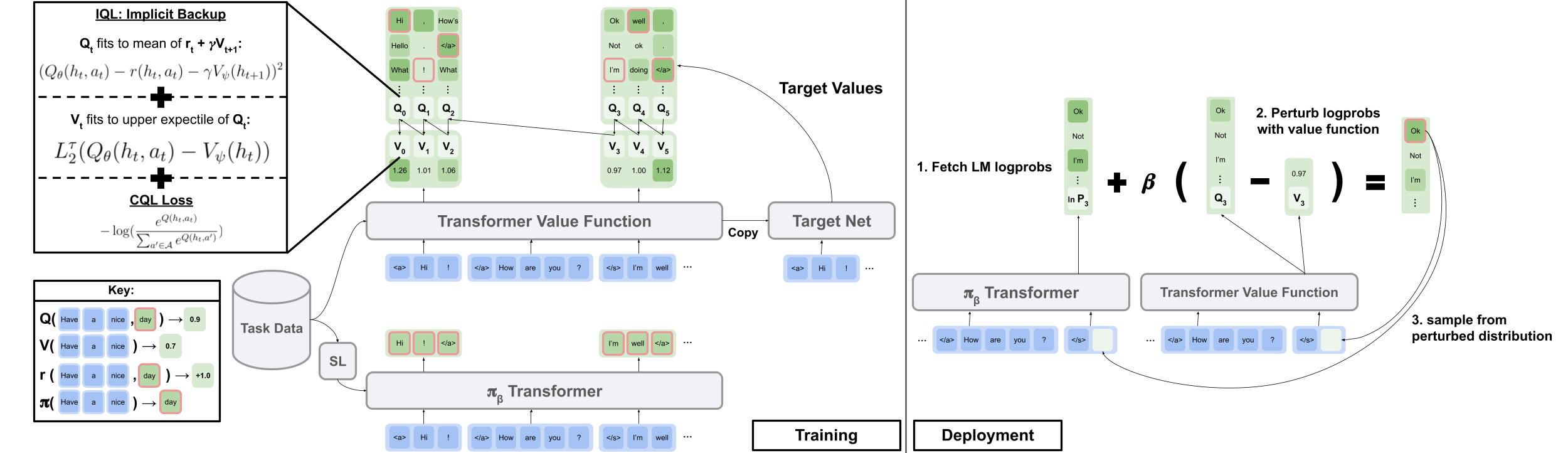
Implicit Language Q Learning
1.0.0
Code officiel de l'article "Offline RL pour la génération de langage naturel avec un langage implicite Q Apprentissage"
site du projet | arxiv
Téléchargez data.zip et outputs.zip à partir du dossier Google Drive ici. Placez les dossiers téléchargés et dézippés, data/ et outputs/ , à la racine du dépôt. data/ Contient les données prétraitées pour toutes nos tâches, et outputs/ contient le point de contrôle de notre récompense Reddit Commentaires sur les commentaires.
Ce repo a été conçu pour Python 3.9.7
pip install -r requirements.txt
export PYTHONPATH= " $PWD /src/ "Pour exécuter les expériences de dialogue visuel, vous devez servir l'environnement de dialogue visuel sur localhost en suivant les instructions ici.
Pour exécuter les expériences de commentaires Reddit avec la récompense du filtre de toxicité:
export OPENAI_API_KEY=your_API_key scripts/ contient tous les scripts de l'expérience. Pour exécuter n'importe quel script dans scripts/ :
python script_name.pyFacultatif:
python script_name.py eval.bsize=5 train.lr=1e-6 wandb.use_wandb=falsepython -m torch.distributed.launch --nproc_per_node [N_GPUs] --use_env script_name.py arg1=a arg2=b Par défaut, tous les scripts de formation se connectent à WANDB. Pour désactiver, définissez wandb.use_wandb=false dans la configuration de formation.
Ici, je décris un flux de travail recommandé pour la formation d'agents RL hors ligne. Supposons que je souhaite former un tas de différents agents RL hors ligne pour générer des commentaires Reddit avec la récompense de toxicité.
Je formerais d'abord un modèle de la Colombie-Britannique sur les données:
cd scripts/train/toxicity/
python train_bc.pyConvertissez ensuite ce point de contrôle BC en un seul compatible avec les modèles RL hors ligne:
cd ../data/
python convert_bc.py --load ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model.pkl --save ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model_converted.pklEnsuite, modifiez le point de contrôle avec lequel RL hors ligne est configuré pour s'entraîner avec:
cd ../train/
python train_iql.py model.load.checkpoint_path=outputs/toxicity/model_converted.pkl model.load.strict_load=false train.loss.awac_weight=0.0 Ceci n'est cependant qu'un flux de travail, vous pouvez également former le modèle BC en même temps que l'agent RL hors ligne en définissant train.loss.awac_weight=1.0 dans la configuration de formation.
data/ dossiers.scripts/ contient tous les scripts pour l'exécution de la formation, de l'évaluation et des étapes de prétraitement des données dans le document. Les scripts sont organisés en sous-dossiers correspondant à l'ensemble de données utilisé.config/ contient .yaml configs pour chaque script. Ce repo utilise HYDRA pour gérer les configurations. Les configurations sont organisées en sous-dossiers correspondant à l'ensemble de données utilisé. La plupart des fichiers de configuration sont nommés les mêmes que leur script correspondant, mais si vous ne savez pas quelle configorat correspond à un script, vérifiez la ligne @hydra.main(config_path="some_path", config_name="some_name") pour voir à quel fichier de configuration correspond au script.src/ contient toutes les implémentations de base. Voir src/models/ pour toutes les implémentations du modèle. Voir src/data/ pour tous les données de données de base et le code d'abstraction MDP. Voir src/utils/ pour diverses fonctions utilitaires. Voir src/wordle/ , src/visdial et src/toxicity/ for All Wordle, Visual Dialogue et Reddit Commentaire Code spécifique de l'ensemble de données.ILQL est appelé iql tout au long du dépôt. Chaque script est associé à un fichier de configuration. Le fichier de configuration spécifie quels modèles, ensemble de données et évaluateurs doivent être chargés par le script et leurs hyperparamètres correspondants. Voir configs/toxicity/train_iql.yaml pour un exemple.
Chaque modèle, ensemble de données ou objet d'évaluateur possible reçoit son propre fichier de configuration, qui spécifie les valeurs par défaut pour cet objet et un attribut name spécial, qui indique au gestionnaire de configuration quelle classe charger. Voir configs/toxicity/model/per_token_iql.yaml pour un exemple.
Les fichiers src/load_objects.py , src/wordle/load_objects.py , src/visdial/load_objects.py et src/toxicity/load_objects.py définissent comment chaque objet est chargé à partir de sa configuration correspondante. La balise @register('name') au-dessus de chaque fonction de chargement de l'objet se lie à l'attribut name dans la configuration.
