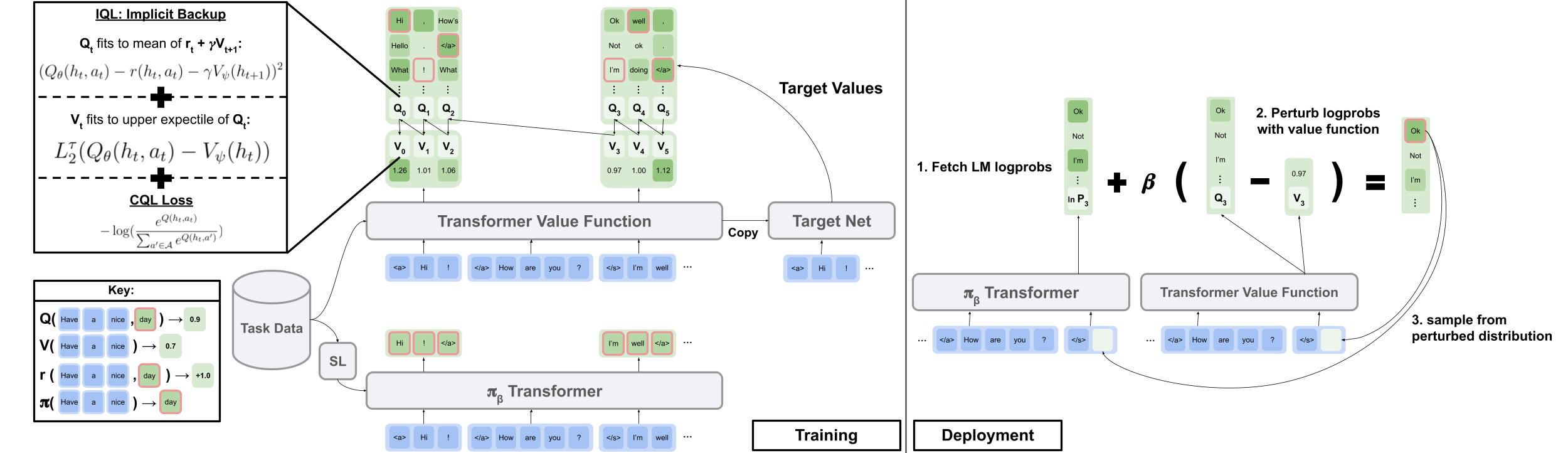
Implicit Language Q Learning
1.0.0
論文からの公式コード「暗黙の言語Q学習を伴う自然言語生成のためのオフラインRL」
プロジェクトサイト| arxiv
Googleドライブフォルダーからdata.zipとoutputs.zipここからダウンロードしてください。ダウンロードされたフォルダーと解凍されたフォルダー、 data/およびoutputs/をリポジトリのルートに配置します。 data/すべてのタスクの前処理されたデータが含まれており、Redditコメントのチェックポイントをoutputs/含めます。
このレポは、Python 3.9.7用に設計されています
pip install -r requirements.txt
export PYTHONPATH= " $PWD /src/ "視覚的な対話実験を実行するには、ここでの指示に従って、LocalHostで視覚的な対話環境を提供する必要があります。
毒性フィルター報酬を使用したRedditコメント実験を実行するには:
export OPENAI_API_KEY=your_API_keyscripts/すべての実験スクリプトを含みます。 scripts/ :
python script_name.pyオプション:
python script_name.py eval.bsize=5 train.lr=1e-6 wandb.use_wandb=falsepython -m torch.distributed.launch --nproc_per_node [N_GPUs] --use_env script_name.py arg1=a arg2=b実行します。デフォルトでは、すべてのトレーニングスクリプトがWandBにログに記録します。これをオフにするには、トレーニング構成でwandb.use_wandb=false設定します。
ここでは、オフラインRLエージェントをトレーニングするための推奨ワークフローの概要を説明します。さまざまなオフラインRLエージェントの束を訓練して、毒性報酬でRedditコメントを生成したいとします。
私は最初にデータに関するBCモデルをトレーニングします。
cd scripts/train/toxicity/
python train_bc.py次に、このBCチェックポイントをオフラインRLモデルと互換性のある1つに変換します。
cd ../data/
python convert_bc.py --load ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model.pkl --save ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model_converted.pkl次に、オフラインRLがトレーニングするように構成されているチェックポイントを編集します。
cd ../train/
python train_iql.py model.load.checkpoint_path=outputs/toxicity/model_converted.pkl model.load.strict_load=false train.loss.awac_weight=0.0ただし、これはワークフローの1つにすぎません。トレーニング構成でtrain.loss.awac_weight=1.0設定することにより、BCモデルをオフラインRLエージェントと同時にトレーニングすることもできます。
data/フォルダーで前処理されます。scripts/ペーパー内のトレーニング、評価、およびデータの前処理手順を実行するためのすべてのスクリプトを含みます。スクリプトは、使用されるデータセットに対応するサブフォルダーに編成されます。config/ contains .yaml configs。このレポは、Hydraを使用して構成を管理します。構成は、使用されるデータセットに対応するサブフォルダーに編成されます。ほとんどの構成ファイルは対応するスクリプトと同じ名前ですが、スクリプトに対応する構成が不明な場合は、line @hydra.main(config_path="some_path", config_name="some_name")をチェックして、スクリプトが対応する構成を確認します。src/には、すべてのコア実装が含まれています。すべてのモデル実装についてはsrc/models/を参照してください。すべてのベースデータ処理とMDP抽象化コードについてはsrc/data/を参照してください。さまざまなユーティリティ関数については、 src/utils/を参照してください。 src/wordle/ 、 src/visdial 、およびsrc/toxicity/すべてのWordle、視覚対話、Redditコメントデータセット固有コードについては、それぞれを参照してください。ILQLは、リポジトリ全体でiqlと呼ばれます。 各スクリプトは構成ファイルに関連付けられています。構成ファイルは、どのモデル、データセット、および評価者がスクリプトとそれらに対応するハイパーパラメーターによってロードされるかを指定します。例についてはconfigs/toxicity/train_iql.yaml参照してください。
各可能なモデル、データセット、または評価者オブジェクトには、そのオブジェクトのデフォルト値とConfig Managerにロードするクラスを指定する特別なname属性を指定する独自の構成ファイルが与えられます。例についてはconfigs/toxicity/model/per_token_iql.yamlを参照してください。
ファイルsrc/load_objects.py 、 src/wordle/load_objects.py 、 src/visdial/load_objects.py 、およびsrc/toxicity/load_objects.py各オブジェクトが対応する構成からロードされる方法を定義します。各ロードオブジェクト関数の上の@register('name')タグは、configのname属性にリンクします。
構成内の一部のオブジェクトに関連付けられている特別なcache_id属性に気付く場合があります。たとえば、 configs/toxicity/train_iql.yamlのtrain_dataset参照してください。この属性は、Config Managerに、このIDに関連付けられている最初のオブジェクトをキャッシュするように指示し、このcache_idを使用して後続のオブジェクト構成のためにこのキャッシュされたオブジェクトを返すようにします。
すべての構成について、レポートルートに対するパスを使用します。
リポジトリの各タスク(Wordle、Visual Dialogue、Redditコメント)は、いくつかの基本クラスを実装しています。実装すると、すべてのオフラインRLアルゴリズムをプラグアンドプレイでタスクに適用できます。独自のタスクを作成するために実装すべきものの概要については、「独自のタスクの作成」セクションを参照してください。以下に、これを可能にする重要な抽象化の概要を説明します。
data.language_environment.Language_Environment - ポリシーが相互作用できるタスクPOMDP環境を表します。ジムのようなインターフェイスがあります。data.language_environment.Policy - 環境と対話できるポリシーを表します。 src/models/のオフラインRLアルゴリズムのそれぞれには、対応するポリシーがあります。data.language_environment.Language_Observation - 環境によって返され、ポリシーへの入力として与えられるテキスト観察を表します。data.language_environment.interact_environment - 環境、ポリシー、およびオプションで現在の観測と環境相互作用ループを実行する関数。現在の観測が提供されていない場合、環境をリセットすることにより、初期状態を自動的に取得します。data.rl_data.DataPoint - すべてのタスクですべてのオフラインRLエージェントに入力として供給される標準化されたデータ形式を定義します。これらのデータ構造は、特定のLanguage_Observationから自動的に作成されます。data.rl_data.TokenReward - すべての単一のトークンで与えられた報酬関数を定義します。これは、より細かい粒子制御を学習するために使用できます。これは、環境の報酬に加えて提供されます。これは、すべてのトークンではなく、相互作用のたびに行われます。すべての実験で、この報酬を定数0に設定したため、効果がありません。data.tokenizer.Tokenizer - 言語モデルへの入力として供給できるトークンのシーケンスに弦を変換する方法を指定します。data.rl_data.RL_Dataset - DataPointオブジェクトを返すデータセットオブジェクトを定義し、オフラインRLエージェントのトレーニングに使用します。 RL_Datasetには2つのバージョンがあります。List_RL_DatasetIterable_RL_Dataset
ここでは、Wordleタスクのすべてのコンポーネントの概要と文書化を行います。
サンプルスクリプトにあるものの多くは、config Managerによって自動的に行われ、対応するパラメーターは構成を変更することで編集できます。ただし、構成を使用してバイパスし、独自のコードベースでWordleタスクを使用する場合は、これを行う方法については、以下のスクリプトとドキュメントを参照できます。
コマンドラインでWordleを再生するための簡単な例。
