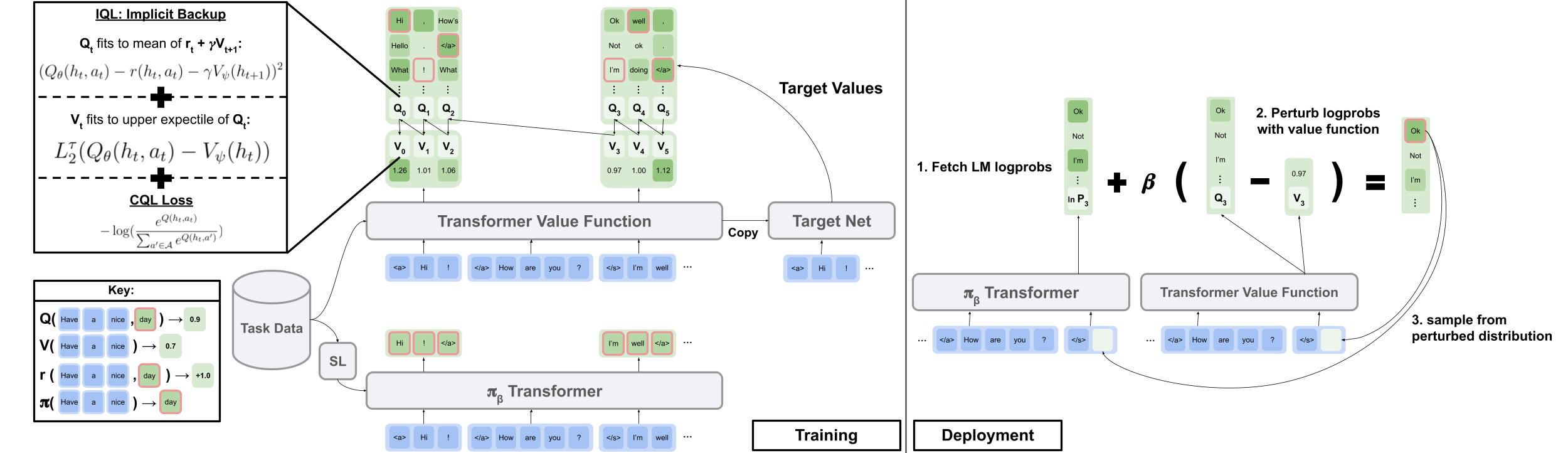
Implicit Language Q Learning
1.0.0
รหัสอย่างเป็นทางการจากกระดาษ "ออฟไลน์ RL สำหรับการสร้างภาษาธรรมชาติด้วยภาษาโดยปริยาย q การเรียนรู้"
เว็บไซต์โครงการ | arxiv
ดาวน์โหลด data.zip และ outputs.zip จากโฟลเดอร์ Google Drive ที่นี่ วางโฟลเดอร์ที่ดาวน์โหลดและคลายซิป data/ และ outputs/ ที่รูทของ repo data/ มีข้อมูลที่ประมวลผลล่วงหน้าสำหรับงานทั้งหมดของเราและ outputs/ มีจุดตรวจสอบสำหรับความคิดเห็นของเรา Reddit upvote รางวัล
repo นี้ออกแบบมาสำหรับ Python 3.9.7
pip install -r requirements.txt
export PYTHONPATH= " $PWD /src/ "ในการเรียกใช้การทดลองบทสนทนาแบบ Visual คุณต้องให้บริการสภาพแวดล้อมการสนทนาทางภาพบน LocalHost โดยทำตามคำแนะนำที่นี่
ในการเรียกใช้การทดลองความคิดเห็น Reddit ด้วยรางวัลตัวกรองความเป็นพิษ:
export OPENAI_API_KEY=your_API_key scripts/ มีสคริปต์การทดลองทั้งหมด เพื่อเรียกใช้สคริปต์ใด ๆ ใน scripts/ :
python script_name.pyไม่จำเป็น:
python script_name.py eval.bsize=5 train.lr=1e-6 wandb.use_wandb=falsepython -m torch.distributed.launch --nproc_per_node [N_GPUs] --use_env script_name.py arg1=a arg2=b โดยค่าเริ่มต้นบันทึกสคริปต์การฝึกอบรมทั้งหมดเป็น Wandb หากต้องการปิดสิ่งนี้ให้ตั้งค่า wandb.use_wandb=false ในการกำหนดค่าการฝึกอบรม
ที่นี่ฉันร่างเวิร์กโฟลว์ที่แนะนำสำหรับการฝึกอบรมตัวแทน RL ออฟไลน์ สมมติว่าฉันต้องการฝึกอบรมตัวแทน RL ออฟไลน์ที่แตกต่างกันเพื่อสร้างความคิดเห็น Reddit ด้วยรางวัลความเป็นพิษ
ก่อนอื่นฉันจะฝึกอบรมรุ่น BC บนข้อมูล:
cd scripts/train/toxicity/
python train_bc.pyจากนั้นแปลงจุดตรวจ BC นี้เป็นหนึ่งเดียวที่เข้ากันได้กับรุ่น RL ออฟไลน์:
cd ../data/
python convert_bc.py --load ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model.pkl --save ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model_converted.pklจากนั้นแก้ไขจุดตรวจสอบว่าออฟไลน์ RL ได้รับการกำหนดค่าให้ฝึกอบรมด้วย:
cd ../train/
python train_iql.py model.load.checkpoint_path=outputs/toxicity/model_converted.pkl model.load.strict_load=false train.loss.awac_weight=0.0 นี่เป็นเพียงเวิร์กโฟลว์เดียวคุณยังสามารถฝึกอบรมรุ่น BC ในเวลาเดียวกันกับตัวแทนออฟไลน์ RL โดยการตั้งค่า train.loss.awac_weight=1.0 ในการกำหนดค่าการฝึกอบรม
data/ โฟลเดอร์scripts/ มีสคริปต์ทั้งหมดสำหรับการฝึกอบรมการประเมินผลและขั้นตอนการประมวลผลข้อมูลล่วงหน้าในกระดาษ สคริปต์ถูกจัดระเบียบเป็นโฟลเดอร์ย่อยที่สอดคล้องกับชุดข้อมูลที่ใช้config/ contains .yaml configs สำหรับแต่ละสคริปต์ repo นี้ใช้ไฮดราเพื่อจัดการการกำหนดค่า การกำหนดค่าถูกจัดระเบียบเป็นโฟลเดอร์ย่อยที่สอดคล้องกับชุดข้อมูลที่ใช้ ไฟล์กำหนดค่าส่วนใหญ่มีชื่อเหมือนกับสคริปต์ที่สอดคล้องกัน แต่ถ้าคุณไม่แน่ใจว่าการกำหนดค่าใดสอดคล้องกับสคริปต์ให้ตรวจสอบบรรทัด @hydra.main(config_path="some_path", config_name="some_name") เพื่อดูไฟล์กำหนดไฟล์สคริปต์ที่สอดคล้องกับsrc/ มีการใช้งานหลักทั้งหมด ดู src/models/ สำหรับการใช้งานโมเดลทั้งหมด ดู src/data/ สำหรับการประมวลผลข้อมูลพื้นฐานทั้งหมดและรหัสนามธรรม MDP ดู src/utils/ สำหรับฟังก์ชั่นยูทิลิตี้ต่างๆ ดู src/wordle/ , src/visdial และ src/toxicity/ สำหรับทั้งหมด Wordle, Dialogue ภาพและชุดข้อมูลความคิดเห็น Reddit ทั้งหมดตามลำดับILQL เรียกว่า iql ตลอดการซื้อคืน แต่ละสคริปต์เชื่อมโยงกับไฟล์กำหนดค่า ไฟล์กำหนดค่าระบุว่าโมเดลชุดข้อมูลและตัวประเมินจะถูกโหลดโดยสคริปต์และไฮเปอร์พารามิเตอร์ที่สอดคล้องกัน ดู configs/toxicity/train_iql.yaml สำหรับตัวอย่าง
แต่ละโมเดลที่เป็นไปได้ชุดข้อมูลหรือวัตถุผู้ประเมินจะได้รับไฟล์กำหนดค่าของตัวเองซึ่งระบุค่าเริ่มต้นสำหรับวัตถุนั้นและแอตทริบิวต์ name พิเศษซึ่งจะบอกตัวจัดการการกำหนดค่าว่าคลาสจะโหลด ดู configs/toxicity/model/per_token_iql.yaml สำหรับตัวอย่าง
ไฟล์ src/load_objects.py , src/wordle/load_objects.py , src/visdial/load_objects.py และ src/toxicity/load_objects.py กำหนดวิธีการโหลดวัตถุแต่ละชิ้นจากการกำหนดค่าที่สอดคล้องกัน แท็ก @register('name') ด้านบนแต่ละฟังก์ชั่นโหลดวัตถุลิงก์ไปยังแอตทริบิวต์ name ในการกำหนดค่า
คุณอาจสังเกตเห็นแอตทริบิวต์ cache_id พิเศษที่เกี่ยวข้องกับวัตถุบางอย่างในการกำหนดค่า ตัวอย่างเช่นดู train_dataset ใน configs/toxicity/train_iql.yaml แอตทริบิวต์นี้บอกให้ตัวจัดการการกำหนดค่าแคชวัตถุแรกที่โหลดที่เชื่อมโยงกับ ID นี้จากนั้นเพื่อส่งคืนวัตถุที่แคชนี้สำหรับการกำหนดค่าวัตถุที่ตามมาด้วย cache_id นี้
สำหรับการกำหนดค่าทั้งหมดให้ใช้เส้นทางที่สัมพันธ์กับรูท repo
งานแต่ละอย่างใน Repo - Wordle, Visual Dialogue และ Reddit ความคิดเห็น - ใช้คลาสพื้นฐานสองสามข้อ เมื่อนำไปใช้แล้วอัลกอริทึม RL ออฟไลน์ทั้งหมดสามารถนำไปใช้กับงานในรูปแบบของปลั๊กแอนด์เพลย์ ดูส่วน "การสร้างงานของคุณเอง" สำหรับภาพรวมของสิ่งที่ควรนำไปใช้เพื่อสร้างงานของคุณเอง ด้านล่างเราร่างสิ่งที่เป็นนามธรรมที่สำคัญซึ่งทำให้สิ่งนี้เป็นไปได้
data.language_environment.Language_Environment - แสดงถึงสภาพแวดล้อมของงาน pomdp ซึ่งนโยบายสามารถโต้ตอบกับ มันมีอินเทอร์เฟซเหมือนโรงยิมdata.language_environment.Policy - แสดงถึงนโยบายที่สามารถโต้ตอบกับสภาพแวดล้อมได้ อัลกอริทึม RL ออฟไลน์แต่ละตัวใน src/models/ มีนโยบายที่สอดคล้องกันdata.language_environment.Language_Observation - แสดงถึงการสังเกตข้อความที่ส่งคืนโดยสภาพแวดล้อมและให้เป็นอินพุตไปยังนโยบายdata.language_environment.interact_environment - ฟังก์ชั่นที่ใช้ในสภาพแวดล้อมนโยบายและทางเลือกการสังเกตในปัจจุบันและเรียกใช้การโต้ตอบกับสภาพแวดล้อม หากการสังเกตในปัจจุบันไม่ได้ให้ข้อมูลจะดึงสถานะเริ่มต้นโดยอัตโนมัติโดยการรีเซ็ตสภาพแวดล้อมdata.rl_data.DataPoint - กำหนดรูปแบบข้อมูลมาตรฐานที่ป้อนเป็นอินพุตไปยังตัวแทน RL ออฟไลน์ทั้งหมดในงานทั้งหมด โครงสร้างข้อมูลเหล่านี้ถูกสร้างขึ้นโดยอัตโนมัติจาก Language_Observation ที่กำหนดdata.rl_data.TokenReward - กำหนดฟังก์ชั่นรางวัลที่ให้ไว้ในโทเค็นทุกตัวซึ่งสามารถใช้สำหรับการเรียนรู้การควบคุมที่ละเอียดยิ่งขึ้น สิ่งนี้มีให้ไว้ในรางวัลด้านสิ่งแวดล้อมซึ่งไม่ได้มาจากโทเค็นทุกครั้ง แต่หลังจากการโต้ตอบแต่ละครั้ง ในการทดลองทั้งหมดของเราเรากำหนดรางวัลนี้เป็นค่าคงที่ 0 ซึ่งไม่มีผลdata.tokenizer.Tokenizer - ระบุวิธีการแปลงสตริงเป็นและจากลำดับของโทเค็นซึ่งสามารถป้อนเป็นอินพุตเป็นแบบจำลองภาษาdata.rl_data.RL_Dataset - กำหนดวัตถุชุดข้อมูลซึ่งส่งคืนวัตถุ DataPoint และใช้สำหรับการฝึกอบรมตัวแทนออฟไลน์ RL RL_Dataset มีสองเวอร์ชัน:List_RL_DatasetIterable_RL_Dataset