Vous pouvez remarquer un attribut cache_id spécial associé à certains objets dans une configuration. Pour un exemple, voir train_dataset dans configs/toxicity/train_iql.yaml . Cet attribut indique au gestionnaire de configuration de mettre en cache le premier objet qu'il charge qui est associé à cet ID, puis de renvoyer cet objet mis en cache pour des configurations d'objet ultérieures avec ce cache_id .
Pour toutes les configurations, utilisez des chemins par rapport à la racine du référentiel.
Chacune des tâches de notre référentiel - Wordle, Dialogue visuel et commentaires Reddit - met en œuvre quelques classes de base. Une fois implémenté, tous les algorithmes RL hors ligne peuvent être appliqués à la tâche de manière plug-and-play. Voir la section "Créer vos propres tâches" pour un aperçu de ce qui devrait être mis en œuvre afin de créer vos propres tâches. Ci-dessous, nous décrivons les abstractions clés qui rendent cela possible.
data.language_environment.Language_Environment - représente un environnement de pomdp de tâche, avec lequel une politique peut interagir. Il a une interface de type gymnase.data.language_environment.Policy - représente une politique qui peut interagir avec un environnement. Chacun des algorithmes RL hors ligne dans src/models/ a une politique correspondante.data.language_environment.Language_Observation - représente une observation de texte qui est renvoyée par l'environnement et donnée comme entrée à une politique.data.language_environment.interact_environment - une fonction qui prend un environnement, une politique et éventuellement l'observation actuelle et exécute une boucle d'interaction environnement. Si l'observation actuelle n'est pas fournie, elle récupère automatiquement un état initial en réinitialisant l'environnement.data.rl_data.DataPoint - définit un format de données standardisé qui est alimenté en entrée à tous les agents RL hors ligne sur toutes les tâches. Ces structures de données sont créées automatiquement à partir d'une Language_Observation .data.rl_data.TokenReward - définit une fonction de récompense donnée à chaque jeton, qui peut être utilisé pour apprendre un contrôle au grain plus fin. Ceci est fourni en plus de la récompense de l'environnement, qui ne vient pas à chaque jeton mais plutôt après chaque tour d'interaction. Dans toutes nos expériences, nous définissons cette récompense sur une constante 0, de sorte qu'elle n'a aucun effet.data.tokenizer.Tokenizer - Spécifie comment convertir les chaînes vers et à partir de séquences de jetons qui peuvent ensuite être alimentés en entrée aux modèles de langue.data.rl_data.RL_Dataset - Définit un objet de jeu de données qui renvoie les objets DataPoint et est utilisé pour la formation d'agents RL hors ligne. Il existe deux versions de RL_Dataset :List_RL_DatasetIterable_RL_Dataset
Ici, nous décrivons et documentons toutes les composantes de notre tâche de lot.
Une grande partie de ce qui est dans l'exemple des scripts se fait automatiquement par le gestionnaire de configuration, et les paramètres correspondants peuvent être modifiés en modifiant les configurations. Mais si vous souhaitez contourner l'utilisation des configurations et utiliser la tâche de lot avec votre propre base de code, vous pouvez référencer les scripts et la documentation ci-dessous pour comment procéder.
Un exemple simple de script pour jouer à Bordle dans la ligne de commande.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from wordle . policy import UserPolicy
from data . language_environment import interact_environment
from utils . misc import convert_path
game_vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( game_vocab )
policy = UserPolicy ()
interact_environment ( env , policy )src/wordle/wordle_game.pysrc/wordle/wordle_env.pysrc/wordle/policy.pysrc/wordle/wordle_dataset.pyPour faire du jeu un MDP valide, l'environnement représente l'état sous-jacent comme un ensemble de contraintes de lettres connues et les utilise pour filtrer le vocabulaire des mots qui répondent à toutes ces contraintes à chaque tour. Un mot aléatoire est ensuite sélectionné dans cette liste de mots filtrés et utilisé pour déterminer les transitions de couleur renvoyées par l'environnement. Ces nouvelles transitions de couleurs mettent ensuite à jour l'ensemble des contraintes de lettres connues.
L'environnement de lot prend une liste de mots. Quelques listes de mots sont données dans data/wordle/word_lists/ , mais n'hésitez pas à faire la vôtre.
Les listes de mots incluses sont:
Les listes de mots sont chargées dans l'environnement via un objet Vocabulary comme dans l'exemple ci-dessus.
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))Le vocabulaire stocke non seulement la liste des mots, mais garde également une trace d'une liste filtrée de mots qui répondent à toutes les contraintes de lettres connues dans un état donné. Cette liste est utilisée pour calculer les transitions dans l'environnement et est utilisée par certaines des politiques fabriquées à la main.
La production de ces listes filtrées en temps réel peut ralentir le processus d'interaction de l'environnement. Cela ne devrait normalement pas être un problème, mais si vous souhaitez synthétiser rapidement de nombreuses données d'une politique, cela peut devenir un goulot d'étranglement. Pour surmonter cela, tous les objets Vocabulary stockent un argument cache , qui cache ces listes de mots filtrées associées à un état donné. vocab.cache.load(f_path) et vocab.cache.dump() permet de charger et d'enregistrer ce cache. Par exemple, data/wordle/vocab_cache_wordle_official.pkl est un grand cache pour la liste de mots wordle_official.txt.
Au-delà du stockage d'un cache, l'objet Vocabulary implémente les méthodes suivantes dans src/wordle/wordle_game.py :
__init__ def __init__ ( self , all_vocab : List [ str ],
wordle_state : Optional [ WordleState ],
cache : Optional [ Cache ] = None ,
fill_cache : bool = True ) -> NoneEntrées:
all_vocab: List[str] - une liste de mots.wordle_state: Optional[WordleState] - un état à partir de laquelle générer la liste des mots filtrés, si aucun état n'est fourni, aucun mot n'est filtré.cache: Optional[Cache]=None - Un cache pour le vocabulaire filtré, comme décrit ci-dessus.fill_cache: bool=True - s'il faut ajouter au cache. Renvoie: None
from_file def from_file ( cls , vocab_file : str , fill_cache : bool = True ) -> VocabularyEntrées:
vocab_file: str - un fichier à partir duquel charger les mots. La méthode sélectionne uniquement les mots de 5 lettres.fill_cache: bool=True - s'il faut ajouter au cache. Renvoie: Vocabulary
filtered_vocab_size def filtered_vocab_size ( self ) -> intRetours: la taille du vocabulaire filtré
all_vocab_size def all_vocab_size ( self ) -> intRetour: la taille du vocabulaire complet non filtré
get_random_word_filtered def get_random_word_filtered ( self ) -> strRenvoie: un mot aléatoire de la liste filtrée.
get_random_word_all def get_random_word_all ( self ) -> strRenvoie: un mot aléatoire de la liste complète non filtrée.
update_vocab def update_vocab ( self , wordle_state : WordleState ) -> VocabularyEntrées:
wordle_state: WordleState - un objet d'état Wordle, représentant l'ensemble des contraintes de lettres connues. Renvoie: un nouvel objet Vocabulary , qui est filtré selon wordle_state .
