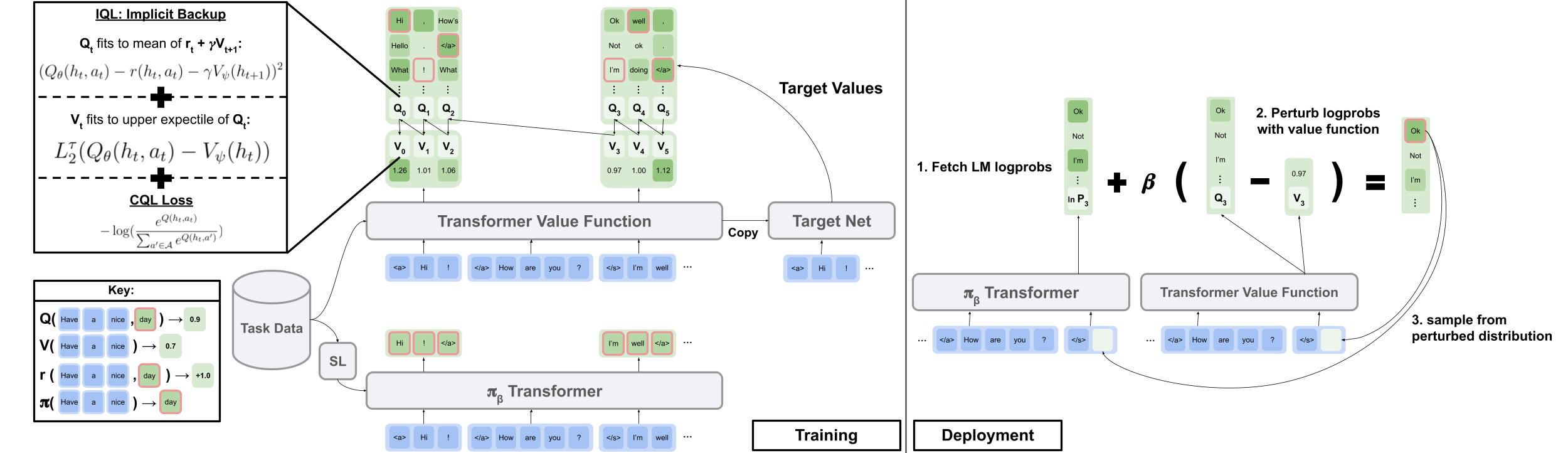
Implicit Language Q Learning
1.0.0
Offizieller Code aus dem Papier "Offline RL für die Erzeugung natürlicher Sprache mit implizitem Sprache Q -Lernen"
Projektseite | Arxiv
Laden Sie data.zip und outputs.zip im Google Drive -Ordner hier herunter. Platzieren Sie die heruntergeladenen und unzippierten Ordner, data/ und outputs/ , am Root des Repo. data/ enthält die vorverarbeiteten Daten für alle unsere Aufgaben outputs/ gibt den Kontrollpunkt für unsere Reddit -Kommentare auf.
Dieses Repo wurde für Python 3.9.7 konzipiert
pip install -r requirements.txt
export PYTHONPATH= " $PWD /src/ "Um die visuellen Dialog -Experimente durchzuführen, müssen Sie die visuelle Dialogumgebung auf Localhost dienen, indem Sie den Anweisungen hier folgen.
Um die Reddit -Kommentarversuche mit der Belohnung des Toxizitätsfilters durchzuführen:
export OPENAI_API_KEY=your_API_key scripts/ enthält alle Experimentskripte. So führen Sie ein Skript in scripts/ :
python script_name.pyOptional:
python script_name.py eval.bsize=5 train.lr=1e-6 wandb.use_wandb=falsepython -m torch.distributed.launch --nproc_per_node [N_GPUs] --use_env script_name.py arg1=a arg2=b Daten parallele Schulung oder Bewertung an mehreren GPUs aus: Standardmäßig protokollieren alle Trainingsskripte bei Wandb. Um dies auszuschalten, setzen Sie in der Trainingskonfiguration wandb.use_wandb=false .
Hier skizzieren ich einen empfohlenen Workflow für das Training von Offline -RL -Agenten. Angenommen, ich möchte eine Reihe verschiedener Offline -RL -Agenten trainieren, um Reddit -Kommentare mit der Toxizitätsbelohnung zu generieren.
Ich würde zuerst ein BC -Modell für die Daten trainieren:
cd scripts/train/toxicity/
python train_bc.pyKonvertieren Sie diesen BC -Checkpoint dann in einen mit den Offline -RL -Modellen kompatibel:
cd ../data/
python convert_bc.py --load ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model.pkl --save ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model_converted.pklBearbeiten Sie dann den Checkpoint, den Offline RL so konfiguriert ist, dass sie trainieren mit:
cd ../train/
python train_iql.py model.load.checkpoint_path=outputs/toxicity/model_converted.pkl model.load.strict_load=false train.loss.awac_weight=0.0 Dies ist jedoch nur ein Workflow. Sie können das BC -Modell auch gleichzeitig mit dem Offline -RL -Agenten schulen, indem Sie in der Trainingskonfiguration train.loss.awac_weight=1.0 einstellen.
data/ Ordner vorverarbeitet.scripts/ enthält alle Skripte zum Ausführen von Schulungen, Bewertungen und Datenvorbereitungsschritten im Papier. Skripte werden in Unterordner organisiert, die dem verwendeten Datensatz entsprechen.config/ enthält .yaml configs für jedes Skript. Dieses Repo verwendet Hydra, um Konfigurationen zu verwalten. Konfigurationen werden in Unterordner organisiert, die dem verwendeten Datensatz entsprechen. Die meisten Konfigurationsdateien werden mit ihrem entsprechenden Skript benannt. Wenn Sie jedoch nicht sicher sind, welche Konfiguration einem Skript entspricht, überprüfen Sie die Zeile @hydra.main(config_path="some_path", config_name="some_name") um zu sehen, welcher Konfigurationsdatei das Skript entspricht.src/ enthält alle Kernimplementierungen. Siehe src/models/ für alle Modellimplementierungen. Siehe src/data/ für alle Basisdatenverarbeitung und MDP -Abstraktionscode. Siehe src/utils/ für verschiedene Dienstprogrammfunktionen. Siehe src/wordle/ , src/visdial und src/toxicity/ für alle Wurm-, visuellen Dialog- und Reddit -Kommentar -Datensatz -Codes.ILQL wird im gesamten Repo als iql bezeichnet. Jedes Skript ist einer Konfigurationsdatei zugeordnet. Die Konfigurationsdatei gibt an, welche Modelle, Datensatz und Evaluatoren vom Skript und ihren entsprechenden Hyperparametern geladen werden sollen. Ein Beispiel finden Sie configs/toxicity/train_iql.yaml .
Jedes mögliche Modell-, Datensatz- oder Evaluator -Objekt erhält eine eigene Konfigurationsdatei, in der die Standardwerte für dieses Objekt und ein spezielles name angegeben sind, wodurch der Konfigurationsmanager mitgeteilt wird, welche Klasse ist. Ein Beispiel finden Sie configs/toxicity/model/per_token_iql.yaml .
Die Dateien src/load_objects.py , src/wordle/load_objects.py , src/visdial/load_objects.py und src/toxicity/load_objects.py Definieren Sie, wie jedes Objekt aus seiner entsprechenden Konfiguration geladen wird. Das @register('name') tag über jede Ladeobjektfunktion wird mit dem name in der Konfiguration verknüpft.
Möglicherweise bemerken Sie ein spezielles cache_id -Attribut, das einigen Objekten in einer Konfiguration zugeordnet ist. In einem Beispiel siehe train_dataset in configs/toxicity/train_iql.yaml . In diesem Attribut wird der Konfigurationsmanager angewiesen, das erste Objekt zu zwischenstrahlen, das dieser ID zugeordnet ist, und dieses zwischenfolgende Objektkonfigurationen mit diesem cache_id zurückzugeben.