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from wordle . policy import UserPolicy
from data . language_environment import interact_environment
from utils . misc import convert_path
game_vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( game_vocab )
policy = UserPolicy ()
interact_environment ( env , policy )src/wordle/wordle_game.pysrc/wordle/wordle_env.pysrc/wordle/policy.pysrc/wordle/wordle_dataset.pyゲームを有効なMDPにするために、環境は既知の文字の制約のセットとして基礎となる状態を表し、これらを使用して、各ターンでこれらすべての制約を満たす単語の語彙をフィルタリングします。次に、このフィルタリングされた単語リストからランダムな単語が選択され、環境によって返される色の遷移を決定するために使用されます。これらの新しい色の遷移は、既知の文字制約のセットを更新します。
Wordle環境には単語リストが含まれています。 data/wordle/word_lists/にはいくつかの単語リストが記載されていますが、独自のものを自由に作成してください。
含まれる単語リストは次のとおりです。
上記の例のように、単語リストはVocabularyオブジェクトを介して環境にロードされます。
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))語彙は、単語リストだけでなく、特定の状態のすべての既知の文字の制約を満たす単語のフィルタリングされたリストを追跡します。このリストは、環境内の遷移を計算するために使用され、手作りのポリシーの一部で使用されます。
これらのフィルタリングされたリストをリアルタイムで作成すると、環境相互作用プロセスが遅くなります。これは通常問題ではないはずですが、ポリシーから多くのデータを迅速に合成したい場合は、これがボトルネックになる可能性があります。これを克服するために、すべてのVocabularyオブジェクトはcache引数を保存します。これは、特定の状態に関連付けられたこれらのフィルタリングされた単語リストをキャッシュします。 vocab.cache.load(f_path)およびvocab.cache.dump()有効にして、このキャッシュの読み込みと保存を可能にします。たとえば、 data/wordle/vocab_cache_wordle_official.pkl wordle_official.txtワードリストの大きなキャッシュです。
キャッシュを保存するだけでなく、 Vocabularyオブジェクトはsrc/wordle/wordle_game.pyで次の方法を実装します:
__init__ def __init__ ( self , all_vocab : List [ str ],
wordle_state : Optional [ WordleState ],
cache : Optional [ Cache ] = None ,
fill_cache : bool = True ) -> None入力:
all_vocab: List[str] - 単語のリスト。wordle_state: Optional[WordleState] - フィルタリングされた単語リストを生成する状態。状態が提供されていない場合、単語はフィルタリングされません。cache: Optional[Cache]=None - 上記のように、フィルター処理されたボカブのキャッシュ。fill_cache: bool=True - キャッシュに追加するかどうか。返品: None
from_file def from_file ( cls , vocab_file : str , fill_cache : bool = True ) -> Vocabulary入力:
vocab_file: str - 単語をロードするファイル。このメソッドは、5文字の長さの単語のみを選択します。fill_cache: bool=True - キャッシュに追加するかどうか。返品: Vocabulary
filtered_vocab_size def filtered_vocab_size ( self ) -> int返品:フィルタリングされた語彙のサイズ
all_vocab_size def all_vocab_size ( self ) -> int返品:完全にフィルター処理された語彙のサイズ
get_random_word_filtered def get_random_word_filtered ( self ) -> str返品:フィルタリングされたリストからのランダムワード。
get_random_word_all def get_random_word_all ( self ) -> str返品:フルフィルターリストからのランダムワード。
update_vocab def update_vocab ( self , wordle_state : WordleState ) -> Vocabulary入力:
wordle_state: WordleState - 既知の文字制約のセットを表すWordle Stateオブジェクト。返品: wordle_stateに従ってフィルタリングされる新しいVocabularyオブジェクト。
__str__ def __str__ ( self ) -> str返品:ターミナルに印刷するためのフィルタリングされた単語リストの文字列表現。
WordleEnvironment 、語彙オブジェクトを入力として採用します。これは、環境内の可能な正しい単語のセットを定義します。
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( vocab )
initial_obs = env . reset ()
next_obs , reward , terminal = env . step ( "snake" )上記のように、環境はsrc/wordle/wordle_env.pyのジムのようなインターフェイスを実装しています:
__init__ def __init__ ( self , vocab : Vocabulary ) -> None入力:
vocab: Vocabulary - 環境の語彙。返品: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]入力:
action: Vocabulary - 環境でのエージェントのアクションを表す一連のテキスト。返品:(観察、報酬、ターミナル)タプル。
reset def reset ( self ) -> WordleObservation返品:観察。
is_terminal def is_terminal ( self ) -> bool返品:相互作用が終了したかどうかを示すブール値。
さまざまなゲームプレイレベルをカバーする手作りのワードルポリシーのセットを実装します。これらはすべて、 src/wordle/policy.pyに実装されています。ここでそれぞれについて説明します。
UserPolicy from wordle . policy import UserPolicy
policy = UserPolicy ( hint_policy = None , vocab = None )説明:
ターミナルで演奏しましょう。
入力:
hint_policy: Optional[Policy] - 使用する単語のヒントが必要な場合は、照会する別のポリシー。vocab: Optional[Union[str, Vocabulary]] - 推測可能な単語のVocabulary 。指定されていない場合、charの5文字のシーケンスは有効な推測です。 StartWordPolicy from wordle . policy import StartWordPolicy
policy = StartWordPolicy ()説明:
最初の単語にのみ適用されます。キュレーションされた高品質のスタートワードのリストからランダムに単語を選択します。
入力:
start_words: Optional[List[str]]=None - 開始単語のキュレーションされたリストをオーバーライドします。 OptimalPolicy from wordle . policy import OptimalPolicy
policy = OptimalPolicy ()説明:
近視では、すべての既知の文字の制約を満たす単語リストから最高の情報ゲインワードを再生します。最適なプレイはNPハードであるため、このポリシーは実際には最適ではありません。しかし、それは非常に高いレベルで再生され、パフォーマンスのためのおおよその上限として使用できます。このポリシーは、単語リストのサイズが2次のパフォーマンスで、計算が非常に遅くなります。計算を保存するには、 self.cache.load(f_path)およびself.cache.dump()使用すると、キャッシュをロードして保存できます。たとえば、 data/wordle/optimal_policy_cache_wordle_official.pkl wordle_official.txtワードリストのこのポリシーのキャッシュを表します。
入力:
start_word_policy: Optional[Policy]=None - 最初の単語は一般に情報のゲインを計算するのに最も高価であるため、これにより、最初の単語のみで呼び出される別のポリシーを指定できます。progress_bar: bool=False - 計算に時間がかかることがあるため、各呼び出しにself.actの進行状況バーを表示するオプションが残ります。 RepeatPolicy from wordle . policy import RepeatPolicy
policy = RepeatPolicy ( start_word_policy = None , first_n = 2 )説明:
既に使用されているfirst_n単語の1つをランダムに繰り返します。これは、最初の言葉で幸運にならない限り勝つことができないため、最大限の準最適なポリシーです。
入力:
start_word_policy: Optional[Policy] - 最初の単語を選択するために使用するポリシー。 None場合は、環境の語彙から単語をランダムに選択します。first_n: Optional[int] - ポリシーは、履歴のfirst_n単語から次の単語をランダムに選択します。 None場合、それは完全な履歴からランダムに選択されます。 RandomMixturePolicy from wordle . policy import RandomMixturePolicy
policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )説明:
確率(1 - prob_smart)で単語リストから完全にランダムに単語を選択し、確率prob_smartを使用してすべての既知の文字の制約を満たす単語リストからランダムな単語を選択します。
入力:
prob_smart: float - 完全にランダムにするのではなく、すべての既知の文字の制約を満たす単語を選択する確率。vocab: Optional[Union[str, Vocabulary]] - から選択する単語リスト。 None場合、ポリシーは環境の単語リストにデフォルトです。 WrongPolicy from wordle . policy import WrongPolicy
from wordle . wordle_game import Vocabulary
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
policy = WrongPolicy ( vocab )説明:
すべての既知の文字の制約を満たすことができないため、正しい単語になることはできない単語リストからワードをランダムに選択します。単語リストのすべての単語が文字の制約を満たしている場合、リストからランダムに単語を選択します。このポリシーは非常に最適です。
入力:
vocab: Union[str, Vocabulary] - 選択できる単語リスト。 MixturePolicy from wordle . policy import MixturePolicy , OptimalPolicy , RandomMixturePolicy
policy1 = OptimalPolicy ()
policy2 = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MixturePolicy ( prob1 = 0.5 , policy1 = policy1 , policy2 = policy2 )説明:
指定された2つのポリシーを混ぜます。 probability prob1を使用してpolicy1から選択し、確率(1 - prob1)でpolicy2から選択します。
入力:
prob1: float - policy1からアクションを選択する確率1。policy1: Policy - アクションを選択する最初のポリシー。確率のprob1で選択されます。policy1: Policy - アクションを選択する2番目のポリシー。確率で選択(1 - prob1) 。 MonteCarloPolicy from wordle . policy import MonteCarloPolicy
sample_policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MonteCarloPolicy ( n_samples = 5 , sample_policy = sample_policy )説明:
ポリシーを取り入れ、環境でモンテカルロロールアウトのn_samples実行し、ロールアウトプロセス中に最高の平均報酬を受け取った次のアクションを選択します。
入力:
n_samples: int - 実行するモンテカルロロールアウトの数。sample_policy: Policy - ロールアウトをサンプリングするポリシー。 
上記のポリシーのいずれかを使用してデータセットを生成できます。データセットは、オフラインのRLエージェントをトレーニングするために使用できます。 src/wordle/wordle_dataset.pyに実装して、2種類の合成データセットを実装します。
wordle.wordle_dataset.WordleListDataset - ファイルからWordleゲームをロードします。wordle.wordle_dataset.WordleIterableDataset - 特定のポリシーのWordleゲームをサンプルします。WordleListDataset :次のようなファイルからWordleデータセットをロードします。
from wordle . wordle_dataset import WordleListDataset
from data . rl_data import ConstantTokenReward
data = WordleListDataset . from_file (
file_path = 'data/wordle/expert_wordle_100k.pkl' ,
max_len = None ,
vocab = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
for i in range ( data . size ()):
item = data . get_item ( i )__init__ def __init__ ( self , items : List [ Tuple [ WordleObservation , Optional [ Dict [ str , Any ]]]], max_len : Optional [ int ], token_reward : TokenReward ) -> None入力:
items: List[Tuple[WordleObservation, Optional[Dict[str, Any]]]] - (wordleobservation、metadata_dict)のタプルの形式のデータのリスト。 Metadata_dictがあらゆる種類のメタデータが、データポイントに保存したいと思うあらゆる種類のメタデータです。max_len: Optional[int] - データセットの最大シーケンス長は、すべてのトークンシーケンスをこの長さに切り捨てます。 None場合、シーケンスは切り捨てられません。token_reward: TokenReward - シーケンスに適用するトークンレベルの報酬。すべての実験に対して、トークンあたり0の一定の報酬を使用します。返品: None
from_file def from_file ( cls , file_path : str , max_len : Optional [ int ], vocab : Optional [ Vocabulary ], token_reward : TokenReward ) -> WordleListDataset入力:
file_path: str - データピクルスファイルへのパス。max_len: Optional[int] - データセットの最大シーケンス長は、すべてのトークンシーケンスをこの長さに切り捨てます。 None場合、シーケンスは切り捨てられません。vocab: Optional[Vocabulary] - 別の環境語彙の下でデータセットをシミュレートします。 None場合、デフォルトでは、データセットの作成に使用されたのと同じ語彙を使用することになります。token_reward: TokenReward - シーケンスに適用するトークンレベルの報酬。すべての実験に対して、トークンあたり0の一定の報酬を使用します。返品: WordleListDatasetオブジェクト。
get_item def get_item ( self , idx : int ) -> DataPoint入力:
idx: int - データセットのインデックス。返品: DataPointオブジェクト。
size def size ( self ) -> int返品:データセットのサイズ。
scripts/data/wordle/の次のスクリプトを使用して、Wordleデータを合成できます。
| スクリプト | 説明 |
|---|---|
generate_data.py | 構成で指定された特定のポリシーから多くのゲームをサンプリングし、それらをファイルに保存します。 |
generate_data_mp.py | 複数のプロセスで並行してゲームをサンプルすることを除いて、 generate_data.pyと同じです。 |
generate_adversarial_data.py | 論文のセクション5で説明されているデータセットを合成します。これは、シングルステップRLメソッドとマルチステップの方法の違いを示すように設計されています。 |
generate_adversarial_data_mp.py | 複数のプロセスで並行してゲームをサンプルすることを除いて、 generate_adversarial_data.pyと同じです。 |