__str__ def __str__ ( self ) -> strRenvoie: une représentation de chaîne de la liste des mots filtrés pour l'impression au terminal.
WordleEnvironment prend un objet de vocabulaire en entrée, qui définit l'ensemble des mots corrects possibles dans l'environnement.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( vocab )
initial_obs = env . reset ()
next_obs , reward , terminal = env . step ( "snake" ) Comme indiqué ci-dessus, l'environnement met en œuvre une interface de type gymnase dans src/wordle/wordle_env.py :
__init__ def __init__ ( self , vocab : Vocabulary ) -> NoneEntrées:
vocab: Vocabulary - Le vocabulaire de l'environnement. Renvoie: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Entrées:
action: Vocabulary - Une série de texte représentant l'action d'un agent dans l'environnement.Renvoie: un tuple (observation, récompense, terminal).
reset def reset ( self ) -> WordleObservationRenvoie: une observation.
is_terminal def is_terminal ( self ) -> boolRenvoie: un booléen indiquant si l'interaction s'est terminée.
Nous mettons en œuvre un ensemble de politiques de lands réalisées à la main qui couvrent une gamme de niveaux de gameplay. Tous ces éléments sont mis en œuvre dans src/wordle/policy.py . Ici, nous décrivons chacun:
UserPolicy from wordle . policy import UserPolicy
policy = UserPolicy ( hint_policy = None , vocab = None )Description:
Vous jouez dans le terminal.
Entrées:
hint_policy: Optional[Policy] - une autre politique pour interroger si vous voulez un indice sur quel mot utiliser.vocab: Optional[Union[str, Vocabulary]] - Un Vocabulary de mots supposables. S'il n'est pas spécifié, une séquence de caractères de 5 lettres est une supposition valide. StartWordPolicy from wordle . policy import StartWordPolicy
policy = StartWordPolicy ()Description:
À appliquer uniquement pour le premier mot. Sélectionne un mot au hasard dans une liste de mots de démarrage organisés et de haute qualité.
Entrées:
start_words: Optional[List[str]]=None - remplacer la liste organisée des mots de démarrage. OptimalPolicy from wordle . policy import OptimalPolicy
policy = OptimalPolicy ()Description:
Myopes joue le mot à gain d'informations le plus élevé de la liste des mots qui répond à toutes les contraintes de lettres connues. Cette politique n'est pas réellement optimale, car le jeu optimal est NP-Dury. Mais il joue à un niveau extrêmement élevé et peut être utilisé comme une limite supérieure approximative pour les performances. Cette politique est très lente à calculer, avec des performances quadratiques dans la taille de la liste des mots; Pour enregistrer les calculs, self.cache.load(f_path) et self.cache.dump() vous permet de charger et d'enregistrer un cache. Par exemple, data/wordle/optimal_policy_cache_wordle_official.pkl représente un cache pour cette politique sur la liste de mots wordle_official.txt .
Entrées:
start_word_policy: Optional[Policy]=None - Étant donné que le premier mot est généralement le plus cher à calculer le gain d'informations, cela vous permet de spécifier une politique différente pour être appelée pour le premier mot.progress_bar: bool=False - puisque cela peut prendre si longtemps à calculer, nous vous laissons la possibilité d'afficher une barre de progression pour chaque appel à self.act . RepeatPolicy from wordle . policy import RepeatPolicy
policy = RepeatPolicy ( start_word_policy = None , first_n = 2 )Description:
Répète aléatoirement l'un des mots first_n déjà utilisés. Il s'agit d'une politique maximale sous-optimale, car elle ne peut jamais gagner à moins qu'elle ait de la chance sur le premier mot.
Entrées:
start_word_policy: Optional[Policy] - une politique à utiliser pour choisir le premier mot. Si None , sélectionnez au hasard un mot dans le vocabulaire de l'environnement.first_n: Optional[int] - La politique sélectionne au hasard le mot suivant parmi les mots first_n de l'historique. Si None , il sélectionne au hasard dans toute l'histoire. RandomMixturePolicy from wordle . policy import RandomMixturePolicy
policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )Description:
Choisit un mot pleinement au hasard à partir d'une liste de mots avec probabilité (1 - prob_smart) et choisit un mot aléatoire de la liste de mots qui répond à toutes les contraintes de lettres connues avec probabilité prob_smart .
Entrées:
prob_smart: float - la probabilité de sélectionner un mot qui répond à toutes les contraintes de lettres connues, plutôt qu'un entièrement au hasard.vocab: Optional[Union[str, Vocabulary]] - Une liste de mots à sélectionner. Si None , la stratégie est par défaut de la liste des mots de l'environnement. WrongPolicy from wordle . policy import WrongPolicy
from wordle . wordle_game import Vocabulary
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
policy = WrongPolicy ( vocab )Description:
Choisit au hasard un mot dans une liste de mots qui ne respecte pas toutes les contraintes de lettres connues et ne peut donc pas être le bon mot. Si tous les mots de la liste des mots répondent aux contraintes de lettre, alors il choisit un mot au hasard dans la liste. Cette politique est très sous-optimale.
Entrées:
vocab: Union[str, Vocabulary] - Une liste de mots à choisir. MixturePolicy from wordle . policy import MixturePolicy , OptimalPolicy , RandomMixturePolicy
policy1 = OptimalPolicy ()
policy2 = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MixturePolicy ( prob1 = 0.5 , policy1 = policy1 , policy2 = policy2 )Description:
Mélange deux politiques données. Sélectionnez parmi policy1 avec Probability prob1 et sélectionnez parmi policy2 avec probabilité (1 - prob1) .
Entrées:
prob1: float - La probabilité de sélectionner une action à partir de policy1 .policy1: Policy - La première politique pour sélectionner les actions. Sélectionné avec probabilité prob1 .policy1: Policy - La deuxième politique pour sélectionner les actions. Sélectionné avec probabilité (1 - prob1) . MonteCarloPolicy from wordle . policy import MonteCarloPolicy
sample_policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MonteCarloPolicy ( n_samples = 5 , sample_policy = sample_policy )Description:
Prend une politique, exécute n_samples des déploiements de Monte Carlo dans l'environnement et sélectionne la prochaine action qui a reçu la récompense moyenne la plus élevée pendant le processus de déploiement.
Entrées:
n_samples: int - Le nombre de déploiements de Monte Carlo à exécuter.sample_policy: Policy - La politique d'exemple de déploiement de. 
