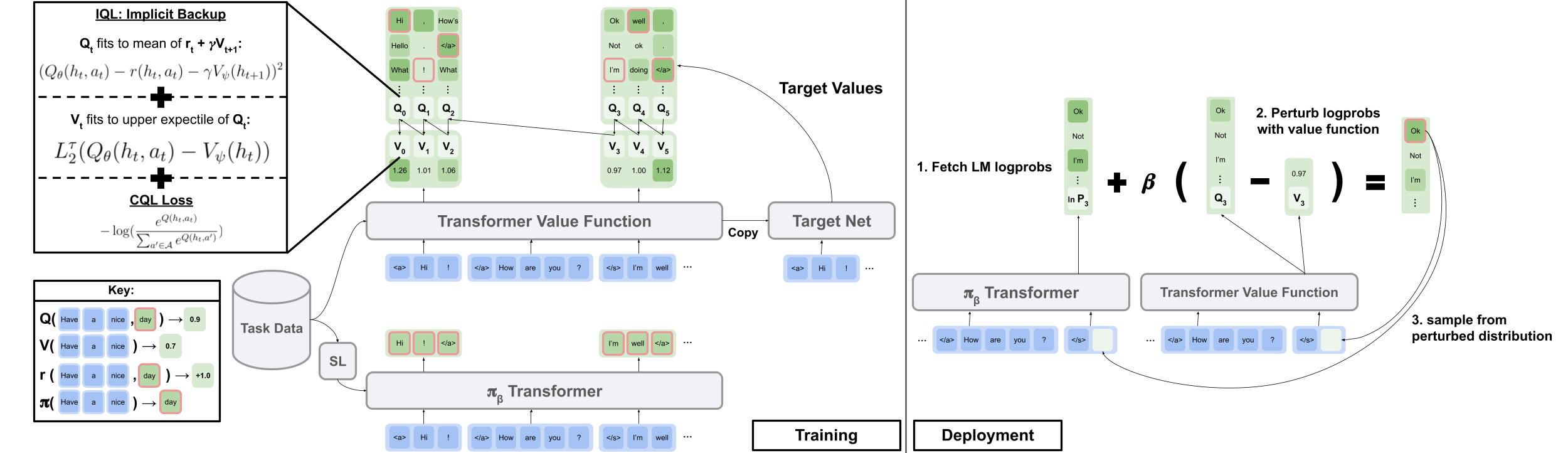
Implicit Language Q Learning
1.0.0
Kode resmi dari makalah "Offline RL untuk pembuatan bahasa alami dengan bahasa implisit q learning"
Situs Proyek | arxiv
Unduh data.zip dan outputs.zip dari folder Google Drive di sini. Tempatkan folder, data/ dan outputs/ yang diunduh dan unit/, pada akar repo. data/ Berisi data yang diproses sebelumnya untuk semua tugas kami, dan outputs/ berisi pos pemeriksaan untuk hadiah reddit kami upvote imbalan.
Repo ini dirancang untuk Python 3.9.7
pip install -r requirements.txt
export PYTHONPATH= " $PWD /src/ "Untuk menjalankan eksperimen dialog visual, Anda perlu melayani lingkungan dialog visual di LocalHost dengan mengikuti instruksi di sini.
Untuk menjalankan eksperimen komentar reddit dengan hadiah filter toksisitas:
export OPENAI_API_KEY=your_API_key scripts/ berisi semua skrip percobaan. Untuk menjalankan skrip apa pun dalam scripts/ :
python script_name.pyOpsional:
python script_name.py eval.bsize=5 train.lr=1e-6 wandb.use_wandb=falsepython -m torch.distributed.launch --nproc_per_node [N_GPUs] --use_env script_name.py arg1=a arg2=b Secara default semua skrip pelatihan log ke wandb. Untuk mematikan ini, atur wandb.use_wandb=false di konfigurasi pelatihan.
Di sini saya menguraikan alur kerja yang disarankan untuk pelatihan agen RL offline. Misalkan saya ingin melatih banyak agen RL offline yang berbeda untuk menghasilkan komentar reddit dengan hadiah toksisitas.
Saya pertama -tama akan melatih model BC pada data:
cd scripts/train/toxicity/
python train_bc.pyKemudian ubah pos pemeriksaan BC ini menjadi satu kompatibel dengan model RL offline:
cd ../data/
python convert_bc.py --load ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model.pkl --save ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model_converted.pklKemudian edit pos pemeriksaan bahwa Offline RL dikonfigurasi untuk berlatih dengan:
cd ../train/
python train_iql.py model.load.checkpoint_path=outputs/toxicity/model_converted.pkl model.load.strict_load=false train.loss.awac_weight=0.0 Ini hanya satu alur kerja, Anda juga dapat melatih model BC secara bersamaan dengan agen RL offline dengan mengatur train.loss.awac_weight=1.0 dalam konfigurasi pelatihan.
data/ folder.scripts/ Berisi semua skrip untuk menjalankan langkah-langkah pelatihan, evaluasi, dan data pra-pemrosesan data. Script diatur ke dalam subfolder yang sesuai dengan dataset yang digunakan.config/ contains .yaml config untuk setiap skrip. Repo ini menggunakan Hydra untuk mengelola konfigurasi. Konfigurasi disusun ke dalam subfolder yang sesuai dengan dataset yang digunakan. Sebagian besar file konfigurasi dinamai sama dengan skrip yang sesuai, tetapi jika Anda tidak yakin konfigurasi mana yang sesuai dengan skrip, periksa line @hydra.main(config_path="some_path", config_name="some_name") untuk melihat file konfigurasi yang sesuai dengan skrip.src/ berisi semua implementasi inti. Lihat src/models/ untuk semua implementasi model. Lihat src/data/ Untuk semua pemrosesan data dasar dan kode abstraksi MDP. Lihat src/utils/ untuk berbagai fungsi utilitas. Lihat src/wordle/ , src/visdial , dan src/toxicity/ Untuk semua Wordle, Dialog Visual, dan Kode Kembali KOMENTAR REDDIT masing -masing.ILQL disebut sebagai iql di seluruh repo. Setiap skrip dikaitkan dengan file konfigurasi. File konfigurasi menentukan model, dataset, dan evaluator mana yang harus dimuat oleh skrip dan hiperparameter yang sesuai. Lihat configs/toxicity/train_iql.yaml Sebagai contoh.
Setiap model yang memungkinkan, dataset, atau objek evaluator diberikan file konfigurasi sendiri, yang menentukan nilai default untuk objek tersebut dan atribut name khusus, yang memberi tahu Config Manager apa yang dimuat kelas. Lihat configs/toxicity/model/per_token_iql.yaml Sebagai contoh.
File src/load_objects.py , src/wordle/load_objects.py , src/visdial/load_objects.py , dan src/toxicity/load_objects.py Tentukan bagaimana setiap objek dimuat dari konfigurasi yang sesuai. Tag @register('name') di atas setiap tautan fungsi objek beban ke atribut name di konfigurasi.
