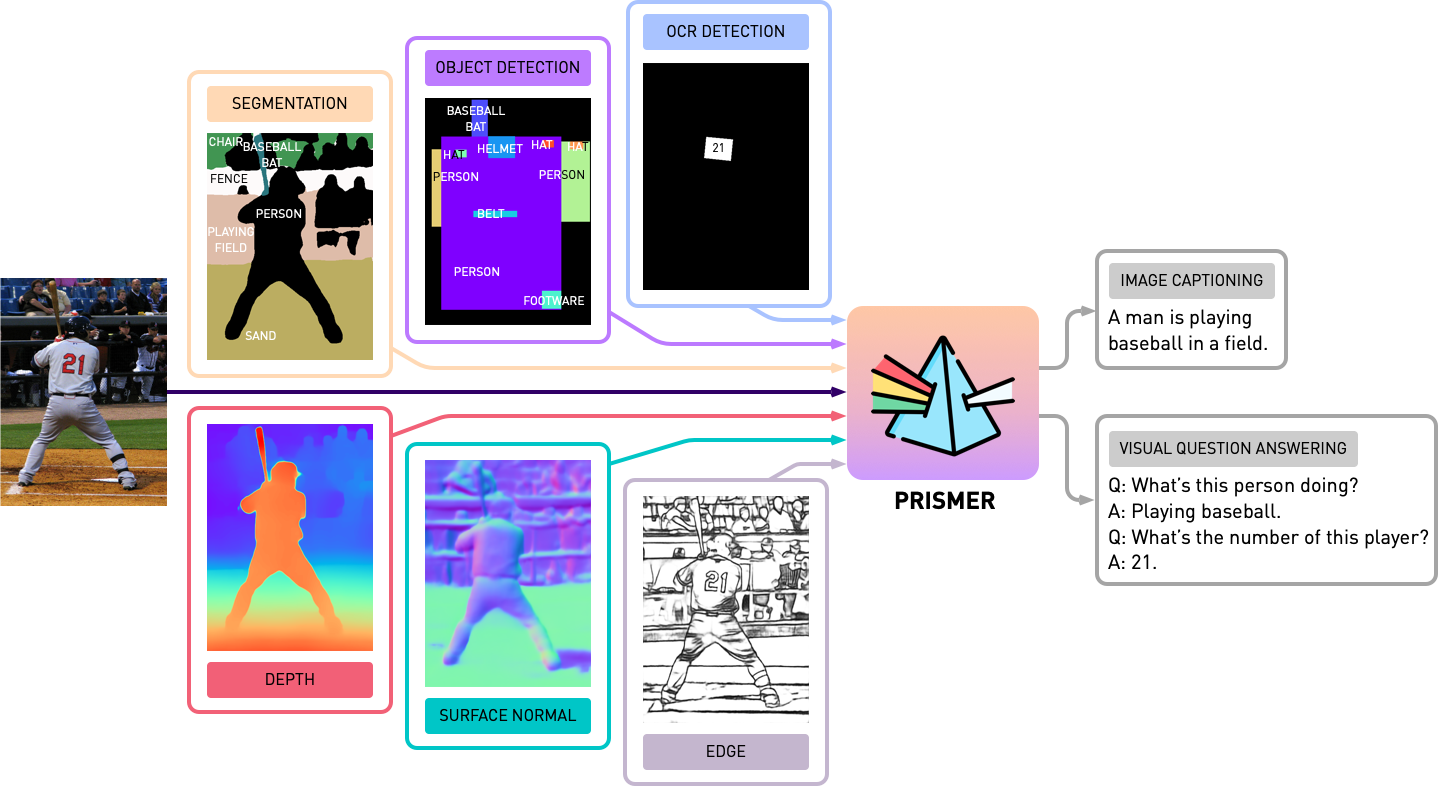
transformers yang diperbarui. Implementasinya didasarkan pada PyTorch 1.13 , dan sangat terintegrasi dengan Toolkit accelerate HuggingFace untuk pelatihan multi-GPU multi-node yang dapat dibaca dan dioptimalkan.
Pertama, mari kita menginstal semua dependensi paket dengan berjalan
pip install -r requirements.txt Kemudian kami menghasilkan konfigurasi accelerate yang sesuai berdasarkan konfigurasi server pelatihan Anda. Untuk pelatihan multi-GPU multi-simpul tunggal dan multi-node, cukup jalankan dan ikuti instruksi dengan,
accelerate configKami pra-pelatihan Prismer/Prismerz dengan kombinasi lima dataset gambar-alt/teks yang banyak digunakan, dengan daftar data pra-terorganisir yang disediakan di bawah ini.
Dataset Web (CC3M, SGU, CC12M) disusun dengan URL gambar. Sangat disarankan untuk menggunakan IMG2DataSet, toolkit yang sangat dioptimalkan untuk mengikis web skala besar untuk mengunduh gambar-gambar ini. Contoh skrip bash menggunakan img2dataset untuk mengunduh dataset cc12m disediakan di bawah ini.
img2dataset --url_list filtered_cc12m.json --input_format " json " --url_col " url " --caption_col " caption " --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256Catatan: Diharapkan bahwa jumlah gambar yang diunduh kurang dari jumlah gambar dalam file JSON, karena beberapa URL mungkin tidak valid atau membutuhkan waktu pemuatan yang lama.
Kami mengevaluasi kinerja captioning gambar pada dua dataset, Coco 2014 dan NOCAPS; dan kinerja VQA pada dataset VQAV2. Dalam tugas VQA, kami juga menambah data pelatihan dengan genom visual QA, mengikuti blip. Sekali lagi, kami telah menyiapkan dan mengatur daftar data pelatihan dan evaluasi yang disediakan di bawah ini.
