prismer
1.0.0
ที่เก็บนี้มีรหัสแหล่งที่มาของ Prismer และ Prismerz จากกระดาษ Prismer: แบบจำลองภาษาวิสัยทัศน์ที่มีผู้เชี่ยวชาญหลายงาน ตรวจสอบการสาธิตอย่างเป็นทางการของเราที่ HuggingFace Space และการสาธิตบุคคลที่สามในการทำซ้ำ
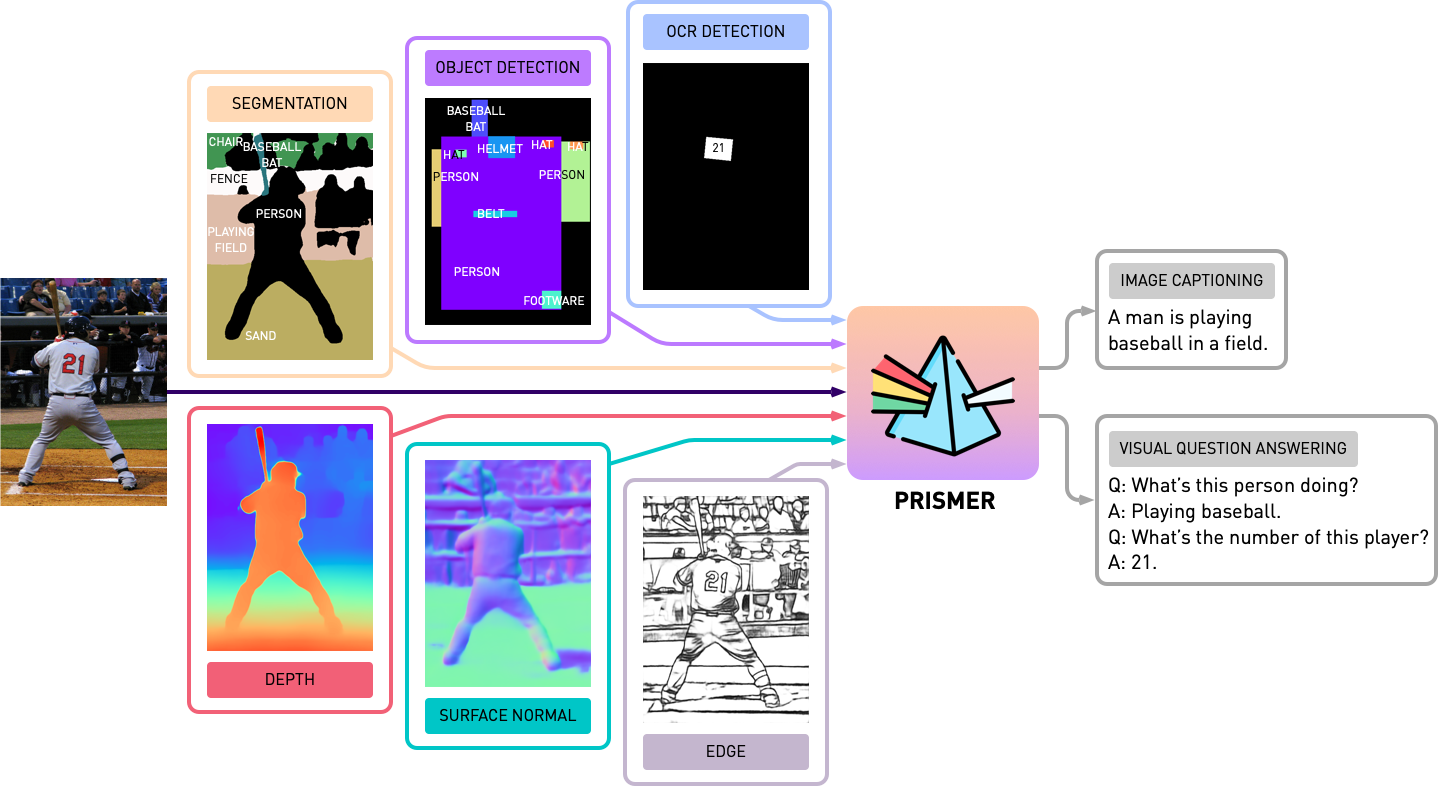
transformers ที่อัปเดต การใช้งานจะขึ้นอยู่กับ PyTorch 1.13 และรวมเข้ากับชุดเครื่องมือ accelerate HuggingFace สำหรับการฝึกอบรมแบบหลายโหนดหลายโหนดที่สามารถอ่านได้และปรับให้เหมาะสม
ก่อนอื่นให้ติดตั้งแพ็คเกจการพึ่งพาทั้งหมดโดยเรียกใช้
pip install -r requirements.txt จากนั้นเราจะสร้างการเร่ง accelerate ที่สอดคล้องกันตามการกำหนดค่าเซิร์ฟเวอร์การฝึกอบรมของคุณ สำหรับการฝึกอบรมแบบหลายโหนดแบบหลายโหนดเดียวและการฝึกอบรมแบบหลายโหนดหลายโหนดเพียงแค่เรียกใช้และทำตามคำแนะนำด้วย
accelerate configเราฝึกซ้อม prismer/prismerz ล่วงหน้าด้วยชุดข้อมูลภาพอัลต์/ข้อความที่ใช้กันอย่างแพร่หลายห้าชุดพร้อมรายการข้อมูลที่จัดระเบียบล่วงหน้าไว้ด้านล่าง
ชุดข้อมูลเว็บ (CC3M, SGU, CC12M) ประกอบด้วย URL รูปภาพ ขอแนะนำอย่างยิ่งให้ใช้ IMG2Dataset ซึ่งเป็นชุดเครื่องมือที่ได้รับการปรับปรุงอย่างสูงสำหรับการขูดเว็บขนาดใหญ่เพื่อดาวน์โหลดภาพเหล่านี้ ตัวอย่างสคริปต์ทุบตีของการใช้ img2dataset เพื่อดาวน์โหลดชุดข้อมูล cc12m มีให้ด้านล่าง
img2dataset --url_list filtered_cc12m.json --input_format " json " --url_col " url " --caption_col " caption " --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256หมายเหตุ: คาดว่าจำนวนภาพที่ดาวน์โหลดน้อยกว่าจำนวนภาพในไฟล์ JSON เนื่องจาก URL บางรายการอาจไม่ถูกต้องหรือต้องใช้เวลาในการโหลดนาน
เราประเมินประสิทธิภาพการทำคำบรรยายภาพบนชุดข้อมูลสองชุดคือ Coco 2014 และ NOCAPS; และประสิทธิภาพ VQA บนชุดข้อมูล VQAV2 ในงาน VQA เรายังเพิ่มข้อมูลการฝึกอบรมด้วย Visual Genome QA ตาม Blip อีกครั้งเราได้จัดทำและจัดระเบียบข้อมูลการฝึกอบรมและการประเมินผลที่ให้ไว้ด้านล่าง
ก่อนที่จะเริ่มการทดลองใด ๆ กับ Prismer เราจำเป็นต้องจัดทำป้ายกำกับผู้เชี่ยวชาญด้านการปรับล่วงหน้าก่อนดังนั้นเราอาจสร้างชุดข้อมูลหลายฉลาก ในโฟลเดอร์ experts เราได้รวมผู้เชี่ยวชาญทั้ง 6 คนที่เราแนะนำไว้ในบทความของเรา เราได้จัดระเบียบ codebase ของผู้เชี่ยวชาญแต่ละคนด้วย API ที่ใช้ร่วมกันและเรียบง่าย
