prismer
1.0.0
该存储库包含Prismer和Prismerz的源代码,Prismer:具有多任务专家的视觉语言模型。查看我们在Huggingface Space的正式演示,并在Replicate上查看第三方演示。
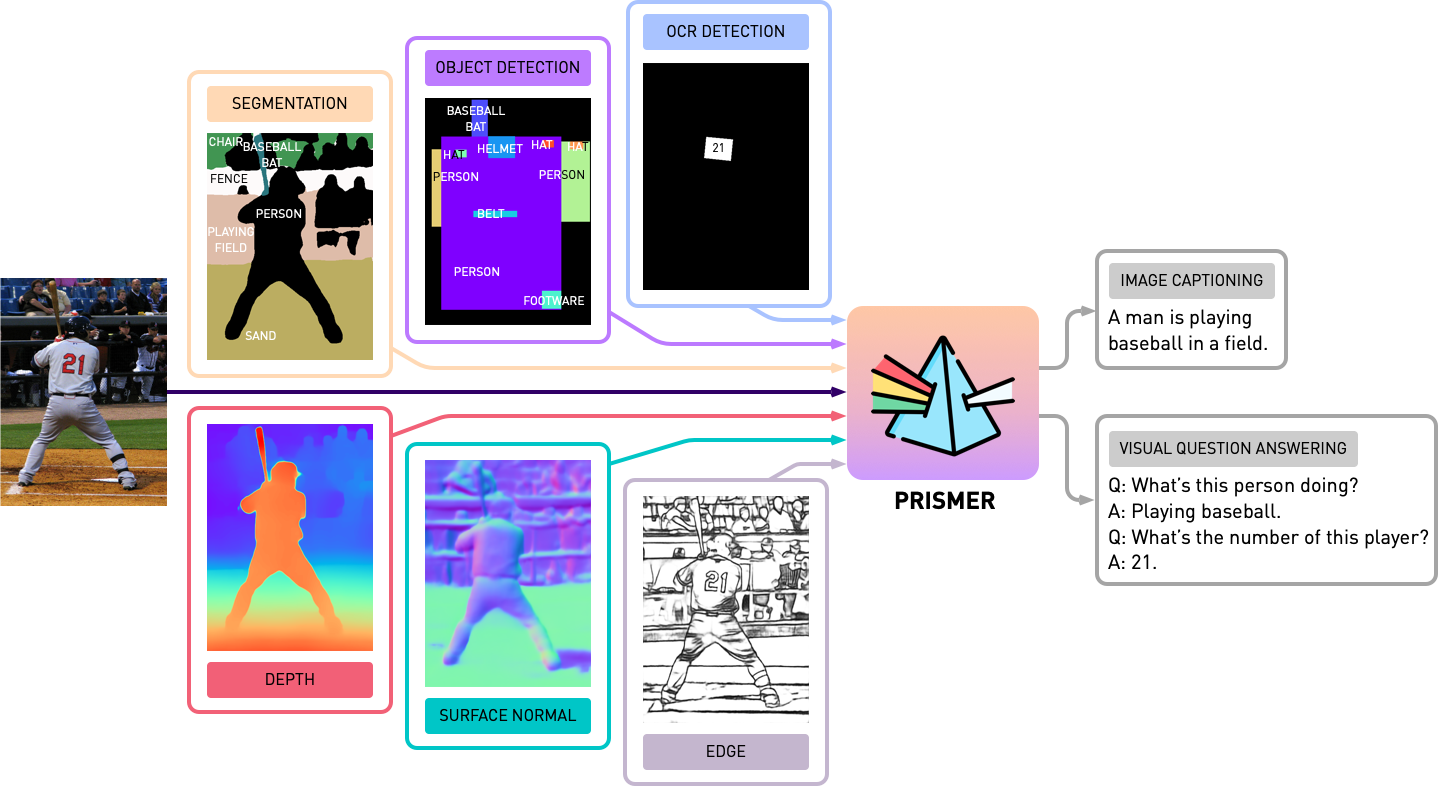
transformers软件包的张量不匹配问题。该实现基于PyTorch 1.13 ,并与HuggingFace accelerate Toolkit高度集成,用于可读和优化的多节点多GPU培训。
首先,让我们通过运行安装所有软件包依赖项
pip install -r requirements.txt然后,我们根据您的培训服务器配置生成相应的accelerate配置。对于单个节点多GPU和多节点的多GPU培训,只需运行并按照说明进行操作,
accelerate config我们与五个广泛使用的图像alt/文本数据集的组合预先培训Prismer/Prismerz,并提供了以下预先组织的数据列表。
Web数据集(CC3M,SGU,CC12M)由图像URL组成。强烈建议使用IMG2DATASET,这是一种高度优化的工具包,用于大规模网络刮擦以下载这些图像。下面提供了使用img2dataset下载cc12m数据集的示例BASH脚本。
img2dataset --url_list filtered_cc12m.json --input_format " json " --url_col " url " --caption_col " caption " --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256注意:预计下载的图像的数量小于JSON文件中图像的数量,因为某些URL可能无效或需要长时间加载时间。
我们在两个数据集(可可2014年和NOCAPS)上评估图像字幕性能;和VQAV2数据集上的VQA性能。在VQA任务中,我们还通过视觉基因组质量质量质量质量质量质量质量质量质量质量增加了训练数据。同样,我们已经准备好并组织了下面提供的培训和评估数据列表。
在使用Prismer进行任何实验之前,我们需要首先预先生成模式专家标签,因此我们可以构建一个多标签数据集。在experts文件夹中,我们包括了我们在论文中介绍的所有6个专家。我们已经用共享且简单的API组织了每个专家的代码库。
注意:专门针对细分专家,请首先安装cd experts/segmentation/mask2former/modeling/pixel_decoder/ops和Run sh make.sh的可变形卷积操作。
要下载预训练的模式专家,请运行
python download_checkpoints.py --download_experts=True要生成专家标签,只需编辑configs/experts.yaml
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.py注意:专家标签生成仅是Prismer模型所必需的,而不是Prismerz模型。
我们已经为Prismer和Prismerz提供了预先训练的检查点(用于零照片的图像字幕),以及VQAV2和COCO数据集的罚款调整检查点。使用这些检查点,应期望重现下面列出的确切性能。
| 模型 | 预训练[零射] | 可可[微调] | VQAV2 [微调] |
|---|---|---|---|
| Prismerz-base | 可可苹果酒[109.6] | 可可苹果酒[133.7] | Test-Dev [76.58] |
| Prismer基地 | 可可苹果酒[122.6] | 可可苹果酒[135.1] | Test-Dev [76.84] |
| Prismerz-large | 可可苹果酒[124.8] | 可可苹果酒[135.7] | Test-Dev [77.49] |
| Prismer-large | 可可苹果酒[129.7] | 可可苹果酒[136.5] | Test-Dev [78.42] |
要下载预训练/罚款的检查点,请运行
# to download all model checkpoints (12 models in total)
python download_checkpoints.py --download_models=True