ที่นี่เราร่างและจัดทำเอกสารส่วนประกอบทั้งหมดของงาน Wordle ของเรา
สิ่งที่อยู่ในสคริปต์ตัวอย่างส่วนใหญ่ทำโดยอัตโนมัติโดยตัวจัดการการกำหนดค่าและพารามิเตอร์ที่เกี่ยวข้องสามารถแก้ไขได้โดยการเปลี่ยนการกำหนดค่า แต่ถ้าคุณต้องการบายพาสโดยใช้การกำหนดค่าและใช้งาน Wordle กับ codebase ของคุณเองคุณสามารถอ้างอิงสคริปต์และเอกสารด้านล่างสำหรับวิธีการทำเช่นนี้
สคริปต์ตัวอย่างง่ายๆสำหรับการเล่น Wordle ใน Commandline
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from wordle . policy import UserPolicy
from data . language_environment import interact_environment
from utils . misc import convert_path
game_vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( game_vocab )
policy = UserPolicy ()
interact_environment ( env , policy )src/wordle/wordle_game.pysrc/wordle/wordle_env.pysrc/wordle/policy.pysrc/wordle/wordle_dataset.pyเพื่อให้เกมเป็น MDP ที่ถูกต้องสภาพแวดล้อมแสดงถึงสถานะพื้นฐานเป็นชุดของข้อ จำกัด ตัวอักษรที่รู้จักและใช้สิ่งเหล่านี้เพื่อกรองคำศัพท์สำหรับคำที่ตรงตามข้อ จำกัด เหล่านี้ทั้งหมดในแต่ละเทิร์น คำสุ่มจะถูกเลือกจากรายการคำที่กรองนี้และใช้เพื่อกำหนดการเปลี่ยนสีที่ส่งคืนโดยสภาพแวดล้อม การเปลี่ยนสีใหม่เหล่านี้จะอัปเดตชุดของข้อ จำกัด ตัวอักษรที่รู้จัก
สภาพแวดล้อม Wordle ใช้ในรายการคำ รายการคำสองสามรายการจะได้รับใน data/wordle/word_lists/ แต่อย่าลังเลที่จะทำเอง
รายการคำที่รวมอยู่ใน:
รายการคำจะถูกโหลดเข้าสู่สภาพแวดล้อมผ่านวัตถุ Vocabulary ดังในตัวอย่างข้างต้น
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))คำศัพท์ไม่เพียง แต่เก็บรายการคำ แต่ยังติดตามรายการคำที่กรองซึ่งตรงกับข้อ จำกัด จดหมายที่รู้จักทั้งหมดในสถานะที่กำหนด รายการนี้ใช้ในการคำนวณการเปลี่ยนแปลงในสภาพแวดล้อมและใช้โดยนโยบายที่สร้างขึ้นด้วยมือ
การผลิตรายการที่ผ่านการกรองเหล่านี้แบบเรียลไทม์สามารถชะลอกระบวนการปฏิสัมพันธ์กับสภาพแวดล้อม โดยปกติแล้วจะไม่เป็นปัญหา แต่ถ้าคุณต้องการสังเคราะห์ข้อมูลจำนวนมากจากนโยบายอย่างรวดเร็วสิ่งนี้อาจกลายเป็นคอขวด เพื่อเอาชนะสิ่งนี้วัตถุ Vocabulary ทั้งหมดเก็บอาร์กิวเมนต์ cache ซึ่งแคชรายการคำที่กรองเหล่านี้เกี่ยวข้องกับสถานะที่กำหนด vocab.cache.load(f_path) และ vocab.cache.dump() เปิดใช้งานการโหลดและบันทึกแคชนี้ ตัวอย่างเช่น data/wordle/vocab_cache_wordle_official.pkl เป็นแคชขนาดใหญ่สำหรับรายการคำ Wordle_official.txt
นอกเหนือจากการจัดเก็บแคชวัตถุ Vocabulary ใช้วิธีการต่อไปนี้ใน src/wordle/wordle_game.py :
__init__ def __init__ ( self , all_vocab : List [ str ],
wordle_state : Optional [ WordleState ],
cache : Optional [ Cache ] = None ,
fill_cache : bool = True ) -> Noneอินพุต:
all_vocab: List[str] - รายการคำwordle_state: Optional[WordleState] - สถานะที่จะสร้างรายการคำที่กรองหากไม่มีสถานะจะไม่มีการกรองคำcache: Optional[Cache]=None - แคชสำหรับคำศัพท์ที่กรองตามที่อธิบายไว้ข้างต้นfill_cache: bool=True - ไม่ว่าจะเพิ่มลงในแคช ผลตอบแทน: None
from_file def from_file ( cls , vocab_file : str , fill_cache : bool = True ) -> Vocabularyอินพุต:
vocab_file: str - ไฟล์ที่จะโหลดคำ วิธีการเลือกคำที่มีความยาว 5 ตัวอักษรเท่านั้นfill_cache: bool=True - ไม่ว่าจะเพิ่มลงในแคช ผลตอบแทน: Vocabulary
filtered_vocab_size def filtered_vocab_size ( self ) -> intReturns: ขนาดของคำศัพท์ที่กรอง
all_vocab_size def all_vocab_size ( self ) -> intReturns: ขนาดของคำศัพท์ที่ไม่มีการกรองเต็มรูปแบบ
get_random_word_filtered def get_random_word_filtered ( self ) -> strReturns: คำสุ่มจากรายการกรอง
get_random_word_all def get_random_word_all ( self ) -> strReturns: คำสุ่มจากรายการที่ไม่มีการกรองเต็มรูปแบบ
update_vocab def update_vocab ( self , wordle_state : WordleState ) -> Vocabularyอินพุต:
wordle_state: WordleState - วัตถุสถานะ Wordle ซึ่งเป็นตัวแทนของชุดของข้อ จำกัด ตัวอักษรที่รู้จัก Returns: วัตถุ Vocabulary ใหม่ซึ่งถูกกรองตาม wordle_state
__str__ def __str__ ( self ) -> strผลตอบแทน: การแสดงสตริงของรายการคำที่กรองสำหรับการพิมพ์ไปยังเทอร์มินัล
WordleEnvironment ใช้วัตถุคำศัพท์เป็นอินพุตซึ่งกำหนดชุดของคำที่ถูกต้องที่เป็นไปได้ในสภาพแวดล้อม
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( vocab )
initial_obs = env . reset ()
next_obs , reward , terminal = env . step ( "snake" ) ดังที่แสดงไว้ข้างต้นสภาพแวดล้อมใช้อินเทอร์เฟซเหมือนโรงยิมใน src/wordle/wordle_env.py :
__init__ def __init__ ( self , vocab : Vocabulary ) -> Noneอินพุต:
vocab: Vocabulary - คำศัพท์ของสิ่งแวดล้อม ผลตอบแทน: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]อินพุต:
action: Vocabulary - สตริงข้อความที่แสดงถึงการกระทำของตัวแทนในสภาพแวดล้อมผลตอบแทน: (การสังเกต, รางวัล, เทอร์มินัล) tuple
reset def reset ( self ) -> WordleObservationผลตอบแทน: การสังเกต
is_terminal def is_terminal ( self ) -> boolผลตอบแทน: บูลีนที่ระบุว่าการโต้ตอบสิ้นสุดลงหรือไม่
เราใช้ชุดนโยบาย Wordle ที่สร้างขึ้นด้วยมือซึ่งครอบคลุมระดับการเล่นเกมที่หลากหลาย ทั้งหมดนี้ถูกนำไปใช้ใน src/wordle/policy.py ที่นี่เราอธิบายแต่ละคน:
UserPolicy from wordle . policy import UserPolicy