generate_data_branch.py | 特定の「エキスパート」ポリシーからゲームをサンプリングし、ゲーム内の各アクションから、「最適ではない」ポリシーは、多くの新しいゲームをサンプリングして分岐します。 |
generate_data_branch_mp.py | 複数のプロセスで並行してゲームをサンプルすることを除いて、 generate_data_branch.pyと同じです。 |
提供された合成ワードルデータセットはdata/wordle/にあります。
| ファイル | 説明 |
|---|---|
expert_wordle_100k_1.pkl | OptimalPolicyからサンプリングされた100Kゲーム。 |
expert_wordle_100k_2.pkl | OptimalPolicyからサンプリングされた別の100Kゲーム。 |
expert_wordle_adversarial_20k.pkl | ペーパーのセクション5で説明されているデータセットは、シングルステップRLメソッドとマルチステップの方法の違いを示すように設計されています。 |
expert_wordle_branch_100k.pkl | generate_data_branch.pyを使用して100kゲームをサンプリングし、 OptimalPolicyからWrongPolicyからサンプリングされたブランチを使用します。 |
expert_wordle_branch_150k.pkl | generate_data_branch.pyを使用して、 OptimalPolicyのWrongPolicyを使用してサンプリングされた別の150kゲーム。 |
expert_wordle_branch_2k_10sub.pkl | generate_data_branch.pyを使用してサンプリングされた2kゲームはexpert_wordle_branch_100k.pkl OptimalPolicyからサンプリングされたアクションごとに10のブランチを使用して、 WrongPolicyからサンプリングされました。 |
expert_wordle_branch_20k_10sub.pkl | 2Kゲームではなく20Kゲームを除いて、 expert_wordle_branch_2k_10sub.pklと同じです。 |
WordleIterableDataset :次のようなポリシーからWordleデータサンプリングを生成します。
from wordle . wordle_dataset import WordleIterableDataset
from wordle . policy import OptimalPolicy
from data . rl_data import ConstantTokenReward
policy = OptimalPolicy ()
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
data = WordleIterableDataset (
policy = policy ,
vocab = vocab ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
while True :
item = data . sample_item ()__init__ def __init__ ( self , policy : Policy , vocab : Vocabulary , max_len : Optional [ int ], token_reward : TokenReward ) -> None入力:
policy: Policy - サンプリングするポリシー。vocab: Vocabulary - 環境の語彙。max_len: Optional[int] - データセットの最大シーケンス長は、すべてのトークンシーケンスをこの長さに切り捨てます。 None場合、シーケンスは切り捨てられません。token_reward: TokenReward - シーケンスに適用するトークンレベルの報酬。すべての実験に対して、トークンあたり0の一定の報酬を使用します。返品: None
sample_item def sample_item ( self ) -> DataPoint返品: DataPointオブジェクト。
このようなWordleゲームの200Kを超えるツイートの大きなデータセットがあります。
これらの色の遷移正方形に単語を改造して、Wordleゲームの実際のデータセットを作成できます。
生のツイートデータはdata/wordle/tweets.csvに記載されていますが、使用可能になるには、実際の単語をツイートの色の正方形に改造する必要があります。このレトロフィットプロセスを実行するには、VoCabリストの下で発生する可能性のあるすべてのカラー遷移をキャッシュする前処理スクリプトを実行する必要があります: guess_vocab (推測可能な単語のセット)およびcorrect_vocab (環境内の可能な正しい単語のセット)。その結果、 wordle.wordle_dataset.WordleHumanDatasetが使用して、ツイートから有効なWordleゲームを合成するデータ構造が得られました。このスクリプトはscripts/data/wordle/build_human_datastructure.pyです。次のようなスクリプトを呼び出します:
cd scripts/data/wordle/
python build_human_datastructure.py --guess_vocab=../../../data/wordle/word_lists/wordle_official.txt --correct_vocab=../../../data/wordle/word_lists/wordle_official.txt --tweets_file=../../../data/wordle/tweets.csv --output_file=../../../data/wordle/random_human_tweet_data.jsonスクリプトのargs:
--guess_vocab推測可能な単語のセットを指定します。--correct_vocab環境で可能な正しい単語のセットを指定します。--tweets_fileツイートの生のCSVファイルを指定します--output_file出力をダンプする場所を指定します。いくつかの単語リストで前処理を実行し、結果はdata/wordle/に保存されました。
| 単語リスト | プリプロセッシングされたツイートデータファイル |
|---|---|
wordle_official.txt | random_human_tweet_data.json |
wordle_official_800.txt | random_human_tweet_data_800.json |
wordle_official_400.txt | random_human_tweet_data_400.json |
wordle_official_200.txt | random_human_tweet_data_200.json |
tweet_words.txt | human_tweet_data_true_word.json |
これらのファイルのいずれかを考えると、Wordle Tweet Datasetを次のようにロードできます。
from wordle . wordle_dataset import WordleHumanDataset
data = WordleHumanDataset . from_file ( 'data/wordle/random_human_tweet_data_200.json' )
print ( data . sample_item ())実験で'data/wordle/random_human_tweet_data_200.json'を使用しました。
WordleHumanDataset : __init__ def __init__ ( self , games : List [ Tuple [ str , List [ str ]]], transitions : Dict [ str , Dict [ str , List [ str ]]], use_true_word : bool , max_len : Optional [ int ], token_reward : TokenReward , game_indexes : Optional [ List [ int ]], top_p : Optional [ float ]) -> None入力:
games: List[Tuple[str, List[str]]] - フォームのタプルのリスト(correct_wordle_word, wordle_transitions_list) wordle_transitions_list ["<b><b><y><y><b>", "<g><b><b><b><b>", "<g><g><y><b><b>", "<g><g><g><g><g>"] 。transitions: Dict[str, Dict[str, List[str]]] - その単語によって誘導される可能性のある別のdictを別のdictマッピングにマッピングして、その遷移を引き起こすために再生される可能性のある単語のリストにマッピングします。このデータ構造は、ツイートに単語を改造するために使用されます。use_true_word: bool - Trueの場合は、ツイートからグラウンドトゥルースの正しい単語を使用します。max_len: Optional[int] - データセットの最大シーケンス長は、すべてのトークンシーケンスをこの長さに切り捨てます。 None場合、シーケンスは切り捨てられません。token_reward: TokenReward - シーケンスに適用するトークンレベルの報酬。すべての実験に対して、トークンあたり0の一定の報酬を使用します。game_indexes: Optional[List[int]] - ツイートの分割を作成するインデックスのリスト。 None場合、データ内のすべてのアイテムが使用されます。 data/wordle/human_eval_idxs.jsonとdata/wordle/human_train_idxs.jsonがランダムに選択された列車と評価の分割として作成されています。top_p: Optional[float] - データの割合を実行するtop_pのフィルター。 None場合、データはフィルタリングされません。 %BCモデルで使用されます。返品: None