Verwenden Sie für alle Konfigurationen Pfade relativ zum Repo -Stamm.
Jede der Aufgaben in unserem Repo - Wurm, visueller Dialog und Reddit -Kommentare - implementiert einige Basisklassen. Nach der Implementierung können alle Offline-RL-Algorithmen auf die Aufgabe auf Plug-and-Play-Weise angewendet werden. In dem Abschnitt "Erstellen Ihrer eigenen Aufgaben" finden Sie einen Überblick darüber, was implementiert werden sollte, um Ihre eigenen Aufgaben zu erstellen. Im Folgenden skizzieren wir die wichtigsten Abstraktionen, die dies ermöglichen.
data.language_environment.Language_Environment - repräsentiert eine Task -POMDP -Umgebung, mit der eine Richtlinie interagieren kann. Es hat eine im Fitnessstudio-ähnliche Oberfläche.data.language_environment.Policy - repräsentiert eine Richtlinie, die mit einer Umgebung interagieren kann. Jede der Offline -RL -Algorithmen in src/models/ hat eine entsprechende Richtlinie.data.language_environment.Language_Observation - repräsentiert eine Textbeobachtung, die von der Umgebung zurückgegeben und als Eingabe für eine Richtlinie angegeben wird.data.language_environment.interact_environment - Eine Funktion, die eine Umgebung, eine Richtlinie und optional die aktuelle Beobachtung übernimmt und eine Umgebungs -Interaktionsschleife ausführt. Wenn die aktuelle Beobachtung nicht bereitgestellt wird, holt sie automatisch einen Ausgangszustand durch Zurücksetzen der Umgebung.data.rl_data.DataPoint - definiert ein standardisiertes Datenformat, das als Eingabe für alle Offline -RL -Agenten bei allen Aufgaben gefüttert wird. Diese Datenstrukturen werden automatisch aus einer bestimmten Language_Observation erstellt.data.rl_data.TokenReward - definiert eine Belohnungsfunktion, die an jedem einzelnen Token angegeben ist und das zum Erlernen einer feinkörnigsten Kontrolle verwendet werden kann. Dies wird zusätzlich zur Belohnung der Umgebung bereitgestellt, die nicht bei jedem Token, sondern nach jeder Interaktionswende kommt. In all unseren Experimenten setzen wir diese Belohnung auf eine Konstante 0, so dass sie keine Wirkung hat.data.tokenizer.Tokenizer - Gibt an, wie Strings in und von Sequenzen von Token konvertiert werden, die dann als Eingabe in Sprachmodelle eingespeist werden können.data.rl_data.RL_Dataset - definiert ein Dataset -Objekt, das DataPoint -Objekte zurückgibt und für das Training von Offline -RL -Agenten verwendet wird. Es gibt zwei Versionen von RL_Dataset :List_RL_DatasetIterable_RL_Dataset
Hier skizzieren und dokumentieren wir alle Komponenten unserer Wurmaufgabe.
Ein Großteil der in den Beispiel -Skripten steckenden Skripten erfolgt automatisch vom Konfigurationsmanager, und die entsprechenden Parameter können durch Ändern der Konfigurationen bearbeitet werden. Wenn Sie jedoch die Konfigurationen umgehen und die Wurmaufgabe mit Ihrer eigenen Codebasis verwenden möchten, können Sie die folgenden Skripte und Dokumentationen dazu verweisen, wie dies zu tun ist.
Ein einfaches Beispiel -Skript zum Abspielen von Wörtern in der Befehlszeile.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from wordle . policy import UserPolicy
from data . language_environment import interact_environment
from utils . misc import convert_path
game_vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( game_vocab )
policy = UserPolicy ()
interact_environment ( env , policy )src/wordle/wordle_game.pysrc/wordle/wordle_env.pysrc/wordle/policy.pysrc/wordle/wordle_dataset.pyUm das Spiel zu einem gültigen MDP zu machen, repräsentiert die Umgebung den zugrunde liegenden Zustand als eine Reihe von bekannten Buchstabenbeschränkungen und verwendet diese, um das Wortschatz für Wörter zu filtern, die alle diese Einschränkungen in jeder Runde einhalten. Anschließend wird ein zufälliges Wort aus dieser filtrierten Wortliste ausgewählt und verwendet, um die von der Umgebung zurückgegebenen Farbübergänge zu bestimmen. Diese neuen Farbübergänge aktualisieren dann den Satz bekannter Buchstabenbeschränkungen.
Die Wurmumgebung nimmt eine Wortliste auf. Einige Wortlisten finden Sie in data/wordle/word_lists/ , aber Sie können Ihre eigenen machen.
Die enthaltenen Wortlisten sind:
Das Wort Listen werden durch ein Vocabulary wie im obigen Beispiel in die Umgebung geladen.
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))Das Wortschatz speichert nicht nur die Wortliste, sondern verfolgt auch eine gefilterte Liste von Wörtern, die alle bekannten Buchstabenbeschränkungen in einem bestimmten Zustand erfüllen. Diese Liste wird verwendet, um Übergänge in der Umgebung zu berechnen und von einigen handgefertigten Richtlinien verwendet.
Das Erstellen dieser gefilterten Listen in Echtzeit kann den Umwelt -Interaktionsprozess verlangsamen. Dies sollte normalerweise kein Problem sein, aber wenn Sie schnell viele Daten aus einer Richtlinie synthetisieren möchten, kann dies ein Engpass werden. Um dies zu überwinden, speichern alle Vocabulary ein cache -Argument, das diese gefilterten Wortlisten zwischen einem bestimmten Zustand zwischengespeichert. vocab.cache.load(f_path) und vocab.cache.dump() ermöglicht das Laden und Speichern dieses Cache. Beispielsweise ist data/wordle/vocab_cache_wordle_official.pkl ein großer Cache für die Liste wromdle_official.txt.
Das Vocabulary ist nicht nur ein Cache implementiert, sondern implementiert die folgenden Methoden in src/wordle/wordle_game.py :
__init__ def __init__ ( self , all_vocab : List [ str ],
wordle_state : Optional [ WordleState ],
cache : Optional [ Cache ] = None ,
fill_cache : bool = True ) -> NoneEingänge:
all_vocab: List[str] - Eine Liste von Wörtern.wordle_state: Optional[WordleState] - Ein Zustand, aus dem die Liste der gefilterten Wortliste generiert werden kann, wenn kein Zustand bereitgestellt wird, werden keine Wörter gefiltert.cache: Optional[Cache]=None - Ein Cache für das gefilterte Vokabel, wie oben beschrieben.fill_cache: bool=True - Ob zum Cache hinzugefügt werden soll. Rückkehr: None
from_file def from_file ( cls , vocab_file : str , fill_cache : bool = True ) -> VocabularyEingänge:
vocab_file: str - Eine Datei, aus der die Wörter geladen werden können. Die Methode wählt nur die Wörter aus, die 5 Buchstaben lang sind.fill_cache: bool=True - Ob zum Cache hinzugefügt werden soll. Rückkehr: Vocabulary
filtered_vocab_size def filtered_vocab_size ( self ) -> intRückgabe: Die Größe des gefilterten Wortschatzes
all_vocab_size def all_vocab_size ( self ) -> intRückgabe: Die Größe des vollständigen Glasvokabulars
get_random_word_filtered def get_random_word_filtered ( self ) -> strRückgabe: Ein zufälliges Wort aus der gefilterten Liste.
get_random_word_all def get_random_word_all ( self ) -> strRückgabe: Ein zufälliges Wort aus der vollständigen ungefilterten Liste.
update_vocab def update_vocab ( self , wordle_state : WordleState ) -> VocabularyEingänge:
wordle_state: WordleState - Ein Wurmzustandsobjekt, das den Satz bekanntem Buchstabenbeschränkungen darstellt. Rückgabe: Ein neues Vocabulary , das gemäß wordle_state gefiltert wird.
