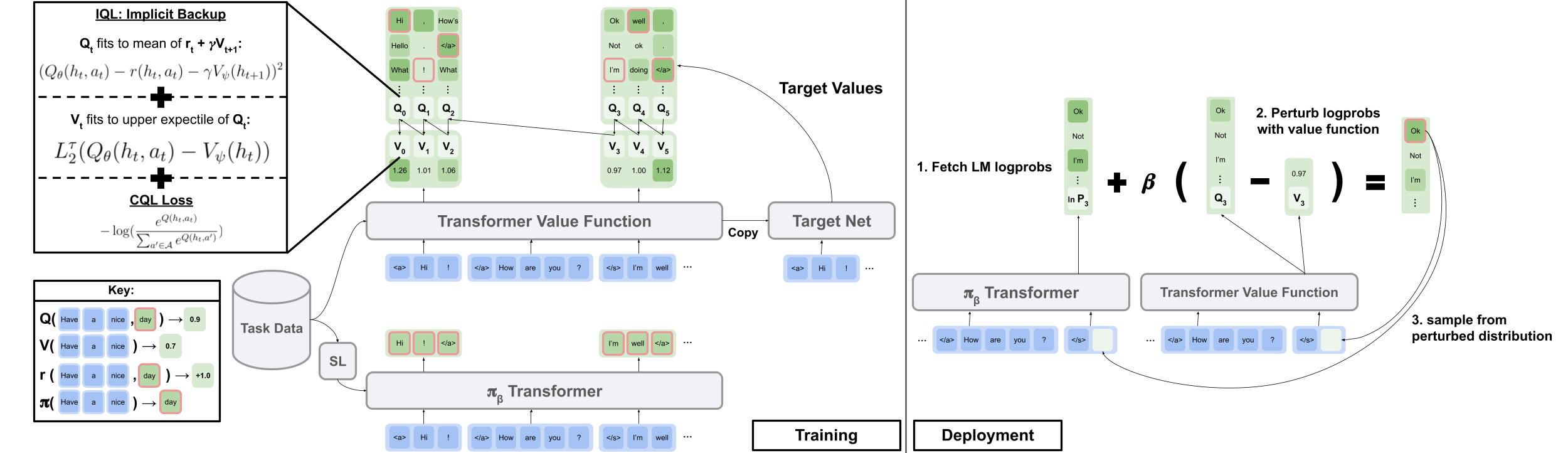
Implicit Language Q Learning
1.0.0
官方代碼中的官方代碼“具有隱性語言q學習的自然語言生成的離線RL”
項目網站| arxiv
從此處的Google Drive文件夾下載data.zip and outputs.zip 。將下載和未拉緊的文件夾, data/和outputs/放在存儲庫的根部。 data/包含我們所有任務的預處理數據,並且outputs/包含我們的reddit註釋的檢查點,請獎勵獎勵。
此存儲庫是為Python 3.9.7設計的
pip install -r requirements.txt
export PYTHONPATH= " $PWD /src/ "要運行視覺對話實驗,您需要按照此處的說明來為Local主持人提供視覺對話環境。
使用毒性過濾器獎勵進行Reddit評論實驗:
export OPENAI_API_KEY=your_API_keyscripts/包含所有實驗腳本。在scripts/ ::
python script_name.py選修的:
python script_name.py eval.bsize=5 train.lr=1e-6 wandb.use_wandb=falsepython -m torch.distributed.launch --nproc_per_node [N_GPUs] --use_env script_name.py arg1=a arg2=b默認情況下,所有培訓腳本都會記錄到WANDB。要關閉此問題,請在培訓配置中設置wandb.use_wandb=false 。
在這裡,我概述了推薦的工作流程,用於培訓離線RL代理。假設我想訓練一堆不同的離線RL代理,以產生毒性獎勵的紅色評論。
我將首先在數據上訓練BC模型:
cd scripts/train/toxicity/
python train_bc.py然後將此BC檢查點轉換為與離線RL模型兼容的一個:
cd ../data/
python convert_bc.py --load ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model.pkl --save ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model_converted.pkl然後編輯離線RL配置為訓練以下檢查的檢查點:
cd ../train/
python train_iql.py model.load.checkpoint_path=outputs/toxicity/model_converted.pkl model.load.strict_load=false train.loss.awac_weight=0.0但是,這只是一個工作流程,您也可以通過設置train.loss.awac_weight=1.0在培訓配置中與離線RL代理同時訓練BC模型。
data/文件夾中預處理。scripts/包含所有用於運行培訓,評估和數據預處理步驟的腳本。腳本被組織成與所使用的數據集相對應的子文件夾。config/ contrains .yaml configs的每個腳本。此存儲庫使用Hydra管理配置。配置被組織成對應於所用數據集的子文件夾。大多數配置文件的命名與其相應的腳本相同,但是如果您不確定哪個配置對應於腳本,請選中line @hydra.main(config_path="some_path", config_name="some_name")以查看腳本對應的配置文件。src/包含所有核心實現。有關所有模型實現,請參見src/models/ 。有關所有基本數據處理和MDP抽象代碼,請參見src/data/ 。有關各種實用程序功能,請參見src/utils/ 。請參閱src/wordle/ , src/visdial和src/toxicity/有關所有詞,視覺對話和reddit評論數據集的特定代碼。ILQL被稱為iql 。 每個腳本都與配置文件關聯。配置文件指定腳本及其相應的超參數將加載哪些模型,數據集和評估器。有關一個示例,請參見configs/toxicity/train_iql.yaml 。
每個可能的模型,數據集或評估器對像都有其自己的配置文件,該文件指定該對象的默認值和一個特殊name屬性,該屬性告訴Config Manager加載什麼類。有關一個示例,請參見configs/toxicity/model/per_token_iql.yaml 。
文件src/load_objects.py , src/wordle/load_objects.py , src/visdial/load_objects.py和src/toxicity/load_objects.py定義了每個對像是如何從其相應配置中加載的。每個加載對象函數上方的@register('name')標籤鏈接到配置中的name屬性。
您可能會注意到與配置中的某些對象關聯的特殊cache_id屬性。例如,請參見configs/toxicity/train_iql.yaml中的train_dataset 。此屬性告訴Config Manager來緩存它加載與此ID關聯的第一個對象,然後使用此cache_id返回此緩存的對像以進行後續對象配置。
對於所有配置,請使用相對於repo root的路徑。
我們存儲庫中的每個任務(Wordle,Visual對話和Reddit評論)都實現了一些基礎類。實施後,所有離線RL算法都可以以插件方式應用於任務。請參閱“創建自己的任務”部分,以概述為了創建自己的任務應實現的內容。在下面,我們概述了使它成為可能的關鍵抽象。
data.language_environment.Language_Environment - 代表一個策略可以與之互動的任務POMDP環境。它具有類似健身房的界面。data.language_environment.Policy - 表示可以與環境交互的策略。 src/models/中的每個離線RL算法都有相應的策略。data.language_environment.Language_Observation - 代表環境返回並作為策略輸入的文本觀察。data.language_environment.interact_environment - 一種函數,它可以在環境,策略和當前觀察過程中運行並運行環境互動循環。如果未提供當前觀察結果,它將通過重置環境自動獲取初始狀態。data.rl_data.DataPoint - 定義標準化的數據格式,該格式被饋送為所有任務上所有離線RL代理的輸入。這些數據結構是從給定的Language_Observation自動創建的。data.rl_data.TokenReward - 定義在每個令牌上給出的獎勵功能,可用於學習更多細粒度控制。這是在環境獎勵之上提供的,它不是在每個令牌上都提供,而是在每次互動之後提供的。在我們的所有實驗中,我們將此獎勵設置為常數0,因此沒有效果。data.tokenizer.Tokenizer - 指定如何將字符串轉換為代幣序列,然後將其作為輸入作為語言模型的輸入。data.rl_data.RL_Dataset - 定義一個數據集對象,該對象返回DataPoint對象,用於訓練離線RL代理。 RL_Dataset有兩個版本:List_RL_DatasetIterable_RL_Dataset
在這裡,我們概述並記錄Wordle任務的所有組件。
示例腳本中的許多內容都是由配置管理器自動完成的,並且可以通過更改配置來編輯相應的參數。但是,如果您想使用配置繞過並將Wordle任務與自己的代碼庫一起使用,則可以在下面引用下面的腳本和文檔以進行此操作。
一個簡單的示例腳本,用於在命令行中播放Wordle。
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from wordle . policy import UserPolicy
from data . language_environment import interact_environment
from utils . misc import convert_path
game_vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( game_vocab )
policy = UserPolicy ()