Anda mungkin melihat atribut cache_id khusus yang terkait dengan beberapa objek dalam konfigurasi. Sebagai contoh, lihat train_dataset di configs/toxicity/train_iql.yaml . Atribut ini memberi tahu manajer konfigurasi untuk menyimpan objek pertama yang dimuat yang dikaitkan dengan ID ini, dan kemudian untuk mengembalikan objek yang di -cache ini untuk konfigurasi objek berikutnya dengan cache_id ini.
Untuk semua konfigurasi, gunakan jalur relatif terhadap root repo.
Masing -masing tugas dalam repo kami - Wordle, Visual Dialogue, dan Reddit komentar - mengimplementasikan beberapa kelas dasar. Setelah diimplementasikan, semua algoritma RL offline dapat diterapkan pada tugas dengan cara plug-and-play. Lihat bagian "Membuat Tugas Anda Sendiri" untuk gambaran umum tentang apa yang harus diimplementasikan untuk membuat tugas Anda sendiri. Di bawah ini, kami menguraikan abstraksi utama yang memungkinkan ini.
data.language_environment.Language_Environment - mewakili lingkungan tugas POMDP, yang dapat berinteraksi dengan kebijakan. Ini memiliki antarmuka seperti gym.data.language_environment.Policy - mewakili kebijakan yang dapat berinteraksi dengan lingkungan. Masing -masing algoritma RL offline dalam src/models/ memiliki kebijakan yang sesuai.data.language_environment.Language_Observation - mewakili pengamatan teks yang dikembalikan oleh lingkungan dan diberikan sebagai input ke kebijakan.data.language_environment.interact_environment - fungsi yang mengambil lingkungan, kebijakan, dan secara opsional pengamatan saat ini dan menjalankan loop interaksi lingkungan. Jika pengamatan saat ini tidak disediakan, secara otomatis mengambil keadaan awal dengan mengatur ulang lingkungan.data.rl_data.DataPoint - Menentukan format data standar yang diberi makan sebagai input untuk semua agen RL offline pada semua tugas. Struktur data ini dibuat secara otomatis dari Language_Observation yang diberikan.data.rl_data.TokenReward - mendefinisikan fungsi hadiah yang diberikan pada setiap token tunggal, yang dapat digunakan untuk mempelajari lebih banyak kontrol berbutir yang lebih halus. Ini disediakan di atas hadiah lingkungan, yang tidak ada di setiap token tetapi sebaliknya setelah setiap pergantian interaksi. Dalam semua percobaan kami, kami menetapkan hadiah ini ke 0 konstan, sehingga tidak berpengaruh.data.tokenizer.Tokenizer - Menentukan cara mengonversi string ke dan dari urutan token yang kemudian dapat diberi makan sebagai input ke model bahasa.data.rl_data.RL_Dataset - mendefinisikan objek dataset yang mengembalikan objek DataPoint dan digunakan untuk pelatihan agen RL offline. Ada dua versi RL_Dataset :List_RL_DatasetIterable_RL_Dataset
Di sini kami menguraikan dan mendokumentasikan semua komponen tugas Wordle kami.
Banyak dari apa yang ada dalam contoh skrip dilakukan secara otomatis oleh Config Manager, dan parameter yang sesuai dapat diedit dengan mengubah konfigurasi. Tetapi jika Anda ingin memotong menggunakan konfigurasi dan menggunakan tugas Wordle dengan basis kode Anda sendiri, Anda dapat merujuk skrip dan dokumentasi di bawah ini untuk cara melakukan ini.
Contoh skrip sederhana untuk bermain Wordle di Commandline.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from wordle . policy import UserPolicy
from data . language_environment import interact_environment
from utils . misc import convert_path
game_vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( game_vocab )
policy = UserPolicy ()
interact_environment ( env , policy )src/wordle/wordle_game.pysrc/wordle/wordle_env.pysrc/wordle/policy.pysrc/wordle/wordle_dataset.pyUntuk menjadikan permainan sebagai MDP yang valid, lingkungan mewakili keadaan yang mendasari sebagai satu set kendala huruf yang diketahui, dan menggunakannya untuk memfilter kosa kata untuk kata -kata yang memenuhi semua kendala ini di setiap belokan. Kata acak kemudian dipilih dari daftar kata yang difilter ini dan digunakan untuk menentukan transisi warna yang dikembalikan oleh lingkungan. Transisi warna baru ini kemudian memperbarui himpunan kendala huruf yang diketahui.
Lingkungan Wordle mengambil dalam daftar kata. Beberapa daftar kata diberikan dalam data/wordle/word_lists/ , tetapi jangan ragu untuk membuatnya sendiri.
Daftar kata yang disertakan adalah:
Daftar kata dimuat ke lingkungan melalui objek Vocabulary seperti pada contoh di atas.
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))Kosakata menyimpan tidak hanya daftar kata, tetapi juga melacak daftar kata -kata yang difilter yang memenuhi semua kendala huruf yang diketahui dalam keadaan tertentu. Daftar ini digunakan untuk menghitung transisi di lingkungan dan digunakan oleh beberapa kebijakan yang dibuat dengan tangan.
Memproduksi daftar yang difilter ini secara real time dapat memperlambat proses interaksi lingkungan. Ini biasanya tidak menjadi masalah, tetapi jika Anda ingin dengan cepat mensintesis banyak data dari suatu kebijakan, maka ini mungkin menjadi hambatan. Untuk mengatasi hal ini, semua objek Vocabulary menyimpan argumen cache , yang menyimpan daftar kata yang difilter yang terkait dengan keadaan tertentu. vocab.cache.load(f_path) dan vocab.cache.dump() memungkinkan memuat dan menyimpan cache ini. Misalnya, data/wordle/vocab_cache_wordle_official.pkl adalah cache besar untuk daftar kata Worddle_Official.txt.
Di luar menyimpan cache, objek Vocabulary mengimplementasikan metode berikut dalam src/wordle/wordle_game.py :
__init__ def __init__ ( self , all_vocab : List [ str ],
wordle_state : Optional [ WordleState ],
cache : Optional [ Cache ] = None ,
fill_cache : bool = True ) -> NoneInput:
all_vocab: List[str] - daftar kata.wordle_state: Optional[WordleState] - keadaan untuk menghasilkan daftar kata yang difilter, jika tidak ada keadaan yang disediakan, tidak ada kata yang difilter.cache: Optional[Cache]=None - Cache untuk vocab yang difilter, seperti dijelaskan di atas.fill_cache: bool=True - apakah akan menambahkan ke cache. Kembali: None
from_file def from_file ( cls , vocab_file : str , fill_cache : bool = True ) -> VocabularyInput:
vocab_file: str - file yang memuat kata -kata. Metode hanya memilih kata -kata yang panjangnya 5 huruf.fill_cache: bool=True - apakah akan menambahkan ke cache. Pengembalian: Vocabulary
filtered_vocab_size def filtered_vocab_size ( self ) -> intPengembalian: Ukuran kosa kata yang difilter
all_vocab_size def all_vocab_size ( self ) -> intPengembalian: Ukuran kosakata penuh tanpa filter
get_random_word_filtered def get_random_word_filtered ( self ) -> strPengembalian: Kata acak dari daftar yang difilter.
get_random_word_all def get_random_word_all ( self ) -> strPengembalian: Kata acak dari daftar tanpa filter lengkap.
update_vocab def update_vocab ( self , wordle_state : WordleState ) -> VocabularyInput:
wordle_state: WordleState - Objek keadaan Wordle, mewakili himpunan kendala huruf yang diketahui. Pengembalian: Objek Vocabulary baru, yang disaring sesuai dengan wordle_state .