from_file def from_file ( cls , file_path : str , use_true_word : bool = False , max_len : Optional [ int ] = None , token_reward : Optional [ TokenReward ] = None , top_p : Optional [ float ] = None ) -> WordleHumanDataset入力:
file_path: str - データをロードするJSONファイルへのパス。use_true_word: bool - Trueの場合は、ツイートからグラウンドトゥルースの正しい単語を使用します。max_len: Optional[int] - データセットの最大シーケンス長は、すべてのトークンシーケンスをこの長さに切り捨てます。 None場合、シーケンスは切り捨てられません。token_reward: TokenReward - シーケンスに適用するトークンレベルの報酬。すべての実験に対して、トークンあたり0の一定の報酬を使用します。game_indexes: Optional[List[int]] - ツイートの分割を作成するインデックスのリスト。 None場合、データ内のすべてのアイテムが使用されます。 data/wordle/human_eval_idxs.jsonとdata/wordle/human_train_idxs.jsonがランダムに選択された列車と評価の分割として作成されています。top_p: Optional[float] - データの割合を実行するtop_pのフィルター。 None場合、データはフィルタリングされません。 %BCモデルで使用されます。返品: WordleHumanDatasetオブジェクト。
sample_item def sample_item ( self ) -> DataPoint返品: DataPointオブジェクト。
トレーニングスクリプトはscripts/train/wordle/にあります。
| スクリプト | 説明 |
|---|---|
train_bc.py | BCエージェントを訓練します。 |
train_iql.py | ILQLエージェントをトレーニングします。 |
評価スクリプトはscripts/eval/wordle/にあります。
| スクリプト | 説明 |
|---|---|
eval_policy.py | Wordle環境でBCまたはILQLエージェントを評価します。 |
eval_q_rank.py | シングルステップRLとマルチステップRLの違いを示すように設計された、ペーパーのセクション5で説明されている合成データセットでトレーニングされたエージェントのQ値の相対ランクを比較するための評価スクリプト。 |
distill_policy_eval.py | エラーバーを使用してeval_policy.pyの結果を印刷します。 |
ここでは、コードベースに視覚的なダイアログデータをロードする方法と環境を実行する方法の概要を説明します。ビジュアルダイアログ環境のリモートコンポーネントをセットアップする方法については、上記のセットアップセクションを参照してください。データと環境のオブジェクトはConfig Managerによって自動的にロードされますが、構成システムをバイパスし、独自のコードベースで環境を使用する場合は、これらのオブジェクトをロード、実行、構成する方法を次に示します。以下で説明するのと同じ設定は、すべて構成でも変更できます。
視覚的な対話環境をロードする方法の例:
from visdial . visdial_env import VDEnvironment
from visdial . visdial_base import VisDialogueData
from visdial . visdial_dataset import VisDialListDataset
from data . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = VisDialogueData (
data_path = convert_path ( 'data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.json' ),
img_feat_path = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/data_img.h5' ),
split = 'train' ,
reward_cache = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/train_rank_reward_cache1.json' ),
yn_reward_kind = 'none'
)
list_data = VisDialListDataset (
data = data ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 )
)
env = VDEnvironment (
dataset = list_data ,
url = 'http://localhost:5000/step_rank' ,
yn_reward = - 2.0 ,
yn_reward_kind = 'none'
)
print ( env . reset ())上記のスクリプトは、「標準的な」報酬実験用にデータセットと環境を構成する方法に対応していますが、データセットを異なる方法で構成する場合は、変更できる多くの引数があります。データセットの分割を変更するだけでなく、これらの引数はタスクまたは報酬を変更することもできます。以下では、 VisDialogueData 、 VisDialListDataset 、およびVDEnvironmentのすべてのさまざまな構成可能なパラメーターについて説明します。
VisDialogueData 、 VisDialListDataset 、およびVDEnvironmentのパラメーターと方法を文書化するため、環境を自分で構成する方法を知っています。
VisDialogueData : src/visdial/visdial_base.pyに実装されたVisDialogueDataは、タスクの対話と報酬のセットを保存します。
__init__ def __init__ ( self , data_path : str , img_feat_path : str , split : str , reward_cache : Optional [ str ] = None , norm_img_feats : bool = True , reward_shift : float = 0.0 , reward_scale : float = 1.0 , addition_scenes : Optional [ List [ Scene ]] = None , mode : str = 'env_stops' , cutoff_rule : Optional [ CutoffRule ] = None , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> None入力:
data_path: str - ダイアログデータへのパス。の1つである必要があります:data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_val.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_test.jsonimg_feat_path: str - 各ダイアログの報酬を計算するために使用される画像機能へのパス。常にdata/vis_dialogue/processed/visdial_0.5/data_img.h5である必要があります。split: str - train 、 val 、またはtestの1つ。使用する画像機能のデータセット分割を示します。 data_path分割と一致するはずです。reward_cache: Optional[str]=None - 各ダイアログの報酬が保存されている場合。 None場合、それはすべての報酬をNoneに設定します。 2つの報酬機能にキャッシュを提供します。train data/vis_dialogue/processed/visdial_0.5/[split]_rank_reward_cache1.json [split] testされていますvaltrain [split]ベースの報酬は、 test data/vis_dialogue/processed/visdial_0.5/[split]_reward_cache2.json valキャッシュされます。norm_img_feats: bool=True - 画像機能を正規化するかどうか。reward_shift: float=0.0 - この金額で報酬をシフトします。