interact_environment ( env , policy )src/wordle/wordle_game.pysrc/wordle/wordle_env.pysrc/wordle/policy.pysrc/wordle/wordle_dataset.py為了使遊戲成為有效的MDP,環境代表了基本狀態作為一組已知的字母約束,並使用它們來過濾詞彙,以符合每回合滿足所有這些約束的單詞。然後從此過濾的單詞列表中選擇一個隨機單詞,並用於確定環境返回的顏色過渡。這些新的顏色轉換然後更新已知字母約束的集合。
Wordle環境帶有單詞列表。在data/wordle/word_lists/中給出了一些單詞列表,但可以隨意製作自己的單詞列表。
包含的單詞列表是:
如上所述,單詞列表通過Vocabulary對象加載到環境中。
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))詞彙不僅存儲單詞列表,還可以跟踪符合給定狀態下所有已知字母約束的過濾單詞列表。此列表用於計算環境中的過渡,並由一些手工製作的政策使用。
實時生產這些過濾列表可以減慢環境交互過程。這通常不應該是一個問題,但是如果您想快速從政策中綜合大量數據,那麼這可能會成為瓶頸。為了克服這一點,所有Vocabulary對像都存儲一個cache參數,該參數緩存了與給定狀態關聯的過濾單詞列表。 vocab.cache.load(f_path)和vocab.cache.dump()啟用加載和保存此緩存。例如, data/wordle/vocab_cache_wordle_official.pkl是Wordle_official.txt Word列表的大量緩存。
除了存儲緩存外, Vocabulary對像還在src/wordle/wordle_game.py中實現以下方法:
__init__ def __init__ ( self , all_vocab : List [ str ],
wordle_state : Optional [ WordleState ],
cache : Optional [ Cache ] = None ,
fill_cache : bool = True ) -> None輸入:
all_vocab: List[str] - 單詞列表。wordle_state: Optional[WordleState] - 一種生成過濾的單詞列表的狀態,如果沒有提供狀態,則不會過濾單詞。cache: Optional[Cache]=None - 如上所述,用於過濾的詞彙的緩存。fill_cache: bool=True - 是否添加到緩存中。返回: None
from_file def from_file ( cls , vocab_file : str , fill_cache : bool = True ) -> Vocabulary輸入:
vocab_file: str - 從中加載單詞的文件。該方法僅選擇5個字母的單詞。fill_cache: bool=True - 是否添加到緩存中。回報: Vocabulary
filtered_vocab_size def filtered_vocab_size ( self ) -> int回報:被過濾的詞彙的大小
all_vocab_size def all_vocab_size ( self ) -> int回報:完整未經過濾的詞彙的大小
get_random_word_filtered def get_random_word_filtered ( self ) -> str返回:從過濾列表中的隨機單詞。
get_random_word_all def get_random_word_all ( self ) -> str返回:完整未經過濾列表中的隨機單詞。
update_vocab def update_vocab ( self , wordle_state : WordleState ) -> Vocabulary輸入:
wordle_state: WordleState - 一個Wordle狀態對象,代表已知字母約束的集合。返回:一個新的Vocabulary對象,根據wordle_state進行過濾。
__str__ def __str__ ( self ) -> str返回:用於打印到終端的過濾單詞列表的字符串表示。
WordleEnvironment將詞彙對像作為輸入,它定義了環境中可能的正確單詞。
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( vocab )
initial_obs = env . reset ()
next_obs , reward , terminal = env . step ( "snake" )如上所示,環境在src/wordle/wordle_env.py中實現類似健身房的界面:
__init__ def __init__ ( self , vocab : Vocabulary ) -> None輸入:
vocab: Vocabulary - 環境的詞彙。返回: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]輸入:
action: Vocabulary - 一串文本,代表代理在環境中的動作。回報:(觀察,獎勵,終端)元組。
reset def reset ( self ) -> WordleObservation回報:觀察。
is_terminal def is_terminal ( self ) -> bool回報:布爾值表示交互是否已終止。
我們實施一套手工製作的文字策略,這些策略涵蓋了一系列遊戲級別。所有這些都在src/wordle/policy.py中實現。在這裡,我們描述每個人:
UserPolicy from wordle . policy import UserPolicy
policy = UserPolicy ( hint_policy = None , vocab = None )描述:
讓您在終端玩。
輸入:
hint_policy: Optional[Policy] - 如果您想提示要使用什麼單詞,請查詢另一個策略。vocab: Optional[Union[str, Vocabulary]] - 可猜測的單詞的Vocabulary 。如果未指定,則任何5個字母的字符序列都是有效的猜測。 StartWordPolicy from wordle . policy import StartWordPolicy
policy = StartWordPolicy ()描述:
僅適用於第一個單詞。從精選的高質量起始單詞列表中隨機選擇一個單詞。
輸入:
start_words: Optional[List[str]]=None - 覆蓋策劃的開始單詞的列表。 OptimalPolicy from wordle . policy import OptimalPolicy
policy = OptimalPolicy ()描述:
從近視上扮演最高信息列表中符合所有已知字母約束的最高信息。該策略實際上並不是最佳的,因為最佳遊戲是NP-HARD。但是它的效果非常高,可以用作性能的近似上限。該策略的計算非常慢,並且在單詞列表的大小中進行性能二次。為了保存計算, self.cache.load(f_path)和self.cache.dump()允許您加載和保存緩存。例如, data/wordle/optimal_policy_cache_wordle_official.pkl在wordle_official.txt word列表上代表此策略的緩存。
輸入:
start_word_policy: Optional[Policy]=None - 由於第一個單詞通常是最昂貴的計算信息增益,因此您可以指定只要求第一個單詞的其他策略。progress_bar: bool=False - 由於計算可能需要這麼長時間,因此我們為您提供每個呼叫self.act的進度條的選擇。 RepeatPolicy from wordle . policy import RepeatPolicy
policy = RepeatPolicy ( start_word_policy = None , first_n = 2 )描述:
隨機重複已經使用的first_n單詞之一。這是最大程度的次優政策,因為除非在第一個單詞上幸運,否則它永遠無法獲勝。