หมายเหตุ: โดยเฉพาะสำหรับผู้เชี่ยวชาญการแบ่งกลุ่มโปรดติดตั้งการดำเนินการ convolution ที่เปลี่ยนแปลงได้โดย cd experts/segmentation/mask2former/modeling/pixel_decoder/ops และเรียกใช้ sh make.sh
หากต้องการดาวน์โหลดผู้เชี่ยวชาญด้านรูปแบบที่ผ่านการฝึกอบรมมาก่อน
python download_checkpoints.py --download_experts=True ในการสร้างฉลากผู้เชี่ยวชาญเพียงแก้ไข configs/experts.yaml ด้วยเส้นทางข้อมูลที่สอดคล้องกันและเรียกใช้
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.pyหมายเหตุ: การสร้างฉลากผู้เชี่ยวชาญเป็นสิ่งจำเป็นสำหรับโมเดล Prismer เท่านั้นไม่ใช่สำหรับโมเดล Prismerz
เราได้ให้ทั้ง Prismer และ Prismerz สำหรับจุดตรวจสอบที่ผ่านการฝึกอบรมมาก่อน (สำหรับคำบรรยายภาพ zero-shot-shot) รวมถึงจุดตรวจสอบที่ปรับจูนบนชุดข้อมูล VQAV2 และ COCO ด้วยจุดตรวจเหล่านี้ควรคาดว่าจะทำซ้ำประสิทธิภาพที่แน่นอนที่แสดงอยู่ด้านล่าง
| แบบอย่าง | ได้รับการฝึกอบรมล่วงหน้า [Zero-Shot] | Coco [ปรับแต่ง] | VQAV2 [ปรับแต่ง] |
|---|---|---|---|
| พรัสเมอร์ซ | Coco Cider [109.6] | Coco Cider [133.7] | test-dev [76.58] |
| ฐานของ Prismer | Coco Cider [122.6] | Coco Cider [135.1] | test-dev [76.84] |
| Prismerz ขนาดใหญ่ | Coco Cider [124.8] | Coco Cider [135.7] | test-dev [77.49] |
| มีขนาดใหญ่ | Coco Cider [129.7] | Coco Cider [136.5] | test-dev [78.42] |
หากต้องการดาวน์โหลดจุดตรวจสอบที่ผ่านการฝึกอบรมล่วงหน้า/ปรับแต่งให้ทำงาน
# to download all model checkpoints (12 models in total)
python download_checkpoints.py --download_models=True
# to download specific checkpoints (Prismer-Base for fine-tuned VQA) in this example
python download_checkpoints.py --download_models= " vqa_prismer_base " หมายเหตุ: อย่าลืมติดตั้ง java ผ่าน sudo apt-get install default-jre ซึ่งจำเป็นต้องเรียกใช้สคริปต์การประเมิน Coco Caption อย่างเป็นทางการ
ในการประเมินจุดตรวจสอบรุ่นโปรดเรียกใช้
# zero-shot image captioning (remember to remove caption prefix in the config files)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# fine-tuned image captioning
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# fine-tuned VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluateในการฝึกอบรมล่วงหน้าหรือปรับแต่งโมเดลใด ๆ ที่มีหรือไม่มีจุดตรวจสอบโปรดเรียกใช้
