Implicit Language Q Learning
1.0.0
Código oficial del documento "RL fuera de línea para la generación de idiomas naturales con lenguaje implícito Q aprendizaje"
Sitio del proyecto | arxiv
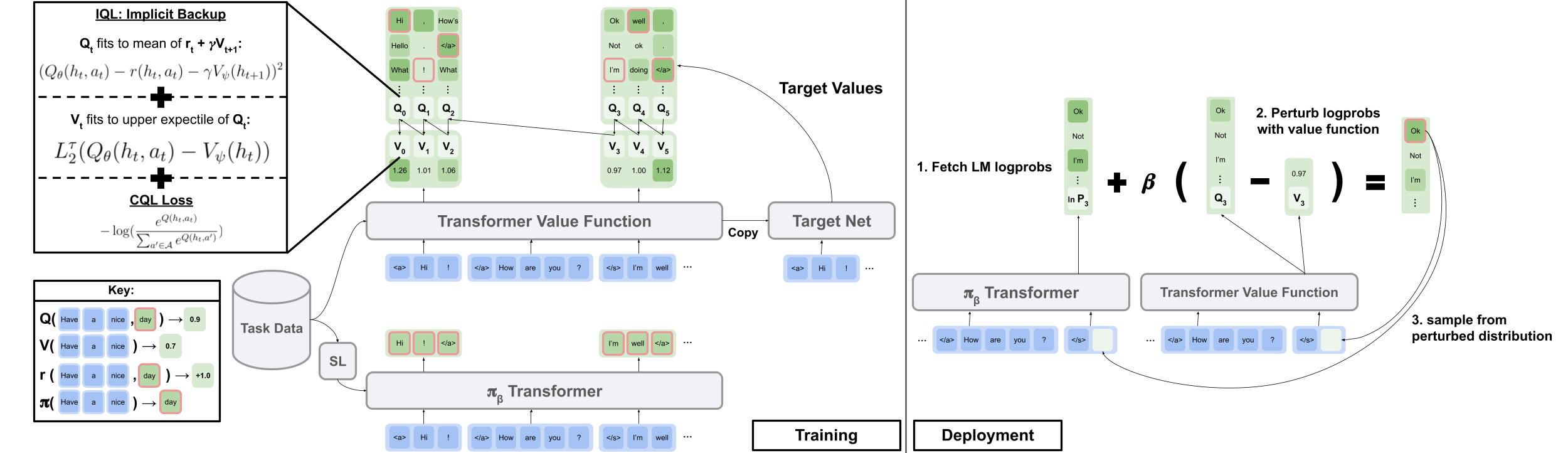
Descargue data.zip y outputs.zip desde la carpeta de Google Drive aquí. Coloque las carpetas, data/ outputs/ descargadas y desbloqueadas en la raíz del repositorio. data/ contiene los datos preprocesados para todas nuestras tareas, y outputs/ contiene el punto de control para nuestra recompensa de voto de voto de comentarios Reddit.
Este repositorio fue diseñado para Python 3.9.7
pip install -r requirements.txt
export PYTHONPATH= " $PWD /src/ "Para ejecutar los experimentos de diálogo visual, debe servir al entorno de diálogo visual en Localhost siguiendo las instrucciones aquí.
Para ejecutar los experimentos de comentarios de Reddit con la recompensa del filtro de toxicidad:
export OPENAI_API_KEY=your_API_key scripts/ Contiene todos los scripts de experimentos. Para ejecutar cualquier script en scripts/ :
python script_name.pyOpcional:
python script_name.py eval.bsize=5 train.lr=1e-6 wandb.use_wandb=falsepython -m torch.distributed.launch --nproc_per_node [N_GPUs] --use_env script_name.py arg1=a arg2=b Por defecto, todos los scripts de entrenamiento registran a Wandb. Para apagar esto, establezca wandb.use_wandb=false en la configuración de entrenamiento.
Aquí describo un flujo de trabajo recomendado para capacitar a los agentes RL fuera de línea. Supongamos que quiero entrenar a un grupo de diferentes agentes de RL fuera de línea para generar comentarios de Reddit con la recompensa de toxicidad.
Primero entrenaría un modelo BC en los datos:
cd scripts/train/toxicity/
python train_bc.pyLuego convierta este punto de control de BC en uno compatible con los modelos RL fuera de línea:
cd ../data/
python convert_bc.py --load ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model.pkl --save ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model_converted.pklLuego edite el punto de control que RL fuera de línea está configurado para entrenar con:
cd ../train/
python train_iql.py model.load.checkpoint_path=outputs/toxicity/model_converted.pkl model.load.strict_load=false train.loss.awac_weight=0.0 Sin embargo, este es solo un flujo de trabajo, también puede entrenar el modelo BC al mismo tiempo que el agente RL fuera de línea configurando train.loss.awac_weight=1.0 en la configuración de entrenamiento.
data/ .scripts/ contiene todos los scripts para ejecutar los pasos de capacitación, evaluación y preprocesamiento de datos en el documento. Los scripts se organizan en subcarpetas correspondientes al conjunto de datos utilizado.config/ contiene configuraciones .yaml para cada script. Este repositorio usa Hydra para administrar las configuraciones. Las configuraciones se organizan en subcarpetas correspondientes al conjunto de datos utilizado. La mayoría de los archivos de configuración se denominan igual que su script correspondiente, pero si no está seguro de qué configuración corresponde a un script, verifique la línea @hydra.main(config_path="some_path", config_name="some_name") para ver a qué archivo de configuración corresponde el script.src/ contiene todas las implementaciones principales. Consulte src/models/ para todas las implementaciones del modelo. Consulte src/data/ para todo el procesamiento de datos base y el código de abstracción MDP. Consulte src/utils/ para varias funciones de utilidad. Consulte src/wordle/ , src/visdial , y src/toxicity/ para todos los Código específico de datos de comentarios de Wordle, Visual y Reddit Comentarios respectivamente.ILQL se conoce como iql a lo largo del repositorio. Cada script está asociado con un archivo de configuración. El archivo de configuración especifica qué modelos, conjunto de datos y evaluadores deben ser cargados por el script y sus hiperparámetros correspondientes. Consulte configs/toxicity/train_iql.yaml para un ejemplo.
Cada modelo posible, conjunto de datos o objeto Evaluator tiene su propio archivo de configuración, que especifica los valores predeterminados para ese objeto y un atributo name especial, que le dice al administrador de configuración qué clase cargar. Consulte configs/toxicity/model/per_token_iql.yaml para un ejemplo.
Los archivos src/load_objects.py , src/wordle/load_objects.py , src/visdial/load_objects.py , y src/toxicity/load_objects.py Definir cómo cada objeto se carga desde su configuración correspondiente. La etiqueta @register('name') sobre cada función de objeto de carga se vincula al atributo name en la configuración.
Puede notar un atributo especial cache_id asociado con algunos objetos en una configuración. Para obtener un ejemplo, consulte train_dataset en configs/toxicity/train_iql.yaml . Este atributo le dice al administrador de configuración que almacene en caché el primer objeto que carga que está asociado con esta ID y luego que devuelva este objeto almacenado en caché para las configuraciones de objetos posteriores con este cache_id .