輸入:
start_word_policy: Optional[Policy] - 用於選擇第一個單詞的策略。如果None ,則隨機從環境的詞彙中選擇一個單詞。first_n: Optional[int] - 該策略將歷史記錄中的第first_n單詞隨機選擇下一個單詞。如果None ,則它將從完整的歷史記錄中隨機選擇。 RandomMixturePolicy from wordle . policy import RandomMixturePolicy
policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )描述:
從概率(1 - prob_smart)中從單詞列表中完全隨機選擇一個單詞,並從單詞列表中選擇一個隨機單詞,該單詞符合所有已知字母約束,並具有概率prob_smart 。
輸入:
prob_smart: float - 選擇一個符合所有已知字母約束的單詞的概率,而不是完全隨機。vocab: Optional[Union[str, Vocabulary]] - 可從中選擇的單詞列表。如果None ,則策略默認為環境單詞列表。 WrongPolicy from wordle . policy import WrongPolicy
from wordle . wordle_game import Vocabulary
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
policy = WrongPolicy ( vocab )描述:
從單詞列表中隨機選擇一個單詞,該單詞無法滿足所有已知的字母約束,因此不能是正確的單詞。如果單詞列表中的所有單詞都符合字母約束,則它將從列表中隨機選擇一個單詞。該政策是高度最佳的。
輸入:
vocab: Union[str, Vocabulary] - 一個單詞列表可供選擇。 MixturePolicy from wordle . policy import MixturePolicy , OptimalPolicy , RandomMixturePolicy
policy1 = OptimalPolicy ()
policy2 = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MixturePolicy ( prob1 = 0.5 , policy1 = policy1 , policy2 = policy2 )描述:
混合兩個給定的政策。從policy1中選擇具有概率prob1選擇,然後從概率(1 - prob1)中從policy2中進行選擇。
輸入:
prob1: float - 從policy1中選擇操作的概率1。policy1: Policy - 第一個選擇行動的政策。選擇具有概率prob1選擇。policy1: Policy - 第二種選擇行動的政策。以概率(1 - prob1)選擇。 MonteCarloPolicy from wordle . policy import MonteCarloPolicy
sample_policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MonteCarloPolicy ( n_samples = 5 , sample_policy = sample_policy )描述:
採取政策,在環境中運行蒙特卡洛推出的n_samples ,並選擇在推出過程中獲得最高平均獎勵的下一個動作。
輸入:
n_samples: int - 要執行的蒙特卡洛推出數量。sample_policy: Policy - 採樣推出的政策。 
上述任何策略均可用於生成數據集,該數據集可用於訓練離線RL代理。我們在src/wordle/wordle_dataset.py中實現了兩種合成數據集:
wordle.wordle_dataset.WordleListDataset - 從文件加載Wordle遊戲。wordle.wordle_dataset.WordleIterableDataset - 從給定的策略中示例Wordle Games。WordleListDataset :從類似文件中加載Wordle數據集:
from wordle . wordle_dataset import WordleListDataset
from data . rl_data import ConstantTokenReward
data = WordleListDataset . from_file (
file_path = 'data/wordle/expert_wordle_100k.pkl' ,
max_len = None ,
vocab = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
for i in range ( data . size ()):
item = data . get_item ( i )__init__ def __init__ ( self , items : List [ Tuple [ WordleObservation , Optional [ Dict [ str , Any ]]]], max_len : Optional [ int ], token_reward : TokenReward ) -> None輸入:
items: List[Tuple[WordleObservation, Optional[Dict[str, Any]]]] - 以(WordLeobservation,metadata_dict)形式的數據列表。元數據_Dict是任何形式的元數據,您可能想存儲在數據標記中的任何一種元數據。max_len: Optional[int] - 數據集中的最大序列長度將截斷所有令牌序列到此長度。如果None ,則不會截斷序列。token_reward: TokenReward - 用於應用序列的令牌級別的獎勵。對於所有實驗,我們使用持續的0獎勵。返回: None
from_file def from_file ( cls , file_path : str , max_len : Optional [ int ], vocab : Optional [ Vocabulary ], token_reward : TokenReward ) -> WordleListDataset輸入:
file_path: str - 數據醃製文件的路徑。max_len: Optional[int] - 數據集中的最大序列長度將截斷所有令牌序列到此長度。如果None ,則不會截斷序列。vocab: Optional[Vocabulary] - 在不同的環境詞彙下模擬數據集。如果None ,則默認使用用於創建數據集的相同詞彙。token_reward: TokenReward - 用於應用序列的令牌級別的獎勵。對於所有實驗,我們使用持續的0獎勵。返回: WordleListDataset對象。
get_item def get_item ( self , idx : int ) -> DataPoint輸入:
idx: int - 數據集中的索引。返回: DataPoint對象。
size def size ( self ) -> int返回:數據集的大小。
scripts/data/wordle/中的以下腳本可用於合成Wordle數據。
| 腳本 | 描述 |
|---|---|
generate_data.py | 從配置中指定的給定策略中採樣許多遊戲,並將其保存到文件中。 |
generate_data_mp.py | 與generate_data.py相同,除了在多個過程中並行示例遊戲。 |
generate_adversarial_data.py | 合成了我們論文第5節中描述的數據集,該數據集旨在證明單步RL方法和多步中的數據集。 |
generate_adversarial_data_mp.py | 除了在多個進程上並行示例遊戲以外,與generate_adversarial_data.py相同。 |
generate_data_branch.py | 從給定的“專家”策略中採樣遊戲,然後從遊戲中的每個動作中進行採樣,“次優”策略分支機構不再採樣許多新遊戲。 |
