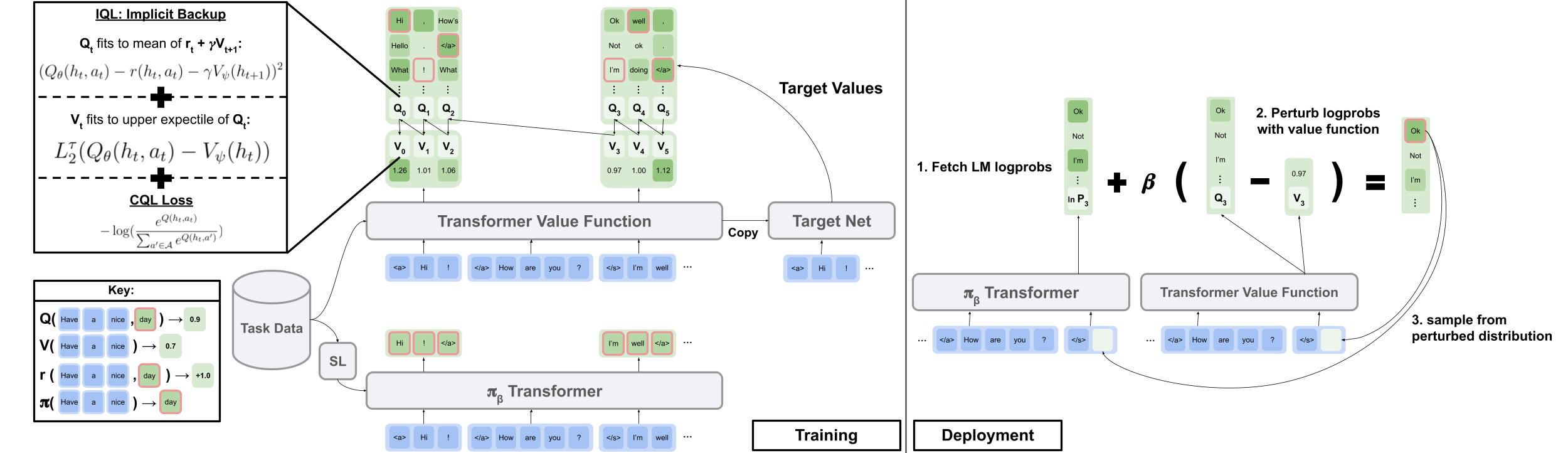
Implicit Language Q Learning
1.0.0
Официальный код из статьи «Офлайн RL для генерации естественного языка с неявным языком Q Learning»
Сайт проекта | arxiv
Загрузите data.zip и outputs.zip из папки Google Drive здесь. Поместите загруженные и расслабленные папки, data/ и outputs/ , в корне репо. data/ содержит предварительно обработанные данные для всех наших задач и outputs/ содержит контрольную точку для наших комментариев Reddit Upvote.
Это репо было разработано для Python 3.9.7
pip install -r requirements.txt
export PYTHONPATH= " $PWD /src/ "Чтобы запустить эксперименты по визуальному диалогу, вам необходимо обслуживать среду визуального диалога на Localhost, следуя инструкциям здесь.
Чтобы запустить эксперименты с комментарием Reddit с вознаграждением фильтра токсичности:
export OPENAI_API_KEY=your_API_key scripts/ содержит все сценарии экспериментов. Чтобы запустить любой сценарий в scripts/ :
python script_name.pyНеобязательный:
python script_name.py eval.bsize=5 train.lr=1e-6 wandb.use_wandb=falsepython -m torch.distributed.launch --nproc_per_node [N_GPUs] --use_env script_name.py arg1=a arg2=b По умолчанию все тренировочные сценарии журнал в Wandb. Чтобы выключить это, установите wandb.use_wandb=false в тренировочной конфигурации.
Здесь я обрисовываю рекомендуемый рабочий процесс для обучения автономных агентов RL. Предположим, что я хочу обучить кучу различных автономных RL -агентов, чтобы генерировать комментарии Reddit с вознаграждением о токсичности.
Сначала я бы тренировал модель BC на данные:
cd scripts/train/toxicity/
python train_bc.pyЗатем преобразуйте эту контрольную точку BC в одну совместимую с автономными моделями RL:
cd ../data/
python convert_bc.py --load ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model.pkl --save ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model_converted.pklЗатем отредактируйте контрольную точку, которую автономный RL настроен на обучение:
cd ../train/
python train_iql.py model.load.checkpoint_path=outputs/toxicity/model_converted.pkl model.load.strict_load=false train.loss.awac_weight=0.0 Это всего лишь один рабочий процесс, вы также можете обучить модель BC одновременно с автономным агентом RL, установив train.loss.awac_weight=1.0 в тренировочной конфигурации.
data/ папке.scripts/ содержит все сценарии для выполнения этапов обучения, оценки и предварительной обработки данных в статье. Сценарии организованы в подпапки, соответствующие используемому набору данных.config/ содержит .yaml configs для каждого сценария. Этот репо использует Hydra для управления конфигурациями. Конфигурации организованы в подпапки, соответствующие используемому набору данных. Большинство файлов конфигурации называются так же, как и их соответствующий скрипт, но если вы не уверены, какой конфигурация соответствует скрипту, проверьте линию @hydra.main(config_path="some_path", config_name="some_name") чтобы увидеть, какой файл конфигурации соответствует скрипту.src/ содержит все основные реализации. См. src/models/ для всех реализаций моделей. См. src/data/ для всех базовых обработок данных и кода абстракции MDP. См. src/utils/ для различных коммунальных функций. См src/wordle/ , src/visdial , и src/toxicity/ для всех Wordle, Visual Dialogue и Special Code Comment Complict Special.ILQL называется iql по всему репо. Каждый скрипт связан с файлом конфигурации. Файл конфигурации указывает, какие модели, набор данных и оценщики должны быть загружены сценарием и соответствующими гиперпараметрами. См configs/toxicity/train_iql.yaml для примера.
Каждому возможным модели, набору данных или объекту оценщика предоставляется собственный файл конфигурации, который указывает значения по умолчанию для этого объекта и атрибут специального name , который сообщает Config Manager, какой класс загрузить. См configs/toxicity/model/per_token_iql.yaml для примера.
Файлы src/load_objects.py , src/wordle/load_objects.py , src/visdial/load_objects.py и src/toxicity/load_objects.py определяют, как каждый объект загружается из соответствующей конфигурации. Тег @register('name') выше каждой ссылки функции объекта загрузки на атрибут name в конфигурации.
Вы можете заметить специальный атрибут cache_id , связанный с некоторыми объектами в конфигурации. Для примера см. train_dataset в configs/toxicity/train_iql.yaml . Этот атрибут говорит Manager Config Cache первого объекта, который он загружает, который связан с этим идентификатором, а затем вернуть этот кэшированный объект для последующих конфигураций объекта с помощью этого cache_id .