Toutes les politiques ci-dessus peuvent être utilisées pour générer des ensembles de données, qui peuvent être utilisés pour former des agents RL hors ligne. Nous mettons en œuvre, dans src/wordle/wordle_dataset.py , deux types d'ensembles de données synthétiques:
wordle.wordle_dataset.WordleListDataset - Charge les jeux de lot à partir d'un fichier.wordle.wordle_dataset.WordleIterableDataset - échantillonne les jeux de bordeaux à partir d'une politique donnée.WordleListDataset :Chargez un ensemble de données de lats à partir d'un fichier comme SO:
from wordle . wordle_dataset import WordleListDataset
from data . rl_data import ConstantTokenReward
data = WordleListDataset . from_file (
file_path = 'data/wordle/expert_wordle_100k.pkl' ,
max_len = None ,
vocab = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
for i in range ( data . size ()):
item = data . get_item ( i )__init__ def __init__ ( self , items : List [ Tuple [ WordleObservation , Optional [ Dict [ str , Any ]]]], max_len : Optional [ int ], token_reward : TokenReward ) -> NoneEntrées:
items: List[Tuple[WordleObservation, Optional[Dict[str, Any]]]] - une liste de données sous forme de tuples de (WordleObservation, metadata_dict). Lorsque Metadata_Dict se trouve une sorte de métadonnées, il y a une sorte de métadonnées que vous voudrez peut-être stocker dans le point de données.max_len: Optional[int] - La longueur maximale de séquence dans l'ensemble de données tronquera toutes les séquences de jetons sur cette longueur. Si None , alors les séquences ne seront pas tronquées.token_reward: TokenReward - la récompense au niveau du token pour s'appliquer aux séquences. Nous utilisons une récompense constante de 0 par-token pour toutes les expériences. Renvoie: None
from_file def from_file ( cls , file_path : str , max_len : Optional [ int ], vocab : Optional [ Vocabulary ], token_reward : TokenReward ) -> WordleListDatasetEntrées:
file_path: str - Le chemin d'accès au fichier de cornichon de données.max_len: Optional[int] - La longueur maximale de séquence dans l'ensemble de données tronquera toutes les séquences de jetons sur cette longueur. Si None , alors les séquences ne seront pas tronquées.vocab: Optional[Vocabulary] - Simuler l'ensemble de données sous un vocabulaire environnement différent. Si None , il est par défaut en utilisant le même vocabulaire qui a été utilisé pour créer l'ensemble de données.token_reward: TokenReward - la récompense au niveau du token pour s'appliquer aux séquences. Nous utilisons une récompense constante de 0 par-token pour toutes les expériences. Renvoie: un objet WordleListDataset .
get_item def get_item ( self , idx : int ) -> DataPointEntrées:
idx: int - Un index dans l'ensemble de données. Renvoie: un objet DataPoint .
size def size ( self ) -> intRenvoie: la taille de l'ensemble de données.
Les scripts suivants dans scripts/data/wordle/ peuvent être utilisés pour synthétiser les données de lot.
| scénario | description |
|---|---|
generate_data.py | Échantillonne un certain nombre de jeux d'une stratégie donnée spécifiée dans la configuration et les enregistre dans un fichier. |
generate_data_mp.py | La même chose que generate_data.py à l'exception des jeux d'échantillons en parallèle sur plusieurs processus. |
generate_adversarial_data.py | synthétise l'ensemble de données décrit dans la section 5 de notre article, qui a été conçu pour démontrer la différence entre les méthodes RL en un seul pas et les méthodes en plusieurs étapes. |
generate_adversarial_data_mp.py | La même chose que generate_adversarial_data.py à l'exception des jeux d'échantillons en parallèle sur plusieurs processus. |
generate_data_branch.py | Échantillons les jeux d'une politique "experte" donnée, puis de chaque action du jeu, une politique "sous-optimale" se dirige vers l'échantillonnage d'un certain nombre de nouveaux jeux. |
generate_data_branch_mp.py | La même chose que generate_data_branch.py sauf les jeux d'échantillons en parallèle sur plusieurs processus. |
Certains ensembles de données de lats synthétiques sont en données dans data/wordle/ .
| déposer | description |
|---|---|
expert_wordle_100k_1.pkl | 100k jeux échantillonnés de OptimalPolicy . |
expert_wordle_100k_2.pkl | Un autre 100 000 jeux échantillonné de l' OptimalPolicy . |
expert_wordle_adversarial_20k.pkl | L'ensemble de données décrit dans la section 5 de notre article, qui a été conçu pour démontrer la différence entre les méthodes RL en un seul pas et les méthodes en plusieurs étapes. |
expert_wordle_branch_100k.pkl | 100K Jeux échantillonnés à l'aide de generate_data_branch.py à partir d' OptimalPolicy avec les branches échantillonnées à partir de WrongPolicy . |
expert_wordle_branch_150k.pkl | Des jeux supplémentaires de 150k échantillonnaient à l'aide de generate_data_branch.py à partir d' OptimalPolicy avec les branches échantillonnées à partir WrongPolicy . |
expert_wordle_branch_2k_10sub.pkl | Les jeux 2K échantillonnés à l'aide de generate_data_branch.py à partir OptimalPolicy avec 10 branches par action échantillonnés à partir de WrongPolicy , de sorte qu'il y a beaucoup plus de données sous-optimales que dans expert_wordle_branch_100k.pkl . |
expert_wordle_branch_20k_10sub.pkl | Identique à expert_wordle_branch_2k_10sub.pkl sauf des jeux 20K au lieu de jeux 2K. |
WordleIterableDataset :Générez l'échantillonnage des données de lots à partir d'une politique comme tel:
from wordle . wordle_dataset import WordleIterableDataset
from wordle . policy import OptimalPolicy
from data . rl_data import ConstantTokenReward
policy = OptimalPolicy ()
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
data = WordleIterableDataset (
policy = policy ,
vocab = vocab ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
while True :
item = data . sample_item ()__init__ def __init__ ( self , policy : Policy , vocab : Vocabulary , max_len : Optional [ int ], token_reward : TokenReward ) -> NoneEntrées:
policy: Policy - Une politique à échantillonner à partir de.vocab: Vocabulary - Le vocabulaire de l'environnement.max_len: Optional[int] - La longueur maximale de séquence dans l'ensemble de données tronquera toutes les séquences de jetons sur cette longueur. Si None , alors les séquences ne seront pas tronquées.token_reward: TokenReward - la récompense au niveau du token pour s'appliquer aux séquences. Nous utilisons une récompense constante de 0 par-token pour toutes les expériences. Renvoie: None
sample_item def sample_item ( self ) -> DataPoint Renvoie: un objet DataPoint .
Nous avons un grand ensemble de données de plus de 200 000 tweets de jeux de lot comme celui-ci:
Nous pouvons moderniser les mots sur ces carrés de transition de couleurs pour créer un réel ensemble de données de jeux de lot.