__str__ def __str__ ( self ) -> strPengembalian: Representasi string dari daftar kata yang difilter untuk dicetak ke terminal.
WordleEnvironment mengambil objek kosa kata sebagai input, yang mendefinisikan seperangkat kata -kata yang benar di lingkungan.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( vocab )
initial_obs = env . reset ()
next_obs , reward , terminal = env . step ( "snake" ) Seperti yang ditunjukkan di atas, lingkungan mengimplementasikan antarmuka seperti gym di src/wordle/wordle_env.py :
__init__ def __init__ ( self , vocab : Vocabulary ) -> NoneInput:
vocab: Vocabulary - Kosakata lingkungan. Kembali: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Input:
action: Vocabulary - Serangkaian teks yang mewakili tindakan agen di lingkungan.Pengembalian: Tuple (Pengamatan, Hadiah, Terminal).
reset def reset ( self ) -> WordleObservationPengembalian: Pengamatan.
is_terminal def is_terminal ( self ) -> boolPengembalian: Boolean yang menunjukkan jika interaksi telah berakhir.
Kami menerapkan serangkaian kebijakan Wordle yang dibuat dengan tangan yang mencakup berbagai tingkat gameplay. Semua ini diimplementasikan dalam src/wordle/policy.py . Di sini kami menggambarkan masing -masing:
UserPolicy from wordle . policy import UserPolicy
policy = UserPolicy ( hint_policy = None , vocab = None )Keterangan:
Mari Anda bermain di terminal.
Input:
hint_policy: Optional[Policy] - Kebijakan lain untuk meminta jika Anda ingin petunjuk tentang kata apa yang digunakan.vocab: Optional[Union[str, Vocabulary]] - Vocabulary kata -kata yang dapat ditebak. Jika tidak ditentukan, urutan 5 huruf chars adalah tebakan yang valid. StartWordPolicy from wordle . policy import StartWordPolicy
policy = StartWordPolicy ()Keterangan:
Untuk diterapkan hanya untuk kata pertama. Memilih kata secara acak dari daftar kata -kata start berkualitas tinggi.
Input:
start_words: Optional[List[str]]=None - angkanya daftar kata start yang dikuratori. OptimalPolicy from wordle . policy import OptimalPolicy
policy = OptimalPolicy ()Keterangan:
Secara miopis memainkan kata mendapatkan informasi tertinggi dari daftar kata yang memenuhi semua kendala surat yang diketahui. Kebijakan ini sebenarnya tidak optimal, karena permainan optimal adalah NP-Hard. Tapi itu diputar pada level yang sangat tinggi, dan dapat digunakan sebagai perkiraan atas untuk kinerja. Kebijakan ini sangat lambat untuk dihitung, dengan kinerja kuadratik dalam ukuran daftar kata; Untuk menyimpan perhitungan, self.cache.load(f_path) dan self.cache.dump() memungkinkan Anda memuat dan menyimpan cache. Misalnya, data/wordle/optimal_policy_cache_wordle_official.pkl mewakili cache untuk kebijakan ini pada daftar kata wordle_official.txt .
Input:
start_word_policy: Optional[Policy]=None - karena kata pertama umumnya adalah yang paling mahal untuk menghitung keuntungan informasi, ini memungkinkan Anda untuk menentukan kebijakan yang berbeda untuk dipanggil hanya kata pertama.progress_bar: bool=False - karena bisa memakan waktu lama untuk menghitung, kami meninggalkan Anda opsi untuk menampilkan bilah kemajuan untuk setiap panggilan ke self.act . RepeatPolicy from wordle . policy import RepeatPolicy
policy = RepeatPolicy ( start_word_policy = None , first_n = 2 )Keterangan:
Mengulang secara acak salah satu kata first_n yang sudah digunakan. Ini adalah kebijakan suboptimal yang maksimal, karena tidak pernah bisa menang kecuali jika itu beruntung pada kata pertama.
Input:
start_word_policy: Optional[Policy] - Kebijakan yang akan digunakan untuk memilih kata pertama. Jika None , maka pilih secara acak dari kata dari kosakata lingkungan.first_n: Optional[int] - Kebijakan secara acak memilih kata berikutnya dari kata -kata first_n dalam sejarah. Jika None , maka ia memilih secara acak dari riwayat lengkap. RandomMixturePolicy from wordle . policy import RandomMixturePolicy
policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )Keterangan:
Memilih satu kata sepenuhnya secara acak dari daftar kata dengan probabilitas (1 - prob_smart) dan memilih kata acak dari daftar kata yang memenuhi semua kendala huruf yang diketahui dengan probabilitas prob_smart .
Input:
prob_smart: float - probabilitas memilih kata yang memenuhi semua kendala huruf yang diketahui, daripada satu sepenuhnya secara acak.vocab: Optional[Union[str, Vocabulary]] - Daftar kata untuk dipilih. Jika None , maka kebijakan itu default ke daftar kata lingkungan. WrongPolicy from wordle . policy import WrongPolicy
from wordle . wordle_game import Vocabulary
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
policy = WrongPolicy ( vocab )Keterangan:
Secara acak memilih kata dari daftar kata yang gagal memenuhi semua kendala huruf yang diketahui dan dengan demikian tidak dapat menjadi kata yang benar. Jika semua kata dalam daftar kata memenuhi kendala huruf, maka ia memilih kata secara acak dari daftar. Kebijakan ini sangat suboptimal.
Input:
vocab: Union[str, Vocabulary] - daftar kata untuk dipilih. MixturePolicy from wordle . policy import MixturePolicy , OptimalPolicy , RandomMixturePolicy
policy1 = OptimalPolicy ()
policy2 = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MixturePolicy ( prob1 = 0.5 , policy1 = policy1 , policy2 = policy2 )Keterangan:
Mencampur dua kebijakan yang diberikan. Pilih dari policy1 dengan probabilitas prob1 dan pilih dari policy2 dengan probabilitas (1 - prob1) .
Input:
prob1: float - probabilitas memilih tindakan dari policy1 .policy1: Policy - Kebijakan pertama yang memilih tindakan dari. Dipilih dengan probabilitas prob1 .policy1: Policy - Kebijakan Kedua untuk memilih tindakan dari. Dipilih dengan probabilitas (1 - prob1) . MonteCarloPolicy from wordle . policy import MonteCarloPolicy
sample_policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MonteCarloPolicy ( n_samples = 5 , sample_policy = sample_policy )Keterangan:
Mengambil kebijakan, menjalankan n_samples dari peluncuran Monte Carlo di lingkungan, dan memilih tindakan berikutnya yang menerima hadiah rata -rata tertinggi selama proses peluncuran.