Для всех конфигураций используйте пути по сравнению с корнем репо.
Каждая из задач в нашем репо - Wordle, Visual Dialogue и Reddit Comments - реализует несколько базовых классов. После реализации все алгоритмы RL в автономном режиме могут быть применены к задаче с помощью подключаемого манера. См. Раздел «Создание ваших собственных задач» для обзора того, что должно быть реализовано для создания собственных задач. Ниже мы обрисоваем ключевые абстракции, которые делают это возможным.
data.language_environment.Language_Environment - представляет собой среду задачи POMDP, с которой политика может взаимодействовать. У него есть тренажерный интерфейс.data.language_environment.Policy - представляет собой политику, которая может взаимодействовать с окружающей средой. Каждый из автономных алгоритмов RL в src/models/ имеет соответствующую политику.data.language_environment.Language_Observation - представляет текстовое наблюдение, которое возвращается средой и придается в качестве входной политики.data.language_environment.interact_environment - функция, которая принимает среду, политику и, необязательно, текущее наблюдение и запускает цикл взаимодействия среды. Если текущее наблюдение не предоставлено, оно автоматически получает начальное состояние, сбросив окружающую среду.data.rl_data.DataPoint - определяет стандартизированный формат данных, который подается в качестве входных данных для всех автономных агентов RL по всем задачам. Эти структуры данных создаются автоматически из данной Language_Observation .data.rl_data.TokenReward - определяет функцию вознаграждения, заданную в каждом токене, которая может использоваться для обучения более тонкозернистому контролю. Это предоставляется в дополнение к вознаграждению окружающей среды, которая поступает не в каждом токене, а после каждого поворота взаимодействия. Во всех наших экспериментах мы установили эту награду на постоянную 0, так что она не имеет никакого эффекта.data.tokenizer.Tokenizer - указывает, как преобразовать строки в последовательности токенов и из токенов, которые затем можно питать как входные в языковые модели.data.rl_data.RL_Dataset - определяет объект набора данных, который возвращает объекты DataPoint и используется для обучения автономных агентов RL. Есть две версии RL_Dataset :List_RL_DatasetIterable_RL_Dataset
Здесь мы обрисовываем и документируем все компоненты нашей задачи Wordle.
Большая часть того, что находится в примере сценариев, выполняется автоматически диспетчере конфигурации, и соответствующие параметры могут быть отредактированы путем изменения конфигураций. Но если вы хотите обойтись, используя конфигурации и используете задачу Wordle с помощью собственной кодовой базы, вы можете ссылаться на сценарии и документацию ниже для того, как это сделать.
Простой пример сценария для воспроизведения Wordle в командной линии.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from wordle . policy import UserPolicy
from data . language_environment import interact_environment
from utils . misc import convert_path
game_vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( game_vocab )
policy = UserPolicy ()
interact_environment ( env , policy )src/wordle/wordle_game.pysrc/wordle/wordle_env.pysrc/wordle/policy.pysrc/wordle/wordle_dataset.pyЧтобы сделать игру действительным MDP, среда представляет собой базовое состояние как набор известных буквенных ограничений и использует их для фильтрации словаря для слов, которые соответствуют всем этим ограничениям на каждом шагу. Затем из этого списка слов выбирается случайное слово и используется для определения цветовых переходов, возвращаемых окружающей средой. Эти новые цветные переходы затем обновляют набор известных буквенных ограничений.
Среда Wordle входит в список слов. Несколько списков слов приведены в data/wordle/word_lists/ , но не стесняйтесь делать свои собственные.
Списки слов включены:
Списки слов загружаются в среду через Vocabulary объект, как в примере выше.
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))Словарь хранит не только список слов, но также отслеживает отфильтрованный список слов, которые соответствуют всем известным ограничениям букв в данном состоянии. Этот список используется для вычисления переходов в окружающей среде и используется некоторыми из ручных политик.
Создание этих фильтрованных списков в режиме реального времени может замедлить процесс взаимодействия окружающей среды. Обычно это не должно быть проблемой, но если вы хотите быстро синтезировать множество данных из политики, то это может стать узким местом. Чтобы преодолеть это, все Vocabulary объекты хранят аргумент cache , который кэширует эти фильтрованные списки слов, связанные с данным состоянием. vocab.cache.load(f_path) и vocab.cache.dump() позволяет загружать и сохранять этот кэш. Например, data/wordle/vocab_cache_wordle_official.pkl - большой кэш для списка слов Wordle_official.txt.
Помимо хранения кэша, Vocabulary объект реализует следующие методы в src/wordle/wordle_game.py :
__init__ def __init__ ( self , all_vocab : List [ str ],
wordle_state : Optional [ WordleState ],
cache : Optional [ Cache ] = None ,
fill_cache : bool = True ) -> NoneВходные данные:
all_vocab: List[str] - список слов.wordle_state: Optional[WordleState] - состояние, из которого можно сгенерировать список фильтрованных слов, если не предоставлено состояние, не отфильтровано слова.cache: Optional[Cache]=Nonefill_cache: bool=True - будь то добавить в кеш. Возвращает: None
from_file def from_file ( cls , vocab_file : str , fill_cache : bool = True ) -> VocabularyВходные данные:
vocab_file: str - файл, из которого можно загрузить слова. Метод выбирает только слова длиной 5 букв.fill_cache: bool=True - будь то добавить в кеш. Возвращение: Vocabulary
filtered_vocab_size def filtered_vocab_size ( self ) -> intВозврат: размер фильтрованного словаря
all_vocab_size def all_vocab_size ( self ) -> intВозвращение: размер полного нефильтрованного словаря
get_random_word_filtered def get_random_word_filtered ( self ) -> strВозврат: случайное слово из фильтрованного списка.
get_random_word_all def get_random_word_all ( self ) -> strВозврат: случайное слово из полного нефильтрованного списка.
update_vocab def update_vocab ( self , wordle_state : WordleState ) -> VocabularyВходные данные:
wordle_state: WordleState - объект Wordle State, представляющий набор известных буквенных ограничений. Возврат: новый Vocabulary объект, который отфильтрован в соответствии с wordle_state .
__str__ def __str__ ( self ) -> strВозврат: строковое представление списка фильтрованных слов для печати на терминал.
WordleEnvironment принимает словарный запас в качестве входного объекта, который определяет набор возможных правильных слов в окружающей среде.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( vocab )
initial_obs = env . reset ()
next_obs , reward , terminal = env . step ( "snake" ) Как показано выше, среда внедряет в спортзал интерфейс в src/wordle/wordle_env.py :
__init__ def __init__ ( self , vocab : Vocabulary ) -> NoneВходные данные:
vocab: Vocabulary - словарный запас окружающей среды. Возвращает: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Входные данные:
action: Vocabulary - строка текста, представляющая действие агента в окружающей среде.Возврат: (наблюдение, вознаграждение, терминал) кортеж.
reset def reset ( self ) -> WordleObservationВозврат: наблюдение.
is_terminal def is_terminal ( self ) -> boolВозврат: логическое, указывающее, прекратилось ли взаимодействие.