# to download specific checkpoints (Prismer-Base for fine-tuned VQA) in this example
python download_checkpoints.py --download_models= " vqa_prismer_base "注意:请记住,要通过sudo apt-get install default-jre安装java,这是运行官方可可字幕评估脚本所需的。
要评估模型检查点,请运行
# zero-shot image captioning (remember to remove caption prefix in the config files)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# fine-tuned image captioning
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# fine-tuned VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate要预先培训或微调任何具有或没有检查点的模型,请运行
# to train/fine-tuning from scratch
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# to train/fine-tuning from the latest checkpoints (saved every epoch)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint 我们还通过Pytorch的官方FSDP插件将模型碎片包括在当前培训脚本中。借助相同的训练命令,还添加--shard_grad_op for Zero-2 sharding(渐变 +优化器状态)或--full_shard for-forl_shard for Zero-3 Sharding(Zero-2 +网络参数)。
注意:您应该期望VQAV2 ACC的错误范围。小于0.1;对于可可/nocaps的苹果酒评分小于1.0。
最后,我们提供了一个最小的示例,可以使用我们的微调Prismer/Prismerz检查点在单个GPU中执行图像字幕。只需将图像放在helpers/images (支持.jpg , .jpeg和.png图像)下,然后运行
python demo.py --exp_name {MODEL_NAME}然后,您可以在helpers/labels文件夹中看到所有生成的模式专家标签以及helpers/images文件夹中生成的字幕。
特别是对于Prismer模型,我们还提供了一个简单的脚本来使生成的专家标签贴上。为了使专家标签及其预测的标题效果和可视化,请运行
python demo_vis.py注意:请记住在configs/caption.yaml演示部分中设置相应的配置。默认的演示模型配置适用于Prismer bas。
如果您发现此代码/工作在您自己的研究中很有用,请考虑引用以下内容:
@article { liu2024prismer ,
title = { Prismer: A Vision-Language Model with Multi-Task Experts } ,
author = { Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima } ,
journal = { Transactions on Machine Learning Research } ,
year = { 2024 }
}版权所有©2023,Nvidia Corporation。版权所有。
这项工作可根据NVIDIA源代码许可-NC提供。
模型检查点在CC-BY-NC-SA-4.0下共享。如果您在材料上进行混音,转换或构建,则必须在与原件相同的许可下分发捐款。
有关业务查询,请访问我们的网站并提交表格:NVIDIA研究许可。
我们要感谢所有开源工作以使该项目成为可能的研究人员。 @bjoernpl用于贡献自动检查点下载脚本。
如有任何疑问,请联系[email protected] 。