generate_data_branch_mp.py | 除了在多個進程上並行示例遊戲以外,與generate_data_branch.py相同。 |
一些提供的合成Wordle數據集在data/wordle/中。
| 文件 | 描述 |
|---|---|
expert_wordle_100k_1.pkl | 從OptimalPolicy取樣了100K遊戲。 |
expert_wordle_100k_2.pkl | 另一個從OptimalPolicy取樣的100K遊戲。 |
expert_wordle_adversarial_20k.pkl | 我們論文第5節中描述的數據集旨在證明單步RL方法和多步中的數據集。 |
expert_wordle_branch_100k.pkl | 使用generate_data_branch.py從OptimalPolicy採樣了100K遊戲,並從WrongPolicy中採樣了分支。 |
expert_wordle_branch_150k.pkl | 另外150k遊戲使用generate_data_branch.py從OptimalPolicy進行了採樣,並從WrongPolicy中採樣了分支。 |
expert_wordle_branch_2k_10sub.pkl | 使用generate_data_branch.py從OptimalPolicy採樣的2K遊戲,每個動作中的10個分支從WrongPolicy採樣,因此比expert_wordle_branch_100k.pkl中的次優數據要多得多。 |
expert_wordle_branch_20k_10sub.pkl | 與expert_wordle_branch_2k_10sub.pkl相同,除了20K遊戲而不是2K遊戲。 |
WordleIterableDataset :從類似策略中生成Wordle數據採樣:
from wordle . wordle_dataset import WordleIterableDataset
from wordle . policy import OptimalPolicy
from data . rl_data import ConstantTokenReward
policy = OptimalPolicy ()
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
data = WordleIterableDataset (
policy = policy ,
vocab = vocab ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
while True :
item = data . sample_item ()__init__ def __init__ ( self , policy : Policy , vocab : Vocabulary , max_len : Optional [ int ], token_reward : TokenReward ) -> None輸入:
policy: Policy - 從中採樣的政策。vocab: Vocabulary - 環境的詞彙。max_len: Optional[int] - 數據集中的最大序列長度將截斷所有令牌序列到此長度。如果None ,則不會截斷序列。token_reward: TokenReward - 用於應用序列的令牌級別的獎勵。對於所有實驗,我們使用持續的0獎勵。返回: None
sample_item def sample_item ( self ) -> DataPoint返回: DataPoint對象。
我們有大量的數據集,其中包含超過200k的Wordle遊戲推文:
我們可以在這些顏色過渡方塊上翻新單詞,以創建一個真正的Wordle遊戲數據集。
RAW Tweet數據在data/wordle/tweets.csv中給出,但是為了可用,需要將實際單詞翻新到Tweets中的顏色正方形上。執行此改裝過程需要執行一個預處理腳本,該腳本緩存了詞彙列表下可能發生的所有可能發生的顏色轉換: guess_vocab (一組可猜測的單詞)和correct_vocab (環境中一組可能的正確單詞)。結果是一個數據結構wordle.wordle_dataset.WordleHumanDataset此腳本是scripts/data/wordle/build_human_datastructure.py 。將腳本稱為:
cd scripts/data/wordle/
python build_human_datastructure.py --guess_vocab=../../../data/wordle/word_lists/wordle_official.txt --correct_vocab=../../../data/wordle/word_lists/wordle_official.txt --tweets_file=../../../data/wordle/tweets.csv --output_file=../../../data/wordle/random_human_tweet_data.json腳本的args:
--guess_vocab指定了一組猜猜單詞。--correct_vocab指定環境中可能的正確單詞的集合。--tweets_file指定推文的原始CSV文件--output_file指定在哪裡轉儲輸出。我們已經在一些單詞列表上運行預處理,結果保存在data/wordle/中。
| 單詞列表 | 預處理的推文數據文件 |
|---|---|
wordle_official.txt | random_human_tweet_data.json |
wordle_official_800.txt | random_human_tweet_data_800.json |
wordle_official_400.txt | random_human_tweet_data_400.json |
wordle_official_200.txt | random_human_tweet_data_200.json |
tweet_words.txt | human_tweet_data_true_word.json |
給定這些文件之一,您可以加載Wordle Tweet數據集這樣:
from wordle . wordle_dataset import WordleHumanDataset
data = WordleHumanDataset . from_file ( 'data/wordle/random_human_tweet_data_200.json' )
print ( data . sample_item ())我們在實驗中使用了'data/wordle/random_human_tweet_data_200.json' 。
WordleHumanDataset : __init__ def __init__ ( self , games : List [ Tuple [ str , List [ str ]]], transitions : Dict [ str , Dict [ str , List [ str ]]], use_true_word : bool , max_len : Optional [ int ], token_reward : TokenReward , game_indexes : Optional [ List [ int ]], top_p : Optional [ float ]) -> None輸入:
games: List[Tuple[str, List[str]]] - 表單的單元列表(correct_wordle_word, wordle_transitions_list) ,其中wordle_transitions_list是一個過渡的列表,指示了tweet中的顏色["<b><b><y><y><b>", "<g><b><b><b><b>", "<g><g><y><b><b>", "<g><g><g><g><g>"] 。transitions: Dict[str, Dict[str, List[str]]] - 將正確的單詞映射到另一個dict映射的dict映射可能被該詞可能引起的顏色過渡到可能播放的單詞列表,這些顏色過渡可能會播放以引起該過渡。該數據結構用於在推文上翻新單詞。use_true_word: bool - 如果為True ,請使用Tweet中的地面真相正確單詞,否則修改有效的單詞列表中的任何正確單詞。max_len: Optional[int] - 數據集中的最大序列長度將截斷所有令牌序列到此長度。如果None ,則不會截斷序列。token_reward: TokenReward - 用於應用序列的令牌級別的獎勵。對於所有實驗,我們使用持續的0獎勵。game_indexes: Optional[List[int]] - 索引列表以創建推文的拆分。如果None ,將使用數據中的所有項目。我們有data/wordle/human_eval_idxs.json和data/wordle/human_train_idxs.json創建的作為隨機選擇的火車和評估拆分。top_p: Optional[float] - top_p的過濾器執行數據的百分比。如果None ,則不會過濾數據。與%BC模型一起使用。返回: None
from_file def from_file ( cls , file_path : str , use_true_word : bool = False , max_len : Optional [ int ] = None , token_reward : Optional [ TokenReward ] = None , top_p : Optional [ float ] = None ) -> WordleHumanDataset輸入:
file_path: str - JSON文件的路徑以加載數據。use_true_word: bool - 如果為True ,請使用Tweet中的地面真相正確單詞,否則修改有效的單詞列表中的任何正確單詞。max_len: Optional[int] - 數據集中的最大序列長度將截斷所有令牌序列到此長度。如果None ,則不會截斷序列。token_reward: TokenReward - 用於應用序列的令牌級別的獎勵。對於所有實驗,我們使用持續的0獎勵。game_indexes: Optional[List[int]] - 索引列表以創建推文的拆分。如果None ,將使用數據中的所有項目。我們有data/wordle/human_eval_idxs.json和data/wordle/human_train_idxs.json創建的作為隨機選擇的火車和評估拆分。top_p: Optional[float] - top_p的過濾器執行數據的百分比。如果None ,則不會過濾數據。與%BC模型一起使用。返回: WordleHumanDataset對象。
sample_item def sample_item ( self ) -> DataPoint返回: DataPoint對象。
培訓腳本在scripts/train/wordle/中。
| 腳本 | 描述 |
|---|---|
train_bc.py | 訓練卑詩省代理商。 |
train_iql.py | 培訓ILQL代理。 |
評估腳本在scripts/eval/wordle/中。
| 腳本 | 描述 |
|---|---|
eval_policy.py | 在Wordle環境中評估BC或ILQL代理。 |
eval_q_rank.py | 一個評估腳本,用於比較在我們論文第5節中所述的合成數據集上訓練的代理的Q值的相對等級,該腳本旨在證明單步RL和多步rl之間的差異。 |
distill_policy_eval.py | 打印出具有錯誤欄的eval_policy.py的結果。 |
在這裡,我們概述瞭如何在代碼庫中加載視覺對話數據以及如何執行環境。有關如何設置視覺對話環境的遠程組件,請參見上面的設置部分。數據和環境對像是由配置管理器自動加載的,但是如果要繞過配置系統並將環境與您自己的代碼庫一起使用,則應該如何加載,執行和配置這些對象。下面描述的相同設置也可以在配置中修改。
如何加載視覺對話環境的一個示例:
from visdial . visdial_env import VDEnvironment
from visdial . visdial_base import VisDialogueData
from visdial . visdial_dataset import VisDialListDataset
from data . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = VisDialogueData (
data_path = convert_path ( 'data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.json' ),
img_feat_path = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/data_img.h5' ),
split = 'train' ,
reward_cache = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/train_rank_reward_cache1.json' ),
yn_reward_kind = 'none'
)
list_data = VisDialListDataset (
data = data ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 )
)
env = VDEnvironment (
dataset = list_data ,
url = 'http://localhost:5000/step_rank' ,
yn_reward = - 2.0 ,
yn_reward_kind = 'none'
)
print ( env . reset ())上面的腳本對應於我們為“標準”獎勵實驗配置數據集和環境的方式,但是如果您想以不同的方式配置數據集,則可以修改許多參數。除了更改數據集拆分外,這些論點還可以更改任務或獎勵。下面我們描述了VisDialogueData , VisDialListDataset和VDEnvironment take的所有不同可配置參數。
我們記錄了VisDialogueData , VisDialListDataset和VDEnvironment的參數和方法,因此您知道如何自己配置環境。
VisDialogueData :用src/visdial/visdial_base.py實現的VisDialogueData存儲任務的對話和獎勵集。
__init__ def __init__ ( self , data_path : str , img_feat_path : str , split : str , reward_cache : Optional [ str ] = None , norm_img_feats : bool = True , reward_shift : float = 0.0 , reward_scale : float = 1.0 , addition_scenes : Optional [ List [ Scene ]] = None , mode : str = 'env_stops' , cutoff_rule : Optional [ CutoffRule ] = None , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> None輸入:
data_path: str - 對話數據的路徑。應該是:data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_val.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_test.jsonimg_feat_path: str - 用於計算每個對話的獎勵的圖像功能的路徑。應始終是data/vis_dialogue/processed/visdial_0.5/data_img.h5 。split: str - train , val或test之一。指示要使用的圖像功能的哪些數據集拆分。應與data_path拆分一致。reward_cache: Optional[str]=None - 存儲每個對話的獎勵的位置。如果None ,它將將所有獎勵設置為None 。