reward_scale: float=1.0 - この金額で報酬をスケーリングします。addition_scenes: Optional[List[Scene]]=None - 追加データをデータセットに挿入します。mode: str='env_stops' - ['agent_stops', 'env_stops', '10_stop'] 。タスクの一部のプロパティを制御します。 env_stopsを使用していますmode='env_stops'の場合、 cutoff_ruleに従って環境の相互作用を早期に停止します。mode='agent_stops'の場合、エージェントは、アクション中に特別な<stop>トークンを生成することにより相互作用を停止します。すべての可能なアクションの後に<stop>を配置することにより、データを拡張します。mode='10_stop'の場合、視覚的なダイアログデータセットの標準であるように、プレイは常に10ラウンドの相互作用の後に停止します。cutoff_rule: Optional[CutoffRule]=None - mode='env_stops'の場合にのみ適用されます。環境がいつ早期に相互作用を停止するかを決定する関数を実装します。すべての実験で、 visdial.visdial_base.PercentileCutoffRule(1.0, 0.5)のデフォルトを使用します。yn_reward: float=-2.0 - yes/noの質問をするために追加すべき報酬ペナルティ。yn_reward_kind: str='none' - yes/noの疑問が尋ねられたかどうかを判断するために使用される文字列の一致ヒューリスティックを指定します。 ['none', 'soft', 'hard', 'conservative']の1つである必要があります。'none' :はい/いいえの質問にペナルティを科さないでください。これは、私たちの論文のstandard報酬に対応しています。'soft' :応答にサブストリングとして"yes"または"no"が含まれている場合、質問をペナルティします。'hard' :応答が文字列"yes"または"no"と正確に一致する場合、質問をペナルティにします。これは、私たちの論文の"y/n"報酬に対応しています。'conservative' :応答がいくつかの文字列に一致するヒューリスティックのいずれかを満たしている場合、質問を罰します。これは、私たちの論文の"conservative y/n"報酬に対応しています。返品: None
__len__ def __len__ ( self ) -> int返品:データセットのサイズ。
__getitem__ def __getitem__ ( self , i : int ) -> Scene入力:
i: int - データセットインデックス。返品:データセットからのアイテム。
VisDialListDataset : src/visdial/visdial_dataset.pyに実装されたVisDialListDatasetは、 VisDialogueDataを包み込み、オフラインのRLエージェントのトレーニングに使用できるDataPoint形式に変換します。
__init__ def __init__ ( self , data : VisDialogueData , max_len : Optional [ int ], token_reward : TokenReward , top_p : Optional [ float ] = None , bottom_p : Optional [ float ] = None ) -> None入力:
data: VisDialogueData - すべての生データを保存する視覚的なダイアログデータオブジェクト。max_len: Optional[int] - データセットの最大シーケンス長は、すべてのトークンシーケンスをこの長さに切り捨てます。 None場合、シーケンスは切り捨てられません。token_reward: TokenReward - シーケンスに適用するトークンレベルの報酬。すべての実験に対して、トークンあたり0の一定の報酬を使用します。top_p: Optional[float] - データの割合を実行するtop_pのフィルター。 None場合、データはフィルタリングされません。 %BCモデルで使用されます。bottom_p: Optional[float] - データの割合を実行するbottom_pのフィルター。 None場合、データはフィルタリングされません。返品: None
size def size ( self ) -> int返品:データセットのサイズ。
get_item def get_item ( self , idx : int ) -> DataPoint入力:
i: int - データセットインデックス。返品:データセットからのDataPoint 。
VDEnvironment : src/visdial/visdial_env.pyで実装されているVDEnvironment 、視覚的な対話環境を定義します。環境には、LocalHostサーバーへの接続が含まれます。セットアップセクションでは、スピンアップ方法について説明します。
__init__ def __init__ ( self , dataset : RL_Dataset , url : str , reward_shift : float = 0.0 , reward_scale : float = 1.0 , actor_stop : bool = False , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> None入力:
dataset: RL_Dataset - RL_Datasetを取得します。具体的には、上記のようにVisDialListDataset 。このデータセットは、初期状態を選択するために使用されます。url: str - 環境を踏むためのURL。このURLに対応するLocalHost Webサーバーを初期化する方法については、セットアップセクションの指示に従ってください。reward_shift: float=0.0 - この金額で報酬をシフトします。reward_scale: float=1.0 - この金額で報酬をスケーリングします。actor_stop: bool=False - 特別な<stop>トークンを生成することにより、アクターがインタラクションを早期に停止できるようにします。yn_reward: float=-2.0 - yes/noの質問をするために追加すべき報酬ペナルティ。yn_reward_kind: str='none' - yes/noの疑問が尋ねられたかどうかを判断するために使用される文字列の一致ヒューリスティックを指定します。 ['none', 'soft', 'hard', 'conservative']の1つである必要があります。'none' :はい/いいえの質問にペナルティを科さないでください。これは、私たちの論文のstandard報酬に対応しています。'soft' :応答にサブストリングとして"yes"または"no"が含まれている場合、質問をペナルティします。'hard' :応答が文字列"yes"または"no"と正確に一致する場合、質問をペナルティにします。これは、私たちの論文の"y/n"報酬に対応しています。'conservative' :応答がいくつかの文字列に一致するヒューリスティックのいずれかを満たしている場合、質問を罰します。これは、私たちの論文の"conservative y/n"報酬に対応しています。返品: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]入力:
action: Vocabulary - 環境の語彙返品:(観察、報酬、ターミナル)タプル。
reset def reset ( self ) -> WordleObservation返品:観察
is_terminal def is_terminal ( self ) -> bool返品:相互作用が終了したかどうかを示すブール値。
トレーニングスクリプトはscripts/train/vis_dial/にあります。
| スクリプト | 説明 |
|---|---|
train_bc.py | BCエージェントを訓練します。 |
train_chai.py | チャイエージェントを訓練します。 |
train_cql.py | CQLエージェントをトレーニングします。 |
train_dt.py | 意思決定トランスエージェントを訓練します。 |
train_iql.py | ILQLエージェントをトレーニングします。 |
train_psi.py | トレーニングan |
train_utterance.py | 発話レベルのILQLエージェントをトレーニングします。 |
評価スクリプトはscripts/eval/vis_dial/にあります。
| スクリプト | 説明 |
|---|---|
eval_policy.py | 視覚的な対話環境でエージェントを評価します。 |
top_advantage.py | モデルの下で最大かつ最小の利点がある質問を見つけます。 |
distill_policy_eval.py | エラーバーを使用してeval_policy.pyの結果を印刷します。 |