Para todas las configuraciones, use rutas relativas a la raíz de repositorio.
Cada una de las tareas en nuestro repositorio (Fordle, Diálogo Visual y comentarios de Reddit) implementa algunas clases base. Una vez implementado, todos los algoritmos RL fuera de línea se pueden aplicar a la tarea de manera plug-and-play. Consulte la sección "Creación de sus propias tareas" para obtener una descripción general de lo que debe implementarse para crear sus propias tareas. A continuación, describimos las abstracciones clave que hacen que esto sea posible.
data.language_environment.Language_Environment : representa un entorno POMDP de tarea, con el que una política puede interactuar. Tiene una interfaz de gimnasio.data.language_environment.Policy : representa una política que puede interactuar con un entorno. Cada uno de los algoritmos RL fuera de línea en src/models/ tiene una política correspondiente.data.language_environment.Language_Observation : representa una observación de texto que es devuelta por el entorno y se da como entrada a una política.data.language_environment.interact_environment : una función que toma en un entorno, una política y, opcionalmente, la observación actual y ejecuta un bucle de interacción del entorno. Si no se proporciona la observación actual, obtiene automáticamente un estado inicial al reiniciar el entorno.data.rl_data.DataPoint : define un formato de datos estandarizado que se alimenta como entrada a todos los agentes RL fuera de línea en todas las tareas. Estas estructuras de datos se crean automáticamente a partir de un Language_Observation determinado_OBServation.data.rl_data.TokenReward : define una función de recompensa dada en cada token, que puede usarse para aprender un control de grano más fino. Esto se proporciona además de la recompensa del medio ambiente, que no viene en cada token sino después de cada giro de interacción. En todos nuestros experimentos, establecemos esta recompensa en un 0 constante, de modo que no tiene ningún efecto.data.tokenizer.Tokenizer : especifica cómo convertir cadenas hacia y desde secuencias de tokens que luego pueden alimentarse como entrada a modelos de idiomas.data.rl_data.RL_Dataset : define un objeto de conjunto de datos que devuelve los objetos DataPoint y se utiliza para capacitar a los agentes RL fuera de línea. Hay dos versiones de RL_Dataset :List_RL_DatasetIterable_RL_Dataset
Aquí describimos y documentamos todos los componentes de nuestra tarea de Wordle.
Gran parte de lo que está en los scripts de ejemplo es realizado automáticamente por el administrador de configuración, y los parámetros correspondientes se pueden editar cambiando las configuraciones. Pero si desea pasar por alto el uso de las configuraciones y usar la tarea de Wordle con su propia base de código, puede hacer referencia a los scripts y la documentación a continuación sobre cómo hacerlo.
Un script de ejemplo simple para reproducir Wordle en la línea de comandos.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from wordle . policy import UserPolicy
from data . language_environment import interact_environment
from utils . misc import convert_path
game_vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( game_vocab )
policy = UserPolicy ()
interact_environment ( env , policy )src/wordle/wordle_game.pysrc/wordle/wordle_env.pysrc/wordle/policy.pysrc/wordle/wordle_dataset.pyPara que el juego sea un MDP válido, el entorno representa el estado subyacente como un conjunto de restricciones de letras conocidas, y las utiliza para filtrar el vocabulario de palabras que cumplen con todas estas restricciones en cada turno. Luego se selecciona una palabra aleatoria de esta lista de palabras filtradas y se usa para determinar las transiciones de color devueltas por el entorno. Estas nuevas transiciones de color actualizan el conjunto de restricciones de letras conocidas.
El entorno de Wordle toma una lista de palabras. Algunas listas de palabras se dan en data/wordle/word_lists/ , pero no dude en hacer las suyas.
Las listas de palabras incluidas son:
Las listas de palabras se cargan en el entorno a través de un objeto Vocabulary como en el ejemplo anterior.
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))El vocabulario almacena no solo la lista de palabras, sino que también realiza un seguimiento de una lista filtrada de palabras que cumplen con todas las limitaciones de letras conocidas en un estado determinado. Esta lista se utiliza para calcular las transiciones en el entorno y es utilizada por algunas de las políticas hechas a mano.
Producir estas listas filtradas en tiempo real puede retrasar el proceso de interacción del entorno. Esto normalmente no debería ser un problema, pero si desea sintetizar rápidamente muchos datos de una política, entonces esto puede convertirse en un cuello de botella. Para superar esto, todos los objetos Vocabulary almacenan un argumento cache , que almacena en caché estas listas de palabras filtradas asociadas con un estado determinado. vocab.cache.load(f_path) y vocab.cache.dump() habilita la carga y guardado de este caché. Por ejemplo, data/wordle/vocab_cache_wordle_official.pkl es un caché grande para la lista de palabras wordle_official.txt.
Más allá de almacenar un caché, el objeto Vocabulary implementa los siguientes métodos en src/wordle/wordle_game.py :
__init__ def __init__ ( self , all_vocab : List [ str ],
wordle_state : Optional [ WordleState ],
cache : Optional [ Cache ] = None ,
fill_cache : bool = True ) -> NoneEntradas:
all_vocab: List[str] - Una lista de palabras.wordle_state: Optional[WordleState] : un estado desde el cual generar la lista de palabras filtradas, si no se proporciona ningún estado, no se filtran palabras.cache: Optional[Cache]=None : un caché para el vocabulario filtrado, como se describió anteriormente.fill_cache: bool=True : si se debe agregar al caché. Devoluciones: None
from_file def from_file ( cls , vocab_file : str , fill_cache : bool = True ) -> VocabularyEntradas:
vocab_file: str : un archivo desde el cual cargar las palabras. El método solo selecciona las palabras que tienen 5 letras de largo.fill_cache: bool=True : si se debe agregar al caché. Devuelos: Vocabulary
filtered_vocab_size def filtered_vocab_size ( self ) -> intDevuelve: El tamaño del vocabulario filtrado
all_vocab_size def all_vocab_size ( self ) -> intDevoluciones: El tamaño del vocabulario completo sin filtrar
get_random_word_filtered def get_random_word_filtered ( self ) -> strDevuelve: una palabra aleatoria de la lista filtrada.
get_random_word_all def get_random_word_all ( self ) -> strDevuelve: Una palabra aleatoria de la lista completa sin filtro.
update_vocab def update_vocab ( self , wordle_state : WordleState ) -> VocabularyEntradas:
wordle_state: WordleState : un objeto de estado de Wordle, que representa el conjunto de restricciones de letras conocidas. Devuelve: un nuevo objeto Vocabulary , que se filtra de acuerdo con wordle_state .
__str__ def __str__ ( self ) -> strDevuelve: una representación de cadena de la lista de palabras filtradas para imprimir en el terminal.