policy = UserPolicy ( hint_policy = None , vocab = None )คำอธิบาย:
มาเล่นในเทอร์มินัลกันเถอะ
อินพุต:
hint_policy: Optional[Policy] - นโยบายอื่นในการสอบถามหากคุณต้องการคำใบ้ว่าจะใช้คำใดvocab: Optional[Union[str, Vocabulary]] - Vocabulary ของคำที่คาดเดาได้ หากไม่ได้ระบุลำดับตัวอักษร 5 ตัวของตัวอักษรใด ๆ ก็เป็นการคาดเดาที่ถูกต้อง StartWordPolicy from wordle . policy import StartWordPolicy
policy = StartWordPolicy ()คำอธิบาย:
ที่จะนำไปใช้สำหรับคำแรกเท่านั้น เลือกคำแบบสุ่มจากรายการคำเริ่มต้นที่มีคุณภาพสูง
อินพุต:
start_words: Optional[List[str]]=None - แทนที่รายการคำศัพท์ที่คัดสรรแล้ว OptimalPolicy from wordle . policy import OptimalPolicy
policy = OptimalPolicy ()คำอธิบาย:
Myopically เล่นข้อมูลสูงสุดได้รับคำจากรายการคำที่ตรงกับข้อ จำกัด จดหมายที่รู้จักทั้งหมด นโยบายนี้ไม่ได้ดีที่สุดเนื่องจากการเล่นที่ดีที่สุดคือ NP-Hard แต่มันเล่นในระดับที่สูงมากและสามารถใช้เป็นขอบเขตบนโดยประมาณสำหรับประสิทธิภาพ นโยบายนี้ช้ามากในการคำนวณโดยมีประสิทธิภาพกำลังสองในขนาดของรายการคำ หากต้องการบันทึกการคำนวณ self.cache.load(f_path) และ self.cache.dump() ช่วยให้คุณโหลดและบันทึกแคช ตัวอย่างเช่น data/wordle/optimal_policy_cache_wordle_official.pkl แสดงถึงแคชสำหรับนโยบายนี้ในรายการคำ wordle_official.txt
อินพุต:
start_word_policy: Optional[Policy]=None - เนื่องจากคำแรกโดยทั่วไปจะมีราคาแพงที่สุดในการคำนวณข้อมูลที่ได้รับสิ่งนี้ช่วยให้คุณสามารถระบุนโยบายที่แตกต่างกันที่จะเรียกใช้เป็นเพียงคำแรกprogress_bar: bool=False - เนื่องจากอาจใช้เวลานานมากในการคำนวณเราจึงปล่อยให้คุณมีตัวเลือกในการแสดงแถบความคืบหน้าสำหรับการโทรแต่ละครั้งเพื่อ self.act RepeatPolicy from wordle . policy import RepeatPolicy
policy = RepeatPolicy ( start_word_policy = None , first_n = 2 )คำอธิบาย:
สุ่มทำซ้ำหนึ่งในคำ first_n ที่ใช้แล้ว นี่เป็นนโยบายที่ไม่เหมาะสมที่สุดเนื่องจากมันไม่สามารถชนะได้เว้นแต่จะโชคดีในคำแรก
อินพุต:
start_word_policy: Optional[Policy] - นโยบายที่จะใช้สำหรับการเลือกคำแรก หาก None ให้เลือกคำจากคำศัพท์ของสภาพแวดล้อมแบบสุ่มfirst_n: Optional[int] - นโยบายสุ่มเลือกคำถัดไปจากคำ first_n ในประวัติศาสตร์ ถ้า None มันจะเลือกแบบสุ่มจากประวัติเต็ม RandomMixturePolicy from wordle . policy import RandomMixturePolicy
policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )คำอธิบาย:
เลือกคำอย่างเต็มที่โดยสุ่มจากรายการคำที่มีความน่าจะเป็น (1 - prob_smart) และเลือกคำสุ่มจากรายการคำที่ตรงกับข้อ จำกัด ตัวอักษรที่รู้จักทั้งหมดด้วยความน่าจะเป็น prob_smart
อินพุต:
prob_smart: float - ความน่าจะเป็นในการเลือกคำที่ตรงกับข้อ จำกัด ตัวอักษรที่รู้จักทั้งหมดแทนที่จะเป็นหนึ่งแบบสุ่มvocab: Optional[Union[str, Vocabulary]] - รายการคำที่เลือกจาก ถ้า None นโยบายจะเริ่มต้นในรายการคำของสภาพแวดล้อม WrongPolicy from wordle . policy import WrongPolicy
from wordle . wordle_game import Vocabulary
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
policy = WrongPolicy ( vocab )คำอธิบาย:
สุ่มเลือกคำจากรายการคำที่ล้มเหลวในการปฏิบัติตามข้อ จำกัด จดหมายที่รู้จักทั้งหมดและไม่สามารถเป็นคำที่ถูกต้องได้ หากคำทั้งหมดในรายการคำตรงตามข้อ จำกัด ของตัวอักษรมันจะเลือกคำที่สุ่มจากรายการ นโยบายนี้เป็นสิ่งที่ไม่เหมาะสมอย่างมาก
อินพุต:
vocab: Union[str, Vocabulary] - รายการคำที่ให้เลือก MixturePolicy from wordle . policy import MixturePolicy , OptimalPolicy , RandomMixturePolicy
policy1 = OptimalPolicy ()
policy2 = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MixturePolicy ( prob1 = 0.5 , policy1 = policy1 , policy2 = policy2 )คำอธิบาย:
ผสมผสานสองนโยบายที่กำหนด เลือกจาก policy1 ด้วยความน่าจะเป็น prob1 และเลือกจาก policy2 ที่มีความน่าจะเป็น (1 - prob1)
อินพุต:
prob1: float - ความน่าจะเป็นในการเลือกการกระทำจาก policy1policy1: Policy - นโยบายแรกในการเลือกการกระทำจาก เลือกด้วยความน่าจะเป็น prob1policy1: Policy - นโยบายที่สองในการเลือกการกระทำจาก เลือกด้วยความน่าจะเป็น (1 - prob1) MonteCarloPolicy from wordle . policy import MonteCarloPolicy
sample_policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MonteCarloPolicy ( n_samples = 5 , sample_policy = sample_policy )คำอธิบาย:
ใช้นโยบายดำเนินการ n_samples ของ Monte Carlo Rollout ในสภาพแวดล้อมและเลือกการดำเนินการต่อไปซึ่งได้รับรางวัลเฉลี่ยสูงสุดในระหว่างกระบวนการเปิดตัว
อินพุต:
n_samples: int - จำนวน Monte Carlo Rollout เพื่อดำเนินการsample_policy: Policy - นโยบายสำหรับตัวอย่างการเปิดตัวจาก 
นโยบายใด ๆ ข้างต้นสามารถใช้ในการสร้างชุดข้อมูลซึ่งสามารถใช้ในการฝึกอบรมตัวแทน RL ออฟไลน์ เรานำไปใช้ใน src/wordle/wordle_dataset.py , ชุดข้อมูลสังเคราะห์สองประเภท:
wordle.wordle_dataset.WordleListDataset - โหลดเกม Wordle จากไฟล์wordle.wordle_dataset.WordleIterableDataset - ตัวอย่างเกม Wordle จากนโยบายที่กำหนดWordleListDataset :โหลดชุดข้อมูล Wordle จากไฟล์เช่น So:
from wordle . wordle_dataset import WordleListDataset
from data . rl_data import ConstantTokenReward
data = WordleListDataset . from_file (
file_path = 'data/wordle/expert_wordle_100k.pkl' ,
max_len = None ,
vocab = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
for i in range ( data . size ()):
item = data . get_item ( i )__init__ def __init__ ( self , items : List [ Tuple [ WordleObservation , Optional [ Dict [ str , Any ]]]], max_len : Optional [ int ], token_reward : TokenReward ) -> Noneอินพุต:
items: List[Tuple[WordleObservation, Optional[Dict[str, Any]]]] - รายการข้อมูลในรูปแบบของ tuples ของ (wordleobservation, metadata_dict) ที่ metadata_dict เป็นข้อมูลเมตาใด ๆ เป็นข้อมูลเมตาประเภทใดก็ตามที่คุณอาจต้องการจัดเก็บใน datapointmax_len: Optional[int] - ความยาวลำดับสูงสุดในชุดข้อมูลจะตัดทอนลำดับโทเค็นทั้งหมดให้ยาว หาก None ลำดับจะไม่ถูกตัดทอนtoken_reward: TokenReward รางวัลระดับโทเค็นเพื่อนำไปใช้กับลำดับ เราใช้รางวัลคงที่ 0 ต่อการทดลองสำหรับการทดลองทั้งหมด ผลตอบแทน: None