__str__ def __str__ ( self ) -> strRückgaben: Eine Zeichenfolgendarstellung der filtrierten Wortliste zum Drucken zum Terminal.
WordleEnvironment nimmt ein Vokabularobjekt als Eingabe an, das die mögliche korrekte Wörter in der Umgebung definiert.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( vocab )
initial_obs = env . reset ()
next_obs , reward , terminal = env . step ( "snake" ) Wie oben gezeigt, implementiert die Umgebung eine im Fitnessstudio-ähnliche Schnittstelle in src/wordle/wordle_env.py :
__init__ def __init__ ( self , vocab : Vocabulary ) -> NoneEingänge:
vocab: Vocabulary - Das Vokabular der Umgebung. Rückkehr: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Eingänge:
action: Vocabulary - Eine Textzeichenfolge, die die Aktion eines Agenten in der Umgebung darstellt.Rückgabe: Ein (Beobachtung, Belohnung, Terminal) Tupel.
reset def reset ( self ) -> WordleObservationRückgabe: Eine Beobachtung.
is_terminal def is_terminal ( self ) -> boolRückgabe: Ein Boolescher Angabe, der angezeigt wird, ob die Interaktion beendet ist.
Wir implementieren eine Reihe von handgefertigten Wurmrichtlinien, die eine Reihe von Gameplay-Levels abdecken. All dies wird in src/wordle/policy.py implementiert. Hier beschreiben wir jeden:
UserPolicy from wordle . policy import UserPolicy
policy = UserPolicy ( hint_policy = None , vocab = None )Beschreibung:
Lass dich im Terminal spielen.
Eingänge:
hint_policy: Optional[Policy] - Eine weitere Richtlinie zum Abfragen, wenn Sie einen Hinweis darauf haben möchten, welches Wort verwendet werden soll.vocab: Optional[Union[str, Vocabulary]] - Ein Vocabulary von erratenen Wörtern. Wenn nicht angegeben, ist eine 5 -Buchstaben -Sequenz von Zeichen eine gültige Vermutung. StartWordPolicy from wordle . policy import StartWordPolicy
policy = StartWordPolicy ()Beschreibung:
Nur für das erste Wort angewendet werden. Wählt ein Wort zufällig aus einer Liste kuratierter, hochwertiger Startwörter aus.
Eingänge:
start_words: Optional[List[str]]=None - Überschreiben Sie die kuratierte Liste der Startwörter. OptimalPolicy from wordle . policy import OptimalPolicy
policy = OptimalPolicy ()Beschreibung:
Spielt myopisch die höchsten Informationsgewinn -Wort aus der Wortliste, die alle bekannten Buchstabenbeschränkungen entspricht. Diese Richtlinie ist eigentlich nicht optimal, da ein optimales Spiel NP-Hard ist. Aber es spielt auf einem extrem hohen Niveau und kann als ungefähre Obergrenze für die Leistung verwendet werden. Diese Richtlinie ist sehr langsam zu berechnen, wobei die Leistung quadratisch in der Größe der Wortliste ist. Um Berechnungen zu speichern, können Sie self.cache.load(f_path) und self.cache.dump() laden und speichern. Beispielsweise repräsentiert data/wordle/optimal_policy_cache_wordle_official.pkl einen Cache für diese Richtlinie in der Wortliste wordle_official.txt .
Eingänge:
start_word_policy: Optional[Policy]=None - Da das erste Wort im Allgemeinen am teuersten für die Berechnung von Informationen zu Gewinne ist, können Sie eine andere Richtlinie angeben, die nur für das erste Wort gefordert werden soll.progress_bar: bool=False - Da es so lange dauern kann, dass berechnet wird, lassen wir Sie die Möglichkeit, für jeden self.act einen Fortschrittsbalken anzuzeigen. RepeatPolicy from wordle . policy import RepeatPolicy
policy = RepeatPolicy ( start_word_policy = None , first_n = 2 )Beschreibung:
Nach dem Zufallsprinzip wiederholt eines der bereits verwendeten first_n -Wörter. Dies ist eine maximal suboptimale Politik, da sie niemals gewinnen kann, es sei denn, es hat das Glück beim ersten Wort.
Eingänge:
start_word_policy: Optional[Policy] - Eine Richtlinie, die für die Auswahl des ersten Wortes verwendet werden soll. Wenn None , dann wählen Sie zufällig ein Wort aus dem Wortschatz der Umgebung aus.first_n: Optional[int] - Die Richtlinie wählt zufällig das nächste Wort aus den first_n -Wörtern im Geschichte aus. Wenn None , wird es zufällig aus der vollständigen Geschichte ausgewählt. RandomMixturePolicy from wordle . policy import RandomMixturePolicy
policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )Beschreibung:
Wählt ein Wort aus einer Wortliste mit Wahrscheinlichkeit (1 - prob_smart) einer Wortliste aus und wählt ein zufälliges Wort aus der Wortliste, das alle bekannten Buchstabenbeschränkungen mit Wahrscheinlichkeit prob_smart erfüllt.
Eingänge:
prob_smart: float - Die Wahrscheinlichkeit, ein Wort auszuwählen, das alle bekannten Buchstabenbeschränkungen entspricht, und nicht ein vollständig zufälliges.vocab: Optional[Union[str, Vocabulary]] - Eine Wortliste zum Auswahl. Wenn None , dann stand die Richtlinie standardmäßig mit der Wortliste der Umgebung. WrongPolicy from wordle . policy import WrongPolicy
from wordle . wordle_game import Vocabulary
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
policy = WrongPolicy ( vocab )Beschreibung:
Wählt zufällig ein Wort aus einer Wortliste aus, die nicht alle bekannten Buchstabenbeschränkungen erfüllt und daher nicht das richtige Wort sein kann. Wenn alle Wörter in der Wortliste die Buchstabenbeschränkungen erfüllen, wählt es aus der Liste ein Wort zufällig aus. Diese Richtlinie ist sehr suboptimal.
Eingänge:
vocab: Union[str, Vocabulary] - Eine Wortliste zur Auswahl. MixturePolicy from wordle . policy import MixturePolicy , OptimalPolicy , RandomMixturePolicy
policy1 = OptimalPolicy ()
policy2 = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MixturePolicy ( prob1 = 0.5 , policy1 = policy1 , policy2 = policy2 )Beschreibung:
Mischt zwei gegebene Richtlinien. Wählen Sie mit der Wahrscheinlichkeit prob1 aus policy1 und wählen Sie mit Wahrscheinlichkeit (1 - prob1) aus policy2 .
Eingänge:
prob1: float - Die Wahrscheinlichkeit, eine Aktion aus policy1 auszuwählen1.policy1: Policy - Die erste Richtlinie zur Auswahl von Aktionen. Ausgewählt mit Wahrscheinlichkeit prob1 .policy1: Policy - Die zweite Richtlinie zur Auswahl von Aktionen aus. Ausgewählt mit Wahrscheinlichkeit (1 - prob1) . MonteCarloPolicy from wordle . policy import MonteCarloPolicy
sample_policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MonteCarloPolicy ( n_samples = 5 , sample_policy = sample_policy )Beschreibung:
Ernimmt eine Richtlinie, führt n_samples von Monte -Carlo -Rollouts in der Umgebung aus und wählt die nächste Aktion aus, die während des Rollout -Prozesses die höchste durchschnittliche Belohnung erhielt.
Eingänge:
n_samples: int - Die Anzahl der Monte -Carlo -Rollouts, die ausgeführt werden sollen.sample_policy: Policy - die Richtlinie zum Beispiel Rollouts von. 