Мы внедряем набор политик Wordle, созданных вручную, которые охватывают ряд уровней игрового процесса. Все они реализованы в src/wordle/policy.py . Здесь мы описываем каждый:
UserPolicy from wordle . policy import UserPolicy
policy = UserPolicy ( hint_policy = None , vocab = None )Описание:
Давайте сыграем в терминале.
Входные данные:
hint_policy: Optional[Policy] - Еще одна политика, чтобы запросить, хотите ли вы намек на то, какое слово использовать.vocab: Optional[Union[str, Vocabulary]] - Vocabulary догадных слов. Если не указано, любая 5 -буквенная последовательность Chars является действительным предположением. StartWordPolicy from wordle . policy import StartWordPolicy
policy = StartWordPolicy ()Описание:
Применяться только для первого слова. Выбирает слово случайным образом из списка кураторских, высококачественных начальных слов.
Входные данные:
start_words: Optional[List[str]]=None - переопределить кураторный список начальных слов. OptimalPolicy from wordle . policy import OptimalPolicy
policy = OptimalPolicy ()Описание:
Миопически воспроизводит наибольшее количество информации из списка слов, которое соответствует всем известным ограничениям письма. Эта политика на самом деле не является оптимальной, так как оптимальная игра-NP-Hard. Но он играет на чрезвычайно высоком уровне и может использоваться в качестве приблизительной верхней границы для производительности. Эта политика очень медленно вычислить, с производительности квадратично в размере списка слов; Чтобы сохранить вычисления, self.cache.load(f_path) и self.cache.dump() позволяет загружать и сохранять кэш. Например, data/wordle/optimal_policy_cache_wordle_official.pkl представляет кэш для этой политики в списке слов wordle_official.txt .
Входные данные:
start_word_policy: Optional[Policy]=None - Поскольку первое слово, как правило, является наиболее дорогим для вычисления информации о информации, это позволяет вам указать другую политику, которая будет вызвана только для первого слова.progress_bar: bool=False - Поскольку это может занять так много времени, чтобы вычислить, мы оставляем вам возможность отобразить панель прогресса для каждого вызова для self.act . RepeatPolicy from wordle . policy import RepeatPolicy
policy = RepeatPolicy ( start_word_policy = None , first_n = 2 )Описание:
Случайно повторяет одно из уже используемых слов first_n . Это максимально неоптимальная политика, поскольку она никогда не сможет победить, если не повезет на первом словом.
Входные данные:
start_word_policy: Optional[Policy] - политика, которую можно использовать для выбора первого слова. Если None , то случайным образом выберите слово из словаря окружающей среды.first_n: Optional[int] - Политика случайным образом выбирает следующее слово из слов first_n в истории. Если None , то он выбирает случайным образом из полной истории. RandomMixturePolicy from wordle . policy import RandomMixturePolicy
policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )Описание:
Выбирает слово, полностью случайное, из списка слов с вероятностью (1 - prob_smart) и выбирает случайное слово из списка слов, который соответствует всем известным ограничениям букв с вероятностью prob_smart .
Входные данные:
prob_smart: float - вероятность выбора слова, которое соответствует всем известным ограничениям букв, а не в полном случайном.vocab: Optional[Union[str, Vocabulary]] - список слов, из которых можно выбрать. Если None , то политика по умолчанию в список слов среды. WrongPolicy from wordle . policy import WrongPolicy
from wordle . wordle_game import Vocabulary
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
policy = WrongPolicy ( vocab )Описание:
Случайно выбирает слово из списка слов, которое не соответствует всем известным ограничениям букв и, следовательно, не может быть правильным словом. Если все слова в списке слов соответствуют ограничениям буквы, то он выбирает слово случайным образом из списка. Эта политика очень неоптимальна.
Входные данные:
vocab: Union[str, Vocabulary] - список слов на выбор. MixturePolicy from wordle . policy import MixturePolicy , OptimalPolicy , RandomMixturePolicy
policy1 = OptimalPolicy ()
policy2 = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MixturePolicy ( prob1 = 0.5 , policy1 = policy1 , policy2 = policy2 )Описание:
Смешает две заданные политики. Выберите из policy1 с вероятностью prob1 и выберите из policy2 с вероятностью (1 - prob1) .
Входные данные:
prob1: float - вероятность выбора действия из policy1 .policy1: Policy - первая политика выбора действий из. Выбран с вероятностью prob1 .policy1: Policy - вторая политика выбора действий из. Выбран с вероятностью (1 - prob1) . MonteCarloPolicy from wordle . policy import MonteCarloPolicy
sample_policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MonteCarloPolicy ( n_samples = 5 , sample_policy = sample_policy )Описание:
Принимает политику, запускает n_samples OF DUPLOTS MONTE CARLO в окружающей среде и выбирает следующее действие, которое получило наибольшее среднее вознаграждение во время процесса развертывания.
Входные данные:
n_samples: int - количество развертываний Монте -Карло для выполнения.sample_policy: Policy - политика для выборочных развертываний. 
Любая из вышеперечисленных политик может использоваться для создания наборов данных, которые можно использовать для обучения автономных агентов RL. Мы реализуем в src/wordle/wordle_dataset.py , два вида синтетических наборов данных:
wordle.wordle_dataset.WordleListDataset - загружает Wordle Games из файла.wordle.wordle_dataset.WordleIterableDataset - образцы Wordle Games из данной политики.WordleListDataset :Загрузите набор данных Wordle из файла, как SO:
from wordle . wordle_dataset import WordleListDataset
from data . rl_data import ConstantTokenReward
data = WordleListDataset . from_file (
file_path = 'data/wordle/expert_wordle_100k.pkl' ,
max_len = None ,
vocab = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
for i in range ( data . size ()):
item = data . get_item ( i )__init__ def __init__ ( self , items : List [ Tuple [ WordleObservation , Optional [ Dict [ str , Any ]]]], max_len : Optional [ int ], token_reward : TokenReward ) -> NoneВходные данные:
items: List[Tuple[WordleObservation, Optional[Dict[str, Any]]]] - список данных в форме кортежей (Wordleobservation, metadata_dict). Там, где Metadata_dict - это какая -либо метаданные - это какие -либо метаданные, которые вы можете сохранить в данных.max_len: Optional[int] - максимальная длина последовательности в наборе данных, усекает все последовательности токенов на эту длину. Если None , то последовательности не будут усечены.token_reward: TokenReward -вознаграждение уровня токена, чтобы применить к последовательностям. Мы используем постоянное вознаграждение в размере 0 за ток для всех экспериментов. Возвращает: None
from_file def from_file ( cls , file_path : str , max_len : Optional [ int ], vocab : Optional [ Vocabulary ], token_reward : TokenReward ) -> WordleListDatasetВходные данные:
file_path: str - Путь к файлу Pickle Data.max_len: Optional[int] - максимальная длина последовательности в наборе данных, усекает все последовательности токенов на эту длину. Если None , то последовательности не будут усечены.vocab: Optional[Vocabulary] - моделируйте набор данных в другой словарный запас среды. Если None , по умолчанию использовать тот же словарный запас, который использовался для создания набора данных.token_reward: TokenReward -вознаграждение уровня токена, чтобы применить к последовательностям. Мы используем постоянное вознаграждение в размере 0 за ток для всех экспериментов. Возвращает: объект WordleListDataset .
get_item def get_item ( self , idx : int ) -> DataPointВходные данные:
idx: int - индекс в наборе данных. Возвращает: объект DataPoint .
size def size ( self ) -> intВозвращает: размер набора данных.