我們為兩個獎勵功能提供緩存:data/vis_dialogue/processed/visdial_0.5/[split]_rank_reward_cache1.json ,其中[split]由train , val或test之一代替。data/vis_dialogue/processed/visdial_0.5/[split]_reward_cache2.json ,其中[split]被train , val或test中的一個替換。norm_img_feats: bool=True - 是否將圖像功能歸一化。reward_shift: float=0.0 - 將獎勵轉移到此數量中。reward_scale: float=1.0 - 將獎勵縮小為此數量。addition_scenes: Optional[List[Scene]]=None - 將其他數據注入數據集。mode: str='env_stops' - ['agent_stops', 'env_stops', '10_stop']之一。控制任務的某些屬性。我們使用env_stopsmode='env_stops' ,請根據cutoff_rule提早停止環境交互。mode='agent_stops' ,則代理在操作過程中通過生成特殊<stop>令牌來停止交互;每次可能的操作之後,通過放置<stop>來增加數據。mode='10_stop' ,則播放在10輪交互後總是停止,這是Visual對話數據集中的標準配置。cutoff_rule: Optional[CutoffRule]=None - 僅當mode='env_stops'時應用。實現一個函數,該功能確定環境何時應儘早停止相互作用。我們在所有實驗中使用visdial.visdial_base.PercentileCutoffRule(1.0, 0.5)的默認值。yn_reward: float=-2.0 - 詢問是/否問題應添加的獎勵罰款。yn_reward_kind: str='none' - 指定字符串匹配的啟發式,用於確定是否問是/否問題。應該是['none', 'soft', 'hard', 'conservative']之一。'none' :不要懲罰是/否問題。這與我們論文中的standard獎勵相對應。'soft' :如果響應包含"yes"或"no"作為子字符串,則懲罰問題。'hard' :如果響應與字符串"yes"或"no"完全匹配,則懲罰問題。這對應於我們論文中的"y/n"獎勵。'conservative' :如果響應滿足幾種匹配的啟發式方法之一,則懲罰一個問題。這與我們論文中的"conservative y/n"獎勵相對應。返回: None
__len__ def __len__ ( self ) -> int返回:數據集的大小。
__getitem__ def __getitem__ ( self , i : int ) -> Scene輸入:
i: int - 數據集索引。返回:數據集中的項目。
VisDialListDataset :用src/visdial/visdial_dataset.py實施的VisDialListDataset圍繞VisDialogueData進行包裹,並將其轉換為DataPoint格式,可用於訓練離線RL代理。
__init__ def __init__ ( self , data : VisDialogueData , max_len : Optional [ int ], token_reward : TokenReward , top_p : Optional [ float ] = None , bottom_p : Optional [ float ] = None ) -> None輸入:
data: VisDialogueData - 一個存儲所有原始數據的視覺對話數據對象。max_len: Optional[int] - 數據集中的最大序列長度將截斷所有令牌序列到此長度。如果None ,則不會截斷序列。token_reward: TokenReward - 用於應用序列的令牌級別的獎勵。對於所有實驗,我們使用持續的0獎勵。top_p: Optional[float] - top_p的過濾器執行數據的百分比。如果None ,則不會過濾數據。與%BC模型一起使用。bottom_p: Optional[float] - bottom_p的過濾器執行數據的百分比。如果None ,則不會過濾數據。返回: None
size def size ( self ) -> int返回:數據集的大小。
get_item def get_item ( self , idx : int ) -> DataPoint輸入:
i: int - 數據集索引。返回:數據集中的DataPoint 。
VDEnvironment :在src/visdial/visdial_env.py中實施的VDEnvironment定義了視覺對話環境,我們的離線RL代理在評估時與之相互作用。環境涉及連接到Localhost服務器,設置部分描述瞭如何旋轉。
__init__ def __init__ ( self , dataset : RL_Dataset , url : str , reward_shift : float = 0.0 , reward_scale : float = 1.0 , actor_stop : bool = False , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> None輸入:
dataset: RL_Dataset - 採用RL_Dataset ;如上所述,特別是VisDialListDataset 。該數據集用於選擇初始狀態。url: str - 踏上環境的URL。請按照“設置”部分中的說明進行指令,以了解如何初始化與此URL相對應的Local -Host Web服務器。reward_shift: float=0.0 - 將獎勵轉移到此數量中。reward_scale: float=1.0 - 將獎勵縮小為此數量。actor_stop: bool=False - 允許演員通過生成特殊<stop>令牌提早停止交互。yn_reward: float=-2.0 - 詢問是/否問題應添加的獎勵罰款。yn_reward_kind: str='none' - 指定字符串匹配的啟發式,用於確定是否問是/否問題。應該是['none', 'soft', 'hard', 'conservative']之一。'none' :不要懲罰是/否問題。這與我們論文中的standard獎勵相對應。'soft' :如果響應包含"yes"或"no"作為子字符串,則懲罰問題。'hard' :如果響應與字符串"yes"或"no"完全匹配,則懲罰問題。這對應於我們論文中的"y/n"獎勵。'conservative' :如果響應滿足幾種匹配的啟發式方法之一,則懲罰一個問題。這與我們論文中的"conservative y/n"獎勵相對應。返回: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]輸入:
action: Vocabulary - 環境的詞彙回報:(觀察,獎勵,終端)元組。
reset def reset ( self ) -> WordleObservation回報:觀察
is_terminal def is_terminal ( self ) -> bool回報:布爾值表示交互是否已終止。
培訓腳本在scripts/train/vis_dial/中。
| 腳本 | 描述 |
|---|---|
train_bc.py | 訓練卑詩省代理商。 |
train_chai.py | 訓練柴特工。 |
train_cql.py | 培訓CQL代理。 |
train_dt.py | 訓練決策變壓器代理。 |
train_iql.py | 培訓ILQL代理。 |
train_psi.py | 訓練 |
train_utterance.py | 培訓講話級的ILQL代理。 |
評估腳本在scripts/eval/vis_dial/中。
| 腳本 | 描述 |
|---|---|
eval_policy.py | 在視覺對話環境中評估代理。 |
top_advantage.py | 找到模型下具有最大和最小優勢的問題。 |