Jede der oben genannten Richtlinien kann verwendet werden, um Datensätze zu generieren, mit denen Offline -RL -Agenten trainiert werden können. Wir implementieren zwei Arten von synthetischen Datensätzen in src/wordle/wordle_dataset.py :
wordle.wordle_dataset.WordleListDataset - lädt Wordle -Spiele aus einer Datei.wordle.wordle_dataset.WordleIterableDataset - Beispiele für Writle -Spiele aus einer bestimmten Richtlinie.WordleListDataset :Laden Sie einen Wurmdatensatz aus einer Datei wie SO:
from wordle . wordle_dataset import WordleListDataset
from data . rl_data import ConstantTokenReward
data = WordleListDataset . from_file (
file_path = 'data/wordle/expert_wordle_100k.pkl' ,
max_len = None ,
vocab = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
for i in range ( data . size ()):
item = data . get_item ( i )__init__ def __init__ ( self , items : List [ Tuple [ WordleObservation , Optional [ Dict [ str , Any ]]]], max_len : Optional [ int ], token_reward : TokenReward ) -> NoneEingänge:
items: List[Tuple[WordleObservation, Optional[Dict[str, Any]]]] - Eine Liste von Daten in Form von Tupeln (wordleobservation, metadata_dict). Wo metadata_dict jede Art von Metadaten eine Art Metadaten ist, die Sie möglicherweise im Datenpunkt speichern möchten.max_len: Optional[int] - Die maximale Sequenzlänge im Datensatz schneidet alle Token -Sequenzen auf diese Länge ab. Wenn None , dann werden Sequenzen nicht abgeschnitten.token_reward: TokenReward -Die Belohnung auf Token-Ebene, die für die Sequenzen gelten. Wir verwenden für alle Experimente eine ständige Belohnung von 0 pro Erfreue. Rückkehr: None
from_file def from_file ( cls , file_path : str , max_len : Optional [ int ], vocab : Optional [ Vocabulary ], token_reward : TokenReward ) -> WordleListDatasetEingänge:
file_path: str - Der Pfad zur Datenfahnendatei.max_len: Optional[int] - Die maximale Sequenzlänge im Datensatz schneidet alle Token -Sequenzen auf diese Länge ab. Wenn None , dann werden Sequenzen nicht abgeschnitten.vocab: Optional[Vocabulary] - Simulieren Sie den Datensatz unter einem anderen Umgebungsvokabular. Wenn None , standardmäßig die Verwendung desselben Vokabulars, mit dem der Datensatz erstellt wurde.token_reward: TokenReward -Die Belohnung auf Token-Ebene, die für die Sequenzen gelten. Wir verwenden für alle Experimente eine ständige Belohnung von 0 pro Erfreue. Rückgabe: Ein WordleListDataset -Objekt.
get_item def get_item ( self , idx : int ) -> DataPointEingänge:
idx: int - Ein Index im Datensatz. Rückgabe: Ein DataPoint -Objekt.
size def size ( self ) -> intRückgabe: Die Größe des Datensatzes.
Die folgenden Skripte in scripts/data/wordle/ können verwendet werden, um Wurmdaten zu synthetisieren.
| Skript | Beschreibung |
|---|---|
generate_data.py | Beispiele eine Reihe von Spielen aus einer in der Konfiguration angegebenen Richtlinie und speichert sie in einer Datei. |
generate_data_mp.py | Das gleiche wie generate_data.py außer Samples -Spielen parallel zu mehreren Prozessen. |
generate_adversarial_data.py | Synthese des in Abschnitt 5 unseres Papiers beschriebenen Datensatzes, der den Unterschied zwischen Einzelstufen- und Mehrschritt-Methoden demonstrieren sollte. |
generate_adversarial_data_mp.py | Das gleiche wie generate_adversarial_data.py außer Beispielspielen parallel zu mehreren Prozessen. |
generate_data_branch.py | Beispiele von einer bestimmten "Experten" -Richtlinie und dann aus jeder Aktion im Spiel, eine "suboptimale" Politik, die eine Reihe neuer Spiele abtastet. |
generate_data_branch_mp.py | Das gleiche wie generate_data_branch.py außer Samples -Spielen parallel zu mehreren Prozessen. |
Einige bereitgestellte synthetische Wurmdatensätze sind in data/wordle/ .
| Datei | Beschreibung |
|---|---|
expert_wordle_100k_1.pkl | 100K -Spiele aus OptimalPolicy . |
expert_wordle_100k_2.pkl | Weitere 100.000 Spiele stammen aus der OptimalPolicy . |
expert_wordle_adversarial_20k.pkl | Der in Abschnitt 5 unseres Papiers beschriebene Datensatzes, der den Unterschied zwischen einstufigen RL-Methoden und mehrstufigen Methoden demonstrieren sollte. |
expert_wordle_branch_100k.pkl | 100K -Spiele mit generate_data_branch.py aus OptimalPolicy mit den aus WrongPolicy abgetasteten Zweigen. |
expert_wordle_branch_150k.pkl | Weitere 150K -Spiele, die mit generate_data_branch.py aus OptimalPolicy mit den aus WrongPolicy abgetasteten Zweigen abgetastet wurden. |
expert_wordle_branch_2k_10sub.pkl | 2K -Spiele mit generate_data_branch.py aus OptimalPolicy mit 10 Zweigen pro Aktion, die von WrongPolicy abgetastet wurden, so dass es viel suboptimalere Daten gibt als in expert_wordle_branch_100k.pkl . |
expert_wordle_branch_20k_10sub.pkl | Das gleiche wie expert_wordle_branch_2k_10sub.pkl außer 20K -Spielen anstelle von 2K -Spielen. |
WordleIterableDataset :Generieren Sie Wurmdaten -Stichproben aus einer Richtlinie wie SO:
from wordle . wordle_dataset import WordleIterableDataset
from wordle . policy import OptimalPolicy
from data . rl_data import ConstantTokenReward
policy = OptimalPolicy ()
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
data = WordleIterableDataset (
policy = policy ,
vocab = vocab ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
while True :
item = data . sample_item ()__init__ def __init__ ( self , policy : Policy , vocab : Vocabulary , max_len : Optional [ int ], token_reward : TokenReward ) -> NoneEingänge:
policy: Policy - eine Richtlinie zum Beispiel.vocab: Vocabulary - Das Vokabular der Umgebung.max_len: Optional[int] - Die maximale Sequenzlänge im Datensatz schneidet alle Token -Sequenzen auf diese Länge ab. Wenn None , dann werden Sequenzen nicht abgeschnitten.token_reward: TokenReward -Die Belohnung auf Token-Ebene, die für die Sequenzen gelten. Wir verwenden für alle Experimente eine ständige Belohnung von 0 pro Erfreue. Rückkehr: None
sample_item def sample_item ( self ) -> DataPoint Rückgabe: Ein DataPoint -Objekt.