Следующие сценарии в scripts/data/wordle/ могут использоваться для синтеза данных Wordle.
| сценарий | описание |
|---|---|
generate_data.py | Образцы ряд игр из данной политики, указанной в конфигурации, и сохраняет их в файле. |
generate_data_mp.py | То же самое, что generate_data.py , за исключением образцов игр параллельно на нескольких процессах. |
generate_adversarial_data.py | Синтезирует набор данных, описанный в разделе 5 нашей статьи, который был разработан, чтобы продемонстрировать разницу между одноэтапными методами RL и многоэтапными. |
generate_adversarial_data_mp.py | Так же, как generate_adversarial_data.py , за исключением образцов игр параллельно на нескольких процессах. |
generate_data_branch.py | Образцы игр из данной «экспертной» политики, а затем от каждого действия в игре, «неоптимальной» политики отбирает выборку ряда новых игр. |
generate_data_branch_mp.py | То же самое, что generate_data_branch.py за исключением образцов игр параллельно на нескольких процессах. |
Некоторые предоставлены синтетические наборы данных Wordle в data/wordle/ .
| файл | описание |
|---|---|
expert_wordle_100k_1.pkl | 100 тыс. Игр, отобранных из OptimalPolicy . |
expert_wordle_100k_2.pkl | Еще 100 тысяч игр, отобранных из OptimalPolicy . |
expert_wordle_adversarial_20k.pkl | Набор данных, описанный в разделе 5 нашей статьи, которая была разработана для демонстрации разницы между одноэтапными методами RL и многоэтапными. |
expert_wordle_branch_100k.pkl | 100K игр, отобранные с использованием generate_data_branch.py от OptimalPolicy с ветвями, отобранными из WrongPolicy . |
expert_wordle_branch_150k.pkl | Еще в 150 тыс. Игр, отобранных с использованием generate_data_branch.py из OptimalPolicy с ветвями, отобранными из WrongPolicy . |
expert_wordle_branch_2k_10sub.pkl | 2K игр, отобранные с использованием generate_data_branch.py из OptimalPolicy с 10 ветвями на действие, отобранные из WrongPolicy , так что существует гораздо более неоптимальные данные, чем в expert_wordle_branch_100k.pkl . |
expert_wordle_branch_20k_10sub.pkl | То же самое, что expert_wordle_branch_2k_10sub.pkl , кроме 20 тыс. Игр вместо 2K. |
WordleIterableDataset :Создать выборку данных Wordle из политики, такой как SO:
from wordle . wordle_dataset import WordleIterableDataset
from wordle . policy import OptimalPolicy
from data . rl_data import ConstantTokenReward
policy = OptimalPolicy ()
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
data = WordleIterableDataset (
policy = policy ,
vocab = vocab ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
while True :
item = data . sample_item ()__init__ def __init__ ( self , policy : Policy , vocab : Vocabulary , max_len : Optional [ int ], token_reward : TokenReward ) -> NoneВходные данные:
policy: Policy - политика для выбора из.vocab: Vocabulary - словарный запас окружающей среды.max_len: Optional[int] - максимальная длина последовательности в наборе данных, усекает все последовательности токенов на эту длину. Если None , то последовательности не будут усечены.token_reward: TokenReward -вознаграждение уровня токена, чтобы применить к последовательностям. Мы используем постоянное вознаграждение в размере 0 за ток для всех экспериментов. Возвращает: None
sample_item def sample_item ( self ) -> DataPoint Возвращает: объект DataPoint .
У нас есть большой набор данных из более чем 200 тысяч твитов Wordle Games, например:
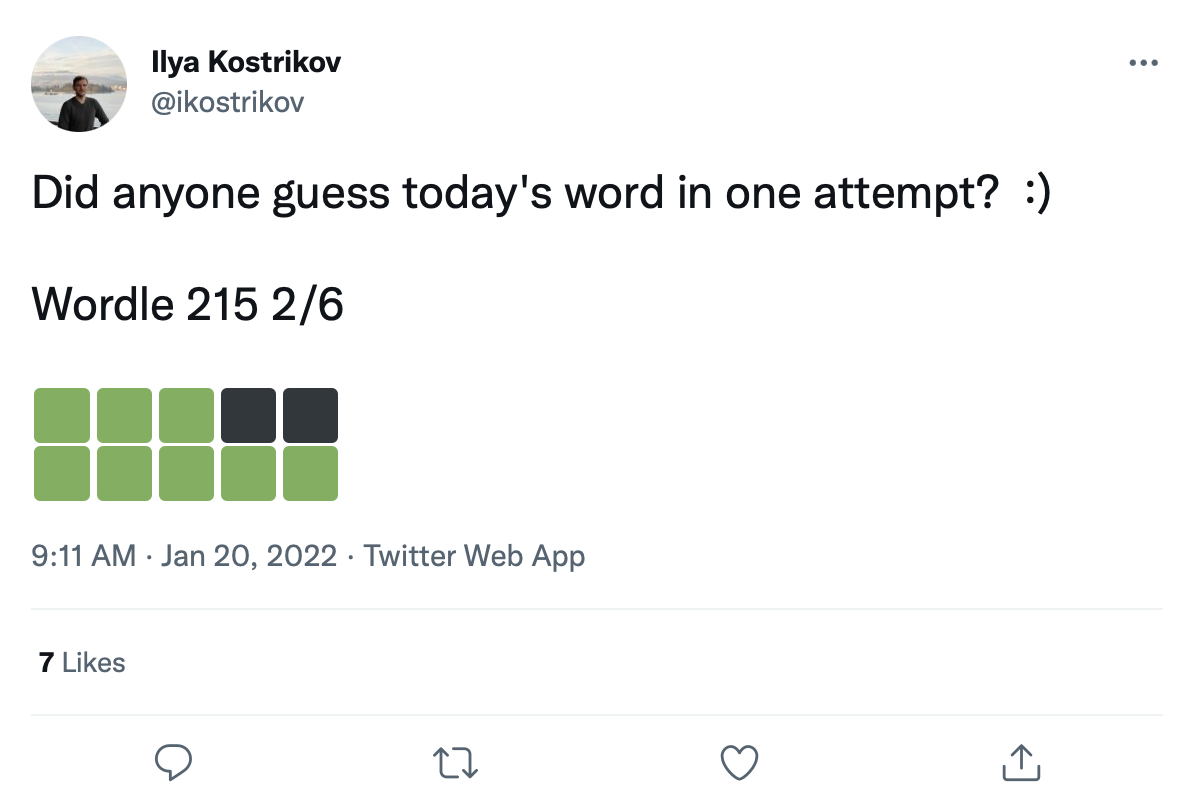
Мы можем модернизировать слова на эти квадраты перехода цвета, чтобы создать реальный набор данных Wordle Games.