WordleEnvironment toma un objeto de vocabulario como entrada, que define el conjunto de posibles palabras correctas en el entorno.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( vocab )
initial_obs = env . reset ()
next_obs , reward , terminal = env . step ( "snake" ) Como se muestra arriba, el entorno implementa una interfaz de gimnasio en src/wordle/wordle_env.py :
__init__ def __init__ ( self , vocab : Vocabulary ) -> NoneEntradas:
vocab: Vocabulary : el vocabulario del medio ambiente. Devoluciones: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Entradas:
action: Vocabulary : una cadena de texto que representa la acción de un agente en el entorno.Devoluciones: una tupla (observación, recompensa, terminal).
reset def reset ( self ) -> WordleObservationDevoluciones: una observación.
is_terminal def is_terminal ( self ) -> boolDevoluciones: un booleano que indica si la interacción ha terminado.
Implementamos un conjunto de políticas de palabras hechas a mano que cubren una gama de niveles de juego. Todos estos se implementan en src/wordle/policy.py . Aquí describimos cada uno:
UserPolicy from wordle . policy import UserPolicy
policy = UserPolicy ( hint_policy = None , vocab = None )Descripción:
Vamos a jugar en la terminal.
Entradas:
hint_policy: Optional[Policy] : otra política para consultar si desea una pista sobre qué palabra usar.vocab: Optional[Union[str, Vocabulary]] - Un Vocabulary de palabras adivinables. Si no se especifica, cualquier secuencia de CHARS de 5 letras es una suposición válida. StartWordPolicy from wordle . policy import StartWordPolicy
policy = StartWordPolicy ()Descripción:
Para ser aplicado solo para la primera palabra. Selecciona una palabra al azar de una lista de palabras de inicio de alta calidad curadas.
Entradas:
start_words: Optional[List[str]]=None : anule la lista curada de palabras iniciales. OptimalPolicy from wordle . policy import OptimalPolicy
policy = OptimalPolicy ()Descripción:
Juega miopicalmente la información más alta de la información de la lista de palabras que cumple con todas las limitaciones de letras conocidas. Esta política no es realmente óptima, ya que el juego óptimo es NP-Hard. Pero juega en un nivel extremadamente alto y puede usarse como un límite superior aproximado para el rendimiento. Esta política es muy lenta para calcular, con un rendimiento cuadrático en el tamaño de la lista de palabras; Para guardar los cálculos, self.cache.load(f_path) y self.cache.dump() le permite cargar y guardar un caché. Por ejemplo, data/wordle/optimal_policy_cache_wordle_official.pkl representa un caché para esta política en la lista de palabras wordle_official.txt .
Entradas:
start_word_policy: Optional[Policy]=None : dado que la primera palabra es generalmente la más costosa para calcular la ganancia de información, esto le permite especificar una política diferente para ser convocada solo para la primera palabra.progress_bar: bool=False : dado que puede llevar tanto tiempo calcularse, le dejamos la opción de mostrar una barra de progreso para cada llamada a self.act . RepeatPolicy from wordle . policy import RepeatPolicy
policy = RepeatPolicy ( start_word_policy = None , first_n = 2 )Descripción:
Repita aleatoriamente una de las first_n palabras ya utilizadas. Esta es una política máxima subóptima, ya que nunca puede ganar a menos que tenga suerte en la primera palabra.
Entradas:
start_word_policy: Optional[Policy] : una política para usar para elegir la primera palabra. Si None , seleccione aleatoriamente una palabra del vocabulario del entorno.first_n: Optional[int] : la política selecciona aleatoriamente la siguiente palabra de las palabras first_n en el historial. Si None , entonces selecciona al azar del historial completo. RandomMixturePolicy from wordle . policy import RandomMixturePolicy
policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )Descripción:
Elige una palabra completamente al azar de una lista de palabras con probabilidad (1 - prob_smart) y elige una palabra aleatoria de la lista de palabras que cumple con todas las restricciones de letras conocidas con probabilidad prob_smart .
Entradas:
prob_smart: float : la probabilidad de seleccionar una palabra que cumpla con todas las limitaciones de letras conocidas, en lugar de una completamente al azar.vocab: Optional[Union[str, Vocabulary]] : una lista de palabras para seleccionar. Si None , la política predetermina la lista de palabras del entorno. WrongPolicy from wordle . policy import WrongPolicy
from wordle . wordle_game import Vocabulary
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
policy = WrongPolicy ( vocab )Descripción:
Elige aleatoriamente una palabra de una lista de palabras que no cumple con todas las restricciones de letras conocidas y, por lo tanto, no puede ser la palabra correcta. Si todas las palabras en la lista de palabras cumplen con las restricciones de las letras, entonces elige una palabra al azar de la lista. Esta política es altamente subóptima.
Entradas:
vocab: Union[str, Vocabulary] - Una lista de palabras para elegir. MixturePolicy from wordle . policy import MixturePolicy , OptimalPolicy , RandomMixturePolicy
policy1 = OptimalPolicy ()
policy2 = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MixturePolicy ( prob1 = 0.5 , policy1 = policy1 , policy2 = policy2 )Descripción:
Mezcla dos políticas dadas. Seleccione de policy1 con probabilidad prob1 y seleccione de policy2 con probabilidad (1 - prob1) .
Entradas:
prob1: float : la probabilidad de seleccionar una acción de policy1 .policy1: Policy : la primera política para seleccionar acciones desde. Seleccionado con probabilidad prob1 .policy1: Policy : la segunda política para seleccionar acciones de. Seleccionado con probabilidad (1 - prob1) . MonteCarloPolicy from wordle . policy import MonteCarloPolicy
sample_policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MonteCarloPolicy ( n_samples = 5 , sample_policy = sample_policy )Descripción:
Toma una política, ejecuta n_samples de despliegues de Monte Carlo en el entorno, y selecciona la siguiente acción que recibió la recompensa promedio más alta durante el proceso de implementación.
Entradas:
n_samples: int - el número de despliegos de Monte Carlo para ejecutar.sample_policy: Policy : la política para probar los despliegos de. 
Cualquiera de las políticas anteriores se puede utilizar para generar conjuntos de datos, que se pueden usar para capacitar a los agentes RL fuera de línea. Implementamos, en src/wordle/wordle_dataset.py , dos tipos de conjuntos de datos sintéticos:
wordle.wordle_dataset.WordleListDataset - Carga los juegos de Worddle desde un archivo.wordle.wordle_dataset.WordleIterableDataset - muestras de juegos de Worddle de una política determinada.WordleListDataset :Cargue un conjunto de datos de Wordle desde un archivo así:
from wordle . wordle_dataset import WordleListDataset
from data . rl_data import ConstantTokenReward
data = WordleListDataset . from_file (
file_path = 'data/wordle/expert_wordle_100k.pkl' ,
max_len = None ,
vocab = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
for i in range ( data . size ()):
item = data . get_item ( i )__init__ def __init__ ( self , items : List [ Tuple [ WordleObservation , Optional [ Dict [ str , Any ]]]], max_len : Optional [ int ], token_reward : TokenReward ) -> NoneEntradas:
items: List[Tuple[WordleObservation, Optional[Dict[str, Any]]]] - una lista de datos en forma de tuplas de (WordDEOBServation, metadata_dict). Donde metadata_dict es cualquier tipo de metadatos es cualquier tipo de metadatos que desee almacenar en el punto de datos.max_len: Optional[int] : la longitud de secuencia máxima en el conjunto de datos, truncará todas las secuencias de token a esta longitud. Si None , entonces las secuencias no se truncarán.token_reward: TokenReward : la recompensa de nivel de token para aplicar a las secuencias. Utilizamos una recompensa constante de 0 por token para todos los experimentos. Devoluciones: None
from_file def from_file ( cls , file_path : str , max_len : Optional [ int ], vocab : Optional [ Vocabulary ], token_reward : TokenReward ) -> WordleListDatasetEntradas:
file_path: str : la ruta al archivo de pepinillos de datos.max_len: Optional[int] : la longitud de secuencia máxima en el conjunto de datos, truncará todas las secuencias de token a esta longitud. Si None , entonces las secuencias no se truncarán.vocab: Optional[Vocabulary] : simule el conjunto de datos bajo un vocabulario de entorno diferente. Si None , el valor predeterminado utiliza el mismo vocabulario que se usó para crear el conjunto de datos.token_reward: TokenReward : la recompensa de nivel de token para aplicar a las secuencias. Utilizamos una recompensa constante de 0 por token para todos los experimentos. Devuelve: un objeto WordleListDataset .