from_file def from_file ( cls , file_path : str , max_len : Optional [ int ], vocab : Optional [ Vocabulary ], token_reward : TokenReward ) -> WordleListDatasetอินพุต:
file_path: str - เส้นทางไปยังไฟล์ Data Picklemax_len: Optional[int] - ความยาวลำดับสูงสุดในชุดข้อมูลจะตัดทอนลำดับโทเค็นทั้งหมดให้เป็นความยาวนี้ หาก None ลำดับจะไม่ถูกตัดทอนvocab: Optional[Vocabulary] - จำลองชุดข้อมูลภายใต้คำศัพท์สภาพแวดล้อมที่แตกต่างกัน หาก None เริ่มต้นในการใช้คำศัพท์เดียวกันกับที่ใช้ในการสร้างชุดข้อมูลtoken_reward: TokenReward รางวัลระดับโทเค็นเพื่อนำไปใช้กับลำดับ เราใช้รางวัลคงที่ 0 ต่อการทดลองสำหรับการทดลองทั้งหมด ผลตอบแทน: วัตถุ WordleListDataset
get_item def get_item ( self , idx : int ) -> DataPointอินพุต:
idx: int - ดัชนีในชุดข้อมูล ส่งคืน: วัตถุ DataPoint
size def size ( self ) -> intผลตอบแทน: ขนาดของชุดข้อมูล
สคริปต์ต่อไปนี้ใน scripts/data/wordle/ สามารถใช้เพื่อสังเคราะห์ข้อมูล Wordle
| สคริปต์ | คำอธิบาย |
|---|---|
generate_data.py | ตัวอย่างเกมจำนวนหนึ่งจากนโยบายที่ระบุไว้ในการกำหนดค่าและบันทึกไว้ในไฟล์ |
generate_data_mp.py | เช่นเดียวกับ generate_data.py ยกเว้นเกมตัวอย่างขนานกันในหลายกระบวนการ |
generate_adversarial_data.py | สังเคราะห์ชุดข้อมูลที่อธิบายไว้ในส่วนที่ 5 ของกระดาษของเราซึ่งออกแบบมาเพื่อแสดงให้เห็นถึงความแตกต่างระหว่างวิธี RL ขั้นตอนเดียวและแบบหลายขั้นตอน |
generate_adversarial_data_mp.py | เช่นเดียวกับ generate_adversarial_data.py ยกเว้นเกมตัวอย่างที่ขนานกันในหลายกระบวนการ |
generate_data_branch.py | เกมตัวอย่างจากนโยบาย "ผู้เชี่ยวชาญ" ที่กำหนดจากนั้นจากการกระทำแต่ละครั้งในเกมนโยบาย "suboptimal" จะแยกการสุ่มตัวอย่างเกมใหม่จำนวนหนึ่ง |
generate_data_branch_mp.py | เช่นเดียวกับ generate_data_branch.py ยกเว้นเกมตัวอย่างที่ขนานกับหลายกระบวนการ |
ชุดข้อมูล Wordle สังเคราะห์อยู่ใน data/wordle/
| ไฟล์ | คำอธิบาย |
|---|---|
expert_wordle_100k_1.pkl | เกม 100K ตัวอย่างจาก OptimalPolicy |
expert_wordle_100k_2.pkl | อีกเกม 100K ตัวอย่างจาก OptimalPolicy |
expert_wordle_adversarial_20k.pkl | ชุดข้อมูลที่อธิบายไว้ในส่วนที่ 5 ของกระดาษของเราซึ่งออกแบบมาเพื่อแสดงให้เห็นถึงความแตกต่างระหว่างวิธี RL ขั้นตอนเดียวและแบบหลายขั้นตอน |
expert_wordle_branch_100k.pkl | เกม 100K ตัวอย่างโดยใช้ generate_data_branch.py จาก OptimalPolicy กับสาขาที่สุ่มตัวอย่างจาก WrongPolicy |
expert_wordle_branch_150k.pkl | อีกเกม 150k ที่สุ่มตัวอย่างโดยใช้ generate_data_branch.py จาก OptimalPolicy กับสาขาที่สุ่มตัวอย่างจาก WrongPolicy |
expert_wordle_branch_2k_10sub.pkl | เกม 2K ตัวอย่างโดยใช้ generate_data_branch.py จาก OptimalPolicy กับ 10 สาขาต่อการกระทำตัวอย่างจาก WrongPolicy เช่นมีข้อมูลที่ไม่ดีกว่าใน expert_wordle_branch_100k.pkl _wordle_branch_100k.pkl |
expert_wordle_branch_20k_10sub.pkl | เช่นเดียวกับ expert_wordle_branch_2k_10sub.pkl ยกเว้นเกม 20k แทนที่จะเป็นเกม 2K |
WordleIterableDataset :สร้างการสุ่มตัวอย่างข้อมูล Wordle จากนโยบายเช่นนั้น:
from wordle . wordle_dataset import WordleIterableDataset
from wordle . policy import OptimalPolicy
from data . rl_data import ConstantTokenReward
policy = OptimalPolicy ()
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
data = WordleIterableDataset (
policy = policy ,
vocab = vocab ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
while True :
item = data . sample_item ()__init__ def __init__ ( self , policy : Policy , vocab : Vocabulary , max_len : Optional [ int ], token_reward : TokenReward ) -> Noneอินพุต:
policy: Policy - นโยบายตัวอย่างจากvocab: Vocabulary - คำศัพท์ของสิ่งแวดล้อมmax_len: Optional[int] - ความยาวลำดับสูงสุดในชุดข้อมูลจะตัดทอนลำดับโทเค็นทั้งหมดให้ยาว หาก None ลำดับจะไม่ถูกตัดทอนtoken_reward: TokenReward รางวัลระดับโทเค็นเพื่อนำไปใช้กับลำดับ เราใช้รางวัลคงที่ 0 ต่อการทดลองสำหรับการทดลองทั้งหมด ผลตอบแทน: None
sample_item def sample_item ( self ) -> DataPoint ส่งคืน: วัตถุ DataPoint
เรามีชุดข้อมูลขนาดใหญ่ของเกม Wordle Tweets มากกว่า 200k เช่นนี้:
เราสามารถติดตั้งคำติดตั้งบนสี่เหลี่ยมการเปลี่ยนสีเหล่านี้เพื่อสร้างชุดข้อมูลจริงของเกม Wordle
ข้อมูลทวีตดิบจะได้รับใน data/wordle/tweets.csv แต่เพื่อให้สามารถใช้งานได้คำจริงจะต้องติดตั้งอีกครั้งบนสี่เหลี่ยมสีในทวีต การดำเนินการติดตั้งเพิ่มเติมนี้ต้องใช้สคริปต์การประมวลผลล่วงหน้าซึ่งแคชการเปลี่ยนสีที่เป็นไปได้ทั้งหมดที่อาจเกิดขึ้นภายใต้รายการคำศัพท์: guess_vocab (ชุดคำที่คาดเดาได้) และ correct_vocab (ชุดคำที่ถูกต้องที่เป็นไปได้ในสภาพแวดล้อม) ผลลัพธ์คือโครงสร้างข้อมูลที่ wordle.wordle_dataset.WordleHumanDataset ใช้เพื่อสังเคราะห์เกม Wordle ที่ถูกต้องจากทวีต สคริปต์นี้เป็น scripts/data/wordle/build_human_datastructure.py เรียกสคริปต์เช่น:
cd scripts/data/wordle/
python build_human_datastructure.py --guess_vocab=../../../data/wordle/word_lists/wordle_official.txt --correct_vocab=../../../data/wordle/word_lists/wordle_official.txt --tweets_file=../../../data/wordle/tweets.csv --output_file=../../../data/wordle/random_human_tweet_data.jsonargs ของสคริปต์:
--guess_vocab ระบุชุดของคำที่คาดเดาได้--correct_vocab ระบุชุดคำที่ถูกต้องที่เป็นไปได้ในสภาพแวดล้อม--tweets_file ระบุไฟล์ CSV ดิบของทวีต--output_file ระบุตำแหน่งที่จะทิ้งเอาต์พุต เราได้ทำการประมวลผลล่วงหน้าในรายการคำบางรายการพร้อมกับผลลัพธ์ที่บันทึกไว้ใน data/wordle/