distill_policy_eval.py | 打印出具有錯誤欄的eval_policy.py的結果。 |
在這裡,我們概述瞭如何在代碼庫中加載Reddit註釋數據以及如何執行環境。有關如何設置毒性過濾器獎勵,請參見上面的設置部分。數據和環境對像是由配置管理器自動加載的,但是如果要瀏覽配置系統並將任務與自己的代碼庫一起使用,則應該如何加載,執行和配置這些對象。下面描述的相同設置也可以在配置中修改。
如何加載Reddit評論環境的一個示例:
from toxicity . toxicity_env import ToxicityEnvironment
from toxicity . reddit_comments_base import RedditData
from toxicity . reward_fs import toxicity_reward
from utils . misc import convert_path
idxs = json . load ( open ( convert_path ( 'data/reddit_comments/train_idxs.json' ), 'r' ))
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = idxs ,
reward_f = toxicity_reward
)
env = ToxicityEnvironment (
data = data ,
reward_f = toxicity_reward
)
print ( env . reset ())
上面的腳本對應於我們如何為毒性獎勵實驗配置環境,但是如果您想以不同的方式配置環境,則可以修改一些參數。這些論點也可以改變任務或獎勵。下面我們描述了我們的獎勵功能, RedditData , ToxicityListDataset和ToxicityEnvironment的所有不同可配置參數。
我們記錄了不同的reddit評論獎勵功能, RedditData , ToxicityListDataset和ToxicityEnvironment的參數和方法,以便您知道如何自己配置環境。
在這裡,我們概述了用於Reddit評論任務的4個主要獎勵功能。這些獎勵中的每一個都在src/toxicity/reward_fs.py中實現。
toxicity_reward from toxicity . reward_fs import toxicity_reward
reward_f = toxicity_reward ()描述:
我們的論文獎勵GPT-3毒性過濾器的“毒性”獎勵。它為無毒評論分配了“ 0”的值,將“ 1”的值分配給中等毒性的評論,而“ 2”的值為“ 2”。
toxicity_noised_reward from toxicity . reward_fs import toxicity_noised_reward
reward_f = toxicity_noised_reward ()描述:
我們的論文的“噪聲毒性”獎勵與toxicity_noised_reward相同,但會引起額外的噪音。具體而言,它以同樣的概率重新分配標記為“ 1”(中等毒性)的註釋為“ 0”(無毒)或“ 2”(極有毒)。
score_human_reward from toxicity . reward_fs import score_human_reward
from utils . misc import convert_path
reward_f = score_human_reward (
reddit_path = convert_path ( 'data/reddit_comments/' ),
indexes = None
)描述:
我們的論文的“支持真實”的獎勵,該獎勵為積極的評論提供了+1的獎勵,而負面評論的獎勵為-1。這使用了數據中的地面真相投票,因此它僅適用於數據集中的註釋,不能用於評估。如果輸入數據中不存在的字符串,則會錯誤。此功能的參數指定要加載的數據。
輸入:
reddit_path: str - 數據的路徑。indexes: List[int] - 數據中的索引分配。如果None ,它將考慮所有數據。 model_reward from toxicity . reward_fs import score_human_reward
from toxicity . reddit_comments_base import RedditData
from toxicity . toxicity_dataset import ToxicityListDataset
from toxicity . reward_model import RobertaBinaryRewardModel
from utils . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = None ,
reward_f = None
)
listdata = ToxicityListDataset (
data = data ,
max_len = 512 ,
token_reward = ConstantTokenReward ( 0.0 )
)
model = RobertaBinaryRewardModel (
data = listdata ,
device = 'cuda' ,
roberta_kind = 'roberta-base' ,
freeze_roberta = False ,
reward_cuttoff = 0.0
)
model . load_state_dict ( torch . load ( convert_path ( 'outputs/toxicity/upvote_reward/model.pkl' ), map_location = 'cpu' ))
reward_f = score_human_reward ( model = model )描述:
如果給定模型預測該評論將獲得積極數量的投票和-1的獎勵,則我們的論文的“投票模型”獎勵將獲得+1的獎勵。我們用於實驗的模型檢查點是: outputs/toxicity/upvote_reward/model.pkl
輸入:
model: RewardModel : src/toxicity/reward_model.py中實現的獎勵模型。該模型應首先訓練並從Pytorch檢查點加載。RedditData : RedditData ,在src/toxicity/reddit_comments_base.py中實施,存儲原始的reddit註釋數據。
__init__ def __init__ ( self , path : str , indexes : Optional [ List [ int ]], reward_f : Optional [ Callable [[ str ], float ]], reward_cache : Optional [ Cache ] = None , reward_shift : float = 0.0 , reward_scale : float = 1.0 ) -> None輸入:
path: str - REDDIT數據的路徑。indexes: Optional[List[int]] - 創建數據拆分的索引列表。 JSON文件中隨機選擇,培訓,驗證和測試拆分:data/reddit_comments/train_idxs.jsondata/reddit_comments/eval_idxs.jsondata/reddit_comments/test_idxs.jsonreward_f: Optional[Callable[[str], float]] - 使用的獎勵功能。reward_cache: Optional[Cache]=None - 獎勵值的緩存,因此您不必每次都重新計算它們。reward_shift: float=0.0 - 將獎勵轉移到此數量中。reward_scale: float=1.0 - 將獎勵縮小為此數量。返回: None
__len__ def __len__ ( self ) -> int返回:數據集的大小。
__getitem__ def __getitem__ ( self , idx : int ) -> Scene輸入:
idx: int - 數據集索引。返回:數據集中的項目。