get_item def get_item ( self , idx : int ) -> DataPointEntradas:
idx: int - un índice en el conjunto de datos. Devuelve: un objeto DataPoint .
size def size ( self ) -> intDevuelve: El tamaño del conjunto de datos.
Los siguientes scripts en scripts/data/wordle/ se pueden usar para sintetizar los datos de Wordle.
| guion | descripción |
|---|---|
generate_data.py | Muestra varios juegos de una política determinada especificada en la configuración y los guarda en un archivo. |
generate_data_mp.py | Lo mismo que generate_data.py , excepto los juegos de muestras en paralelo en múltiples procesos. |
generate_adversarial_data.py | Sintetiza el conjunto de datos descrito en la Sección 5 de nuestro artículo, que fue diseñado para demostrar la diferencia entre los métodos RL de un solo paso y los de múltiples pasos. |
generate_adversarial_data_mp.py | Lo mismo que generate_adversarial_data.py , excepto los juegos de muestras en paralelo en múltiples procesos. |
generate_data_branch.py | Los juegos de muestras de una política "experta" y luego de cada acción en el juego, una política "subóptima" ramifica la muestra de varios juegos nuevos. |
generate_data_branch_mp.py | Lo mismo que generate_data_branch.py , excepto los juegos de muestras en paralelo en múltiples procesos. |
Algunos conjuntos de datos de Wordle sintéticos proporcionados están en data/wordle/ .
| archivo | descripción |
|---|---|
expert_wordle_100k_1.pkl | 100k Juegos muestreados de OptimalPolicy . |
expert_wordle_100k_2.pkl | Otros 100k Juegos se muestrearon de la OptimalPolicy . |
expert_wordle_adversarial_20k.pkl | El conjunto de datos descrito en la Sección 5 de nuestro artículo, que fue diseñado para demostrar la diferencia entre los métodos RL de un solo paso y los de múltiples pasos. |
expert_wordle_branch_100k.pkl | 100k Juegos muestreados usando generate_data_branch.py de OptimalPolicy con las ramas muestreadas de WrongPolicy . |
expert_wordle_branch_150k.pkl | Otros 150k juegos muestreados usando generate_data_branch.py de OptimalPolicy con las ramas muestreadas de WrongPolicy . |
expert_wordle_branch_2k_10sub.pkl | 2K Juegos muestreados usando generate_data_branch.py de OptimalPolicy con 10 ramas por acción muestreadas de WrongPolicy , de modo que hay muchos más datos subóptimos que en expert_wordle_branch_100k.pkl . |
expert_wordle_branch_20k_10sub.pkl | Lo mismo que expert_wordle_branch_2k_10sub.pkl , excepto 20k juegos en lugar de juegos de 2k. |
WordleIterableDataset :Genere un muestreo de datos de fondos a partir de una política como así:
from wordle . wordle_dataset import WordleIterableDataset
from wordle . policy import OptimalPolicy
from data . rl_data import ConstantTokenReward
policy = OptimalPolicy ()
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
data = WordleIterableDataset (
policy = policy ,
vocab = vocab ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
while True :
item = data . sample_item ()__init__ def __init__ ( self , policy : Policy , vocab : Vocabulary , max_len : Optional [ int ], token_reward : TokenReward ) -> NoneEntradas:
policy: Policy : una política a la muestra de.vocab: Vocabulary : el vocabulario del medio ambiente.max_len: Optional[int] : la longitud de secuencia máxima en el conjunto de datos, truncará todas las secuencias de token a esta longitud. Si None , entonces las secuencias no se truncarán.token_reward: TokenReward : la recompensa de nivel de token para aplicar a las secuencias. Utilizamos una recompensa constante de 0 por token para todos los experimentos. Devoluciones: None
sample_item def sample_item ( self ) -> DataPoint Devuelve: un objeto DataPoint .
Tenemos un gran conjunto de datos de más de 200k tweets de juegos de Wordle como este:
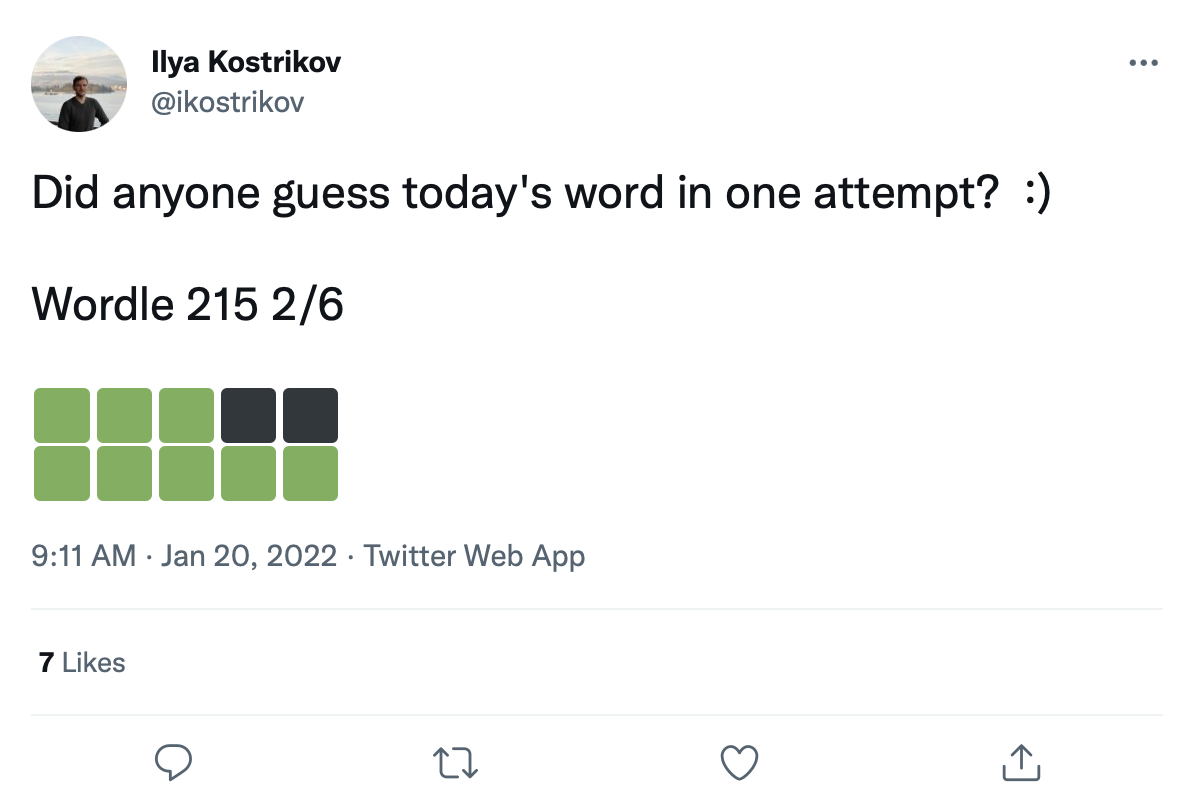
Podemos adaptar palabras en estos cuadrados de transición de color para crear un conjunto de datos real de juegos de Wordle.