Input:
n_samples: int - Jumlah peluncuran Monte Carlo untuk dieksekusi.sample_policy: Policy - Kebijakan untuk mencicipi peluncuran dari. 
Kebijakan di atas dapat digunakan untuk menghasilkan kumpulan data, yang dapat digunakan untuk melatih agen RL offline. Kami mengimplementasikan, dalam src/wordle/wordle_dataset.py , dua jenis set data sintetis:
wordle.wordle_dataset.WordleListDataset - memuat game Wordle dari file.wordle.wordle_dataset.WordleIterableDataset - Sampel Game Wordle dari kebijakan yang diberikan.WordleListDataset :Muat dataset Wordle dari file seperti SO:
from wordle . wordle_dataset import WordleListDataset
from data . rl_data import ConstantTokenReward
data = WordleListDataset . from_file (
file_path = 'data/wordle/expert_wordle_100k.pkl' ,
max_len = None ,
vocab = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
for i in range ( data . size ()):
item = data . get_item ( i )__init__ def __init__ ( self , items : List [ Tuple [ WordleObservation , Optional [ Dict [ str , Any ]]]], max_len : Optional [ int ], token_reward : TokenReward ) -> NoneInput:
items: List[Tuple[WordleObservation, Optional[Dict[str, Any]]]] - daftar data dalam bentuk tupel (WorddleObservation, metadata_dict). Di mana metadata_dict adalah segala jenis metadata adalah segala jenis metadata yang mungkin ingin Anda simpan di titik data.max_len: Optional[int] - Panjang urutan maksimum dalam dataset, akan memotong semua urutan token dengan panjang ini. Jika None , maka urutan tidak akan terpotong.token_reward: TokenReward -Hadiah tingkat token untuk berlaku untuk urutan. Kami menggunakan hadiah konstan 0 per-token untuk semua percobaan. Kembali: None
from_file def from_file ( cls , file_path : str , max_len : Optional [ int ], vocab : Optional [ Vocabulary ], token_reward : TokenReward ) -> WordleListDatasetInput:
file_path: str - Path ke file acar data.max_len: Optional[int] - Panjang urutan maksimum dalam dataset, akan memotong semua urutan token dengan panjang ini. Jika None , maka urutan tidak akan terpotong.vocab: Optional[Vocabulary] - Simulasi dataset di bawah kosakata lingkungan yang berbeda. Jika None , default menggunakan kosakata yang sama yang digunakan untuk membuat dataset.token_reward: TokenReward -Hadiah tingkat token untuk berlaku untuk urutan. Kami menggunakan hadiah konstan 0 per-token untuk semua percobaan. Pengembalian: Objek WordleListDataset .
get_item def get_item ( self , idx : int ) -> DataPointInput:
idx: int - indeks dalam dataset. Pengembalian: Objek DataPoint .
size def size ( self ) -> intPengembalian: Ukuran dataset.
Script berikut dalam scripts/data/wordle/ dapat digunakan untuk mensintesis data Wordle.
| naskah | keterangan |
|---|---|
generate_data.py | Sampel sejumlah game dari kebijakan tertentu yang ditentukan dalam konfigurasi dan menyimpannya ke file. |
generate_data_mp.py | Sama seperti generate_data.py kecuali sampel game secara paralel pada beberapa proses. |
generate_adversarial_data.py | Sintesis dataset yang dijelaskan dalam Bagian 5 dari makalah kami, yang dirancang untuk menunjukkan perbedaan antara metode RL satu langkah dan yang multi-langkah. |
generate_adversarial_data_mp.py | Sama seperti generate_adversarial_data.py kecuali sampel game secara paralel pada beberapa proses. |
generate_data_branch.py | Sampel permainan dari kebijakan "ahli" yang diberikan dan kemudian dari setiap aksi dalam permainan, kebijakan "suboptimal" bercabang dari sampel sejumlah game baru. |
generate_data_branch_mp.py | Sama seperti generate_data_branch.py kecuali sampel game secara paralel pada beberapa proses. |
Beberapa dataset sintetis yang disediakan ada dalam data/wordle/ .
| mengajukan | keterangan |
|---|---|
expert_wordle_100k_1.pkl | 100K game sampel dari OptimalPolicy . |
expert_wordle_100k_2.pkl | Game 100K lainnya diambil sampelnya dari OptimalPolicy . |
expert_wordle_adversarial_20k.pkl | Dataset yang dijelaskan dalam Bagian 5 dari makalah kami, yang dirancang untuk menunjukkan perbedaan antara metode RL satu langkah dan yang multi-langkah. |
expert_wordle_branch_100k.pkl | 100K game yang disampel menggunakan generate_data_branch.py dari OptimalPolicy dengan cabang yang disampel dari WrongPolicy . |
expert_wordle_branch_150k.pkl | Permainan 150k lainnya yang diambil sampelnya menggunakan generate_data_branch.py dari OptimalPolicy dengan cabang yang disampel dari WrongPolicy . |
expert_wordle_branch_2k_10sub.pkl | Game 2K sampel menggunakan generate_data_branch.py dari OptimalPolicy dengan 10 cabang per tindakan yang disampel dari WrongPolicy , sehingga ada lebih banyak data suboptimal yang lebih besar daripada di expert_wordle_branch_100k.pkl . |
expert_wordle_branch_20k_10sub.pkl | Sama seperti expert_wordle_branch_2k_10sub.pkl kecuali 20K game, bukan game 2K. |
WordleIterableDataset :Menghasilkan pengambilan sampel data Wordle dari kebijakan seperti itu:
from wordle . wordle_dataset import WordleIterableDataset
from wordle . policy import OptimalPolicy
from data . rl_data import ConstantTokenReward
policy = OptimalPolicy ()
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
data = WordleIterableDataset (
policy = policy ,
vocab = vocab ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
while True :
item = data . sample_item ()__init__ def __init__ ( self , policy : Policy , vocab : Vocabulary , max_len : Optional [ int ], token_reward : TokenReward ) -> NoneInput:
policy: Policy - Kebijakan untuk mencicipi dari.vocab: Vocabulary - Kosakata lingkungan.max_len: Optional[int] - Panjang urutan maksimum dalam dataset, akan memotong semua urutan token dengan panjang ini. Jika None , maka urutan tidak akan terpotong.token_reward: TokenReward -Hadiah tingkat token untuk berlaku untuk urutan. Kami menggunakan hadiah konstan 0 per-token untuk semua percobaan. Kembali: None
sample_item def sample_item ( self ) -> DataPoint Pengembalian: Objek DataPoint .
Kami memiliki dataset besar lebih dari 200 ribu tweet game Wordle seperti ini:
Kita dapat memperbaiki kata -kata ke dalam kotak transisi warna ini untuk membuat dataset nyata game Wordle.