Les données de tweet brutes sont données dans data/wordle/tweets.csv , mais pour être utilisable, les mots réels doivent être modernisés sur les carrés de couleur dans les tweets. L'exécution de ce processus de modernisation nécessite l'exécution d'un script de prétraitement qui met en cache toutes les transitions de couleurs possibles qui pourraient se produire sous les listes de vocabs: guess_vocab (un ensemble de mots supposables) et correct_vocab (un ensemble de mots corrects possibles dans un environnement). Le résultat est une structure de données que wordle.wordle_dataset.WordleHumanDataset utilise pour synthétiser les jeux de lots valides à partir des tweets. Ce script est scripts/data/wordle/build_human_datastructure.py . Appelez le script comme:
cd scripts/data/wordle/
python build_human_datastructure.py --guess_vocab=../../../data/wordle/word_lists/wordle_official.txt --correct_vocab=../../../data/wordle/word_lists/wordle_official.txt --tweets_file=../../../data/wordle/tweets.csv --output_file=../../../data/wordle/random_human_tweet_data.jsonLes args du script:
--guess_vocab Spécifie l'ensemble des mots supposables.--correct_vocab Spécifie l'ensemble des mots corrects possibles dans un environnement.--tweets_file Spécifie le fichier CSV brut de tweets--output_file Spécifie où vider la sortie. Nous avons exécuté le prétraitement sur certaines des listes de mots, avec les résultats enregistrés dans data/wordle/ .
| liste de mots | Fichier de données de tweet prétraité |
|---|---|
wordle_official.txt | random_human_tweet_data.json |
wordle_official_800.txt | random_human_tweet_data_800.json |
wordle_official_400.txt | random_human_tweet_data_400.json |
wordle_official_200.txt | random_human_tweet_data_200.json |
tweet_words.txt | human_tweet_data_true_word.json |
Compte tenu de l'un de ces fichiers, vous pouvez charger l'ensemble de données de tweet de losts comme tel:
from wordle . wordle_dataset import WordleHumanDataset
data = WordleHumanDataset . from_file ( 'data/wordle/random_human_tweet_data_200.json' )
print ( data . sample_item ()) Nous avons utilisé 'data/wordle/random_human_tweet_data_200.json' dans nos expériences.
WordleHumanDataset : __init__ def __init__ ( self , games : List [ Tuple [ str , List [ str ]]], transitions : Dict [ str , Dict [ str , List [ str ]]], use_true_word : bool , max_len : Optional [ int ], token_reward : TokenReward , game_indexes : Optional [ List [ int ]], top_p : Optional [ float ]) -> NoneEntrées:
games: List[Tuple[str, List[str]]] - une liste de tuples du formulaire (correct_wordle_word, wordle_transitions_list) , où wordle_transitions_list est une liste de transitions indiquant les couleurs dans le tweet comme: ["<b><b><y><y><b>", "<g><b><b><b><b>", "<g><g><y><b><b>", "<g><g><g><g><g>"] .transitions: Dict[str, Dict[str, List[str]]] - Un dict cartographier le mot de forfait correct à un autre dict cartographier des transitions de couleurs possibles qui auraient pu être induites par ce mot à une liste de mots qui auraient pu être joués pour provoquer cette transition. Cette structure de données est utilisée pour moderniser les mots sur les tweets.use_true_word: bool - Si True , utilisez le mot correct de la truth du sol du tweet, sinon modifie tout mot correct dans la liste des mots qui fonctionne.max_len: Optional[int] - La longueur maximale de séquence dans l'ensemble de données tronquera toutes les séquences de jetons sur cette longueur. Si None , alors les séquences ne seront pas tronquées.token_reward: TokenReward - la récompense au niveau du token pour s'appliquer aux séquences. Nous utilisons une récompense constante de 0 par-token pour toutes les expériences.game_indexes: Optional[List[int]] - une liste d'index pour créer une répartition des tweets. Si None , tous les éléments des données seront utilisés. Nous avons data/wordle/human_eval_idxs.json et data/wordle/human_train_idxs.json créées comme train et évalue sélectionnés au hasard.top_p: Optional[float] - Filtre pour le pourcentage de performance top_p des données. Si None , aucune donnée ne sera filtrée. Utilisé avec% de modèles BC. Renvoie: None
from_file def from_file ( cls , file_path : str , use_true_word : bool = False , max_len : Optional [ int ] = None , token_reward : Optional [ TokenReward ] = None , top_p : Optional [ float ] = None ) -> WordleHumanDatasetEntrées:
file_path: str - Le chemin du fichier JSON pour charger les données.use_true_word: bool - Si True , utilisez le mot correct de la truth du sol du tweet, sinon modifie tout mot correct dans la liste des mots qui fonctionne.max_len: Optional[int] - La longueur maximale de séquence dans l'ensemble de données tronquera toutes les séquences de jetons sur cette longueur. Si None , alors les séquences ne seront pas tronquées.token_reward: TokenReward - la récompense au niveau du token pour s'appliquer aux séquences. Nous utilisons une récompense constante de 0 par-token pour toutes les expériences.game_indexes: Optional[List[int]] - une liste d'index pour créer une répartition des tweets. Si None , tous les éléments des données seront utilisés. Nous avons data/wordle/human_eval_idxs.json et data/wordle/human_train_idxs.json créées comme train et évalue sélectionnés au hasard.top_p: Optional[float] - Filtre pour le pourcentage de performance top_p des données. Si None , aucune donnée ne sera filtrée. Utilisé avec% de modèles BC. Renvoie: un objet WordleHumanDataset .
sample_item def sample_item ( self ) -> DataPoint Renvoie: un objet DataPoint .
Les scripts de formation sont dans scripts/train/wordle/ .
| scénario | description |
|---|---|
train_bc.py | Former un agent de la Colombie-Britannique. |
train_iql.py | Entraîner un agent ILQL. |
Les scripts d'évaluation se trouvent dans scripts/eval/wordle/ .
| scénario | description |
|---|---|
eval_policy.py | Évaluez un agent BC ou ILQL dans l'environnement de lot. |
eval_q_rank.py | Un script d'évaluation pour comparer le rang relatif des valeurs Q pour les agents formés sur l'ensemble de données synthétique décrit dans la section 5 de notre article, qui a été conçu pour démontrer une différence entre la RL en un seul pas et la RL en plusieurs étapes. |
distill_policy_eval.py | Imprime le résultat de eval_policy.py avec des barres d'erreur. |
Ici, nous décrivons comment charger les données de dialogue visuel dans notre base de code et comment exécuter l'environnement. Voir la section de configuration ci-dessus pour configurer les composants distants de l'environnement de dialogue visuel. Les objets Data and Environment sont chargés automatiquement par le gestionnaire de configuration, mais si vous souhaitez contourner le système de configuration et utiliser l'environnement avec votre propre base de code, voici comment vous devez charger, exécuter et configurer ces objets. Les mêmes paramètres décrits ci-dessous peuvent également être modifiés dans les configurations.