ToxicityListDataset : src/toxicity/toxicity_dataset.py實施的ToxicityListDataset圍繞RedditData包裹,並將其轉換為DataPoint格式,可用於訓練離線RL代理。
__init__ def __init__ ( self , data : RedditData , max_len : Optional [ int ], token_reward : TokenReward , cuttoff : Optional [ float ] = None , resample_timeout : float = 0.0 , include_parent : bool = True ) -> None輸入:
data: RedditData - 一個存儲所有原始數據的Reddit評論數據對象。max_len: Optional[int] - 數據集中的最大序列長度將截斷所有令牌序列到此長度。如果None ,則不會截斷序列。token_reward: TokenReward - 用於應用序列的令牌級別的獎勵。對於所有實驗,我們使用持續的0獎勵。cuttoff: Optional[float]=None - 過濾數據集中的所有註釋,獎勵小於cuttoff 。如果None ,則不會過濾數據。與%BC模型一起使用。resample_timeout: float=0.0 - 當cuttoff不等於None時,即使數據集具有列表類型接口,也可以從數據集中對IID進行隨機採樣。它統一地從數據集中重新示例,直到找到滿足Cuttoff的獎勵的評論為止。在“毒性”獎勵的情況下,這種重新採樣可能會在GPT-3 API上導致速率限制錯誤,因此我們允許您添加一個resample_timeout來解決此問題:大約0.05的超時性應解決利率限制問題。include_parent: bool=True - 是否在線程中的父評論中調節。如果是False ,將培訓模型以無條件生成評論。返回: None
size def size ( self ) -> int返回:數據集的大小。
get_item def get_item ( self , idx : int ) -> DataPoint輸入:
i: int - 數據集索引。返回:數據集中的DataPoint 。
ToxicityEnvironment :在src/toxicity/toxicity_env.py中實施的ToxicityEnvironment定義了Reddit評論生成環境,我們的離線RL代理在評估時與之相互作用。
__init__ def __init__ ( self , data : RedditData , reward_f : Optional [ Callable [[ str ], float ]], reward_shift : float = 0.0 , reward_scale : float = 1.0 , include_parent : bool = True ) -> None輸入:
data: RedditData - 用於選擇初始狀態父評論以進行條件的數據集。reward_f: Optional[Callable[[str], float]] - 使用的獎勵功能。reward_shift: float=0.0 - 將獎勵轉移到此數量中。reward_scale: float=1.0 - 將獎勵縮小為此數量。include_parent: bool=True - 指定是在上一個註釋中調節還是在reddit線程中發布。返回: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]輸入:
action: Vocabulary - 環境的詞彙回報:(觀察,獎勵,終端)元組。
reset def reset ( self ) -> WordleObservation回報:觀察
is_terminal def is_terminal ( self ) -> bool回報:布爾值表示交互是否已終止。
培訓腳本在scripts/train/toxicity/中。
| 腳本 | 描述 |
|---|---|
train_bc.py | 訓練卑詩省代理商。 |
train_iql.py | 培訓ILQL代理。 |
train_upvote_reward.py | 培訓投票獎勵模型。 |
評估腳本在scripts/eval/toxicity/中。
| 腳本 | 描述 |
|---|---|
eval_policy.py | 在Reddit評論環境中評估代理。 |
distill_policy_eval.py | 打印出具有錯誤欄的eval_policy.py的結果。 |
如上所述,所有任務(Wordle,Visual對話,Reddit)都具有在代碼庫中實現的相應環境和數據集。代碼庫中的所有離線RL算法均已在這些給定的環境和數據集之一上訓練,執行和評估。
您可以類似地定義自己的任務,這些任務可以輕鬆地在所有這些離線RL算法上運行。該代碼庫實現了一組簡單的RL環境抽象集,使得可以定義自己的環境和數據集,這些環境和數據集可以使用任何離線RL算法插件。
所有核心抽象均在src/data/中定義。在這裡,我們概述了需要實現的內容才能創建自己的任務。如有示例,請參見src/wordle/ , src/vis_dial/和src/toxicity/中的實現。
所有任務都必須實現以下子類: Language_Observation和Language_Environment ,該子類在src/data/language_environment.py中。
Language_Observation :該類代表將向您的語言模型輸入的環境的觀察。
Language_Observation必須定義以下兩個函數。
to_sequence def to_sequence ( self ) -> Tuple [ List [ str , Optional [ float ]], bool ]:描述:
將觀察對象轉換為標準格式的函數,該格式可以輸入到語言模型並用於培訓。
返回:
__str__ def __str__ ( self ) -> str :描述:
這僅用於將觀測值打印到終端。它應該將觀察值轉換為用戶可以解釋的某種字符串。
返回:字符串。
Language_Environment :該課程代表了用於在線互動的體育型環境,僅用於評估。
語言_environment必須定義以下三個函數。
step def step ( self , action : str ) -> Tuple [ Language_Observation , float , bool ]:描述:
就像標準的健身房環境一樣,以弦的形式採取行動,將環境前進。
返回:元組(Lagans_Observation,Reward,終端)。
reset def reset ( self ) -> Language_Observation :描述:
這將環境重置為初始狀態。
返回:相應的初始Language_Observation
is_terminal def is_terminal ( self ) -> bool :描述:
輸出環境是否已達到末端狀態。
回報:一個布爾值,指示環境是否已達到終端狀態。
所有任務必須實現List_RL_Dataset或Iterable_RL_Dataset或兩者的子類,這些子類是在src/data/rl_data.py中定義的。
List_RL_Dataset :該類代表可用於訓練離線RL代理的列表數據集(或有限長度的可索引數據集)。
List_RL_Dataset必須定義以下兩個函數。
get_item def get_item ( self , idx : int ) -> DataPoint描述:
這以給定索引從數據集獲取項目。
返回:數據集中的DataPoint對象。
size def size ( self ) -> int描述:
返回數據集的大小。
返回:數據集的大小。
Iterable_RL_Dataset :該類代表可用於訓練離線RL代理訓練的數據集(或隨機示例數據點IID的不可索引的數據集)。
Iterable_RL_Dataset必須定義以下功能。
sample_item def sample_item ( self ) -> DataPoint描述:
從數據集中示例數據點。
返回:數據集中的DataPoint對象。