Here we outline how to load the Reddit comments data in our codebase and how to execute the environment. See the setup section above for how to setup the toxicity filter reward. The data and environment objects are loaded automatically by the config manager, but if you want to by-pass the config system and use the task with your own codebase, here's how you should load, execute, and configure these objects. The same settings described below can all be modified in the configs as well.
An example of how to load the Reddit comment environment:
from toxicity . toxicity_env import ToxicityEnvironment
from toxicity . reddit_comments_base import RedditData
from toxicity . reward_fs import toxicity_reward
from utils . misc import convert_path
idxs = json . load ( open ( convert_path ( 'data/reddit_comments/train_idxs.json' ), 'r' ))
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = idxs ,
reward_f = toxicity_reward
)
env = ToxicityEnvironment (
data = data ,
reward_f = toxicity_reward
)
print ( env . reset ())
The above script corresponds to how we configured the environment for our toxicity reward experiments, but if you want to configure the environment differently, there are a few arguments you can modify. These arguments can also change the task or reward. Below we describe all the different configurable parameters that our reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment take.
We document the parameters and methods for our different Reddit comment reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment , so that you know how to configure the environment yourself.
Here we outline the 4 main reward functions we use for our Reddit comment task. Each of these rewards is implemented in src/toxicity/reward_fs.py .
toxicity_reward from toxicity . reward_fs import toxicity_reward
reward_f = toxicity_reward ()説明:
The "toxicity" reward from our paper, which queries the GPT-3 toxicity filter. It assigns a value of "0" to non-toxic comments, a value of "1" to moderately toxic comments, and a value of "2" to very toxic comments.
toxicity_noised_reward from toxicity . reward_fs import toxicity_noised_reward
reward_f = toxicity_noised_reward ()説明:
The "noised toxicity" reward from our paper, which is the same as toxicity_noised_reward but induces additional noise. Specifically, it re-assigns comments labeled as "1" (moderately toxic) to either "0" (non-toxic) or "2" (extremely toxic) with equal probability.
score_human_reward from toxicity . reward_fs import score_human_reward
from utils . misc import convert_path
reward_f = score_human_reward (
reddit_path = convert_path ( 'data/reddit_comments/' ),
indexes = None
)説明:
The "upvotes real" reward from our paper, which gives a reward of +1 for positive upvote comments and -1 for negative upvote comments. This uses the ground truth upvotes in the data, so it only applies to comments in the dataset and cannot be used for evaluation. If you input a string not present in the data, it will error. The arguments to this function specify what data to load.
Inputs:
reddit_path: str – a path to the data.indexes: List[int] – a split of indexes in the data to use. If None , it considers all the data. model_reward from toxicity . reward_fs import score_human_reward
from toxicity . reddit_comments_base import RedditData
from toxicity . toxicity_dataset import ToxicityListDataset
from toxicity . reward_model import RobertaBinaryRewardModel
from utils . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = None ,
reward_f = None
)
listdata = ToxicityListDataset (
data = data ,
max_len = 512 ,
token_reward = ConstantTokenReward ( 0.0 )
)
model = RobertaBinaryRewardModel (
data = listdata ,
device = 'cuda' ,
roberta_kind = 'roberta-base' ,
freeze_roberta = False ,
reward_cuttoff = 0.0
)
model . load_state_dict ( torch . load ( convert_path ( 'outputs/toxicity/upvote_reward/model.pkl' ), map_location = 'cpu' ))
reward_f = score_human_reward ( model = model )説明:
The "upvotes model" reward from our paper, which gives a reward of +1 if the given model predicts that the comment will get a positive number of upvotes and a reward of -1 otherwise. The model checkpoint we used for our experiments is at: outputs/toxicity/upvote_reward/model.pkl
Inputs:
model: RewardModel : the reward model implemented in src/toxicity/reward_model.py . The model should be first trained and loaded from a pytorch checkpoint.RedditData : RedditData , implemented in src/toxicity/reddit_comments_base.py , stores the raw Reddit comments data.