Un exemple de la façon de charger l'environnement du dialogue visuel:
from visdial . visdial_env import VDEnvironment
from visdial . visdial_base import VisDialogueData
from visdial . visdial_dataset import VisDialListDataset
from data . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = VisDialogueData (
data_path = convert_path ( 'data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.json' ),
img_feat_path = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/data_img.h5' ),
split = 'train' ,
reward_cache = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/train_rank_reward_cache1.json' ),
yn_reward_kind = 'none'
)
list_data = VisDialListDataset (
data = data ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 )
)
env = VDEnvironment (
dataset = list_data ,
url = 'http://localhost:5000/step_rank' ,
yn_reward = - 2.0 ,
yn_reward_kind = 'none'
)
print ( env . reset ()) Le script ci-dessus correspond à la façon dont nous avons configuré l'ensemble de données et l'environnement pour nos expériences de récompense «standard», mais si vous souhaitez configurer l'ensemble de données différemment, il existe de nombreux arguments que vous pouvez modifier. Au-delà du simple changement de division de l'ensemble de données, ces arguments peuvent également modifier la tâche ou la récompense. Ci-dessous, nous décrivons tous les différents paramètres configurables que VisDialogueData , VisDialListDataset et VDEnvironment prennent.
Nous documentons les paramètres et les méthodes pour VisDialogueData , VisDialListDataset et VDEnvironment , afin que vous sachiez comment configurer l'environnement vous-même.
VisDialogueData : VisDialogueData , implémenté dans src/visdial/visdial_base.py , stocke l'ensemble de dialogues et de récompenses de la tâche.
__init__ def __init__ ( self , data_path : str , img_feat_path : str , split : str , reward_cache : Optional [ str ] = None , norm_img_feats : bool = True , reward_shift : float = 0.0 , reward_scale : float = 1.0 , addition_scenes : Optional [ List [ Scene ]] = None , mode : str = 'env_stops' , cutoff_rule : Optional [ CutoffRule ] = None , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneEntrées:
data_path: str - Le chemin vers les données de dialogue. Devrait être l'un des:data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_val.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_test.jsonimg_feat_path: str - Le chemin vers les fonctionnalités d'image utilisés pour calculer la récompense pour chaque dialogue. Doit toujours être data/vis_dialogue/processed/visdial_0.5/data_img.h5 .split: str - l'un des train , val ou test . Indique quelle division d'ensemble de données des fonctionnalités d'image à utiliser. Devrait être cohérent avec la division data_path .reward_cache: Optional[str]=None - où les récompenses pour chaque dialogue sont stockées. Si None , il ne définira toutes les récompenses sur None . Nous fournissons des caches pour deux fonctions de récompense:data/vis_dialogue/processed/visdial_0.5/[split]_rank_reward_cache1.json , où [split] est remplacé par l'un de train , val ou test .data/vis_dialogue/processed/visdial_0.5/[split]_reward_cache2.json , où [split] est remplacé par l'un des train , val ou test .norm_img_feats: bool=True - s'il faut normaliser les fonctionnalités de l'image.reward_shift: float=0.0 - déplacer la récompense par ce montant.reward_scale: float=1.0 - Échelle la récompense par ce montant.addition_scenes: Optional[List[Scene]]=None - Injecter des données supplémentaires dans l'ensemble de données.mode: str='env_stops' - l'un des ['agent_stops', 'env_stops', '10_stop'] . Contrôle certaines propriétés de la tâche. Nous utilisons env_stopsmode='env_stops' , alors arrêtez l'interaction de l'environnement tôt selon cutoff_rule .mode='agent_stops' , alors l'agent arrête l'interaction en générant un jeton <stop> spécial pendant son action; Augmente les données en plaçant un <stop> après chaque action possible.mode='10_stop' , le jeu s'arrête toujours après 10 tours d'interaction, tout comme la norme dans l'ensemble de données de dialogue visuel.cutoff_rule: Optional[CutoffRule]=None - ne s'applique que si mode='env_stops' . Met en œuvre une fonction qui détermine le moment où l'environnement doit arrêter l'interaction tôt. Nous utilisons la valeur par défaut de visdial.visdial_base.PercentileCutoffRule(1.0, 0.5) dans toutes nos expériences.yn_reward: float=-2.0 - la pénalité de récompense qui devrait être ajoutée pour poser des questions oui / non.yn_reward_kind: str='none' - Spécifie l'heuristique de correspondance de chaîne à utiliser pour déterminer si une question oui / non a été posée. Devrait être l'un des ['none', 'soft', 'hard', 'conservative'] .'none' : ne pénalisez pas les questions oui / non. Cela correspond à la récompense standard de notre article.'soft' : pénalise une question si la réponse contient "yes" ou "no" en tant que sous-chaîne.'hard' : pénalise une question si la réponse correspond exactement à la chaîne "yes" ou "no" . Cela correspond à la récompense "y/n" dans notre article.'conservative' : pénaliser la question si la réponse satisfait l'une des nombreuses heuristiques correspondantes à des cordes. Cela correspond à la récompense "conservative y/n" dans notre article. Renvoie: None
__len__ def __len__ ( self ) -> intRenvoie: la taille de l'ensemble de données.
__getitem__ def __getitem__ ( self , i : int ) -> SceneEntrées:
i: int - L'indice de l'ensemble de données.Renvoie: un élément de l'ensemble de données.
VisDialListDataset : VisDialListDataset , implémenté dans src/visdial/visdial_dataset.py , s'enroule autour de VisDialogueData et le convertit en format DataPoint qui peut être utilisé pour entraîner des agents RL hors ligne.
__init__ def __init__ ( self , data : VisDialogueData , max_len : Optional [ int ], token_reward : TokenReward , top_p : Optional [ float ] = None , bottom_p : Optional [ float ] = None ) -> NoneEntrées:
data: VisDialogueData - Un objet de données de dialogue visuel qui stocke toutes les données brutes.max_len: Optional[int] - La longueur maximale de séquence dans l'ensemble de données tronquera toutes les séquences de jetons sur cette longueur. Si None , alors les séquences ne seront pas tronquées.token_reward: TokenReward - la récompense au niveau du token pour s'appliquer aux séquences. Nous utilisons une récompense constante de 0 par-token pour toutes les expériences.top_p: Optional[float] - Filtre pour le pourcentage de performance top_p des données. Si None , aucune donnée ne sera filtrée. Utilisé avec% de modèles BC.bottom_p: Optional[float] - filtrez pour le pourcentage d'effectif bottom_p des données. Si None , aucune donnée ne sera filtrée. Renvoie: None
size def size ( self ) -> intRenvoie: la taille de l'ensemble de données.
get_item def get_item ( self , idx : int ) -> DataPointEntrées:
i: int - L'indice de l'ensemble de données. Renvoie: un DataPoint à partir de l'ensemble de données.