Wir haben einen großen Datensatz von über 200.000 Tweets von Wurmspielen wie folgt:
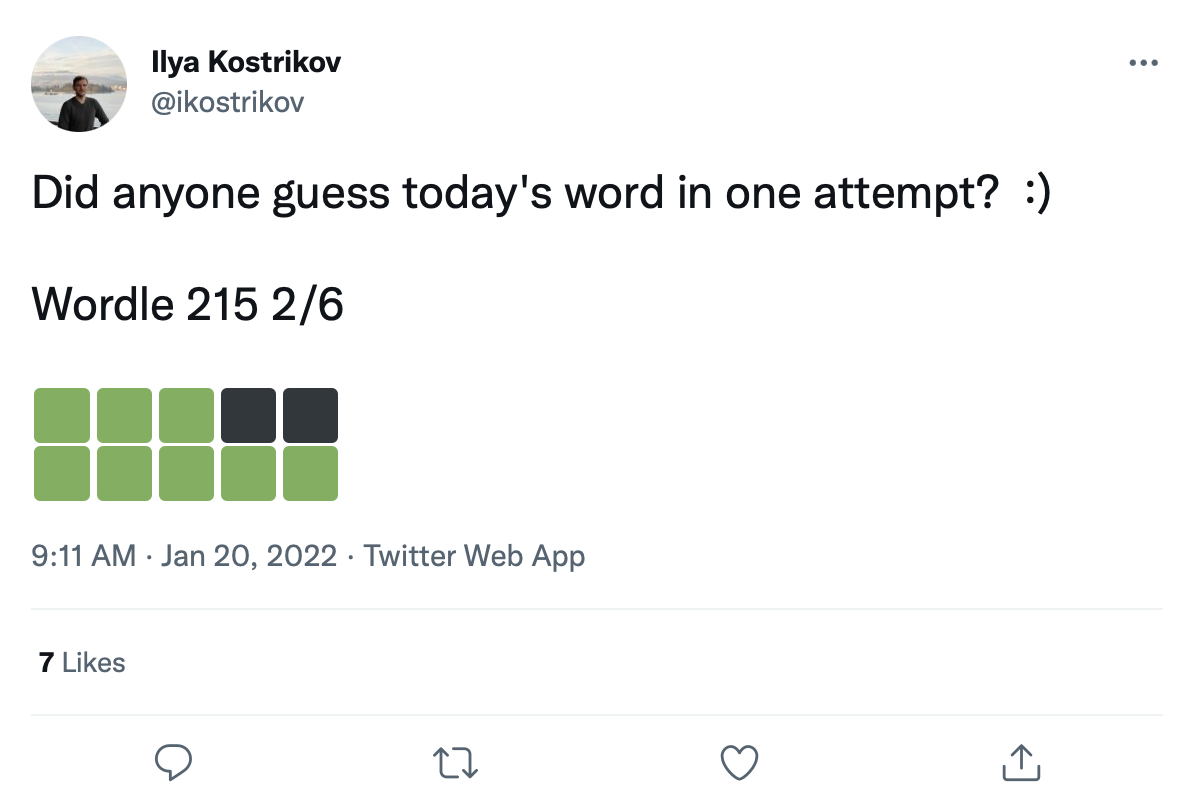
Wir können Wörter auf diese Farbübergangsquadrate nachrüsten, um einen echten Datensatz mit Wurmspielen zu erstellen.
Die RAW -Tweet -Daten finden Sie in data/wordle/tweets.csv . Um nutzbar zu sein, müssen tatsächliche Wörter in den Tweets auf die Farbquadrate nachgerüstet werden. Um diesen Nachrüstprozess durchzuführen, muss ein Vorverarbeitungsskript ausgeführt werden, das alle möglichen Farbübergänge zwischengeschnitten hat, die unter den Vocab -Listen auftreten können: guess_vocab (eine Reihe von erratenen Wörtern) und correct_vocab (eine Reihe möglicher korrekter Wörter in einer Umgebung). Das Ergebnis ist eine Datenstruktur, die wordle.wordle_dataset.WordleHumanDataset verwendet, um gültige Wurmspiele aus den Tweets zu synthetisieren. Dieses Skript besteht aus scripts/data/wordle/build_human_datastructure.py . Rufen Sie das Skript an wie:
cd scripts/data/wordle/
python build_human_datastructure.py --guess_vocab=../../../data/wordle/word_lists/wordle_official.txt --correct_vocab=../../../data/wordle/word_lists/wordle_official.txt --tweets_file=../../../data/wordle/tweets.csv --output_file=../../../data/wordle/random_human_tweet_data.jsonDie Argumente des Skripts:
--guess_vocab Gibt die Menge an erratener Wörter an.--correct_vocab Gibt den Satz möglicher korrekter Wörter in einer Umgebung an.--tweets_file gibt die RAW-CSV-Datei von Tweets an--output_file gibt an, wo die Ausgabe abgelegt werden soll. Wir haben die Vorverarbeitung auf einigen der Wortlisten ausgeführt, wobei die Ergebnisse in data/wordle/ gespeichert sind.
| Wortliste | Vorverarbeitete Tweet -Datendatei |
|---|---|
wordle_official.txt | random_human_tweet_data.json |
wordle_official_800.txt | random_human_tweet_data_800.json |
wordle_official_400.txt | random_human_tweet_data_400.json |
wordle_official_200.txt | random_human_tweet_data_200.json |
tweet_words.txt | human_tweet_data_true_word.json |
Angesichts einer dieser Dateien können Sie den Wurm -Tweet -Datensatz wie SO laden:
from wordle . wordle_dataset import WordleHumanDataset
data = WordleHumanDataset . from_file ( 'data/wordle/random_human_tweet_data_200.json' )
print ( data . sample_item ()) Wir haben in unseren Experimenten 'data/wordle/random_human_tweet_data_200.json' verwendet.
WordleHumanDataset : __init__ def __init__ ( self , games : List [ Tuple [ str , List [ str ]]], transitions : Dict [ str , Dict [ str , List [ str ]]], use_true_word : bool , max_len : Optional [ int ], token_reward : TokenReward , game_indexes : Optional [ List [ int ]], top_p : Optional [ float ]) -> NoneEingänge:
games: List[Tuple[str, List[str]]] – a list of tuples of the form (correct_wordle_word, wordle_transitions_list) , where wordle_transitions_list is a list of transitions indicating the colors in the Tweet like: ["<b><b><y><y><b>", "<g><b><b><b><b>", "<g><g><y><b><b>", "<g><g><g><g><g>"] .transitions: Dict[str, Dict[str, List[str]]] - Ein Diktat, das das richtige Wurmwort zu einem anderen Diktat -Zuordnung für mögliche Farbübergänge zubereitet, die durch dieses Wort auf eine Liste von Wörtern induziert werden könnten, die gespielt werden könnten, um diesen Übergang zu verursachen. Diese Datenstruktur wird verwendet, um Wörter auf die Tweets nachzurotten.use_true_word: bool -Verwenden Sie bei True das korrekte Wort der Grundwahrheit aus dem Tweet, sonst nach, sonst ein korrektes Wort in der Wortliste, die funktioniert.max_len: Optional[int] - Die maximale Sequenzlänge im Datensatz schneidet alle Token -Sequenzen auf diese Länge ab. Wenn None , dann werden Sequenzen nicht abgeschnitten.token_reward: TokenReward -Die Belohnung auf Token-Ebene, die für die Sequenzen gelten. Wir verwenden für alle Experimente eine ständige Belohnung von 0 pro Erfreue.game_indexes: Optional[List[int]] - Eine Liste von Indizes zum Erstellen einer Aufteilung der Tweets. Wenn None , werden alle Elemente in den Daten verwendet. Wir haben data/wordle/human_eval_idxs.json und data/wordle/human_train_idxs.json als zufällig ausgewählte Zug- und Eval -Splits.top_p: Optional[float] - Filtern Sie für die top_p -Leistung von Prozent der Daten. Wenn None , werden keine Daten gefiltert. Verwendet mit %BC -Modellen. Rückkehr: None
from_file def from_file ( cls , file_path : str , use_true_word : bool = False , max_len : Optional [ int ] = None , token_reward : Optional [ TokenReward ] = None , top_p : Optional [ float ] = None ) -> WordleHumanDatasetEingänge:
file_path: str - Der Pfad zur JSON -Datei, um die Daten aus zu laden.use_true_word: bool -Verwenden Sie bei True das korrekte Wort der Grundwahrheit aus dem Tweet, sonst nach, sonst ein korrektes Wort in der Wortliste, die funktioniert.max_len: Optional[int] - Die maximale Sequenzlänge im Datensatz schneidet alle Token -Sequenzen auf diese Länge ab. Wenn None , dann werden Sequenzen nicht abgeschnitten.token_reward: TokenReward -Die Belohnung auf Token-Ebene, die für die Sequenzen gelten. Wir verwenden für alle Experimente eine ständige Belohnung von 0 pro Erfreue.game_indexes: Optional[List[int]] - Eine Liste von Indizes zum Erstellen einer Aufteilung der Tweets. Wenn None , werden alle Elemente in den Daten verwendet. Wir haben data/wordle/human_eval_idxs.json und data/wordle/human_train_idxs.json als zufällig ausgewählte Zug- und Eval -Splits.top_p: Optional[float] - Filtern Sie für die top_p -Leistung von Prozent der Daten. Wenn None , werden keine Daten gefiltert. Verwendet mit %BC -Modellen. Rückgabe: Ein WordleHumanDataset -Objekt.
sample_item def sample_item ( self ) -> DataPoint Rückgabe: Ein DataPoint -Objekt.