Sebelum memulai eksperimen dengan Prismer, kita perlu terlebih dahulu pra-menghasilkan label ahli modalitas, jadi kita dapat membangun dataset multi-label. Di folder experts , kami telah memasukkan semua 6 ahli yang kami perkenalkan dalam makalah kami. Kami telah mengatur basis kode masing -masing ahli dengan API bersama dan sederhana.
Catatan: Khusus untuk pakar segmentasi, silakan instal pertama operasi konvolusi yang dapat dideformasi oleh cd experts/segmentation/mask2former/modeling/pixel_decoder/ops dan jalankan sh make.sh
Untuk mengunduh ahli modalitas pra-terlatih, jalankan
python download_checkpoints.py --download_experts=True Untuk menghasilkan label ahli, cukup edit configs/experts.yaml dengan jalur data yang sesuai, dan jalankan
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.pyCatatan: Pembuatan label ahli hanya diperlukan untuk model Prismer, bukan untuk model Prismerz.
Kami telah menyediakan Prismer dan Prismerz untuk pos pemeriksaan pra-terlatih (untuk captioning gambar nol-shot), serta pos pemeriksaan yang disesuaikan dengan fine pada dataset VQAV2 dan Coco. Dengan pos -pos pemeriksaan ini, harus diharapkan untuk mereproduksi kinerja persis yang tercantum di bawah ini.
| Model | Pra-terlatih [Zero-shot] | Coco [disesuaikan] | VQAV2 [disesuaikan] |
|---|---|---|---|
| Prismerz-base | Coco Cider [109.6] | Coco Cider [133.7] | test-dev [76.58] |
| Basis prismer | Coco Cider [122.6] | Coco Cider [135.1] | test-dev [76.84] |
| Prismerz-Large | Coco Cider [124.8] | Coco Cider [135.7] | test-dev [77.49] |
| Prismer-Large | Coco Cider [129.7] | Coco Cider [136.5] | test-dev [78.42] |
Untuk mengunduh pos pemeriksaan pra-terlatih/didenda, jalankan
# to download all model checkpoints (12 models in total)
python download_checkpoints.py --download_models=True
# to download specific checkpoints (Prismer-Base for fine-tuned VQA) in this example
python download_checkpoints.py --download_models= " vqa_prismer_base " Catatan: Ingatlah untuk menginstal Java melalui sudo apt-get install default-jre yang diperlukan untuk menjalankan skrip evaluasi keterangan coco resmi.
Untuk mengevaluasi pos pemeriksaan model, silakan jalankan
# zero-shot image captioning (remember to remove caption prefix in the config files)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# fine-tuned image captioning
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# fine-tuned VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluateUntuk melakukan pra-pelatihan atau menyempurnakan model apa pun dengan atau tanpa pos pemeriksaan, silakan jalankan
# to train/fine-tuning from scratch
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# to train/fine-tuning from the latest checkpoints (saved every epoch)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint Kami juga menyertakan model sharding dalam skrip pelatihan saat ini melalui plugin FSDP resmi Pytorch. Dengan perintah pelatihan yang sama, tambahan tambahkan --shard_grad_op untuk zero-2 sharding (gradien + status optimiser), atau --full_shard untuk zero-3 sharding (nol-2 + parameter jaringan).
Catatan: Anda harus mengharapkan rentang kesalahan untuk VQAV2 ACC. menjadi kurang dari 0,1; Untuk skor sari Coco/NoCaps menjadi kurang dari 1,0.
Akhirnya, kami telah menawarkan contoh minimal untuk melakukan captioning gambar dalam satu GPU dengan pos pemeriksaan Prismer/Prismerz kami yang disesuaikan. Cukup letakkan gambar Anda di bawah helpers/images (dukungan .jpg , .jpeg , dan .png gambar), dan jalankan
python demo.py --exp_name {MODEL_NAME} Anda kemudian dapat melihat semua label pakar modalitas yang dihasilkan di folder helpers/labels dan keterangan yang dihasilkan di folder helpers/images .
Khususnya untuk model Prismer, kami juga menawarkan skrip sederhana untuk melakukan pretifikasi label ahli yang dihasilkan. Untuk menguntungkan dan memvisualisasikan label ahli serta keterangannya, lari
python demo_vis.py Catatan: Ingat untuk mengatur konfigurasi yang sesuai di bagian Demo configs/caption.yaml . Konfigurasi model demo default adalah untuk prismer-base.
Jika Anda menemukan kode/pekerjaan ini berguna dalam penelitian Anda sendiri, silakan mempertimbangkan mengutip yang berikut:
@article { liu2024prismer ,
title = { Prismer: A Vision-Language Model with Multi-Task Experts } ,
author = { Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima } ,
journal = { Transactions on Machine Learning Research } ,
year = { 2024 }
}Hak Cipta © 2023, Nvidia Corporation. Semua hak dilindungi undang -undang.
Pekerjaan ini tersedia di bawah Lisensi Kode Sumber NVIDIA-NC.
Pos Pemeriksaan Model dibagi berdasarkan CC-BY-NC-SA-4.0. Jika Anda remix, mengubah, atau membangun materi, Anda harus mendistribusikan kontribusi Anda di bawah lisensi yang sama dengan aslinya.
Untuk pertanyaan bisnis, silakan kunjungi situs web kami dan kirimkan formulir: Lisensi Penelitian NVIDIA.
Kami ingin mengucapkan terima kasih kepada semua peneliti yang membuka sumber pekerjaan mereka untuk memungkinkan proyek ini. @BJOERNPL karena menyumbangkan skrip unduhan pos pemeriksaan otomatis.
Jika Anda memiliki pertanyaan, silakan hubungi [email protected] .