| รายการคำ | ไฟล์ข้อมูลทวีตที่ประเมินล่วงหน้า |
|---|---|
wordle_official.txt | random_human_tweet_data.json |
wordle_official_800.txt | random_human_tweet_data_800.json |
wordle_official_400.txt | random_human_tweet_data_400.json |
wordle_official_200.txt | random_human_tweet_data_200.json |
tweet_words.txt | human_tweet_data_true_word.json |
ให้หนึ่งในไฟล์เหล่านี้คุณสามารถโหลดชุดข้อมูล Wordle Tweet ได้เช่น So:
from wordle . wordle_dataset import WordleHumanDataset
data = WordleHumanDataset . from_file ( 'data/wordle/random_human_tweet_data_200.json' )
print ( data . sample_item ()) เราใช้ 'data/wordle/random_human_tweet_data_200.json' ในการทดลองของเรา
WordleHumanDataset : __init__ def __init__ ( self , games : List [ Tuple [ str , List [ str ]]], transitions : Dict [ str , Dict [ str , List [ str ]]], use_true_word : bool , max_len : Optional [ int ], token_reward : TokenReward , game_indexes : Optional [ List [ int ]], top_p : Optional [ float ]) -> Noneอินพุต:
games: List[Tuple[str, List[str]]] - รายการของ tuples ของแบบฟอร์ม (correct_wordle_word, wordle_transitions_list) โดยที่ wordle_transitions_list เป็นรายการของการเปลี่ยนที่แสดงสีในทวีตเช่น: ["<b><b><y><y><b>", "<g><b><b><b><b>", "<g><g><y><b><b>", "<g><g><g><g><g>"]transitions: Dict[str, Dict[str, List[str]]] - การทำแผนที่คำสั่งคำ Wordle ที่ถูกต้องไปยังการทำแผนที่การเปลี่ยนสีที่เป็นไปได้ที่เป็นไปได้ซึ่งอาจเกิดขึ้นได้จากคำนั้นไปยังรายการคำที่สามารถเล่นเพื่อทำให้เกิดการเปลี่ยนแปลงนั้น โครงสร้างข้อมูลนี้ใช้เพื่อติดตั้งคำติดตั้งลงบนทวีตuse_true_word: bool ถ้า True ใช้คำที่ถูกต้องของความจริงพื้นดินจากทวีตอื่น ๆ อีกครั้งการติดตั้งคำที่ถูกต้องใด ๆ ในรายการคำที่ใช้งานได้max_len: Optional[int] - ความยาวลำดับสูงสุดในชุดข้อมูลจะตัดทอนลำดับโทเค็นทั้งหมดให้ยาว หาก None ลำดับจะไม่ถูกตัดทอนtoken_reward: TokenReward รางวัลระดับโทเค็นเพื่อนำไปใช้กับลำดับ เราใช้รางวัลคงที่ 0 ต่อการทดลองสำหรับการทดลองทั้งหมดgame_indexes: Optional[List[int]] - รายการดัชนีเพื่อสร้างการแยกทวีต หาก None รายการทั้งหมดในข้อมูลจะถูกใช้ เรามี data/wordle/human_eval_idxs.json และ data/wordle/human_train_idxs.json สร้างขึ้นเป็นรถไฟที่เลือกแบบสุ่มและการแยกการประเมินtop_p: Optional[float] - ตัวกรองสำหรับ top_p ที่ดำเนินการเปอร์เซ็นต์ของข้อมูล หาก None จะไม่มีการกรองข้อมูล ใช้กับโมเดล %BC ผลตอบแทน: None
from_file def from_file ( cls , file_path : str , use_true_word : bool = False , max_len : Optional [ int ] = None , token_reward : Optional [ TokenReward ] = None , top_p : Optional [ float ] = None ) -> WordleHumanDatasetอินพุต:
file_path: str - เส้นทางไปยังไฟล์ JSON เพื่อโหลดข้อมูลจากuse_true_word: bool ถ้า True ใช้คำที่ถูกต้องของความจริงพื้นดินจากทวีตอื่น ๆ อีกครั้งการติดตั้งคำที่ถูกต้องใด ๆ ในรายการคำที่ใช้งานได้max_len: Optional[int] - ความยาวลำดับสูงสุดในชุดข้อมูลจะตัดทอนลำดับโทเค็นทั้งหมดให้ยาว หาก None ลำดับจะไม่ถูกตัดทอนtoken_reward: TokenReward รางวัลระดับโทเค็นเพื่อนำไปใช้กับลำดับ เราใช้รางวัลคงที่ 0 ต่อการทดลองสำหรับการทดลองทั้งหมดgame_indexes: Optional[List[int]] - รายการดัชนีเพื่อสร้างการแยกทวีต หาก None รายการทั้งหมดในข้อมูลจะถูกใช้ เรามี data/wordle/human_eval_idxs.json และ data/wordle/human_train_idxs.json สร้างขึ้นเป็นรถไฟที่เลือกแบบสุ่มและการแยกการประเมินtop_p: Optional[float] - ตัวกรองสำหรับ top_p ที่ดำเนินการเปอร์เซ็นต์ของข้อมูล หาก None จะไม่มีการกรองข้อมูล ใช้กับโมเดล %BC ผลตอบแทน: วัตถุ WordleHumanDataset
sample_item def sample_item ( self ) -> DataPoint ส่งคืน: วัตถุ DataPoint
สคริปต์การฝึกอบรมอยู่ใน scripts/train/wordle/
| สคริปต์ | คำอธิบาย |
|---|---|
train_bc.py | ฝึกอบรมตัวแทน BC |
train_iql.py | ฝึกอบรมตัวแทน ILQL |
สคริปต์การประเมินผลอยู่ใน scripts/eval/wordle/
| สคริปต์ | คำอธิบาย |
|---|---|
eval_policy.py | ประเมินตัวแทน BC หรือ ILQL ในสภาพแวดล้อม Wordle |
eval_q_rank.py | สคริปต์การประเมินผลสำหรับการเปรียบเทียบอันดับสัมพัทธ์ของค่า Q สำหรับตัวแทนที่ได้รับการฝึกฝนในชุดข้อมูลสังเคราะห์ที่อธิบายไว้ในส่วนที่ 5 ของบทความของเราซึ่งได้รับการออกแบบมาเพื่อแสดงความแตกต่างระหว่าง RL ขั้นตอนเดียวและ RL หลายขั้นตอน |
distill_policy_eval.py | พิมพ์ผลลัพธ์ของ eval_policy.py ด้วยแถบข้อผิดพลาด |
ที่นี่เราร่างวิธีการโหลดข้อมูลการโต้ตอบภาพใน codebase ของเราและวิธีการดำเนินการสภาพแวดล้อม ดูส่วนการตั้งค่าด้านบนสำหรับวิธีการตั้งค่าส่วนประกอบระยะไกลของสภาพแวดล้อมการสนทนาแบบ Visual วัตถุข้อมูลและสภาพแวดล้อมจะถูกโหลดโดยอัตโนมัติโดยตัวจัดการการกำหนดค่า แต่ถ้าคุณต้องการบายพาสระบบกำหนดค่าและใช้สภาพแวดล้อมด้วย codebase ของคุณเองนี่คือวิธีที่คุณควรโหลดดำเนินการและกำหนดค่าวัตถุเหล่านี้ การตั้งค่าเดียวกันที่อธิบายไว้ด้านล่างสามารถแก้ไขได้ทั้งหมดในการกำหนดค่าเช่นกัน
ตัวอย่างของวิธีการโหลดสภาพแวดล้อมการสนทนาแบบภาพ:
from visdial . visdial_env import VDEnvironment
from visdial . visdial_base import VisDialogueData
from visdial . visdial_dataset import VisDialListDataset
from data . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = VisDialogueData (
data_path = convert_path ( 'data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.json' ),
img_feat_path = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/data_img.h5' ),
split = 'train' ,
reward_cache = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/train_rank_reward_cache1.json' ),
yn_reward_kind = 'none'
)
list_data = VisDialListDataset (
data = data ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 )
)
env = VDEnvironment (
dataset = list_data ,