Необработанные данные твита приведены в data/wordle/tweets.csv . Выполнение этого процесса переоборудования требует выполнения сценария предварительной обработки, который кэширует все возможные цветовые переходы, которые могут происходить в списках словаря: guess_vocab (набор догадных слов) и correct_vocab (набор возможных правильных слов в среде). Результатом является структура данных, которая wordle.wordle_dataset.WordleHumanDataset использует для синтеза действительных игр Wordle из твитов. Этот скрипт - scripts/data/wordle/build_human_datastructure.py . Позвоните в сценарий, как:
cd scripts/data/wordle/
python build_human_datastructure.py --guess_vocab=../../../data/wordle/word_lists/wordle_official.txt --correct_vocab=../../../data/wordle/word_lists/wordle_official.txt --tweets_file=../../../data/wordle/tweets.csv --output_file=../../../data/wordle/random_human_tweet_data.jsonСценарий ARGS:
--guess_vocab указывает набор угадательных слов.--correct_vocab определяет набор возможных правильных слов в среде.--tweets_file Указывает необработанный файл CSV твитов--output_file Указывает, где сбросить выход. Мы запустили предварительную обработку в некоторых списках слов, с результатами, сохраненными в data/wordle/ .
| Список слов | Предварительный файл данных твита |
|---|---|
wordle_official.txt | random_human_tweet_data.json |
wordle_official_800.txt | random_human_tweet_data_800.json |
wordle_official_400.txt | random_human_tweet_data_400.json |
wordle_official_200.txt | random_human_tweet_data_200.json |
tweet_words.txt | human_tweet_data_true_word.json |
Учитывая один из этих файлов, вы можете загрузить набор данных твитов Wordle, например:
from wordle . wordle_dataset import WordleHumanDataset
data = WordleHumanDataset . from_file ( 'data/wordle/random_human_tweet_data_200.json' )
print ( data . sample_item ()) Мы использовали 'data/wordle/random_human_tweet_data_200.json' в наших экспериментах.
WordleHumanDataset : __init__ def __init__ ( self , games : List [ Tuple [ str , List [ str ]]], transitions : Dict [ str , Dict [ str , List [ str ]]], use_true_word : bool , max_len : Optional [ int ], token_reward : TokenReward , game_indexes : Optional [ List [ int ]], top_p : Optional [ float ]) -> NoneВходные данные:
games: List[Tuple[str, List[str]]] - список кортежей формы (correct_wordle_word, wordle_transitions_list) , где wordle_transitions_list - это список переходов, указывающих цвета в твите, как: ["<b><b><y><y><b>", "<g><b><b><b><b>", "<g><g><y><b><b>", "<g><g><g><g><g>"] .transitions: Dict[str, Dict[str, List[str]]] - DICT, отображающий правильное слово WORLDE с другим отображением DICT возможные цветовые переходы, которые могли быть вызваны этим словом в список слов, которые можно было бы воспроизвести, чтобы вызвать этот переход. Эта структура данных используется для модернизации слов на твитах.use_true_word: bool -если True , используйте правильное слово с правильным словом из земли из твита, иначе модернизируйте любое правильное слово в списке слов, которое работает.max_len: Optional[int] - максимальная длина последовательности в наборе данных, усекает все последовательности токенов на эту длину. Если None , то последовательности не будут усечены.token_reward: TokenReward -вознаграждение уровня токена, чтобы применить к последовательностям. Мы используем постоянное вознаграждение в размере 0 за ток для всех экспериментов.game_indexes: Optional[List[int]] - список индексов для создания разделения твитов. Если None , все элементы в данных будут использоваться. У нас есть data/wordle/human_eval_idxs.json и data/wordle/human_train_idxs.json созданные в виде случайно выбранных поездов и рассеивания.top_p: Optional[float] - Фильтр для top_p , выполняющий процент данных. Если None , данные не будут отфильтрованы. Используется с %моделей BC. Возвращает: None
from_file def from_file ( cls , file_path : str , use_true_word : bool = False , max_len : Optional [ int ] = None , token_reward : Optional [ TokenReward ] = None , top_p : Optional [ float ] = None ) -> WordleHumanDatasetВходные данные:
file_path: str - Путь к файлу json для загрузки данных.use_true_word: bool -если True , используйте правильное слово с правильным словом из земли из твита, иначе модернизируйте любое правильное слово в списке слов, которое работает.max_len: Optional[int] - максимальная длина последовательности в наборе данных, усекает все последовательности токенов на эту длину. Если None , то последовательности не будут усечены.token_reward: TokenReward -вознаграждение уровня токена, чтобы применить к последовательностям. Мы используем постоянное вознаграждение в размере 0 за ток для всех экспериментов.game_indexes: Optional[List[int]] - список индексов для создания разделения твитов. Если None , все элементы в данных будут использоваться. У нас есть data/wordle/human_eval_idxs.json и data/wordle/human_train_idxs.json созданные в виде случайно выбранных поездов и рассеивания.top_p: Optional[float] - Фильтр для top_p , выполняющий процент данных. Если None , данные не будут отфильтрованы. Используется с %моделей BC. Возврат: объект WordleHumanDataset .
sample_item def sample_item ( self ) -> DataPoint Возвращает: объект DataPoint .
Обучающие сценарии находятся в scripts/train/wordle/ .
| сценарий | описание |
|---|---|
train_bc.py | Тренировать агент BC. |
train_iql.py | Обучить агент ILQL. |
Сценарии оценки находятся в scripts/eval/wordle/ .
| сценарий | описание |
|---|---|
eval_policy.py | Оцените агент BC или ILQL в среде Wordle. |
eval_q_rank.py | Сценарий оценки для сравнения относительного ранга Q значений для агентов, обученных на наборе синтетического данных, описанного в разделе 5 нашей статьи, которая была разработана для демонстрации разницы между одноэтапным RL и многоэтапным RL. |
distill_policy_eval.py | Отпечатает результат eval_policy.py с помощью столкновений ошибок. |
Здесь мы описываем, как загрузить данные о визуальном диалоге в нашу кодовую базу и как выполнить среду. См. Раздел «Настройка» выше для того, чтобы настроить удаленные компоненты среды визуального диалога. Объекты данных и среды автоматически загружаются менеджером Config Config, но если вы хотите обойти систему конфигурации и использовать среду с собственной кодовой базой, вот как вы должны загружать, выполнять и настроить эти объекты. Те же самые настройки, описанные ниже, также могут быть изменены и в конфигурации.