Los datos de tweets sin procesar se dan en data/wordle/tweets.csv , pero para ser utilizables, las palabras reales deben adaptarse a los cuadrados de color en los tweets. Realizar este proceso de modernización requiere ejecutar un script de preprocesamiento que almacena en caché todas las transiciones de color posibles que podrían ocurrir en las listas de vocabulario: guess_vocab (un conjunto de palabras adivinables) y correct_vocab (un conjunto de posibles palabras correctas en un entorno). El resultado es una estructura de datos que wordle.wordle_dataset.WordleHumanDataset utiliza para sintetizar juegos de Wordle válidos de los tweets. Este script es scripts/data/wordle/build_human_datastructure.py . Llame al guión como:
cd scripts/data/wordle/
python build_human_datastructure.py --guess_vocab=../../../data/wordle/word_lists/wordle_official.txt --correct_vocab=../../../data/wordle/word_lists/wordle_official.txt --tweets_file=../../../data/wordle/tweets.csv --output_file=../../../data/wordle/random_human_tweet_data.jsonLos args del guión:
--guess_vocab Especifica el conjunto de palabras adivinables.--correct_vocab Especifica el conjunto de posibles palabras correctas en un entorno.--tweets_file especifica el archivo CSV sin procesar de los tweets--output_file especifica dónde volcar la salida. Hemos ejecutado el preprocesamiento en algunas de las listas de palabras, con los resultados guardados en data/wordle/ .
| lista de palabras | archivo de datos de tweet preprocesado |
|---|---|
wordle_official.txt | random_human_tweet_data.json |
wordle_official_800.txt | random_human_tweet_data_800.json |
wordle_official_400.txt | random_human_tweet_data_400.json |
wordle_official_200.txt | random_human_tweet_data_200.json |
tweet_words.txt | human_tweet_data_true_word.json |
Dado uno de estos archivos, puede cargar el conjunto de datos de Tweet de Wordle así:
from wordle . wordle_dataset import WordleHumanDataset
data = WordleHumanDataset . from_file ( 'data/wordle/random_human_tweet_data_200.json' )
print ( data . sample_item ()) Utilizamos 'data/wordle/random_human_tweet_data_200.json' en nuestros experimentos.
WordleHumanDataset : __init__ def __init__ ( self , games : List [ Tuple [ str , List [ str ]]], transitions : Dict [ str , Dict [ str , List [ str ]]], use_true_word : bool , max_len : Optional [ int ], token_reward : TokenReward , game_indexes : Optional [ List [ int ]], top_p : Optional [ float ]) -> NoneEntradas:
games: List[Tuple[str, List[str]]] - Una lista de tuplas de la forma (correct_wordle_word, wordle_transitions_list) , donde wordle_transitions_list es una lista de transiciones que indican los colores en el tweet: ["<b><b><y><y><b>", "<g><b><b><b><b>", "<g><g><y><b><b>", "<g><g><g><g><g>"] .transitions: Dict[str, Dict[str, List[str]]] - un mapeo de mapeo de la palabra correcta a otra posible transición de color de mapeo de dict que podría haber sido inducido por esa palabra a una lista de palabras que podrían haberse jugado para causar esa transición. Esta estructura de datos se utiliza para modernizar palabras en los tweets.use_true_word: bool : si True , use la palabra correcta de verdad en tierra del tweet, de lo contrario, vuelva a modificar cualquier palabra correcta en la lista de palabras que funciona.max_len: Optional[int] : la longitud de secuencia máxima en el conjunto de datos, truncará todas las secuencias de token a esta longitud. Si None , entonces las secuencias no se truncarán.token_reward: TokenReward : la recompensa de nivel de token para aplicar a las secuencias. Utilizamos una recompensa constante de 0 por token para todos los experimentos.game_indexes: Optional[List[int]] : una lista de índices para crear una división de los tweets. Si None , se utilizarán todos los elementos en los datos. Tenemos data/wordle/human_eval_idxs.json y data/wordle/human_train_idxs.json creado como divisiones de tren y evaluación seleccionadas al azar.top_p: Optional[float] : filtre para el porcentaje de realización de top_p de los datos. Si None , no se filtrarán datos. Usado con modelos %BC. Devoluciones: None
from_file def from_file ( cls , file_path : str , use_true_word : bool = False , max_len : Optional [ int ] = None , token_reward : Optional [ TokenReward ] = None , top_p : Optional [ float ] = None ) -> WordleHumanDatasetEntradas:
file_path: str : la ruta al archivo JSON para cargar los datos.use_true_word: bool : si True , use la palabra correcta de verdad en tierra del tweet, de lo contrario, vuelva a modificar cualquier palabra correcta en la lista de palabras que funciona.max_len: Optional[int] : la longitud de secuencia máxima en el conjunto de datos, truncará todas las secuencias de token a esta longitud. Si None , entonces las secuencias no se truncarán.token_reward: TokenReward : la recompensa de nivel de token para aplicar a las secuencias. Utilizamos una recompensa constante de 0 por token para todos los experimentos.game_indexes: Optional[List[int]] : una lista de índices para crear una división de los tweets. Si None , se utilizarán todos los elementos en los datos. Tenemos data/wordle/human_eval_idxs.json y data/wordle/human_train_idxs.json creado como divisiones de tren y evaluación seleccionadas al azar.top_p: Optional[float] : filtre para el porcentaje de realización de top_p de los datos. Si None , no se filtrarán datos. Usado con modelos %BC. Devuelve: un objeto WordleHumanDataset .
sample_item def sample_item ( self ) -> DataPoint Devuelve: un objeto DataPoint .