url = 'http://localhost:5000/step_rank' ,
yn_reward = - 2.0 ,
yn_reward_kind = 'none'
)
print ( env . reset ()) สคริปต์ข้างต้นสอดคล้องกับวิธีที่เรากำหนดค่าชุดข้อมูลและสภาพแวดล้อมสำหรับการทดลองรางวัล 'มาตรฐาน' ของเรา แต่ถ้าคุณต้องการกำหนดค่าชุดข้อมูลที่แตกต่างกันมีอาร์กิวเมนต์มากมายที่คุณสามารถแก้ไขได้ นอกเหนือจากการเปลี่ยนชุดข้อมูลแยกอาร์กิวเมนต์เหล่านี้ยังสามารถเปลี่ยนงานหรือรางวัลได้ ด้านล่างเราจะอธิบายพารามิเตอร์ที่กำหนดค่าที่แตกต่างกันทั้งหมดที่ VisDialogueData , VisDialListDataset และ VDEnvironment
เราจัดทำเอกสารพารามิเตอร์และวิธีการสำหรับ VisDialogueData , VisDialListDataset และ VDEnvironment เพื่อให้คุณรู้วิธีกำหนดค่าสภาพแวดล้อมด้วยตัวคุณเอง
VisDialogueData : VisDialogueData ดำเนินการใน src/visdial/visdial_base.py เก็บชุดบทสนทนาและรางวัลของงาน
__init__ def __init__ ( self , data_path : str , img_feat_path : str , split : str , reward_cache : Optional [ str ] = None , norm_img_feats : bool = True , reward_shift : float = 0.0 , reward_scale : float = 1.0 , addition_scenes : Optional [ List [ Scene ]] = None , mode : str = 'env_stops' , cutoff_rule : Optional [ CutoffRule ] = None , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> Noneอินพุต:
data_path: str - เส้นทางไปยังข้อมูลการสนทนา ควรเป็นหนึ่งใน:data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_val.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_test.jsonimg_feat_path: str - เส้นทางไปยังคุณสมบัติภาพที่ใช้ในการคำนวณรางวัลสำหรับการสนทนาแต่ละครั้ง ควรเป็น data/vis_dialogue/processed/visdial_0.5/data_img.h5split: str - หนึ่งใน train , val , หรือ test ระบุว่าชุดข้อมูลใดที่แยกคุณสมบัติของรูปภาพที่จะใช้ ควรสอดคล้องกับการแยก data_pathreward_cache: Optional[str]=None - ที่ซึ่งรางวัลสำหรับแต่ละบทสนทนาจะถูกเก็บไว้ ถ้า None มันจะกำหนดรางวัลทั้งหมดเป็น None เราให้บริการแคชสำหรับสองฟังก์ชั่นรางวัล:test เราใช้ในกระดาษของเราถูกแคชที่: data/vis_dialogue/processed/visdial_0.5/[split]_rank_reward_cache1.json ที่ [split] ถูกแทนที่ด้วย train หรือ valdata/vis_dialogue/processed/visdial_0.5/[split]_reward_cache2.json ซึ่ง [split] ถูกแทนที่ val train หรือ testnorm_img_feats: bool=True - ไม่ว่าจะทำให้คุณสมบัติของภาพเป็นปกติหรือไม่reward_shift: float=0.0 - เปลี่ยนรางวัลตามจำนวนนี้reward_scale: float=1.0 - ขยายรางวัลด้วยจำนวนนี้addition_scenes: Optional[List[Scene]]=None - ฉีดข้อมูลเพิ่มเติมลงในชุดข้อมูลmode: str='env_stops' - หนึ่งใน ['agent_stops', 'env_stops', '10_stop'] ควบคุมคุณสมบัติบางอย่างของงาน เราใช้ env_stopsmode='env_stops' จากนั้นหยุดการโต้ตอบสภาพแวดล้อมในช่วงต้นตาม cutoff_rulemode='agent_stops' เอเจนต์จะหยุดการโต้ตอบโดยการสร้างโทเค็น <stop> พิเศษในระหว่างการกระทำ เพิ่มข้อมูลโดยวาง <stop> หลังจากการกระทำที่เป็นไปได้ทุกครั้งmode='10_stop' การเล่นจะหยุดหลังจากการโต้ตอบ 10 รอบ 10 รอบเช่นเดียวกับมาตรฐานในชุดข้อมูลบทสนทนาภาพcutoff_rule: Optional[CutoffRule]=None - ใช้เฉพาะถ้า mode='env_stops' ใช้ฟังก์ชั่นที่กำหนดว่าสภาพแวดล้อมควรหยุดการโต้ตอบเร็วเมื่อใด เราใช้ค่าเริ่มต้นของ visdial.visdial_base.PercentileCutoffRule(1.0, 0.5) ในการทดลองทั้งหมดของเราyn_reward: float=-2.0 การลงโทษรางวัลที่ควรเพิ่มสำหรับการถามคำถามใช่/ไม่ใช่yn_reward_kind: str='none' - ระบุการจับคู่สตริงที่จะใช้สำหรับการพิจารณาว่ามีการถามคำถามใช่/ไม่ใช่หรือไม่ ควรเป็นหนึ่งใน ['none', 'soft', 'hard', 'conservative']'none' : อย่าลงโทษคำถามใช่/ไม่ใช่ สิ่งนี้สอดคล้องกับรางวัล standard ในกระดาษของเรา'soft' : ลงโทษคำถามหากการตอบกลับมี "yes" หรือ "no" เป็นสายย่อย'hard' : ลงโทษคำถามหากการตอบกลับตรงกับสตริง "yes" หรือ "no" สิ่งนี้สอดคล้องกับรางวัล "y/n" ในกระดาษของเรา'conservative' : ลงโทษคำถามหากการตอบสนองตอบสนองหนึ่งในหลาย ๆ สตริงที่ตรงกัน สิ่งนี้สอดคล้องกับรางวัล "conservative y/n" ในกระดาษของเรา ผลตอบแทน: None
__len__ def __len__ ( self ) -> intผลตอบแทน: ขนาดของชุดข้อมูล
__getitem__ def __getitem__ ( self , i : int ) -> Sceneอินพุต:
i: int - ดัชนีชุดข้อมูลReturns: รายการจากชุดข้อมูล
VisDialListDataset : VisDialListDataset ดำเนินการใน src/visdial/visdial_dataset.py ล้อมรอบ VisDialogueData และแปลงเป็นรูปแบบ DataPoint ที่สามารถใช้ในการฝึกอบรมตัวแทน RL ออฟไลน์
__init__ def __init__ ( self , data : VisDialogueData , max_len : Optional [ int ], token_reward : TokenReward , top_p : Optional [ float ] = None , bottom_p : Optional [ float ] = None ) -> Noneอินพุต:
data: VisDialogueData - วัตถุข้อมูลการสนทนาแบบภาพที่เก็บข้อมูลดิบทั้งหมดmax_len: Optional[int] - ความยาวลำดับสูงสุดในชุดข้อมูลจะตัดทอนลำดับโทเค็นทั้งหมดให้ยาว หาก None ลำดับจะไม่ถูกตัดทอนtoken_reward: TokenReward รางวัลระดับโทเค็นเพื่อนำไปใช้กับลำดับ เราใช้รางวัลคงที่ 0 ต่อการทดลองสำหรับการทดลองทั้งหมดtop_p: Optional[float] - ตัวกรองสำหรับ top_p ที่ดำเนินการเปอร์เซ็นต์ของข้อมูล หาก None จะไม่มีการกรองข้อมูล ใช้กับโมเดล %BCbottom_p: Optional[float] - ตัวกรองสำหรับ bottom_p ที่ดำเนินการเปอร์เซ็นต์ของข้อมูล หาก None จะไม่มีการกรองข้อมูล ผลตอบแทน: None
size def size ( self ) -> intผลตอบแทน: ขนาดของชุดข้อมูล
get_item def get_item ( self , idx : int ) -> DataPointอินพุต:
i: int - ดัชนีชุดข้อมูล Returns: DataPoint จากชุดข้อมูล
VDEnvironment : VDEnvironment ดำเนินการใน src/visdial/visdial_env.py กำหนดสภาพแวดล้อมการสนทนาทางสายตาซึ่งตัวแทน RL ออฟไลน์ของเราโต้ตอบกับเวลาประเมินผล สภาพแวดล้อมเกี่ยวข้องกับการเชื่อมต่อกับเซิร์ฟเวอร์ localhost ซึ่งส่วนการตั้งค่าอธิบายวิธีการหมุน