Пример того, как загрузить среду визуального диалога:
from visdial . visdial_env import VDEnvironment
from visdial . visdial_base import VisDialogueData
from visdial . visdial_dataset import VisDialListDataset
from data . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = VisDialogueData (
data_path = convert_path ( 'data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.json' ),
img_feat_path = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/data_img.h5' ),
split = 'train' ,
reward_cache = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/train_rank_reward_cache1.json' ),
yn_reward_kind = 'none'
)
list_data = VisDialListDataset (
data = data ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 )
)
env = VDEnvironment (
dataset = list_data ,
url = 'http://localhost:5000/step_rank' ,
yn_reward = - 2.0 ,
yn_reward_kind = 'none'
)
print ( env . reset ()) Приведенный выше скрипт соответствует тому, как мы настроили набор данных и среду для наших «стандартных» экспериментов по вознаграждению, но если вы хотите по -разному настроить набор данных, есть много аргументов, которые вы можете изменить. Помимо того, что просто изменение разделения набора данных эти аргументы также могут изменить задачу или вознаграждение. Ниже мы опишем все различные настраиваемые параметры, которые приобретают VisDialogueData , VisDialListDataset и VDEnvironment .
Мы документируем параметры и методы для VisDialogueData , VisDialListDataset и VDEnvironment , поэтому вы знаете, как самостоятельно настроить среду.
VisDialogueData : VisDialogueData , реализованная в src/visdial/visdial_base.py , хранит набор диалогов и вознаграждений задачи.
__init__ def __init__ ( self , data_path : str , img_feat_path : str , split : str , reward_cache : Optional [ str ] = None , norm_img_feats : bool = True , reward_shift : float = 0.0 , reward_scale : float = 1.0 , addition_scenes : Optional [ List [ Scene ]] = None , mode : str = 'env_stops' , cutoff_rule : Optional [ CutoffRule ] = None , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneВходные данные:
data_path: str - путь к данным диалога. Должен быть одним из:data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_val.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_test.jsonimg_feat_path: str - путь к функциям изображения, используемым для вычисления вознаграждения для каждого диалога. Всегда должны быть data/vis_dialogue/processed/visdial_0.5/data_img.h5 .split: str - один из train , val или test . Указывает, какой набор данных разделения функций изображения для использования. Должен соответствовать разделению data_path .reward_cache: Optional[str]=None - где хранятся награды за каждый диалог. Если None , это установит все награды ни на None . Мы предоставляем кэши для двух функций вознаграждения:data/vis_dialogue/processed/visdial_0.5/[split]_rank_reward_cache1.json , где [split] заменяется одним из train , val или test .data/vis_dialogue/processed/visdial_0.5/[split]_reward_cache2.json , где [split] заменяется одним из train , val или test .norm_img_feats: bool=True - будь то нормализовать функции изображения.reward_shift: float=0.0 - Сдвиньте вознаграждение на эту сумму.reward_scale: float=1.0 - масштабируйте вознаграждение на эту сумму.addition_scenes: Optional[List[Scene]]=None - введите дополнительные данные в набор данных.mode: str='env_stops' - один из ['agent_stops', 'env_stops', '10_stop'] . Контролирует некоторые свойства задачи. Мы используем env_stopsmode='env_stops' , затем остановите взаимодействие среды рано в соответствии с cutoff_rule .mode='agent_stops' , то агент прекращает взаимодействие, генерируя специальный токен <stop> во время его действия; Увеличивает данные, размещая <stop> после всех возможных действий.mode='10_stop' , игра всегда останавливается после 10 раундов взаимодействия, как и стандарт в наборе данных о визуальном диалоге.cutoff_rule: Optional[CutoffRule]=None - только применимо, если mode='env_stops' . Реализует функцию, которая определяет, когда среда должна остановить взаимодействие на ранней стадии. Мы используем дефолт visdial.visdial_base.PercentileCutoffRule(1.0, 0.5) во всех наших экспериментах.yn_reward: float=-2.0 -штраф за вознаграждение, которое следует добавить за задание вопросов «да/нет».yn_reward_kind: str='none' - указывает эвристику строки, которая будет использована для определения того, был ли вопрос «да/нет». Должен быть одним из ['none', 'soft', 'hard', 'conservative'] .'none' : не наказывайте «Да/нет вопросов». Это соответствует standard награде в нашей статье.'soft' : накажите вопрос, если ответ содержит "yes" или "no" в качестве подстроения.'hard' : наклейте вопрос, соответствует ли ответ, точно со стандартной строкой "yes" или "no" . Это соответствует вознаграждению "y/n" в нашей статье.'conservative' : накажите вопрос, удовлетворяет ли ответ один из нескольких эвристики, соответствующих строк, эвристика. Это соответствует вознаграждению "conservative y/n" в нашей статье. Возвращает: None
__len__ def __len__ ( self ) -> intВозвращает: размер набора данных.
__getitem__ def __getitem__ ( self , i : int ) -> SceneВходные данные:
i: int - индекс набора данных.Возвращает: элемент из набора данных.
VisDialListDataset : VisDialListDataset , реализованный в src/visdial/visdial_dataset.py , оборачивается вокруг VisDialogueData и преобразует его в формат DataPoint , который можно использовать для обучения автономных RL -агентов.
__init__ def __init__ ( self , data : VisDialogueData , max_len : Optional [ int ], token_reward : TokenReward , top_p : Optional [ float ] = None , bottom_p : Optional [ float ] = None ) -> NoneВходные данные:
data: VisDialogueData - объект данных визуального диалога, который хранит все необработанные данные.max_len: Optional[int] - максимальная длина последовательности в наборе данных, усекает все последовательности токенов на эту длину. Если None , то последовательности не будут усечены.token_reward: TokenReward -вознаграждение уровня токена, чтобы применить к последовательностям. Мы используем постоянное вознаграждение в размере 0 за ток для всех экспериментов.top_p: Optional[float] - Фильтр для top_p , выполняющий процент данных. Если None , данные не будут отфильтрованы. Используется с %моделей BC.bottom_p: Optional[float] - Фильтр для bottom_p , выполняющий процент данных. Если None , данные не будут отфильтрованы. Возвращает: None
size def size ( self ) -> intВозвращает: размер набора данных.
get_item def get_item ( self , idx : int ) -> DataPointВходные данные:
i: int - индекс набора данных. Возвращает: DataPoint из набора данных.