Data tweet mentah diberikan dalam data/wordle/tweets.csv , tetapi untuk dapat digunakan, kata -kata aktual perlu dipasang kembali ke kotak warna di tweet. Melakukan proses retrofiting ini membutuhkan pelaksanaan skrip preprocessing yang menyimpan semua kemungkinan transisi warna yang dapat terjadi di bawah daftar vocab: guess_vocab (seperangkat kata -kata yang dapat ditebak) dan correct_vocab (serangkaian kata -kata yang benar yang mungkin di lingkungan). Hasilnya adalah struktur data yang digunakan wordle.wordle_dataset.WordleHumanDataset untuk mensintesis game Wordle yang valid dari tweet. Script ini adalah scripts/data/wordle/build_human_datastructure.py . Hubungi skrip seperti:
cd scripts/data/wordle/
python build_human_datastructure.py --guess_vocab=../../../data/wordle/word_lists/wordle_official.txt --correct_vocab=../../../data/wordle/word_lists/wordle_official.txt --tweets_file=../../../data/wordle/tweets.csv --output_file=../../../data/wordle/random_human_tweet_data.jsonArgs skrip:
--guess_vocab Menentukan himpunan kata-kata yang dapat ditebak.--correct_vocab Menentukan himpunan kata-kata yang benar di lingkungan.--tweets_file Menentukan file CSV mentah dari tweet--output_file Menentukan tempat membuang output. Kami telah menjalankan preprocessing pada beberapa daftar kata, dengan hasil yang disimpan dalam data/wordle/ .
| Daftar Kata | File data tweet preproses |
|---|---|
wordle_official.txt | random_human_tweet_data.json |
wordle_official_800.txt | random_human_tweet_data_800.json |
wordle_official_400.txt | random_human_tweet_data_400.json |
wordle_official_200.txt | random_human_tweet_data_200.json |
tweet_words.txt | human_tweet_data_true_word.json |
Diberikan salah satu dari file -file ini Anda dapat memuat dataset tweet Wordle seperti:
from wordle . wordle_dataset import WordleHumanDataset
data = WordleHumanDataset . from_file ( 'data/wordle/random_human_tweet_data_200.json' )
print ( data . sample_item ()) Kami menggunakan 'data/wordle/random_human_tweet_data_200.json' dalam percobaan kami.
WordleHumanDataset : __init__ def __init__ ( self , games : List [ Tuple [ str , List [ str ]]], transitions : Dict [ str , Dict [ str , List [ str ]]], use_true_word : bool , max_len : Optional [ int ], token_reward : TokenReward , game_indexes : Optional [ List [ int ]], top_p : Optional [ float ]) -> NoneInput:
games: List[Tuple[str, List[str]]] – a list of tuples of the form (correct_wordle_word, wordle_transitions_list) , where wordle_transitions_list is a list of transitions indicating the colors in the Tweet like: ["<b><b><y><y><b>", "<g><b><b><b><b>", "<g><g><y><b><b>", "<g><g><g><g><g>"] .transitions: Dict[str, Dict[str, List[str]]] - Dikt pemetaan kata Wordle yang benar ke dikt lain pemetaan transisi warna yang mungkin diinduksi oleh kata itu ke daftar kata -kata yang bisa dimainkan untuk menyebabkan transisi itu. Struktur data ini digunakan untuk memperbaiki kata -kata ke tweet.use_true_word: bool -jika True , gunakan kata-kebenaran yang benar dari tweet, selain itu retrofit kata apa pun yang benar dalam daftar kata yang berfungsi.max_len: Optional[int] - Panjang urutan maksimum dalam dataset, akan memotong semua urutan token dengan panjang ini. Jika None , maka urutan tidak akan terpotong.token_reward: TokenReward -Hadiah tingkat token untuk berlaku untuk urutan. Kami menggunakan hadiah konstan 0 per-token untuk semua percobaan.game_indexes: Optional[List[int]] - Daftar indeks untuk membuat perpecahan tweet. Jika None , semua item dalam data akan digunakan. Kami memiliki data/wordle/human_eval_idxs.json dan data/wordle/human_train_idxs.json dibuat sebagai pelatihan yang dipilih secara acak dan pemisahan eval.top_p: Optional[float] - Filter untuk top_p melakukan persen dari data. Jika None , tidak ada data yang akan difilter. Digunakan dengan %model BC. Kembali: None
from_file def from_file ( cls , file_path : str , use_true_word : bool = False , max_len : Optional [ int ] = None , token_reward : Optional [ TokenReward ] = None , top_p : Optional [ float ] = None ) -> WordleHumanDatasetInput:
file_path: str - Path ke file JSON untuk memuat data dari.use_true_word: bool -jika True , gunakan kata-kebenaran yang benar dari tweet, selain itu retrofit kata apa pun yang benar dalam daftar kata yang berfungsi.max_len: Optional[int] - Panjang urutan maksimum dalam dataset, akan memotong semua urutan token dengan panjang ini. Jika None , maka urutan tidak akan terpotong.token_reward: TokenReward -Hadiah tingkat token untuk berlaku untuk urutan. Kami menggunakan hadiah konstan 0 per-token untuk semua percobaan.game_indexes: Optional[List[int]] - Daftar indeks untuk membuat perpecahan tweet. Jika None , semua item dalam data akan digunakan. Kami memiliki data/wordle/human_eval_idxs.json dan data/wordle/human_train_idxs.json dibuat sebagai pelatihan yang dipilih secara acak dan pemisahan eval.top_p: Optional[float] - Filter untuk top_p melakukan persen dari data. Jika None , tidak ada data yang akan difilter. Digunakan dengan %model BC. Pengembalian: Objek WordleHumanDataset .
sample_item def sample_item ( self ) -> DataPoint Pengembalian: Objek DataPoint .
Script pelatihan ada dalam scripts/train/wordle/ .
| naskah | keterangan |
|---|---|
train_bc.py | Latih agen BC. |
train_iql.py | Latih agen ILQL. |
Skrip evaluasi ada dalam scripts/eval/wordle/ .
| naskah | keterangan |
|---|---|
eval_policy.py | Mengevaluasi agen BC atau ILQL di lingkungan Wordle. |
eval_q_rank.py | Skrip evaluasi untuk membandingkan peringkat relatif nilai Q untuk agen yang dilatih pada dataset sintetis yang dijelaskan dalam Bagian 5 dari makalah kami, yang dirancang untuk menunjukkan perbedaan antara RL satu langkah dan multi-langkah RL. |
distill_policy_eval.py | Mencetak hasil eval_policy.py dengan bilah kesalahan. |
Di sini kami menguraikan cara memuat data dialog visual di basis kode kami dan cara menjalankan lingkungan. Lihat bagian Pengaturan di atas untuk cara mengatur komponen jarak jauh dari lingkungan dialog visual. Objek Data dan Lingkungan dimuat secara otomatis oleh Config Manager, tetapi jika Anda ingin melewati sistem konfigurasi dan menggunakan lingkungan dengan basis kode Anda sendiri, inilah cara Anda memuat, mengeksekusi, dan mengkonfigurasi objek ini. Pengaturan yang sama yang dijelaskan di bawah ini semuanya dapat dimodifikasi di konfigurasi juga.