VDEnvironment : VDEnvironment , implémenté dans src/visdial/visdial_env.py , définit l'environnement de dialogue visuel, avec lequel nos agents RL hors ligne interagissent au temps d'évaluation. L'environnement consiste à se connecter à un serveur localhost, que la section de configuration décrit comment tourner.
__init__ def __init__ ( self , dataset : RL_Dataset , url : str , reward_shift : float = 0.0 , reward_scale : float = 1.0 , actor_stop : bool = False , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> NoneEntrées:
dataset: RL_Dataset - prend un RL_Dataset ; spécifiquement VisDialListDataset , comme ci-dessus. Cet ensemble de données est utilisé pour sélectionner les états initiaux.url: str - L'URL pour faire un pas dans l'environnement. Suivez les instructions de la section Configuration pour savoir comment initialiser le serveur Web localhost correspondant à cette URL.reward_shift: float=0.0 - déplacer la récompense par ce montant.reward_scale: float=1.0 - Échelle la récompense par ce montant.actor_stop: bool=False - permettez à l'acteur d'arrêter l'interaction tôt en générant un jeton <stop> spécial.yn_reward: float=-2.0 - la pénalité de récompense qui devrait être ajoutée pour poser des questions oui / non.yn_reward_kind: str='none' - Spécifie l'heuristique de correspondance de chaîne à utiliser pour déterminer si une question oui / non a été posée. Devrait être l'un des ['none', 'soft', 'hard', 'conservative'] .'none' : ne pénalisez pas les questions oui / non. Cela correspond à la récompense standard de notre article.'soft' : pénalise une question si la réponse contient "yes" ou "no" en tant que sous-chaîne.'hard' : pénalise une question si la réponse correspond exactement à la chaîne "yes" ou "no" . Cela correspond à la récompense "y/n" dans notre article.'conservative' : pénaliser la question si la réponse satisfait l'une des nombreuses heuristiques correspondantes à des cordes. Cela correspond à la récompense "conservative y/n" dans notre article. Renvoie: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Entrées:
action: Vocabulary - Le vocabulaire de l'environnementRenvoie: un tuple (observation, récompense, terminal).
reset def reset ( self ) -> WordleObservationRetour: une observation
is_terminal def is_terminal ( self ) -> boolRenvoie: un booléen indiquant si l'interaction s'est terminée.
Les scripts de formation sont dans scripts/train/vis_dial/ .
| scénario | description |
|---|---|
train_bc.py | Former un agent de la Colombie-Britannique. |
train_chai.py | Former un agent chai. |
train_cql.py | Former un agent CQL. |
train_dt.py | Former un agent de transformateur de décision. |
train_iql.py | Entraîner un agent ILQL. |
train_psi.py | Entraîner un |
train_utterance.py | Former un agent ILQL au niveau de l'énoncé. |
Les scripts d'évaluation sont dans scripts/eval/vis_dial/ .
| scénario | description |
|---|---|
eval_policy.py | Évaluez un agent dans l'environnement du dialogue visuel. |
top_advantage.py | Trouve les questions qui ont le plus grand et le plus petit avantage dans le modèle. |
distill_policy_eval.py | Imprime le résultat de eval_policy.py avec des barres d'erreur. |
Here we outline how to load the Reddit comments data in our codebase and how to execute the environment. See the setup section above for how to setup the toxicity filter reward. The data and environment objects are loaded automatically by the config manager, but if you want to by-pass the config system and use the task with your own codebase, here's how you should load, execute, and configure these objects. The same settings described below can all be modified in the configs as well.
An example of how to load the Reddit comment environment:
from toxicity . toxicity_env import ToxicityEnvironment
from toxicity . reddit_comments_base import RedditData
from toxicity . reward_fs import toxicity_reward
from utils . misc import convert_path
idxs = json . load ( open ( convert_path ( 'data/reddit_comments/train_idxs.json' ), 'r' ))
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = idxs ,
reward_f = toxicity_reward
)
env = ToxicityEnvironment (
data = data ,
reward_f = toxicity_reward
)
print ( env . reset ())
The above script corresponds to how we configured the environment for our toxicity reward experiments, but if you want to configure the environment differently, there are a few arguments you can modify. These arguments can also change the task or reward. Below we describe all the different configurable parameters that our reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment take.
We document the parameters and methods for our different Reddit comment reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment , so that you know how to configure the environment yourself.
Here we outline the 4 main reward functions we use for our Reddit comment task. Each of these rewards is implemented in src/toxicity/reward_fs.py .
toxicity_reward from toxicity . reward_fs import toxicity_reward
reward_f = toxicity_reward ()Description:
The "toxicity" reward from our paper, which queries the GPT-3 toxicity filter. It assigns a value of "0" to non-toxic comments, a value of "1" to moderately toxic comments, and a value of "2" to very toxic comments.
toxicity_noised_reward from toxicity . reward_fs import toxicity_noised_reward
reward_f = toxicity_noised_reward ()Description:
The "noised toxicity" reward from our paper, which is the same as toxicity_noised_reward but induces additional noise. Specifically, it re-assigns comments labeled as "1" (moderately toxic) to either "0" (non-toxic) or "2" (extremely toxic) with equal probability.
score_human_reward from toxicity . reward_fs import score_human_reward
from utils . misc import convert_path
reward_f = score_human_reward (
reddit_path = convert_path ( 'data/reddit_comments/' ),
indexes = None
)Description:
The "upvotes real" reward from our paper, which gives a reward of +1 for positive upvote comments and -1 for negative upvote comments. This uses the ground truth upvotes in the data, so it only applies to comments in the dataset and cannot be used for evaluation. If you input a string not present in the data, it will error. The arguments to this function specify what data to load.
Inputs:
reddit_path: str – a path to the data.indexes: List[int] – a split of indexes in the data to use. If None , it considers all the data. model_reward from toxicity . reward_fs import score_human_reward
from toxicity . reddit_comments_base import RedditData
from toxicity . toxicity_dataset import ToxicityListDataset
from toxicity . reward_model import RobertaBinaryRewardModel
from utils . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = None ,
reward_f = None
)
listdata = ToxicityListDataset (
data = data ,
max_len = 512 ,
token_reward = ConstantTokenReward ( 0.0 )
)
model = RobertaBinaryRewardModel (
data = listdata ,
device = 'cuda' ,
roberta_kind = 'roberta-base' ,
freeze_roberta = False ,
reward_cuttoff = 0.0
)
model . load_state_dict ( torch . load ( convert_path ( 'outputs/toxicity/upvote_reward/model.pkl' ), map_location = 'cpu' ))
reward_f = score_human_reward ( model = model )Description:
The "upvotes model" reward from our paper, which gives a reward of +1 if the given model predicts that the comment will get a positive number of upvotes and a reward of -1 otherwise. The model checkpoint we used for our experiments is at: outputs/toxicity/upvote_reward/model.pkl
Inputs:
model: RewardModel : the reward model implemented in src/toxicity/reward_model.py . The model should be first trained and loaded from a pytorch checkpoint.RedditData : RedditData , implemented in src/toxicity/reddit_comments_base.py , stores the raw Reddit comments data.