Los guiones de entrenamiento están en scripts/train/wordle/ .
| guion | descripción |
|---|---|
train_bc.py | Capacitar a un agente de BC. |
train_iql.py | Entrena a un agente de ILQL. |
Los scripts de evaluación están en scripts/eval/wordle/ .
| guion | descripción |
|---|---|
eval_policy.py | Evalúe un agente BC o ILQL en el entorno de Wordle. |
eval_q_rank.py | Un script de evaluación para comparar el rango relativo de valores de Q para agentes entrenados en el conjunto de datos sintético descrito en la Sección 5 de nuestro documento, que fue diseñado para demostrar una diferencia entre RL de un solo paso y RL de múltiples pasos. |
distill_policy_eval.py | Imprime el resultado de eval_policy.py con barras de error. |
Aquí describimos cómo cargar los datos de diálogo visual en nuestra base de código y cómo ejecutar el entorno. Consulte la sección Configuración anterior para configurar los componentes remotos del entorno de diálogo visual. Los objetos de datos y entorno están cargados automáticamente por el administrador de configuración, pero si desea pasar el sistema de configuración y usar el entorno con su propia base de código, así es como debe cargar, ejecutar y configurar estos objetos. Las mismas configuraciones descritas a continuación también se pueden modificar en las configuraciones.
Un ejemplo de cómo cargar el entorno de diálogo visual:
from visdial . visdial_env import VDEnvironment
from visdial . visdial_base import VisDialogueData
from visdial . visdial_dataset import VisDialListDataset
from data . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = VisDialogueData (
data_path = convert_path ( 'data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.json' ),
img_feat_path = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/data_img.h5' ),
split = 'train' ,
reward_cache = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/train_rank_reward_cache1.json' ),
yn_reward_kind = 'none'
)
list_data = VisDialListDataset (
data = data ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 )
)
env = VDEnvironment (
dataset = list_data ,
url = 'http://localhost:5000/step_rank' ,
yn_reward = - 2.0 ,
yn_reward_kind = 'none'
)
print ( env . reset ()) El script anterior corresponde a cómo configuramos el conjunto de datos y el entorno para nuestros experimentos de recompensa 'estándar', pero si desea configurar el conjunto de datos de manera diferente, hay muchos argumentos que puede modificar. Más allá de simplemente cambiar la división del conjunto de datos, estos argumentos también pueden cambiar la tarea o la recompensa. A continuación describimos todos los diferentes parámetros configurables que se toman VisDialogueData , VisDialListDataset y VDEnvironment .
Documentamos los parámetros y métodos para VisDialogueData , VisDialListDataset y VDEnvironment , para que sepa cómo configurar el entorno usted mismo.
VisDialogueData : VisDialogueData , implementado en src/visdial/visdial_base.py , almacena el conjunto de diálogos y recompensas de la tarea.
__init__ def __init__ ( self , data_path : str , img_feat_path : str , split : str , reward_cache : Optional [ str ] = None , norm_img_feats : bool = True , reward_shift : float = 0.0 , reward_scale : float = 1.0 , addition_scenes : Optional [ List [ Scene ]] = None , mode : str = 'env_stops' , cutoff_rule : Optional [ CutoffRule ] = None , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneEntradas:
data_path: str : la ruta a los datos del diálogo. Debería ser uno de:data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_val.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_test.jsonimg_feat_path: str - La ruta a las características de la imagen utilizadas para calcular la recompensa para cada diálogo. Siempre debe ser data/vis_dialogue/processed/visdial_0.5/data_img.h5 .split: str - Uno de train , val o test . Indica qué división del conjunto de datos de las características de la imagen usar. Debe ser consistente con la división data_path .reward_cache: Optional[str]=None - donde se almacenan las recompensas para cada diálogo. Si None , establecerá todas las recompensas a None . Proporcionamos cachés para dos funciones de recompensa:data/vis_dialogue/processed/visdial_0.5/[split]_rank_reward_cache1.json , donde [split] se reemplaza por uno de train , val o test .data/vis_dialogue/processed/visdial_0.5/[split]_reward_cache2.json , donde [split] se reemplaza por uno de train , val o test .norm_img_feats: bool=True : si normalizar las características de la imagen.reward_shift: float=0.0 - Cambie la recompensa por esta cantidad.reward_scale: float=1.0 - Escala la recompensa por esta cantidad.addition_scenes: Optional[List[Scene]]=None - inyectar datos adicionales en el conjunto de datos.mode: str='env_stops' - uno de ['agent_stops', 'env_stops', '10_stop'] . Controla algunas propiedades de la tarea. Usamos env_stopsmode='env_stops' , entonces detenga la interacción del entorno temprano de acuerdo con cutoff_rule .mode='agent_stops' , entonces el agente detiene la interacción generando un token especial <stop> durante su acción; aumenta los datos colocando un <stop> después de cada acción posible.mode='10_stop' , la reproducción siempre se detiene después de 10 rondas de interacción, como es estándar en el conjunto de datos de diálogo visual.cutoff_rule: Optional[CutoffRule]=None - Solo se aplica si mode='env_stops' . Implementa una función que determina cuándo el entorno debe detener la interacción temprano. Utilizamos el valor predeterminado de visdial.visdial_base.PercentileCutoffRule(1.0, 0.5) en todos nuestros experimentos.yn_reward: float=-2.0 -La penalización de recompensa que debe agregarse por hacer preguntas de sí/no.yn_reward_kind: str='none' - Especifica la heurística de la coincidencia de cadenas que se utilizará para determinar si se hizo una pregunta sí/no. Debería ser uno de ['none', 'soft', 'hard', 'conservative'] .'none' : no penalices en las preguntas de sí/no. Esto corresponde a la recompensa standard en nuestro artículo.'soft' : penaliza una pregunta si la respuesta contiene "yes" o "no" como subcadena.'hard' : penaliza una pregunta si la respuesta coincide exactamente con la cadena "yes" o "no" . Esto corresponde a la recompensa "y/n" en nuestro artículo.'conservative' : penaliza una pregunta si la respuesta satisface una de varias heurísticas de coincidencia de cadenas. Esto corresponde a la recompensa "conservative y/n" en nuestro artículo. Devoluciones: None
__len__ def __len__ ( self ) -> intDevuelve: El tamaño del conjunto de datos.
__getitem__ def __getitem__ ( self , i : int ) -> SceneEntradas:
i: int - el índice del conjunto de datos.Devuelve: un elemento del conjunto de datos.
VisDialListDataset : VisDialListDataset , implementado en src/visdial/visdial_dataset.py , envuelve VisDialogueData y lo convierte en un formato DataPoint que se puede usar para entrenar a los agentes RL fuera de línea.
__init__ def __init__ ( self , data : VisDialogueData , max_len : Optional [ int ], token_reward : TokenReward , top_p : Optional [ float ] = None , bottom_p : Optional [ float ] = None ) -> NoneEntradas:
data: VisDialogueData : un objeto de datos de diálogo visual que almacena todos los datos sin procesar.max_len: Optional[int] : la longitud de secuencia máxima en el conjunto de datos, truncará todas las secuencias de token a esta longitud. Si None , entonces las secuencias no se truncarán.token_reward: TokenReward : la recompensa de nivel de token para aplicar a las secuencias. Utilizamos una recompensa constante de 0 por token para todos los experimentos.top_p: Optional[float] : filtre para el porcentaje de realización de top_p de los datos. Si None , no se filtrarán datos. Usado con modelos %BC.bottom_p: Optional[float] : filtre para el porcentaje de realización de bottom_p de los datos. Si None , no se filtrarán datos. Devoluciones: None
size def size ( self ) -> intDevuelve: El tamaño del conjunto de datos.
get_item def get_item ( self , idx : int ) -> DataPointEntradas:
i: int - el índice del conjunto de datos. Devuelve: un DataPoint del conjunto de datos.