VDEnvironment : VDEnvironment , реализованный в src/visdial/visdial_env.py , определяет среду визуального диалога, с которой наши автономные агенты RL взаимодействуют во время оценки. Среда включает в себя подключение к серверу Localhost, который в разделе «Настройка» описывается, как вращаться.
__init__ def __init__ ( self , dataset : RL_Dataset , url : str , reward_shift : float = 0.0 , reward_scale : float = 1.0 , actor_stop : bool = False , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneВходные данные:
dataset: RL_Dataset - принимает RL_Dataset ; В частности, VisDialListDataset , как указано выше. Этот набор данных используется для выбора начальных состояний.url: str - URL для шага в окружающей среде. Следуйте инструкциям в разделе «Настройка», чтобы инициализировать WebServer Localhost, соответствующий этому URL.reward_shift: float=0.0 - Сдвиньте вознаграждение на эту сумму.reward_scale: float=1.0 - масштабируйте вознаграждение на эту сумму.actor_stop: bool=False - Позвольте актеру прекратить взаимодействие на раннем этапе, генерируя специальный токен <stop> .yn_reward: float=-2.0 -штраф за вознаграждение, которое следует добавить за задание вопросов «да/нет».yn_reward_kind: str='none' - указывает эвристику строки, которая будет использована для определения того, был ли вопрос «да/нет». Должен быть одним из ['none', 'soft', 'hard', 'conservative'] .'none' : не наказывайте «Да/нет вопросов». Это соответствует standard награде в нашей статье.'soft' : накажите вопрос, если ответ содержит "yes" или "no" в качестве подстроения.'hard' : наклейте вопрос, соответствует ли ответ, точно со стандартной строкой "yes" или "no" . Это соответствует вознаграждению "y/n" в нашей статье.'conservative' : накажите вопрос, удовлетворяет ли ответ один из нескольких эвристики, соответствующих строк, эвристика. Это соответствует вознаграждению "conservative y/n" в нашей статье. Возвращает: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Входные данные:
action: Vocabulary - словарь окружающей средыВозврат: (наблюдение, вознаграждение, терминал) кортеж.
reset def reset ( self ) -> WordleObservationВозврат: наблюдение
is_terminal def is_terminal ( self ) -> boolВозврат: логическое, указывающее, прекратилось ли взаимодействие.
Обучающие сценарии находятся в scripts/train/vis_dial/ .
| сценарий | описание |
|---|---|
train_bc.py | Тренировать агент BC. |
train_chai.py | Тренировать агент чая. |
train_cql.py | Обучить агент CQL. |
train_dt.py | Обучить агента трансформатора решений. |
train_iql.py | Обучить агент ILQL. |
train_psi.py | Тренировать |
train_utterance.py | Обучить агент ILQL на уровне высказывания. |
Сценарии оценки находятся в scripts/eval/vis_dial/ .
| сценарий | описание |
|---|---|
eval_policy.py | Оценить агента в среде визуального диалога. |
top_advantage.py | Находит вопросы, которые имеют наибольшее и наименьшее преимущество под моделью. |
distill_policy_eval.py | Отпечатает результат eval_policy.py с помощью столкновений ошибок. |
Here we outline how to load the Reddit comments data in our codebase and how to execute the environment. See the setup section above for how to setup the toxicity filter reward. The data and environment objects are loaded automatically by the config manager, but if you want to by-pass the config system and use the task with your own codebase, here's how you should load, execute, and configure these objects. The same settings described below can all be modified in the configs as well.
An example of how to load the Reddit comment environment:
from toxicity . toxicity_env import ToxicityEnvironment
from toxicity . reddit_comments_base import RedditData
from toxicity . reward_fs import toxicity_reward
from utils . misc import convert_path
idxs = json . load ( open ( convert_path ( 'data/reddit_comments/train_idxs.json' ), 'r' ))
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = idxs ,
reward_f = toxicity_reward
)
env = ToxicityEnvironment (
data = data ,
reward_f = toxicity_reward
)
print ( env . reset ())
The above script corresponds to how we configured the environment for our toxicity reward experiments, but if you want to configure the environment differently, there are a few arguments you can modify. These arguments can also change the task or reward. Below we describe all the different configurable parameters that our reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment take.
We document the parameters and methods for our different Reddit comment reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment , so that you know how to configure the environment yourself.
Here we outline the 4 main reward functions we use for our Reddit comment task. Each of these rewards is implemented in src/toxicity/reward_fs.py .
toxicity_reward from toxicity . reward_fs import toxicity_reward
reward_f = toxicity_reward ()Описание:
The "toxicity" reward from our paper, which queries the GPT-3 toxicity filter. It assigns a value of "0" to non-toxic comments, a value of "1" to moderately toxic comments, and a value of "2" to very toxic comments.
toxicity_noised_reward from toxicity . reward_fs import toxicity_noised_reward
reward_f = toxicity_noised_reward ()Описание:
The "noised toxicity" reward from our paper, which is the same as toxicity_noised_reward but induces additional noise. Specifically, it re-assigns comments labeled as "1" (moderately toxic) to either "0" (non-toxic) or "2" (extremely toxic) with equal probability.
score_human_reward from toxicity . reward_fs import score_human_reward
from utils . misc import convert_path
reward_f = score_human_reward (
reddit_path = convert_path ( 'data/reddit_comments/' ),
indexes = None
)Описание:
The "upvotes real" reward from our paper, which gives a reward of +1 for positive upvote comments and -1 for negative upvote comments. This uses the ground truth upvotes in the data, so it only applies to comments in the dataset and cannot be used for evaluation. If you input a string not present in the data, it will error. The arguments to this function specify what data to load.
Inputs:
reddit_path: str – a path to the data.indexes: List[int] – a split of indexes in the data to use. If None , it considers all the data. model_reward from toxicity . reward_fs import score_human_reward
from toxicity . reddit_comments_base import RedditData
from toxicity . toxicity_dataset import ToxicityListDataset
from toxicity . reward_model import RobertaBinaryRewardModel
from utils . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = None ,
reward_f = None
)
listdata = ToxicityListDataset (
data = data ,
max_len = 512 ,
token_reward = ConstantTokenReward ( 0.0 )
)
model = RobertaBinaryRewardModel (
data = listdata ,
device = 'cuda' ,
roberta_kind = 'roberta-base' ,
freeze_roberta = False ,
reward_cuttoff = 0.0
)
model . load_state_dict ( torch . load ( convert_path ( 'outputs/toxicity/upvote_reward/model.pkl' ), map_location = 'cpu' ))
reward_f = score_human_reward ( model = model )Описание:
The "upvotes model" reward from our paper, which gives a reward of +1 if the given model predicts that the comment will get a positive number of upvotes and a reward of -1 otherwise. The model checkpoint we used for our experiments is at: outputs/toxicity/upvote_reward/model.pkl
Inputs:
model: RewardModel : the reward model implemented in src/toxicity/reward_model.py . The model should be first trained and loaded from a pytorch checkpoint.RedditData : RedditData , implemented in src/toxicity/reddit_comments_base.py , stores the raw Reddit comments data.