__init__ def __init__ ( self , path : str , indexes : Optional [ List [ int ]], reward_f : Optional [ Callable [[ str ], float ]], reward_cache : Optional [ Cache ] = None , reward_shift : float = 0.0 , reward_scale : float = 1.0 ) -> NoneInputs:
path: str – the path to the Reddit data.indexes: Optional[List[int]] – a list of indexes to create a split of the data. Randomly selected, training, validation, and test splits are in the json files:data/reddit_comments/train_idxs.jsondata/reddit_comments/eval_idxs.jsondata/reddit_comments/test_idxs.jsonreward_f: Optional[Callable[[str], float]] – the reward function to use.reward_cache: Optional[Cache]=None – a cache of reward values, so you don't have to recompute them everytime.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount. Returns: None
__len__ def __len__ ( self ) -> intReturns: the size of the dataset.
__getitem__ def __getitem__ ( self , idx : int ) -> SceneInputs:
idx: int – the dataset index.Returns: an item from the dataset.
ToxicityListDataset : ToxicityListDataset , implemented in src/toxicity/toxicity_dataset.py , wraps around RedditData and converts it into a DataPoint format that can be used to train offline RL agents.
__init__ def __init__ ( self , data : RedditData , max_len : Optional [ int ], token_reward : TokenReward , cuttoff : Optional [ float ] = None , resample_timeout : float = 0.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – a Reddit comment data object that stores all the raw data.max_len: Optional[int] – the maximum sequence length in the dataset, will truncate all token sequences to this length. If None , then sequences will not be truncated.token_reward: TokenReward – the token-level reward to apply to the sequences. We use a constant reward of 0 per-token for all experiments.cuttoff: Optional[float]=None – filter out all comments from the dataset with reward less than cuttoff . If None , no data will be filtered. Used with %BC models.resample_timeout: float=0.0 – when cuttoff is not equal to None , comments are stochastically sampled iid from the dataset, like an iterable, even though the dataset has a list-type interface. It uniformly re-samples from the dataset until it finds a comment with a reward that satisfies the cuttoff. In the case of the "toxicity" reward, this re-sampling can cause rate-limit errors on the GPT-3 API, so we allow you to add a resample_timeout to fix this issue: a timeout of roughly 0.05 should fix rate-limit issues.include_parent: bool=True – whether to condition on the parent comment in the thread. If False , models will be trained to generate comments unconditionally. Returns: None
size def size ( self ) -> intReturns: the size of the dataset.
get_item def get_item ( self , idx : int ) -> DataPointInputs:
i: int – the dataset index. Returns: a DataPoint from the dataset.
ToxicityEnvironment : ToxicityEnvironment , implemented in src/toxicity/toxicity_env.py , defines the Reddit comment generation environment, which our offline RL agents interact with at evaluation time.
__init__ def __init__ ( self , data : RedditData , reward_f : Optional [ Callable [[ str ], float ]], reward_shift : float = 0.0 , reward_scale : float = 1.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – the dataset used to select initial state parent comments to condition on.reward_f: Optional[Callable[[str], float]] – the reward function to use.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount.include_parent: bool=True – specifies whether to condition on the previous comment or post in the Reddit thread. Returns: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Inputs:
action: Vocabulary – the environment's vocabularyReturns: an (observation, reward, terminal) tuple.
reset def reset ( self ) -> WordleObservationReturns: an observation
is_terminal def is_terminal ( self ) -> boolReturns: a boolean indicating if the interaction has terminated.
Training scripts are in scripts/train/toxicity/ .
| scénario | description |
|---|---|
train_bc.py | Train a BC agent. |
train_iql.py | Train an ILQL agent. |
train_upvote_reward.py | Train the upvote reward model. |
Evaluation scripts are in scripts/eval/toxicity/ .
| scénario | description |
|---|---|
eval_policy.py | Evaluate an agent in the Reddit comments environment. |
distill_policy_eval.py | Prints out the result of eval_policy.py with error bars. |
All tasks – Wordle, Visual Dialogue, Reddit – have a corresponding environment and dataset implemented in the codebase, as described above. And all offline RL algorithms in the codebase are trained, executed, and evaluated on one of these given environments and datasets.
You can similarly define your own tasks that can easily be run on all these offline RL algorithms. This codebase implements a simple set of RL environment abstractions that make it possible to define your own environments and datasets that can plug-and-play with any of the offline RL algorithms.
All of the core abstractions are defined in src/data/ . Here we outline what needs to be implemented in order to create your own tasks. For examples, see the implementations in src/wordle/ , src/vis_dial/ , and src/toxicity/ .
All tasks must implement subclasses of: Language_Observation and Language_Environment , which are in src/data/language_environment.py .
Language_Observation :This class represents the observations from the environment that will be input to your language model.
A Language_Observation must define the following two functions.
to_sequence def to_sequence ( self ) -> Tuple [ List [ str , Optional [ float ]], bool ]:Description:
A function which converts the observation object into a standard format that can be input to the language model and used for training.
Renvoie:
__str__ def __str__ ( self ) -> str :Description:
This is only used to print the observation to the terminal. It should convert the observation into some kind of string that is interpretable by a user.
Returns: a string.
Language_Environment :This class represents a gym-style environment for online interaction, which is only used for evaluation.
A Language_Environment must define the following three functions.
step def step ( self , action : str ) -> Tuple [ Language_Observation , float , bool ]:Description:
Just like a standard gym environment, given an action in the form of a string, step the environment forward.
Returns: a tuple of (Language_Observation, reward, terminal).
reset def reset ( self ) -> Language_Observation :Description:
This resets the environment to an initial state.
Returns: the corresponding initial Language_Observation
is_terminal def is_terminal ( self ) -> bool :Description:
Outputs whether the environment has reached a terminal state.
Returns: a boolean indicating if the environment has reached a terminal state.
All tasks must implement subclasses of either List_RL_Dataset or Iterable_RL_Dataset or both, which are defined in src/data/rl_data.py .
List_RL_Dataset :This class represents a list dataset (or an indexable dataset of finite length) that can be used to train offline RL agents.
A List_RL_Dataset must define the following two functions.
get_item def get_item ( self , idx : int ) -> DataPointDescription:
This gets an item from the dataset at a given index.
Returns: a DataPoint object from the dataset.
size def size ( self ) -> intDescription:
Returns the size of the dataset.
Returns: the dataset's size.
Iterable_RL_Dataset :This class represents an iterable dataset (or a non-indexable dataset that stochastically samples datapoints iid) that can be used to train offline RL agents.
A Iterable_RL_Dataset must define the following function.
sample_item def sample_item ( self ) -> DataPointDescription:
Samples a datapoint from the dataset.
Returns: a DataPoint object from the dataset.