# to train/fine-tuning from scratch
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# to train/fine-tuning from the latest checkpoints (saved every epoch)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint นอกจากนี้เรายังได้รวมรุ่นที่ชาร์ดในสคริปต์การฝึกอบรมปัจจุบันผ่านปลั๊กอิน FSDP อย่างเป็นทางการของ Pytorch ด้วยคำสั่งการฝึกอบรมเดียวกันเพิ่ม --shard_grad_op สำหรับ zero-2 sharding (การไล่ระดับสี + สถานะตัวปรับให้เหมาะสม) หรือ --full_shard สำหรับ zero-3 sharding (พารามิเตอร์เครือข่าย ZERO-2 +)
หมายเหตุ: คุณควรคาดหวังช่วงข้อผิดพลาดสำหรับ VQAV2 ACC น้อยกว่า 0.1; สำหรับคะแนนไซเดอร์ Coco/NOCAPS น้อยกว่า 1.0
ในที่สุดเราได้เสนอตัวอย่างน้อยที่สุดในการแสดงคำบรรยายภาพใน GPU เดียวด้วยจุดตรวจ Prismer/Prismerz ที่ปรับแต่งได้อย่างละเอียด เพียงแค่ใส่ภาพของคุณภายใต้ helpers/images (สนับสนุน .jpg , .jpeg และ .png ภาพ) และเรียกใช้
python demo.py --exp_name {MODEL_NAME} จากนั้นคุณสามารถดูป้ายกำกับผู้เชี่ยวชาญด้านรูปแบบที่สร้างขึ้นทั้งหมดในโฟลเดอร์ helpers/labels และคำอธิบายภาพที่สร้างขึ้นในโฟลเดอร์ helpers/images
โดยเฉพาะอย่างยิ่งสำหรับโมเดล Prismer เรายังได้เสนอสคริปต์อย่างง่ายเพื่อให้ฉลากผู้เชี่ยวชาญที่สร้างขึ้นล่วงหน้า เพื่อให้ภาพลักษณ์และแสดงภาพฉลากผู้เชี่ยวชาญเช่นเดียวกับคำบรรยายภาพที่คาดการณ์
python demo_vis.py หมายเหตุ: อย่าลืมตั้งค่าการกำหนดค่าที่สอดคล้องกันในส่วน demo configs/caption.yaml การกำหนดค่าแบบจำลองการสาธิตเริ่มต้นใช้สำหรับ prismer-base
หากคุณพบรหัส/งานนี้มีประโยชน์ในการวิจัยของคุณเองโปรดพิจารณาอ้างถึงสิ่งต่อไปนี้:
@article { liu2024prismer ,
title = { Prismer: A Vision-Language Model with Multi-Task Experts } ,
author = { Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima } ,
journal = { Transactions on Machine Learning Research } ,
year = { 2024 }
}ลิขสิทธิ์© 2023, Nvidia Corporation สงวนลิขสิทธิ์
งานนี้มีให้ภายใต้ NVIDIA Source COLOSE LICANITH-NC
จุดตรวจสอบแบบจำลองจะถูกแชร์ภายใต้ CC-BY-NC-SA-4.0 หากคุณรีมิกซ์แปลงหรือสร้างเนื้อหาคุณต้องแจกจ่ายการมีส่วนร่วมของคุณภายใต้ใบอนุญาตเดียวกับต้นฉบับ
สำหรับการสอบถามทางธุรกิจกรุณาเยี่ยมชมเว็บไซต์ของเราและส่งแบบฟอร์ม: Nvidia Research Licensing
เราขอขอบคุณนักวิจัยทุกคนที่เปิดแหล่งข้อมูลเพื่อให้โครงการนี้เป็นไปได้ @bjoernpl สำหรับการสนับสนุนสคริปต์ดาวน์โหลดจุดตรวจสอบอัตโนมัติ
หากคุณมีคำถามใด ๆ โปรดติดต่อ [email protected]