Trainingsskripte sind in scripts/train/wordle/ .
| Skript | Beschreibung |
|---|---|
train_bc.py | Trainieren Sie einen BC -Agenten. |
train_iql.py | Trainieren Sie einen ILQL -Agenten. |
Evaluierungsskripte befinden sich in scripts/eval/wordle/ .
| Skript | Beschreibung |
|---|---|
eval_policy.py | Bewerten Sie einen BC- oder ILQL -Agenten in der Wurmumgebung. |
eval_q_rank.py | Ein Evaluierungsskript zum Vergleich des relativen Ranges der Q-Werte für Agenten, die auf dem in Abschnitt 5 unseres Papier beschriebenen synthetischen Datensatz geschult wurden, das einen Unterschied zwischen einstufiger RL und mehrstufiger RL demonstriert. |
distill_policy_eval.py | Druckt das Ergebnis von eval_policy.py mit Fehlerbalken aus. |
Hier skizzieren wir, wie die visuellen Dialogdaten in unserer Codebasis geladen werden und wie die Umgebung ausgeführt wird. In dem Abschnitt "Setup" oben finden Sie die Remote -Komponenten der visuellen Dialogumgebung. Die Daten- und Umgebungsobjekte werden vom Konfigurationsmanager automatisch geladen. Wenn Sie jedoch das Konfigurationssystem umgeben und die Umgebung mit Ihrer eigenen Codebasis verwenden möchten, sollten Sie diese Objekte laden, ausführen und konfigurieren. Dieselben unten beschriebenen Einstellungen können auch in den Konfigurationen geändert werden.
Ein Beispiel dafür, wie man die visuelle Dialogumgebung lädt:
from visdial . visdial_env import VDEnvironment
from visdial . visdial_base import VisDialogueData
from visdial . visdial_dataset import VisDialListDataset
from data . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = VisDialogueData (
data_path = convert_path ( 'data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.json' ),
img_feat_path = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/data_img.h5' ),
split = 'train' ,
reward_cache = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/train_rank_reward_cache1.json' ),
yn_reward_kind = 'none'
)
list_data = VisDialListDataset (
data = data ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 )
)
env = VDEnvironment (
dataset = list_data ,
url = 'http://localhost:5000/step_rank' ,
yn_reward = - 2.0 ,
yn_reward_kind = 'none'
)
print ( env . reset ()) Das obige Skript entspricht der Konfiguration des Datensatzes und der Umgebung für unsere "Standard" -Warnungsversuche. Wenn Sie jedoch den Datensatz unterschiedlich konfigurieren möchten, können Sie viele Argumente ändern. Diese Argumente können nicht nur den Datensatz -Split ändern, sondern können auch die Aufgabe oder Belohnung ändern. Im Folgenden beschreiben wir alle verschiedenen konfigurierbaren Parameter, die VisDialogueData , VisDialListDataset und VDEnvironment aufnehmen.
Wir dokumentieren die Parameter und Methoden für VisDialogueData , VisDialListDataset und VDEnvironment , damit Sie wissen, wie Sie die Umgebung selbst konfigurieren.
VisDialogueData : VisDialogueData , implementiert in src/visdial/visdial_base.py , speichert die Dialoge und Belohnungen der Aufgabe.
__init__ def __init__ ( self , data_path : str , img_feat_path : str , split : str , reward_cache : Optional [ str ] = None , norm_img_feats : bool = True , reward_shift : float = 0.0 , reward_scale : float = 1.0 , addition_scenes : Optional [ List [ Scene ]] = None , mode : str = 'env_stops' , cutoff_rule : Optional [ CutoffRule ] = None , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneEingänge:
data_path: str - Der Pfad zu den Dialogdaten. Sollte einer von: sein:data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_val.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_test.jsonimg_feat_path: str - Der Pfad zu den Bildfunktionen, mit denen die Belohnung für jeden Dialog berechnet wird. Sollte immer data/vis_dialogue/processed/visdial_0.5/data_img.h5 sein.split: str - einer von train , val oder test . Gibt an, welche Datensatzaufteilung der Bildfunktionen verwendet werden soll. Sollte mit dem data_path -Split übereinstimmen.reward_cache: Optional[str]=None - wobei die Belohnungen für jeden Dialog gespeichert werden. Wenn None , wird alle Belohnungen auf None gesetzt. Wir bieten Caches für zwei Belohnungsfunktionen:data/vis_dialogue/processed/visdial_0.5/[split]_rank_reward_cache1.json , wobei [split] durch einen train , val oder test ersetzt wird.val Belohnung, die von den visuellen data/vis_dialogue/processed/visdial_0.5/[split]_reward_cache2.json test Papiers Learning Cooperative mit [split] train verwendet wird.norm_img_feats: bool=True - Ob die Bildfunktionen normalisieren sollen.reward_shift: float=0.0 - Verschieben Sie die Belohnung um diesen Betrag.reward_scale: float=1.0 - Skalieren Sie die Belohnung um diesen Betrag.addition_scenes: Optional[List[Scene]]=None - In den Datensatz zusätzliche Daten einfügen.mode: str='env_stops' - einer von ['agent_stops', 'env_stops', '10_stop'] . Kontrolliert einige Eigenschaften der Aufgabe. Wir verwenden env_stopsmode='env_stops' , stoppen Sie die Umgebungsinteraktion nach cutoff_rule frühzeitig.mode='agent_stops' , stoppt der Agent die Interaktion, indem er während seiner Aktion ein spezielles <stop> -Token generiert. Erhöht die Daten, indem Sie nach jeder möglichen Aktion einen <stop> platzieren.mode='10_stop' , wird das Spiel nach 10 Wechselwirkungsrunden immer stoppt, wie es im visuellen Dialog -Datensatz Standard ist.cutoff_rule: Optional[CutoffRule]=None - gilt nur dann, wenn mode='env_stops' . Implementiert eine Funktion, die feststellt, wann die Umgebung die Interaktion frühzeitig stoppen sollte. Wir verwenden die Standardeinstellung von visdial.visdial_base.PercentileCutoffRule(1.0, 0.5) in allen unseren Experimenten.yn_reward: float=-2.0 -Die Belohnungsstrafe, die hinzugefügt werden sollte, um Ja/Nein-Fragen zu stellen.yn_reward_kind: str='none' - Gibt die String Match Heuristic an, um zu bestimmen, ob eine Ja/No -Frage gestellt wurde. Sollte einer von ['none', 'soft', 'hard', 'conservative'] sein.'none' : Bestrafe Ja/Nein -Fragen nicht. Dies entspricht der standard in unserem Artikel.'soft' : Beweisen Sie eine Frage, ob die Antwort "yes" oder "no" als Substring enthält.'hard' : Beweisen Sie eine Frage, ob die Antwort genau mit der Zeichenfolge "yes" oder "no" übereinstimmt. Dies entspricht der "y/n" -Belohnung in unserem Artikel.'conservative' : Bestreben Sie eine Frage, ob die Antwort eine von mehreren String -Matching -Heuristiken erfüllt. Dies entspricht der "conservative y/n" -Belohnung in unserer Arbeit. Rückkehr: None
__len__ def __len__ ( self ) -> intRückgabe: Die Größe des Datensatzes.
__getitem__ def __getitem__ ( self , i : int ) -> SceneEingänge:
i: int - Der Datensatzindex.Rückgabe: Ein Element aus dem Datensatz.
VisDialListDataset : VisDialListDataset , implementiert in src/visdial/visdial_dataset.py , wickelt sich um VisDialogueData und verwandelt es in ein DataPoint -Format, mit dem Offline -RL -Agenten trainiert werden können.