__init__ def __init__ ( self , dataset : RL_Dataset , url : str , reward_shift : float = 0.0 , reward_scale : float = 1.0 , actor_stop : bool = False , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> Noneอินพุต:
dataset: RL_Dataset - ใช้ RL_Dataset ; VisDialListDataset โดยเฉพาะดังกล่าวข้างต้น ชุดข้อมูลนี้ใช้เพื่อเลือกสถานะเริ่มต้นurl: str - URL สำหรับการก้าวเข้าสู่สภาพแวดล้อม ทำตามคำแนะนำในส่วนการตั้งค่าสำหรับวิธีเริ่มต้นเว็บเซิร์ฟเวอร์ localhost ที่สอดคล้องกับ URL นี้reward_shift: float=0.0 - เปลี่ยนรางวัลตามจำนวนนี้reward_scale: float=1.0 - ขยายรางวัลด้วยจำนวนนี้actor_stop: bool=False - อนุญาตให้นักแสดงหยุดการโต้ตอบก่อนเวลาโดยการสร้างโทเค็น <stop> พิเศษyn_reward: float=-2.0 การลงโทษรางวัลที่ควรเพิ่มสำหรับการถามคำถามใช่/ไม่ใช่yn_reward_kind: str='none' - ระบุการจับคู่สตริงที่จะใช้สำหรับการพิจารณาว่ามีการถามคำถามใช่/ไม่ใช่หรือไม่ ควรเป็นหนึ่งใน ['none', 'soft', 'hard', 'conservative']'none' : อย่าลงโทษคำถามใช่/ไม่ใช่ สิ่งนี้สอดคล้องกับรางวัล standard ในกระดาษของเรา'soft' : ลงโทษคำถามหากการตอบกลับมี "yes" หรือ "no" เป็นสายย่อย'hard' : ลงโทษคำถามหากการตอบกลับตรงกับสตริง "yes" หรือ "no" สิ่งนี้สอดคล้องกับรางวัล "y/n" ในกระดาษของเรา'conservative' : ลงโทษคำถามหากการตอบสนองตอบสนองหนึ่งในหลาย ๆ สตริงที่ตรงกัน สิ่งนี้สอดคล้องกับรางวัล "conservative y/n" ในกระดาษของเรา ผลตอบแทน: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]อินพุต:
action: Vocabulary - คำศัพท์ของสิ่งแวดล้อมผลตอบแทน: (การสังเกต, รางวัล, เทอร์มินัล) tuple
reset def reset ( self ) -> WordleObservationผลตอบแทน: การสังเกต
is_terminal def is_terminal ( self ) -> boolผลตอบแทน: บูลีนที่ระบุว่าการโต้ตอบสิ้นสุดลงหรือไม่
สคริปต์การฝึกอบรมอยู่ใน scripts/train/vis_dial/
| สคริปต์ | คำอธิบาย |
|---|---|
train_bc.py | ฝึกอบรมตัวแทน BC |
train_chai.py | ฝึกอบรมตัวแทนชัย |
train_cql.py | ฝึกอบรมตัวแทน CQL |
train_dt.py | ฝึกอบรมตัวแทนหม้อแปลงการตัดสินใจ |
train_iql.py | ฝึกอบรมตัวแทน ILQL |
train_psi.py | ฝึก |
train_utterance.py | ฝึกอบรมตัวแทน ILQL ระดับคำพูด |
สคริปต์การประเมินผลอยู่ใน scripts/eval/vis_dial/
| สคริปต์ | คำอธิบาย |
|---|---|
eval_policy.py | ประเมินตัวแทนในสภาพแวดล้อมการสนทนาด้วยภาพ |
top_advantage.py | ค้นหาคำถามที่มีข้อได้เปรียบที่ยิ่งใหญ่ที่สุดและเล็กที่สุดภายใต้โมเดล |
distill_policy_eval.py | พิมพ์ผลลัพธ์ของ eval_policy.py ด้วยแถบข้อผิดพลาด |
Here we outline how to load the Reddit comments data in our codebase and how to execute the environment. See the setup section above for how to setup the toxicity filter reward. The data and environment objects are loaded automatically by the config manager, but if you want to by-pass the config system and use the task with your own codebase, here's how you should load, execute, and configure these objects. The same settings described below can all be modified in the configs as well.
An example of how to load the Reddit comment environment:
from toxicity . toxicity_env import ToxicityEnvironment
from toxicity . reddit_comments_base import RedditData
from toxicity . reward_fs import toxicity_reward
from utils . misc import convert_path
idxs = json . load ( open ( convert_path ( 'data/reddit_comments/train_idxs.json' ), 'r' ))
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = idxs ,
reward_f = toxicity_reward
)
env = ToxicityEnvironment (
data = data ,
reward_f = toxicity_reward
)
print ( env . reset ())
The above script corresponds to how we configured the environment for our toxicity reward experiments, but if you want to configure the environment differently, there are a few arguments you can modify. These arguments can also change the task or reward. Below we describe all the different configurable parameters that our reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment take.
We document the parameters and methods for our different Reddit comment reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment , so that you know how to configure the environment yourself.
Here we outline the 4 main reward functions we use for our Reddit comment task. Each of these rewards is implemented in src/toxicity/reward_fs.py .
toxicity_reward from toxicity . reward_fs import toxicity_reward
reward_f = toxicity_reward ()คำอธิบาย:
The "toxicity" reward from our paper, which queries the GPT-3 toxicity filter. It assigns a value of "0" to non-toxic comments, a value of "1" to moderately toxic comments, and a value of "2" to very toxic comments.
toxicity_noised_reward from toxicity . reward_fs import toxicity_noised_reward
reward_f = toxicity_noised_reward ()คำอธิบาย:
The "noised toxicity" reward from our paper, which is the same as toxicity_noised_reward but induces additional noise. Specifically, it re-assigns comments labeled as "1" (moderately toxic) to either "0" (non-toxic) or "2" (extremely toxic) with equal probability.
score_human_reward from toxicity . reward_fs import score_human_reward
from utils . misc import convert_path
reward_f = score_human_reward (
reddit_path = convert_path ( 'data/reddit_comments/' ),
indexes = None
)คำอธิบาย:
The "upvotes real" reward from our paper, which gives a reward of +1 for positive upvote comments and -1 for negative upvote comments. This uses the ground truth upvotes in the data, so it only applies to comments in the dataset and cannot be used for evaluation. If you input a string not present in the data, it will error. The arguments to this function specify what data to load.