Contoh cara memuat lingkungan dialog visual:
from visdial . visdial_env import VDEnvironment
from visdial . visdial_base import VisDialogueData
from visdial . visdial_dataset import VisDialListDataset
from data . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = VisDialogueData (
data_path = convert_path ( 'data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.json' ),
img_feat_path = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/data_img.h5' ),
split = 'train' ,
reward_cache = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/train_rank_reward_cache1.json' ),
yn_reward_kind = 'none'
)
list_data = VisDialListDataset (
data = data ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 )
)
env = VDEnvironment (
dataset = list_data ,
url = 'http://localhost:5000/step_rank' ,
yn_reward = - 2.0 ,
yn_reward_kind = 'none'
)
print ( env . reset ()) Skrip di atas sesuai dengan cara kami mengonfigurasi dataset dan lingkungan untuk eksperimen hadiah 'standar' kami, tetapi jika Anda ingin mengonfigurasi dataset secara berbeda, ada banyak argumen yang dapat Anda modifikasi. Selain hanya mengubah perpecahan dataset, argumen ini juga dapat mengubah tugas atau hadiah. Di bawah ini kami menjelaskan semua parameter yang dapat dikonfigurasi yang berbeda yang diambil VisDialogueData , VisDialListDataset , dan VDEnvironment .
Kami mendokumentasikan parameter dan metode untuk VisDialogueData , VisDialListDataset , dan VDEnvironment , jadi Anda tahu cara mengkonfigurasi lingkungan sendiri.
VisDialogueData : VisDialogueData , diimplementasikan dalam src/visdial/visdial_base.py , menyimpan set dialog dan hadiah tugas.
__init__ def __init__ ( self , data_path : str , img_feat_path : str , split : str , reward_cache : Optional [ str ] = None , norm_img_feats : bool = True , reward_shift : float = 0.0 , reward_scale : float = 1.0 , addition_scenes : Optional [ List [ Scene ]] = None , mode : str = 'env_stops' , cutoff_rule : Optional [ CutoffRule ] = None , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneInput:
data_path: str - Jalur ke data dialog. Harus menjadi salah satu dari:data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_val.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_test.jsonimg_feat_path: str - Jalur ke fitur gambar yang digunakan untuk menghitung hadiah untuk setiap dialog. Harus selalu data/vis_dialogue/processed/visdial_0.5/data_img.h5 .split: str - salah satu dari train , val , atau test . Menunjukkan perpecahan dataset dari fitur gambar yang akan digunakan. Harus konsisten dengan split data_path .reward_cache: Optional[str]=None - di mana imbalan untuk setiap dialog disimpan. Jika None , itu akan menetapkan semua hadiah ke None . Kami menyediakan cache untuk dua fungsi hadiah:data/vis_dialogue/processed/visdial_0.5/[split]_rank_reward_cache1.json , di mana [split] digantikan oleh salah satu train , val , atau test .data/vis_dialogue/processed/visdial_0.5/[split]_reward_cache2.json , di mana [split] digantikan oleh salah satu train , val , atau test .norm_img_feats: bool=True - apakah akan menormalkan fitur gambar.reward_shift: float=0.0 - geser hadiah dengan jumlah ini.reward_scale: float=1.0 - skala hadiah dengan jumlah ini.addition_scenes: Optional[List[Scene]]=None - menyuntikkan data tambahan ke dalam dataset.mode: str='env_stops' - salah satu dari ['agent_stops', 'env_stops', '10_stop'] . Mengontrol beberapa sifat tugas. Kami menggunakan env_stopsmode='env_stops' , lalu hentikan interaksi lingkungan lebih awal menurut cutoff_rule .mode='agent_stops' , maka agen menghentikan interaksi dengan menghasilkan token <stop> khusus selama aksinya; menambah data dengan menempatkan <stop> setelah setiap tindakan yang memungkinkan.mode='10_stop' , permainan selalu berhenti setelah 10 putaran interaksi, seperti standar dalam dataset dialog visual.cutoff_rule: Optional[CutoffRule]=None - hanya berlaku jika mode='env_stops' . Mengimplementasikan fungsi yang menentukan kapan lingkungan harus menghentikan interaksi lebih awal. Kami menggunakan default visdial.visdial_base.PercentileCutoffRule(1.0, 0.5) dalam semua percobaan kami.yn_reward: float=-2.0 -Hukuman hadiah yang harus ditambahkan untuk mengajukan pertanyaan ya/tidak.yn_reward_kind: str='none' - Menentukan heuristik pencocokan string yang akan digunakan untuk menentukan apakah pertanyaan ya/tidak ditanyakan. Harus menjadi salah satu dari ['none', 'soft', 'hard', 'conservative'] .'none' : Jangan menghukum pertanyaan ya/tidak. Ini sesuai dengan hadiah standard dalam makalah kami.'soft' : menghukum pertanyaan jika respons berisi "yes" atau "no" sebagai substring.'hard' : menghukum pertanyaan jika respons cocok dengan string "yes" atau "no" . Ini sesuai dengan hadiah "y/n" dalam makalah kami.'conservative' : menghukum pertanyaan jika tanggapan memenuhi salah satu dari beberapa heuristik yang cocok dengan string. Ini sesuai dengan hadiah "conservative y/n" dalam makalah kami. Kembali: None
__len__ def __len__ ( self ) -> intPengembalian: Ukuran dataset.
__getitem__ def __getitem__ ( self , i : int ) -> SceneInput:
i: int - Indeks Dataset.Pengembalian: Item dari dataset.
VisDialListDataset : VisDialListDataset , diimplementasikan dalam src/visdial/visdial_dataset.py , membungkus di sekitar VisDialogueData dan mengubahnya menjadi format DataPoint yang dapat digunakan untuk melatih agen RL offline.
__init__ def __init__ ( self , data : VisDialogueData , max_len : Optional [ int ], token_reward : TokenReward , top_p : Optional [ float ] = None , bottom_p : Optional [ float ] = None ) -> NoneInput:
data: VisDialogueData - Objek Data Dialog Visual yang menyimpan semua data mentah.max_len: Optional[int] - Panjang urutan maksimum dalam dataset, akan memotong semua urutan token dengan panjang ini. Jika None , maka urutan tidak akan terpotong.token_reward: TokenReward -Hadiah tingkat token untuk berlaku untuk urutan. Kami menggunakan hadiah konstan 0 per-token untuk semua percobaan.top_p: Optional[float] - Filter untuk top_p melakukan persen dari data. Jika None , tidak ada data yang akan difilter. Digunakan dengan %model BC.bottom_p: Optional[float] - Filter untuk bottom_p melakukan persen dari data. Jika None , tidak ada data yang akan difilter. Kembali: None
size def size ( self ) -> intPengembalian: Ukuran dataset.
get_item def get_item ( self , idx : int ) -> DataPointInput:
i: int - Indeks Dataset. Pengembalian: titik DataPoint dari dataset.