__init__ def __init__ ( self , data : VisDialogueData , max_len : Optional [ int ], token_reward : TokenReward , top_p : Optional [ float ] = None , bottom_p : Optional [ float ] = None ) -> NoneEingänge:
data: VisDialogueData - Ein visuelles Dialogdatenobjekt, das alle Rohdaten speichert.max_len: Optional[int] - Die maximale Sequenzlänge im Datensatz schneidet alle Token -Sequenzen auf diese Länge ab. Wenn None , dann werden Sequenzen nicht abgeschnitten.token_reward: TokenReward -Die Belohnung auf Token-Ebene, die für die Sequenzen gelten. Wir verwenden für alle Experimente eine ständige Belohnung von 0 pro Erfreue.top_p: Optional[float] - Filtern Sie für die top_p -Leistung von Prozent der Daten. Wenn None , werden keine Daten gefiltert. Verwendet mit %BC -Modellen.bottom_p: Optional[float] - Filter für den prozentualen Prozentsatz von bottom_p . Wenn None , werden keine Daten gefiltert. Rückkehr: None
size def size ( self ) -> intRückgabe: Die Größe des Datensatzes.
get_item def get_item ( self , idx : int ) -> DataPointEingänge:
i: int - Der Datensatzindex. Rückgabe: Ein DataPoint aus dem Datensatz.
VDEnvironment : Die in src/visdial/visdial_env.py implementierte VDEnvironment definiert die visuelle Dialogumgebung, mit der unsere Offline -RL -Agenten zur Bewertungszeit interagieren. Die Umgebung umfasst eine Verbindung zu einem lokalen Server, den der Setup -Abschnitt beschreibt, wie man sich dreht.
__init__ def __init__ ( self , dataset : RL_Dataset , url : str , reward_shift : float = 0.0 , reward_scale : float = 1.0 , actor_stop : bool = False , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneEingänge:
dataset: RL_Dataset - nimmt ein RL_Dataset ; speziell VisDialListDataset , wie oben. Dieser Datensatz wird verwendet, um Anfangszustände auszuwählen.url: str - Die URL für den Eintritt in die Umwelt. Befolgen Sie die Anweisungen im Setup -Abschnitt, wie Sie den Lokalhost -Webserver initialisieren, der dieser URL entspricht.reward_shift: float=0.0 - Verschieben Sie die Belohnung um diesen Betrag.reward_scale: float=1.0 - Skalieren Sie die Belohnung um diesen Betrag.actor_stop: bool=False - Erlauben Sie dem Schauspieler, die Interaktion frühzeitig zu stoppen, indem Sie ein spezielles <stop> -Token generieren.yn_reward: float=-2.0 -Die Belohnungsstrafe, die hinzugefügt werden sollte, um Ja/Nein-Fragen zu stellen.yn_reward_kind: str='none' - Gibt die String Match Heuristic an, um zu bestimmen, ob eine Ja/No -Frage gestellt wurde. Sollte einer von ['none', 'soft', 'hard', 'conservative'] sein.'none' : Bestrafe Ja/Nein -Fragen nicht. Dies entspricht der standard in unserem Artikel.'soft' : Beweisen Sie eine Frage, ob die Antwort "yes" oder "no" als Substring enthält.'hard' : Beweisen Sie eine Frage, ob die Antwort genau mit der Zeichenfolge "yes" oder "no" übereinstimmt. Dies entspricht der "y/n" -Belohnung in unserem Artikel.'conservative' : Bestreben Sie eine Frage, ob die Antwort eine von mehreren String -Matching -Heuristiken erfüllt. Dies entspricht der "conservative y/n" -Belohnung in unserer Arbeit. Rückkehr: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Eingänge:
action: Vocabulary - Der Wortschatz der UmgebungRückgabe: Ein (Beobachtung, Belohnung, Terminal) Tupel.
reset def reset ( self ) -> WordleObservationRückgabe: Eine Beobachtung
is_terminal def is_terminal ( self ) -> boolRückgabe: Ein Boolescher Angabe, der angezeigt wird, ob die Interaktion beendet ist.
Trainingsskripte sind in scripts/train/vis_dial/ .
| Skript | Beschreibung |
|---|---|
train_bc.py | Trainieren Sie einen BC -Agenten. |
train_chai.py | Trainieren Sie einen Chai -Agenten. |
train_cql.py | Trainieren Sie einen CQL -Agenten. |
train_dt.py | Trainieren Sie einen Entscheidungstransformatoragenten. |
train_iql.py | Trainieren Sie einen ILQL -Agenten. |
train_psi.py | Trainieren und |
train_utterance.py | Trainieren Sie einen Ilql-Agenten auf Äußerungsebene. |
Evaluierungsskripte befinden sich in scripts/eval/vis_dial/ .
| Skript | Beschreibung |
|---|---|
eval_policy.py | Bewerten Sie einen Agenten in der visuellen Dialogumgebung. |
top_advantage.py | Findet die Fragen, die unter dem Modell den größten und kleinsten Vorteil haben. |
distill_policy_eval.py | Druckt das Ergebnis von eval_policy.py mit Fehlerbalken aus. |
Here we outline how to load the Reddit comments data in our codebase and how to execute the environment. See the setup section above for how to setup the toxicity filter reward. The data and environment objects are loaded automatically by the config manager, but if you want to by-pass the config system and use the task with your own codebase, here's how you should load, execute, and configure these objects. The same settings described below can all be modified in the configs as well.
An example of how to load the Reddit comment environment:
from toxicity . toxicity_env import ToxicityEnvironment
from toxicity . reddit_comments_base import RedditData
from toxicity . reward_fs import toxicity_reward
from utils . misc import convert_path
idxs = json . load ( open ( convert_path ( 'data/reddit_comments/train_idxs.json' ), 'r' ))
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = idxs ,
reward_f = toxicity_reward
)
env = ToxicityEnvironment (
data = data ,
reward_f = toxicity_reward
)
print ( env . reset ())
The above script corresponds to how we configured the environment for our toxicity reward experiments, but if you want to configure the environment differently, there are a few arguments you can modify. These arguments can also change the task or reward. Below we describe all the different configurable parameters that our reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment take.
We document the parameters and methods for our different Reddit comment reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment , so that you know how to configure the environment yourself.
Here we outline the 4 main reward functions we use for our Reddit comment task. Each of these rewards is implemented in src/toxicity/reward_fs.py .
toxicity_reward from toxicity . reward_fs import toxicity_reward
reward_f = toxicity_reward ()Beschreibung:
The "toxicity" reward from our paper, which queries the GPT-3 toxicity filter. It assigns a value of "0" to non-toxic comments, a value of "1" to moderately toxic comments, and a value of "2" to very toxic comments.
toxicity_noised_reward from toxicity . reward_fs import toxicity_noised_reward
reward_f = toxicity_noised_reward ()Beschreibung:
The "noised toxicity" reward from our paper, which is the same as toxicity_noised_reward but induces additional noise. Specifically, it re-assigns comments labeled as "1" (moderately toxic) to either "0" (non-toxic) or "2" (extremely toxic) with equal probability.
score_human_reward from toxicity . reward_fs import score_human_reward
from utils . misc import convert_path
reward_f = score_human_reward (
reddit_path = convert_path ( 'data/reddit_comments/' ),
indexes = None
)Beschreibung:
The "upvotes real" reward from our paper, which gives a reward of +1 for positive upvote comments and -1 for negative upvote comments. This uses the ground truth upvotes in the data, so it only applies to comments in the dataset and cannot be used for evaluation. If you input a string not present in the data, it will error. The arguments to this function specify what data to load.