Inputs:
reddit_path: str – a path to the data.indexes: List[int] – a split of indexes in the data to use. If None , it considers all the data. model_reward from toxicity . reward_fs import score_human_reward
from toxicity . reddit_comments_base import RedditData
from toxicity . toxicity_dataset import ToxicityListDataset
from toxicity . reward_model import RobertaBinaryRewardModel
from utils . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = None ,
reward_f = None
)
listdata = ToxicityListDataset (
data = data ,
max_len = 512 ,
token_reward = ConstantTokenReward ( 0.0 )
)
model = RobertaBinaryRewardModel (
data = listdata ,
device = 'cuda' ,
roberta_kind = 'roberta-base' ,
freeze_roberta = False ,
reward_cuttoff = 0.0
)
model . load_state_dict ( torch . load ( convert_path ( 'outputs/toxicity/upvote_reward/model.pkl' ), map_location = 'cpu' ))
reward_f = score_human_reward ( model = model )คำอธิบาย:
The "upvotes model" reward from our paper, which gives a reward of +1 if the given model predicts that the comment will get a positive number of upvotes and a reward of -1 otherwise. The model checkpoint we used for our experiments is at: outputs/toxicity/upvote_reward/model.pkl
Inputs:
model: RewardModel : the reward model implemented in src/toxicity/reward_model.py . The model should be first trained and loaded from a pytorch checkpoint.RedditData : RedditData , implemented in src/toxicity/reddit_comments_base.py , stores the raw Reddit comments data.
__init__ def __init__ ( self , path : str , indexes : Optional [ List [ int ]], reward_f : Optional [ Callable [[ str ], float ]], reward_cache : Optional [ Cache ] = None , reward_shift : float = 0.0 , reward_scale : float = 1.0 ) -> NoneInputs:
path: str – the path to the Reddit data.indexes: Optional[List[int]] – a list of indexes to create a split of the data. Randomly selected, training, validation, and test splits are in the json files:data/reddit_comments/train_idxs.jsondata/reddit_comments/eval_idxs.jsondata/reddit_comments/test_idxs.jsonreward_f: Optional[Callable[[str], float]] – the reward function to use.reward_cache: Optional[Cache]=None – a cache of reward values, so you don't have to recompute them everytime.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount. Returns: None
__len__ def __len__ ( self ) -> intReturns: the size of the dataset.
__getitem__ def __getitem__ ( self , idx : int ) -> SceneInputs:
idx: int – the dataset index.Returns: an item from the dataset.
ToxicityListDataset : ToxicityListDataset , implemented in src/toxicity/toxicity_dataset.py , wraps around RedditData and converts it into a DataPoint format that can be used to train offline RL agents.
__init__ def __init__ ( self , data : RedditData , max_len : Optional [ int ], token_reward : TokenReward , cuttoff : Optional [ float ] = None , resample_timeout : float = 0.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – a Reddit comment data object that stores all the raw data.max_len: Optional[int] – the maximum sequence length in the dataset, will truncate all token sequences to this length. If None , then sequences will not be truncated.token_reward: TokenReward – the token-level reward to apply to the sequences. We use a constant reward of 0 per-token for all experiments.cuttoff: Optional[float]=None – filter out all comments from the dataset with reward less than cuttoff . If None , no data will be filtered. Used with %BC models.resample_timeout: float=0.0 – when cuttoff is not equal to None , comments are stochastically sampled iid from the dataset, like an iterable, even though the dataset has a list-type interface. It uniformly re-samples from the dataset until it finds a comment with a reward that satisfies the cuttoff. In the case of the "toxicity" reward, this re-sampling can cause rate-limit errors on the GPT-3 API, so we allow you to add a resample_timeout to fix this issue: a timeout of roughly 0.05 should fix rate-limit issues.include_parent: bool=True – whether to condition on the parent comment in the thread. If False , models will be trained to generate comments unconditionally. Returns: None
size def size ( self ) -> intReturns: the size of the dataset.
get_item def get_item ( self , idx : int ) -> DataPointInputs:
i: int – the dataset index. Returns: a DataPoint from the dataset.
ToxicityEnvironment : ToxicityEnvironment , implemented in src/toxicity/toxicity_env.py , defines the Reddit comment generation environment, which our offline RL agents interact with at evaluation time.
__init__ def __init__ ( self , data : RedditData , reward_f : Optional [ Callable [[ str ], float ]], reward_shift : float = 0.0 , reward_scale : float = 1.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – the dataset used to select initial state parent comments to condition on.reward_f: Optional[Callable[[str], float]] – the reward function to use.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount.include_parent: bool=True – specifies whether to condition on the previous comment or post in the Reddit thread. Returns: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Inputs:
action: Vocabulary – the environment's vocabularyReturns: an (observation, reward, terminal) tuple.
reset def reset ( self ) -> WordleObservationReturns: an observation
is_terminal def is_terminal ( self ) -> boolReturns: a boolean indicating if the interaction has terminated.
Training scripts are in scripts/train/toxicity/ .
| script | คำอธิบาย |
|---|---|
train_bc.py | Train a BC agent. |
train_iql.py | Train an ILQL agent. |
train_upvote_reward.py | Train the upvote reward model. |
Evaluation scripts are in scripts/eval/toxicity/ .
| script | คำอธิบาย |
|---|---|
eval_policy.py | Evaluate an agent in the Reddit comments environment. |
distill_policy_eval.py | Prints out the result of eval_policy.py with error bars. |
All tasks – Wordle, Visual Dialogue, Reddit – have a corresponding environment and dataset implemented in the codebase, as described above. And all offline RL algorithms in the codebase are trained, executed, and evaluated on one of these given environments and datasets.
You can similarly define your own tasks that can easily be run on all these offline RL algorithms. This codebase implements a simple set of RL environment abstractions that make it possible to define your own environments and datasets that can plug-and-play with any of the offline RL algorithms.
All of the core abstractions are defined in src/data/ . Here we outline what needs to be implemented in order to create your own tasks. For examples, see the implementations in src/wordle/ , src/vis_dial/ , and src/toxicity/ .
All tasks must implement subclasses of: Language_Observation and Language_Environment , which are in src/data/language_environment.py .
Language_Observation :This class represents the observations from the environment that will be input to your language model.
A Language_Observation must define the following two functions.
to_sequence def to_sequence ( self ) -> Tuple [ List [ str , Optional [ float ]], bool ]:คำอธิบาย:
A function which converts the observation object into a standard format that can be input to the language model and used for training.
ผลตอบแทน:
__str__ def __str__ ( self ) -> str :คำอธิบาย:
This is only used to print the observation to the terminal. It should convert the observation into some kind of string that is interpretable by a user.
Returns: a string.
Language_Environment :This class represents a gym-style environment for online interaction, which is only used for evaluation.
A Language_Environment must define the following three functions.
step def step ( self , action : str ) -> Tuple [ Language_Observation , float , bool ]:คำอธิบาย:
Just like a standard gym environment, given an action in the form of a string, step the environment forward.
Returns: a tuple of (Language_Observation, reward, terminal).
reset def reset ( self ) -> Language_Observation :คำอธิบาย:
This resets the environment to an initial state.
Returns: the corresponding initial Language_Observation
is_terminal def is_terminal ( self ) -> bool :คำอธิบาย:
Outputs whether the environment has reached a terminal state.
Returns: a boolean indicating if the environment has reached a terminal state.
All tasks must implement subclasses of either List_RL_Dataset or Iterable_RL_Dataset or both, which are defined in src/data/rl_data.py .
List_RL_Dataset :This class represents a list dataset (or an indexable dataset of finite length) that can be used to train offline RL agents.
A List_RL_Dataset must define the following two functions.
get_item def get_item ( self , idx : int ) -> DataPointคำอธิบาย:
This gets an item from the dataset at a given index.
Returns: a DataPoint object from the dataset.
size def size ( self ) -> intคำอธิบาย:
Returns the size of the dataset.
Returns: the dataset's size.
Iterable_RL_Dataset :This class represents an iterable dataset (or a non-indexable dataset that stochastically samples datapoints iid) that can be used to train offline RL agents.
A Iterable_RL_Dataset must define the following function.
sample_item def sample_item ( self ) -> DataPointคำอธิบาย:
Samples a datapoint from the dataset.
Returns: a DataPoint object from the dataset.