__init__ def __init__ ( self , path : str , indexes : Optional [ List [ int ]], reward_f : Optional [ Callable [[ str ], float ]], reward_cache : Optional [ Cache ] = None , reward_shift : float = 0.0 , reward_scale : float = 1.0 ) -> NoneInputs:
path: str – the path to the Reddit data.indexes: Optional[List[int]] – a list of indexes to create a split of the data. Randomly selected, training, validation, and test splits are in the json files:data/reddit_comments/train_idxs.jsondata/reddit_comments/eval_idxs.jsondata/reddit_comments/test_idxs.jsonreward_f: Optional[Callable[[str], float]] – the reward function to use.reward_cache: Optional[Cache]=None – a cache of reward values, so you don't have to recompute them everytime.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount. Returns: None
__len__ def __len__ ( self ) -> intReturns: the size of the dataset.
__getitem__ def __getitem__ ( self , idx : int ) -> SceneInputs:
idx: int – the dataset index.Returns: an item from the dataset.
ToxicityListDataset : ToxicityListDataset , implemented in src/toxicity/toxicity_dataset.py , wraps around RedditData and converts it into a DataPoint format that can be used to train offline RL agents.
__init__ def __init__ ( self , data : RedditData , max_len : Optional [ int ], token_reward : TokenReward , cuttoff : Optional [ float ] = None , resample_timeout : float = 0.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – a Reddit comment data object that stores all the raw data.max_len: Optional[int] – the maximum sequence length in the dataset, will truncate all token sequences to this length. If None , then sequences will not be truncated.token_reward: TokenReward – the token-level reward to apply to the sequences. We use a constant reward of 0 per-token for all experiments.cuttoff: Optional[float]=None – filter out all comments from the dataset with reward less than cuttoff . If None , no data will be filtered. Used with %BC models.resample_timeout: float=0.0 – when cuttoff is not equal to None , comments are stochastically sampled iid from the dataset, like an iterable, even though the dataset has a list-type interface. It uniformly re-samples from the dataset until it finds a comment with a reward that satisfies the cuttoff. In the case of the "toxicity" reward, this re-sampling can cause rate-limit errors on the GPT-3 API, so we allow you to add a resample_timeout to fix this issue: a timeout of roughly 0.05 should fix rate-limit issues.include_parent: bool=True – whether to condition on the parent comment in the thread. If False , models will be trained to generate comments unconditionally. Returns: None
size def size ( self ) -> intReturns: the size of the dataset.
get_item def get_item ( self , idx : int ) -> DataPointInputs:
i: int – the dataset index. Returns: a DataPoint from the dataset.
ToxicityEnvironment : ToxicityEnvironment , implemented in src/toxicity/toxicity_env.py , defines the Reddit comment generation environment, which our offline RL agents interact with at evaluation time.
__init__ def __init__ ( self , data : RedditData , reward_f : Optional [ Callable [[ str ], float ]], reward_shift : float = 0.0 , reward_scale : float = 1.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – the dataset used to select initial state parent comments to condition on.reward_f: Optional[Callable[[str], float]] – the reward function to use.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount.include_parent: bool=True – specifies whether to condition on the previous comment or post in the Reddit thread. Returns: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Inputs:
action: Vocabulary – the environment's vocabularyReturns: an (observation, reward, terminal) tuple.
reset def reset ( self ) -> WordleObservationReturns: an observation
is_terminal def is_terminal ( self ) -> boolReturns: a boolean indicating if the interaction has terminated.
Training scripts are in scripts/train/toxicity/ .
| сценарий | описание |
|---|---|
train_bc.py | Train a BC agent. |
train_iql.py | Train an ILQL agent. |
train_upvote_reward.py | Train the upvote reward model. |
Evaluation scripts are in scripts/eval/toxicity/ .
| сценарий | описание |
|---|---|
eval_policy.py | Evaluate an agent in the Reddit comments environment. |
distill_policy_eval.py | Prints out the result of eval_policy.py with error bars. |
All tasks – Wordle, Visual Dialogue, Reddit – have a corresponding environment and dataset implemented in the codebase, as described above. And all offline RL algorithms in the codebase are trained, executed, and evaluated on one of these given environments and datasets.
You can similarly define your own tasks that can easily be run on all these offline RL algorithms. This codebase implements a simple set of RL environment abstractions that make it possible to define your own environments and datasets that can plug-and-play with any of the offline RL algorithms.
All of the core abstractions are defined in src/data/ . Here we outline what needs to be implemented in order to create your own tasks. For examples, see the implementations in src/wordle/ , src/vis_dial/ , and src/toxicity/ .
All tasks must implement subclasses of: Language_Observation and Language_Environment , which are in src/data/language_environment.py .
Language_Observation :This class represents the observations from the environment that will be input to your language model.
A Language_Observation must define the following two functions.
to_sequence def to_sequence ( self ) -> Tuple [ List [ str , Optional [ float ]], bool ]:Описание:
A function which converts the observation object into a standard format that can be input to the language model and used for training.
Возвращает:
__str__ def __str__ ( self ) -> str :Описание:
This is only used to print the observation to the terminal. It should convert the observation into some kind of string that is interpretable by a user.
Returns: a string.
Language_Environment :This class represents a gym-style environment for online interaction, which is only used for evaluation.
A Language_Environment must define the following three functions.
step def step ( self , action : str ) -> Tuple [ Language_Observation , float , bool ]:Описание:
Just like a standard gym environment, given an action in the form of a string, step the environment forward.
Returns: a tuple of (Language_Observation, reward, terminal).
reset def reset ( self ) -> Language_Observation :Описание:
This resets the environment to an initial state.
Returns: the corresponding initial Language_Observation
is_terminal def is_terminal ( self ) -> bool :Описание:
Outputs whether the environment has reached a terminal state.
Returns: a boolean indicating if the environment has reached a terminal state.
All tasks must implement subclasses of either List_RL_Dataset or Iterable_RL_Dataset or both, which are defined in src/data/rl_data.py .
List_RL_Dataset :This class represents a list dataset (or an indexable dataset of finite length) that can be used to train offline RL agents.
A List_RL_Dataset must define the following two functions.
get_item def get_item ( self , idx : int ) -> DataPointОписание:
This gets an item from the dataset at a given index.
Returns: a DataPoint object from the dataset.
size def size ( self ) -> intОписание:
Returns the size of the dataset.
Returns: the dataset's size.
Iterable_RL_Dataset :This class represents an iterable dataset (or a non-indexable dataset that stochastically samples datapoints iid) that can be used to train offline RL agents.
A Iterable_RL_Dataset must define the following function.
sample_item def sample_item ( self ) -> DataPointОписание:
Samples a datapoint from the dataset.
Returns: a DataPoint object from the dataset.