__init__ def __init__ ( self , path : str , indexes : Optional [ List [ int ]], reward_f : Optional [ Callable [[ str ], float ]], reward_cache : Optional [ Cache ] = None , reward_shift : float = 0.0 , reward_scale : float = 1.0 ) -> NoneInputs:
path: str – the path to the Reddit data.indexes: Optional[List[int]] – a list of indexes to create a split of the data. Randomly selected, training, validation, and test splits are in the json files:data/reddit_comments/train_idxs.jsondata/reddit_comments/eval_idxs.jsondata/reddit_comments/test_idxs.jsonreward_f: Optional[Callable[[str], float]] – the reward function to use.reward_cache: Optional[Cache]=None – a cache of reward values, so you don't have to recompute them everytime.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount. Returns: None
__len__ def __len__ ( self ) -> intReturns: the size of the dataset.
__getitem__ def __getitem__ ( self , idx : int ) -> SceneInputs:
idx: int – the dataset index.Returns: an item from the dataset.
ToxicityListDataset : ToxicityListDataset , implemented in src/toxicity/toxicity_dataset.py , wraps around RedditData and converts it into a DataPoint format that can be used to train offline RL agents.
__init__ def __init__ ( self , data : RedditData , max_len : Optional [ int ], token_reward : TokenReward , cuttoff : Optional [ float ] = None , resample_timeout : float = 0.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – a Reddit comment data object that stores all the raw data.max_len: Optional[int] – the maximum sequence length in the dataset, will truncate all token sequences to this length. If None , then sequences will not be truncated.token_reward: TokenReward – the token-level reward to apply to the sequences. We use a constant reward of 0 per-token for all experiments.cuttoff: Optional[float]=None – filter out all comments from the dataset with reward less than cuttoff . If None , no data will be filtered. Used with %BC models.resample_timeout: float=0.0 – when cuttoff is not equal to None , comments are stochastically sampled iid from the dataset, like an iterable, even though the dataset has a list-type interface. It uniformly re-samples from the dataset until it finds a comment with a reward that satisfies the cuttoff. In the case of the "toxicity" reward, this re-sampling can cause rate-limit errors on the GPT-3 API, so we allow you to add a resample_timeout to fix this issue: a timeout of roughly 0.05 should fix rate-limit issues.include_parent: bool=True – whether to condition on the parent comment in the thread. If False , models will be trained to generate comments unconditionally. Returns: None
size def size ( self ) -> intReturns: the size of the dataset.
get_item def get_item ( self , idx : int ) -> DataPointInputs:
i: int – the dataset index. Returns: a DataPoint from the dataset.
ToxicityEnvironment : ToxicityEnvironment , implemented in src/toxicity/toxicity_env.py , defines the Reddit comment generation environment, which our offline RL agents interact with at evaluation time.
__init__ def __init__ ( self , data : RedditData , reward_f : Optional [ Callable [[ str ], float ]], reward_shift : float = 0.0 , reward_scale : float = 1.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – the dataset used to select initial state parent comments to condition on.reward_f: Optional[Callable[[str], float]] – the reward function to use.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount.include_parent: bool=True – specifies whether to condition on the previous comment or post in the Reddit thread. Returns: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Inputs:
action: Vocabulary – the environment's vocabularyReturns: an (observation, reward, terminal) tuple.
reset def reset ( self ) -> WordleObservationReturns: an observation
is_terminal def is_terminal ( self ) -> boolReturns: a boolean indicating if the interaction has terminated.
Training scripts are in scripts/train/toxicity/ .
| スクリプト | 説明 |
|---|---|
train_bc.py | Train a BC agent. |
train_iql.py | Train an ILQL agent. |
train_upvote_reward.py | Train the upvote reward model. |
Evaluation scripts are in scripts/eval/toxicity/ .
| スクリプト | 説明 |
|---|---|
eval_policy.py | Evaluate an agent in the Reddit comments environment. |
distill_policy_eval.py | Prints out the result of eval_policy.py with error bars. |
All tasks – Wordle, Visual Dialogue, Reddit – have a corresponding environment and dataset implemented in the codebase, as described above. And all offline RL algorithms in the codebase are trained, executed, and evaluated on one of these given environments and datasets.
You can similarly define your own tasks that can easily be run on all these offline RL algorithms. This codebase implements a simple set of RL environment abstractions that make it possible to define your own environments and datasets that can plug-and-play with any of the offline RL algorithms.
All of the core abstractions are defined in src/data/ . Here we outline what needs to be implemented in order to create your own tasks. For examples, see the implementations in src/wordle/ , src/vis_dial/ , and src/toxicity/ .
All tasks must implement subclasses of: Language_Observation and Language_Environment , which are in src/data/language_environment.py .
Language_Observation :This class represents the observations from the environment that will be input to your language model.
A Language_Observation must define the following two functions.
to_sequence def to_sequence ( self ) -> Tuple [ List [ str , Optional [ float ]], bool ]:説明:
A function which converts the observation object into a standard format that can be input to the language model and used for training.
返品:
__str__ def __str__ ( self ) -> str :説明:
This is only used to print the observation to the terminal. It should convert the observation into some kind of string that is interpretable by a user.
Returns: a string.
Language_Environment :This class represents a gym-style environment for online interaction, which is only used for evaluation.
A Language_Environment must define the following three functions.
step def step ( self , action : str ) -> Tuple [ Language_Observation , float , bool ]:説明:
Just like a standard gym environment, given an action in the form of a string, step the environment forward.
Returns: a tuple of (Language_Observation, reward, terminal).
reset def reset ( self ) -> Language_Observation :説明:
This resets the environment to an initial state.
Returns: the corresponding initial Language_Observation
is_terminal def is_terminal ( self ) -> bool :説明:
Outputs whether the environment has reached a terminal state.
Returns: a boolean indicating if the environment has reached a terminal state.
All tasks must implement subclasses of either List_RL_Dataset or Iterable_RL_Dataset or both, which are defined in src/data/rl_data.py .
List_RL_Dataset :This class represents a list dataset (or an indexable dataset of finite length) that can be used to train offline RL agents.
A List_RL_Dataset must define the following two functions.
get_item def get_item ( self , idx : int ) -> DataPoint説明:
This gets an item from the dataset at a given index.
Returns: a DataPoint object from the dataset.
size def size ( self ) -> int説明:
Returns the size of the dataset.
Returns: the dataset's size.
Iterable_RL_Dataset :This class represents an iterable dataset (or a non-indexable dataset that stochastically samples datapoints iid) that can be used to train offline RL agents.
A Iterable_RL_Dataset must define the following function.
sample_item def sample_item ( self ) -> DataPoint説明:
Samples a datapoint from the dataset.
Returns: a DataPoint object from the dataset.