VDEnvironment : VDEnvironment , implementado en src/visdial/visdial_env.py , define el entorno de diálogo visual, con el que nuestros agentes RL fuera de línea interactúan en el momento de la evaluación. El entorno implica conectarse a un servidor localhost, que la sección de configuración describe cómo girar.
__init__ def __init__ ( self , dataset : RL_Dataset , url : str , reward_shift : float = 0.0 , reward_scale : float = 1.0 , actor_stop : bool = False , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneEntradas:
dataset: RL_Dataset - Toma un RL_Dataset ; Específicamente VisDialListDataset , como arriba. Este conjunto de datos se utiliza para seleccionar estados iniciales.url: str - La URL para pisar el medio ambiente. Siga las instrucciones en la sección Configuración sobre cómo inicializar el servidor web LocalHost correspondiente a esta URL.reward_shift: float=0.0 - Cambie la recompensa por esta cantidad.reward_scale: float=1.0 - Escala la recompensa por esta cantidad.actor_stop: bool=False : permita que el actor detenga la interacción temprano generando un token especial <stop> .yn_reward: float=-2.0 -La penalización de recompensa que debe agregarse por hacer preguntas de sí/no.yn_reward_kind: str='none' - Especifica la heurística de la coincidencia de cadenas que se utilizará para determinar si se hizo una pregunta sí/no. Debería ser uno de ['none', 'soft', 'hard', 'conservative'] .'none' : no penalices en las preguntas de sí/no. Esto corresponde a la recompensa standard en nuestro artículo.'soft' : penaliza una pregunta si la respuesta contiene "yes" o "no" como subcadena.'hard' : penaliza una pregunta si la respuesta coincide exactamente con la cadena "yes" o "no" . Esto corresponde a la recompensa "y/n" en nuestro artículo.'conservative' : penaliza una pregunta si la respuesta satisface una de varias heurísticas de coincidencia de cadenas. Esto corresponde a la recompensa "conservative y/n" en nuestro artículo. Devoluciones: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Entradas:
action: Vocabulary - El vocabulario del medio ambienteDevoluciones: una tupla (observación, recompensa, terminal).
reset def reset ( self ) -> WordleObservationDevoluciones: una observación
is_terminal def is_terminal ( self ) -> boolDevoluciones: un booleano que indica si la interacción ha terminado.
Los scripts de entrenamiento están en scripts/train/vis_dial/ .
| guion | descripción |
|---|---|
train_bc.py | Capacitar a un agente de BC. |
train_chai.py | Entrena a un agente chai. |
train_cql.py | Entrena a un agente de CQL. |
train_dt.py | Entrena a un agente de transformador de decisión. |
train_iql.py | Entrena a un agente de ILQL. |
train_psi.py | Entrenar un |
train_utterance.py | Entrena a un agente de ILQL de nivel de expresión. |
Los scripts de evaluación están en scripts/eval/vis_dial/ .
| guion | descripción |
|---|---|
eval_policy.py | Evaluar un agente en el entorno de diálogo visual. |
top_advantage.py | Encuentra las preguntas que tienen la mayor y más pequeña ventaja bajo el modelo. |
distill_policy_eval.py | Imprime el resultado de eval_policy.py con barras de error. |
Here we outline how to load the Reddit comments data in our codebase and how to execute the environment. See the setup section above for how to setup the toxicity filter reward. The data and environment objects are loaded automatically by the config manager, but if you want to by-pass the config system and use the task with your own codebase, here's how you should load, execute, and configure these objects. The same settings described below can all be modified in the configs as well.
An example of how to load the Reddit comment environment:
from toxicity . toxicity_env import ToxicityEnvironment
from toxicity . reddit_comments_base import RedditData
from toxicity . reward_fs import toxicity_reward
from utils . misc import convert_path
idxs = json . load ( open ( convert_path ( 'data/reddit_comments/train_idxs.json' ), 'r' ))
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = idxs ,
reward_f = toxicity_reward
)
env = ToxicityEnvironment (
data = data ,
reward_f = toxicity_reward
)
print ( env . reset ())
The above script corresponds to how we configured the environment for our toxicity reward experiments, but if you want to configure the environment differently, there are a few arguments you can modify. These arguments can also change the task or reward. Below we describe all the different configurable parameters that our reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment take.
We document the parameters and methods for our different Reddit comment reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment , so that you know how to configure the environment yourself.
Here we outline the 4 main reward functions we use for our Reddit comment task. Each of these rewards is implemented in src/toxicity/reward_fs.py .
toxicity_reward from toxicity . reward_fs import toxicity_reward
reward_f = toxicity_reward ()Descripción:
The "toxicity" reward from our paper, which queries the GPT-3 toxicity filter. It assigns a value of "0" to non-toxic comments, a value of "1" to moderately toxic comments, and a value of "2" to very toxic comments.
toxicity_noised_reward from toxicity . reward_fs import toxicity_noised_reward
reward_f = toxicity_noised_reward ()Descripción:
The "noised toxicity" reward from our paper, which is the same as toxicity_noised_reward but induces additional noise. Specifically, it re-assigns comments labeled as "1" (moderately toxic) to either "0" (non-toxic) or "2" (extremely toxic) with equal probability.
score_human_reward from toxicity . reward_fs import score_human_reward
from utils . misc import convert_path
reward_f = score_human_reward (
reddit_path = convert_path ( 'data/reddit_comments/' ),
indexes = None
)Descripción:
The "upvotes real" reward from our paper, which gives a reward of +1 for positive upvote comments and -1 for negative upvote comments. This uses the ground truth upvotes in the data, so it only applies to comments in the dataset and cannot be used for evaluation. If you input a string not present in the data, it will error. The arguments to this function specify what data to load.
Inputs:
reddit_path: str – a path to the data.indexes: List[int] – a split of indexes in the data to use. If None , it considers all the data. model_reward from toxicity . reward_fs import score_human_reward
from toxicity . reddit_comments_base import RedditData
from toxicity . toxicity_dataset import ToxicityListDataset
from toxicity . reward_model import RobertaBinaryRewardModel
from utils . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = None ,
reward_f = None
)
listdata = ToxicityListDataset (
data = data ,
max_len = 512 ,
token_reward = ConstantTokenReward ( 0.0 )
)
model = RobertaBinaryRewardModel (
data = listdata ,
device = 'cuda' ,
roberta_kind = 'roberta-base' ,
freeze_roberta = False ,
reward_cuttoff = 0.0
)
model . load_state_dict ( torch . load ( convert_path ( 'outputs/toxicity/upvote_reward/model.pkl' ), map_location = 'cpu' ))
reward_f = score_human_reward ( model = model )Descripción:
The "upvotes model" reward from our paper, which gives a reward of +1 if the given model predicts that the comment will get a positive number of upvotes and a reward of -1 otherwise. The model checkpoint we used for our experiments is at: outputs/toxicity/upvote_reward/model.pkl
Inputs:
model: RewardModel : the reward model implemented in src/toxicity/reward_model.py . The model should be first trained and loaded from a pytorch checkpoint.RedditData : RedditData , implemented in src/toxicity/reddit_comments_base.py , stores the raw Reddit comments data.