VDEnvironment : VDEnvironment , diimplementasikan dalam src/visdial/visdial_env.py , mendefinisikan lingkungan dialog visual, yang berinteraksi dengan agen RL offline kami pada waktu evaluasi. Lingkungan melibatkan penghubung ke server LocalHost, yang dijelaskan bagian pengaturannya.
__init__ def __init__ ( self , dataset : RL_Dataset , url : str , reward_shift : float = 0.0 , reward_scale : float = 1.0 , actor_stop : bool = False , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneInput:
dataset: RL_Dataset - mengambil RL_Dataset ; khususnya VisDialListDataset , seperti di atas. Dataset ini digunakan untuk memilih status awal.url: str - URL untuk melangkah di lingkungan. Ikuti instruksi di bagian pengaturan untuk cara menginisialisasi server web localhost yang sesuai dengan url ini.reward_shift: float=0.0 - geser hadiah dengan jumlah ini.reward_scale: float=1.0 - skala hadiah dengan jumlah ini.actor_stop: bool=False - Izinkan aktor untuk menghentikan interaksi lebih awal dengan menghasilkan token <stop> khusus.yn_reward: float=-2.0 -Hukuman hadiah yang harus ditambahkan untuk mengajukan pertanyaan ya/tidak.yn_reward_kind: str='none' - Menentukan heuristik pencocokan string yang akan digunakan untuk menentukan apakah pertanyaan ya/tidak ditanyakan. Harus menjadi salah satu dari ['none', 'soft', 'hard', 'conservative'] .'none' : Jangan menghukum pertanyaan ya/tidak. Ini sesuai dengan hadiah standard dalam makalah kami.'soft' : menghukum pertanyaan jika respons berisi "yes" atau "no" sebagai substring.'hard' : menghukum pertanyaan jika respons cocok dengan string "yes" atau "no" . Ini sesuai dengan hadiah "y/n" dalam makalah kami.'conservative' : menghukum pertanyaan jika tanggapan memenuhi salah satu dari beberapa heuristik yang cocok dengan string. Ini sesuai dengan hadiah "conservative y/n" dalam makalah kami. Kembali: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Input:
action: Vocabulary - Kosakata LingkunganPengembalian: Tuple (Pengamatan, Hadiah, Terminal).
reset def reset ( self ) -> WordleObservationPengembalian: Pengamatan
is_terminal def is_terminal ( self ) -> boolPengembalian: Boolean yang menunjukkan jika interaksi telah berakhir.
Script pelatihan ada dalam scripts/train/vis_dial/ .
| naskah | keterangan |
|---|---|
train_bc.py | Latih agen BC. |
train_chai.py | Latih agen chai. |
train_cql.py | Latih agen CQL. |
train_dt.py | Latih agen transformator keputusan. |
train_iql.py | Latih agen ILQL. |
train_psi.py | Latih An |
train_utterance.py | Latih agen ILQL tingkat ucapan. |
Skrip evaluasi ada dalam scripts/eval/vis_dial/ .
| naskah | keterangan |
|---|---|
eval_policy.py | Evaluasi agen di lingkungan dialog visual. |
top_advantage.py | Menemukan pertanyaan yang memiliki keuntungan terbesar dan terkecil di bawah model. |
distill_policy_eval.py | Mencetak hasil eval_policy.py dengan bilah kesalahan. |
Here we outline how to load the Reddit comments data in our codebase and how to execute the environment. See the setup section above for how to setup the toxicity filter reward. The data and environment objects are loaded automatically by the config manager, but if you want to by-pass the config system and use the task with your own codebase, here's how you should load, execute, and configure these objects. The same settings described below can all be modified in the configs as well.
An example of how to load the Reddit comment environment:
from toxicity . toxicity_env import ToxicityEnvironment
from toxicity . reddit_comments_base import RedditData
from toxicity . reward_fs import toxicity_reward
from utils . misc import convert_path
idxs = json . load ( open ( convert_path ( 'data/reddit_comments/train_idxs.json' ), 'r' ))
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = idxs ,
reward_f = toxicity_reward
)
env = ToxicityEnvironment (
data = data ,
reward_f = toxicity_reward
)
print ( env . reset ())
The above script corresponds to how we configured the environment for our toxicity reward experiments, but if you want to configure the environment differently, there are a few arguments you can modify. These arguments can also change the task or reward. Below we describe all the different configurable parameters that our reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment take.
We document the parameters and methods for our different Reddit comment reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment , so that you know how to configure the environment yourself.
Here we outline the 4 main reward functions we use for our Reddit comment task. Each of these rewards is implemented in src/toxicity/reward_fs.py .
toxicity_reward from toxicity . reward_fs import toxicity_reward
reward_f = toxicity_reward ()Keterangan:
The "toxicity" reward from our paper, which queries the GPT-3 toxicity filter. It assigns a value of "0" to non-toxic comments, a value of "1" to moderately toxic comments, and a value of "2" to very toxic comments.
toxicity_noised_reward from toxicity . reward_fs import toxicity_noised_reward
reward_f = toxicity_noised_reward ()Keterangan:
The "noised toxicity" reward from our paper, which is the same as toxicity_noised_reward but induces additional noise. Specifically, it re-assigns comments labeled as "1" (moderately toxic) to either "0" (non-toxic) or "2" (extremely toxic) with equal probability.
score_human_reward from toxicity . reward_fs import score_human_reward
from utils . misc import convert_path
reward_f = score_human_reward (
reddit_path = convert_path ( 'data/reddit_comments/' ),
indexes = None
)Keterangan:
The "upvotes real" reward from our paper, which gives a reward of +1 for positive upvote comments and -1 for negative upvote comments. This uses the ground truth upvotes in the data, so it only applies to comments in the dataset and cannot be used for evaluation. If you input a string not present in the data, it will error. The arguments to this function specify what data to load.
Inputs:
reddit_path: str – a path to the data.indexes: List[int] – a split of indexes in the data to use. If None , it considers all the data. model_reward from toxicity . reward_fs import score_human_reward
from toxicity . reddit_comments_base import RedditData
from toxicity . toxicity_dataset import ToxicityListDataset
from toxicity . reward_model import RobertaBinaryRewardModel
from utils . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = None ,
reward_f = None
)
listdata = ToxicityListDataset (
data = data ,
max_len = 512 ,
token_reward = ConstantTokenReward ( 0.0 )
)
model = RobertaBinaryRewardModel (
data = listdata ,
device = 'cuda' ,
roberta_kind = 'roberta-base' ,
freeze_roberta = False ,
reward_cuttoff = 0.0
)
model . load_state_dict ( torch . load ( convert_path ( 'outputs/toxicity/upvote_reward/model.pkl' ), map_location = 'cpu' ))
reward_f = score_human_reward ( model = model )Keterangan:
The "upvotes model" reward from our paper, which gives a reward of +1 if the given model predicts that the comment will get a positive number of upvotes and a reward of -1 otherwise. The model checkpoint we used for our experiments is at: outputs/toxicity/upvote_reward/model.pkl
Inputs:
model: RewardModel : the reward model implemented in src/toxicity/reward_model.py . The model should be first trained and loaded from a pytorch checkpoint.RedditData : RedditData , implemented in src/toxicity/reddit_comments_base.py , stores the raw Reddit comments data.