Inputs:
reddit_path: str – a path to the data.indexes: List[int] – a split of indexes in the data to use. If None , it considers all the data. model_reward from toxicity . reward_fs import score_human_reward
from toxicity . reddit_comments_base import RedditData
from toxicity . toxicity_dataset import ToxicityListDataset
from toxicity . reward_model import RobertaBinaryRewardModel
from utils . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = None ,
reward_f = None
)
listdata = ToxicityListDataset (
data = data ,
max_len = 512 ,
token_reward = ConstantTokenReward ( 0.0 )
)
model = RobertaBinaryRewardModel (
data = listdata ,
device = 'cuda' ,
roberta_kind = 'roberta-base' ,
freeze_roberta = False ,
reward_cuttoff = 0.0
)
model . load_state_dict ( torch . load ( convert_path ( 'outputs/toxicity/upvote_reward/model.pkl' ), map_location = 'cpu' ))
reward_f = score_human_reward ( model = model )Beschreibung:
The "upvotes model" reward from our paper, which gives a reward of +1 if the given model predicts that the comment will get a positive number of upvotes and a reward of -1 otherwise. The model checkpoint we used for our experiments is at: outputs/toxicity/upvote_reward/model.pkl
Inputs:
model: RewardModel : the reward model implemented in src/toxicity/reward_model.py . The model should be first trained and loaded from a pytorch checkpoint.RedditData : RedditData , implemented in src/toxicity/reddit_comments_base.py , stores the raw Reddit comments data.
__init__ def __init__ ( self , path : str , indexes : Optional [ List [ int ]], reward_f : Optional [ Callable [[ str ], float ]], reward_cache : Optional [ Cache ] = None , reward_shift : float = 0.0 , reward_scale : float = 1.0 ) -> NoneInputs:
path: str – the path to the Reddit data.indexes: Optional[List[int]] – a list of indexes to create a split of the data. Randomly selected, training, validation, and test splits are in the json files:data/reddit_comments/train_idxs.jsondata/reddit_comments/eval_idxs.jsondata/reddit_comments/test_idxs.jsonreward_f: Optional[Callable[[str], float]] – the reward function to use.reward_cache: Optional[Cache]=None – a cache of reward values, so you don't have to recompute them everytime.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount. Returns: None
__len__ def __len__ ( self ) -> intReturns: the size of the dataset.
__getitem__ def __getitem__ ( self , idx : int ) -> SceneInputs:
idx: int – the dataset index.Returns: an item from the dataset.
ToxicityListDataset : ToxicityListDataset , implemented in src/toxicity/toxicity_dataset.py , wraps around RedditData and converts it into a DataPoint format that can be used to train offline RL agents.
__init__ def __init__ ( self , data : RedditData , max_len : Optional [ int ], token_reward : TokenReward , cuttoff : Optional [ float ] = None , resample_timeout : float = 0.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – a Reddit comment data object that stores all the raw data.max_len: Optional[int] – the maximum sequence length in the dataset, will truncate all token sequences to this length. If None , then sequences will not be truncated.token_reward: TokenReward – the token-level reward to apply to the sequences. We use a constant reward of 0 per-token for all experiments.cuttoff: Optional[float]=None – filter out all comments from the dataset with reward less than cuttoff . If None , no data will be filtered. Used with %BC models.resample_timeout: float=0.0 – when cuttoff is not equal to None , comments are stochastically sampled iid from the dataset, like an iterable, even though the dataset has a list-type interface. It uniformly re-samples from the dataset until it finds a comment with a reward that satisfies the cuttoff. In the case of the "toxicity" reward, this re-sampling can cause rate-limit errors on the GPT-3 API, so we allow you to add a resample_timeout to fix this issue: a timeout of roughly 0.05 should fix rate-limit issues.include_parent: bool=True – whether to condition on the parent comment in the thread. If False , models will be trained to generate comments unconditionally. Returns: None
size def size ( self ) -> intReturns: the size of the dataset.
get_item def get_item ( self , idx : int ) -> DataPointInputs:
i: int – the dataset index. Returns: a DataPoint from the dataset.
ToxicityEnvironment : ToxicityEnvironment , implemented in src/toxicity/toxicity_env.py , defines the Reddit comment generation environment, which our offline RL agents interact with at evaluation time.
__init__ def __init__ ( self , data : RedditData , reward_f : Optional [ Callable [[ str ], float ]], reward_shift : float = 0.0 , reward_scale : float = 1.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – the dataset used to select initial state parent comments to condition on.reward_f: Optional[Callable[[str], float]] – the reward function to use.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount.include_parent: bool=True – specifies whether to condition on the previous comment or post in the Reddit thread. Returns: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Inputs:
action: Vocabulary – the environment's vocabularyReturns: an (observation, reward, terminal) tuple.
reset def reset ( self ) -> WordleObservationReturns: an observation
is_terminal def is_terminal ( self ) -> boolReturns: a boolean indicating if the interaction has terminated.
Training scripts are in scripts/train/toxicity/ .
| Skript | Beschreibung |
|---|---|
train_bc.py | Train a BC agent. |
train_iql.py | Train an ILQL agent. |
train_upvote_reward.py | Train the upvote reward model. |
Evaluation scripts are in scripts/eval/toxicity/ .
| Skript | Beschreibung |
|---|---|
eval_policy.py | Evaluate an agent in the Reddit comments environment. |
distill_policy_eval.py | Prints out the result of eval_policy.py with error bars. |
All tasks – Wordle, Visual Dialogue, Reddit – have a corresponding environment and dataset implemented in the codebase, as described above. And all offline RL algorithms in the codebase are trained, executed, and evaluated on one of these given environments and datasets.
You can similarly define your own tasks that can easily be run on all these offline RL algorithms. This codebase implements a simple set of RL environment abstractions that make it possible to define your own environments and datasets that can plug-and-play with any of the offline RL algorithms.
All of the core abstractions are defined in src/data/ . Here we outline what needs to be implemented in order to create your own tasks. For examples, see the implementations in src/wordle/ , src/vis_dial/ , and src/toxicity/ .
All tasks must implement subclasses of: Language_Observation and Language_Environment , which are in src/data/language_environment.py .
Language_Observation :This class represents the observations from the environment that will be input to your language model.
A Language_Observation must define the following two functions.
to_sequence def to_sequence ( self ) -> Tuple [ List [ str , Optional [ float ]], bool ]:Beschreibung:
A function which converts the observation object into a standard format that can be input to the language model and used for training.
Rückgaben:
__str__ def __str__ ( self ) -> str :Beschreibung:
This is only used to print the observation to the terminal. It should convert the observation into some kind of string that is interpretable by a user.
Returns: a string.
Language_Environment :This class represents a gym-style environment for online interaction, which is only used for evaluation.
A Language_Environment must define the following three functions.
step def step ( self , action : str ) -> Tuple [ Language_Observation , float , bool ]:Beschreibung:
Just like a standard gym environment, given an action in the form of a string, step the environment forward.
Returns: a tuple of (Language_Observation, reward, terminal).
reset def reset ( self ) -> Language_Observation :Beschreibung:
This resets the environment to an initial state.
Returns: the corresponding initial Language_Observation
is_terminal def is_terminal ( self ) -> bool :Beschreibung:
Outputs whether the environment has reached a terminal state.
Returns: a boolean indicating if the environment has reached a terminal state.
All tasks must implement subclasses of either List_RL_Dataset or Iterable_RL_Dataset or both, which are defined in src/data/rl_data.py .
List_RL_Dataset :This class represents a list dataset (or an indexable dataset of finite length) that can be used to train offline RL agents.
A List_RL_Dataset must define the following two functions.
get_item def get_item ( self , idx : int ) -> DataPointBeschreibung:
This gets an item from the dataset at a given index.
Returns: a DataPoint object from the dataset.
size def size ( self ) -> intBeschreibung:
Returns the size of the dataset.
Returns: the dataset's size.
Iterable_RL_Dataset :This class represents an iterable dataset (or a non-indexable dataset that stochastically samples datapoints iid) that can be used to train offline RL agents.
A Iterable_RL_Dataset must define the following function.
sample_item def sample_item ( self ) -> DataPointBeschreibung:
Samples a datapoint from the dataset.
Returns: a DataPoint object from the dataset.