__init__ def __init__ ( self , path : str , indexes : Optional [ List [ int ]], reward_f : Optional [ Callable [[ str ], float ]], reward_cache : Optional [ Cache ] = None , reward_shift : float = 0.0 , reward_scale : float = 1.0 ) -> NoneInputs:
path: str – the path to the Reddit data.indexes: Optional[List[int]] – a list of indexes to create a split of the data. Randomly selected, training, validation, and test splits are in the json files:data/reddit_comments/train_idxs.jsondata/reddit_comments/eval_idxs.jsondata/reddit_comments/test_idxs.jsonreward_f: Optional[Callable[[str], float]] – the reward function to use.reward_cache: Optional[Cache]=None – a cache of reward values, so you don't have to recompute them everytime.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount. Returns: None
__len__ def __len__ ( self ) -> intReturns: the size of the dataset.
__getitem__ def __getitem__ ( self , idx : int ) -> SceneInputs:
idx: int – the dataset index.Returns: an item from the dataset.
ToxicityListDataset : ToxicityListDataset , implemented in src/toxicity/toxicity_dataset.py , wraps around RedditData and converts it into a DataPoint format that can be used to train offline RL agents.
__init__ def __init__ ( self , data : RedditData , max_len : Optional [ int ], token_reward : TokenReward , cuttoff : Optional [ float ] = None , resample_timeout : float = 0.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – a Reddit comment data object that stores all the raw data.max_len: Optional[int] – the maximum sequence length in the dataset, will truncate all token sequences to this length. If None , then sequences will not be truncated.token_reward: TokenReward – the token-level reward to apply to the sequences. We use a constant reward of 0 per-token for all experiments.cuttoff: Optional[float]=None – filter out all comments from the dataset with reward less than cuttoff . If None , no data will be filtered. Used with %BC models.resample_timeout: float=0.0 – when cuttoff is not equal to None , comments are stochastically sampled iid from the dataset, like an iterable, even though the dataset has a list-type interface. It uniformly re-samples from the dataset until it finds a comment with a reward that satisfies the cuttoff. In the case of the "toxicity" reward, this re-sampling can cause rate-limit errors on the GPT-3 API, so we allow you to add a resample_timeout to fix this issue: a timeout of roughly 0.05 should fix rate-limit issues.include_parent: bool=True – whether to condition on the parent comment in the thread. If False , models will be trained to generate comments unconditionally. Returns: None
size def size ( self ) -> intReturns: the size of the dataset.
get_item def get_item ( self , idx : int ) -> DataPointInputs:
i: int – the dataset index. Returns: a DataPoint from the dataset.
ToxicityEnvironment : ToxicityEnvironment , implemented in src/toxicity/toxicity_env.py , defines the Reddit comment generation environment, which our offline RL agents interact with at evaluation time.
__init__ def __init__ ( self , data : RedditData , reward_f : Optional [ Callable [[ str ], float ]], reward_shift : float = 0.0 , reward_scale : float = 1.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – the dataset used to select initial state parent comments to condition on.reward_f: Optional[Callable[[str], float]] – the reward function to use.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount.include_parent: bool=True – specifies whether to condition on the previous comment or post in the Reddit thread. Returns: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Inputs:
action: Vocabulary – the environment's vocabularyReturns: an (observation, reward, terminal) tuple.
reset def reset ( self ) -> WordleObservationReturns: an observation
is_terminal def is_terminal ( self ) -> boolReturns: a boolean indicating if the interaction has terminated.
Training scripts are in scripts/train/toxicity/ .
| guion | descripción |
|---|---|
train_bc.py | Train a BC agent. |
train_iql.py | Train an ILQL agent. |
train_upvote_reward.py | Train the upvote reward model. |
Evaluation scripts are in scripts/eval/toxicity/ .
| guion | descripción |
|---|---|
eval_policy.py | Evaluate an agent in the Reddit comments environment. |
distill_policy_eval.py | Prints out the result of eval_policy.py with error bars. |
All tasks – Wordle, Visual Dialogue, Reddit – have a corresponding environment and dataset implemented in the codebase, as described above. And all offline RL algorithms in the codebase are trained, executed, and evaluated on one of these given environments and datasets.
You can similarly define your own tasks that can easily be run on all these offline RL algorithms. This codebase implements a simple set of RL environment abstractions that make it possible to define your own environments and datasets that can plug-and-play with any of the offline RL algorithms.
All of the core abstractions are defined in src/data/ . Here we outline what needs to be implemented in order to create your own tasks. For examples, see the implementations in src/wordle/ , src/vis_dial/ , and src/toxicity/ .
All tasks must implement subclasses of: Language_Observation and Language_Environment , which are in src/data/language_environment.py .
Language_Observation :This class represents the observations from the environment that will be input to your language model.
A Language_Observation must define the following two functions.
to_sequence def to_sequence ( self ) -> Tuple [ List [ str , Optional [ float ]], bool ]:Descripción:
A function which converts the observation object into a standard format that can be input to the language model and used for training.
Devoluciones:
__str__ def __str__ ( self ) -> str :Descripción:
This is only used to print the observation to the terminal. It should convert the observation into some kind of string that is interpretable by a user.
Returns: a string.
Language_Environment :This class represents a gym-style environment for online interaction, which is only used for evaluation.
A Language_Environment must define the following three functions.
step def step ( self , action : str ) -> Tuple [ Language_Observation , float , bool ]:Descripción:
Just like a standard gym environment, given an action in the form of a string, step the environment forward.
Returns: a tuple of (Language_Observation, reward, terminal).
reset def reset ( self ) -> Language_Observation :Descripción:
This resets the environment to an initial state.
Returns: the corresponding initial Language_Observation
is_terminal def is_terminal ( self ) -> bool :Descripción:
Outputs whether the environment has reached a terminal state.
Returns: a boolean indicating if the environment has reached a terminal state.
All tasks must implement subclasses of either List_RL_Dataset or Iterable_RL_Dataset or both, which are defined in src/data/rl_data.py .
List_RL_Dataset :This class represents a list dataset (or an indexable dataset of finite length) that can be used to train offline RL agents.
A List_RL_Dataset must define the following two functions.
get_item def get_item ( self , idx : int ) -> DataPointDescripción:
This gets an item from the dataset at a given index.
Returns: a DataPoint object from the dataset.
size def size ( self ) -> intDescripción:
Returns the size of the dataset.
Returns: the dataset's size.
Iterable_RL_Dataset :This class represents an iterable dataset (or a non-indexable dataset that stochastically samples datapoints iid) that can be used to train offline RL agents.
A Iterable_RL_Dataset must define the following function.
sample_item def sample_item ( self ) -> DataPointDescripción:
Samples a datapoint from the dataset.
Returns: a DataPoint object from the dataset.