__init__ def __init__ ( self , path : str , indexes : Optional [ List [ int ]], reward_f : Optional [ Callable [[ str ], float ]], reward_cache : Optional [ Cache ] = None , reward_shift : float = 0.0 , reward_scale : float = 1.0 ) -> NoneInputs:
path: str – the path to the Reddit data.indexes: Optional[List[int]] – a list of indexes to create a split of the data. Randomly selected, training, validation, and test splits are in the json files:data/reddit_comments/train_idxs.jsondata/reddit_comments/eval_idxs.jsondata/reddit_comments/test_idxs.jsonreward_f: Optional[Callable[[str], float]] – the reward function to use.reward_cache: Optional[Cache]=None – a cache of reward values, so you don't have to recompute them everytime.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount. Returns: None
__len__ def __len__ ( self ) -> intReturns: the size of the dataset.
__getitem__ def __getitem__ ( self , idx : int ) -> SceneInputs:
idx: int – the dataset index.Returns: an item from the dataset.
ToxicityListDataset : ToxicityListDataset , implemented in src/toxicity/toxicity_dataset.py , wraps around RedditData and converts it into a DataPoint format that can be used to train offline RL agents.
__init__ def __init__ ( self , data : RedditData , max_len : Optional [ int ], token_reward : TokenReward , cuttoff : Optional [ float ] = None , resample_timeout : float = 0.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – a Reddit comment data object that stores all the raw data.max_len: Optional[int] – the maximum sequence length in the dataset, will truncate all token sequences to this length. If None , then sequences will not be truncated.token_reward: TokenReward – the token-level reward to apply to the sequences. We use a constant reward of 0 per-token for all experiments.cuttoff: Optional[float]=None – filter out all comments from the dataset with reward less than cuttoff . If None , no data will be filtered. Used with %BC models.resample_timeout: float=0.0 – when cuttoff is not equal to None , comments are stochastically sampled iid from the dataset, like an iterable, even though the dataset has a list-type interface. It uniformly re-samples from the dataset until it finds a comment with a reward that satisfies the cuttoff. In the case of the "toxicity" reward, this re-sampling can cause rate-limit errors on the GPT-3 API, so we allow you to add a resample_timeout to fix this issue: a timeout of roughly 0.05 should fix rate-limit issues.include_parent: bool=True – whether to condition on the parent comment in the thread. If False , models will be trained to generate comments unconditionally. Returns: None
size def size ( self ) -> intReturns: the size of the dataset.
get_item def get_item ( self , idx : int ) -> DataPointInputs:
i: int – the dataset index. Returns: a DataPoint from the dataset.
ToxicityEnvironment : ToxicityEnvironment , implemented in src/toxicity/toxicity_env.py , defines the Reddit comment generation environment, which our offline RL agents interact with at evaluation time.
__init__ def __init__ ( self , data : RedditData , reward_f : Optional [ Callable [[ str ], float ]], reward_shift : float = 0.0 , reward_scale : float = 1.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – the dataset used to select initial state parent comments to condition on.reward_f: Optional[Callable[[str], float]] – the reward function to use.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount.include_parent: bool=True – specifies whether to condition on the previous comment or post in the Reddit thread. Returns: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Inputs:
action: Vocabulary – the environment's vocabularyReturns: an (observation, reward, terminal) tuple.
reset def reset ( self ) -> WordleObservationReturns: an observation
is_terminal def is_terminal ( self ) -> boolReturns: a boolean indicating if the interaction has terminated.
Training scripts are in scripts/train/toxicity/ .
| naskah | keterangan |
|---|---|
train_bc.py | Train a BC agent. |
train_iql.py | Train an ILQL agent. |
train_upvote_reward.py | Train the upvote reward model. |
Evaluation scripts are in scripts/eval/toxicity/ .
| naskah | keterangan |
|---|---|
eval_policy.py | Evaluate an agent in the Reddit comments environment. |
distill_policy_eval.py | Prints out the result of eval_policy.py with error bars. |
All tasks – Wordle, Visual Dialogue, Reddit – have a corresponding environment and dataset implemented in the codebase, as described above. And all offline RL algorithms in the codebase are trained, executed, and evaluated on one of these given environments and datasets.
You can similarly define your own tasks that can easily be run on all these offline RL algorithms. This codebase implements a simple set of RL environment abstractions that make it possible to define your own environments and datasets that can plug-and-play with any of the offline RL algorithms.
All of the core abstractions are defined in src/data/ . Here we outline what needs to be implemented in order to create your own tasks. For examples, see the implementations in src/wordle/ , src/vis_dial/ , and src/toxicity/ .
All tasks must implement subclasses of: Language_Observation and Language_Environment , which are in src/data/language_environment.py .
Language_Observation :This class represents the observations from the environment that will be input to your language model.
A Language_Observation must define the following two functions.
to_sequence def to_sequence ( self ) -> Tuple [ List [ str , Optional [ float ]], bool ]:Keterangan:
A function which converts the observation object into a standard format that can be input to the language model and used for training.
Kembali:
__str__ def __str__ ( self ) -> str :Keterangan:
This is only used to print the observation to the terminal. It should convert the observation into some kind of string that is interpretable by a user.
Returns: a string.
Language_Environment :This class represents a gym-style environment for online interaction, which is only used for evaluation.
A Language_Environment must define the following three functions.
step def step ( self , action : str ) -> Tuple [ Language_Observation , float , bool ]:Keterangan:
Just like a standard gym environment, given an action in the form of a string, step the environment forward.
Returns: a tuple of (Language_Observation, reward, terminal).
reset def reset ( self ) -> Language_Observation :Keterangan:
This resets the environment to an initial state.
Returns: the corresponding initial Language_Observation
is_terminal def is_terminal ( self ) -> bool :Keterangan:
Outputs whether the environment has reached a terminal state.
Returns: a boolean indicating if the environment has reached a terminal state.
All tasks must implement subclasses of either List_RL_Dataset or Iterable_RL_Dataset or both, which are defined in src/data/rl_data.py .
List_RL_Dataset :This class represents a list dataset (or an indexable dataset of finite length) that can be used to train offline RL agents.
A List_RL_Dataset must define the following two functions.
get_item def get_item ( self , idx : int ) -> DataPointKeterangan:
This gets an item from the dataset at a given index.
Returns: a DataPoint object from the dataset.
size def size ( self ) -> intKeterangan:
Returns the size of the dataset.
Returns: the dataset's size.
Iterable_RL_Dataset :This class represents an iterable dataset (or a non-indexable dataset that stochastically samples datapoints iid) that can be used to train offline RL agents.
A Iterable_RL_Dataset must define the following function.
sample_item def sample_item ( self ) -> DataPointKeterangan:
Samples a datapoint from the dataset.
Returns: a DataPoint object from the dataset.


