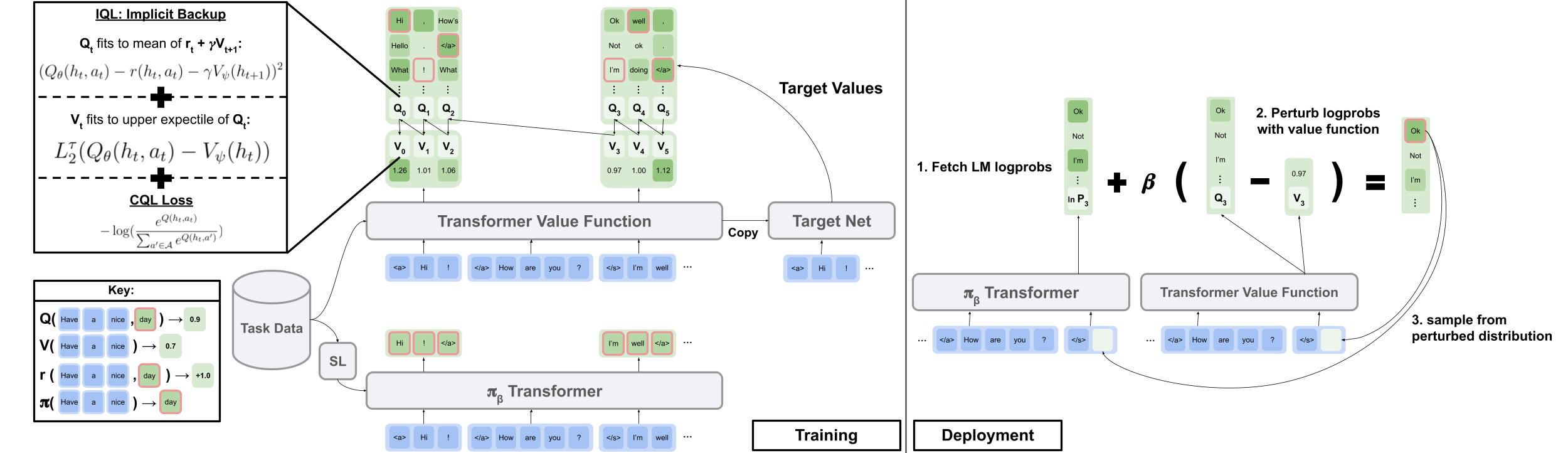
Implicit Language Q Learning
1.0.0
논문의 공식 코드 "암시 적 언어 Q 학습을 가진 자연 언어 생성을위한 오프라인 RL"
프로젝트 사이트 | arxiv
Google 드라이브 폴더에서 data.zip 및 outputs.zip 다운로드하십시오. 다운로드 및 압축이없는 폴더, data/ 및 outputs/ 를 Repo의 루트에 배치하십시오. data/ 모든 작업에 대한 전처리 데이터를 포함하며 outputs/ Reddit 주석에 대한 체크 포인트가 포함되어 있습니다.
이 저장소는 Python 3.9.7 용으로 설계되었습니다
pip install -r requirements.txt
export PYTHONPATH= " $PWD /src/ "시각적 대화 실험을 실행하려면 여기에 지침을 따라 LocalHost에서 시각적 대화 환경을 제공해야합니다.
독성 필터 보상으로 Reddit 주석 실험을 실행하려면 :
export OPENAI_API_KEY=your_API_key scripts/ 모든 실험 스크립트를 포함합니다. scripts/ :
python script_name.py선택 과목:
python script_name.py eval.bsize=5 train.lr=1e-6 wandb.use_wandb=falsepython -m torch.distributed.launch --nproc_per_node [N_GPUs] --use_env script_name.py arg1=a arg2=b 기본적으로 모든 교육 스크립트는 wandb에 로그인합니다. 이를 끄려면 교육 구성에서 wandb.use_wandb=false 설정하십시오.
여기서 나는 오프라인 RL 에이전트를 훈련하기위한 권장 워크 플로를 간략하게 설명합니다. 독성 보상으로 Reddit 의견을 생성하기 위해 다양한 오프라인 RL 에이전트를 훈련시키고 싶다고 가정 해 봅시다.
먼저 데이터에 대한 BC 모델을 훈련시킬 것입니다.
cd scripts/train/toxicity/
python train_bc.py그런 다음이 BC 체크 포인트를 오프라인 RL 모델과 호환되는 하나로 변환하십시오.
cd ../data/
python convert_bc.py --load ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model.pkl --save ../../outputs/toxicity/conditional_toxicity_official_bc_test1/model_converted.pkl그런 다음 오프라인 RL이 다음과 함께 훈련하도록 구성된 검사 점을 편집하십시오.
cd ../train/
python train_iql.py model.load.checkpoint_path=outputs/toxicity/model_converted.pkl model.load.strict_load=false train.loss.awac_weight=0.0 그러나 이것은 하나의 워크 플로 일 뿐이므로 train.loss.awac_weight=1.0 설정하여 오프라인 RL 에이전트와 동시에 BC 모델을 교육 할 수도 있습니다.
data/ 폴더에서 사전 처리 된 제공됩니다.scripts/ 에는 논문의 교육, 평가 및 데이터 사전 처리 단계를 실행하기위한 모든 스크립트가 포함되어 있습니다. 스크립트는 사용 된 데이터 세트에 해당하는 서브 폴더로 구성됩니다.config/ contains 각 스크립트에 대한 .yaml 구성. 이 repo는 Hydra를 사용하여 구성을 관리합니다. 구성은 사용 된 데이터 세트에 해당하는 서브 폴더로 구성됩니다. 대부분의 구성 파일은 해당 스크립트와 동일하지만 어떤 구성이 스크립트에 해당하는지 확실하지 않은 경우 스크립트에 해당하는 구성 파일을 확인하려면 @hydra.main(config_path="some_path", config_name="some_name") 을 확인하십시오.src/ 에는 모든 핵심 구현이 포함되어 있습니다. 모든 모델 구현은 src/models/ 참조하십시오. 모든 기본 데이터 처리 및 MDP 추상화 코드는 src/data/ 참조하십시오. 다양한 유틸리티 기능은 src/utils/ 참조하십시오. 모든 Wordle, Visual DataSet 데이터 세트 특정 코드에 대해 src/wordle/ , src/visdial 및 SRC/독성/ src/toxicity/ 각각 참조하십시오.ILQL 은 Repo 전체에서 iql 이라고합니다. 각 스크립트는 구성 파일과 관련이 있습니다. 구성 파일은 스크립트와 해당 하이퍼 파라 미터에 의해로드 될 모델, 데이터 세트 및 평가자를 지정합니다. 예를 들어 configs/toxicity/train_iql.yaml 참조하십시오.
가능한 각 모델, 데이터 세트 또는 평가자 객체는 자체 구성 파일과 해당 객체의 기본값과 특수 name 속성을 지정하여 구성 관리자에게로드 할 클래스를 알려줍니다. 예를 들어 configs/toxicity/model/per_token_iql.yaml 참조하십시오.
파일 src/load_objects.py , src/wordle/load_objects.py , src/visdial/load_objects.py 및 src/toxicity/load_objects.py 각 객체가 해당 구성에서로드되는 방식을 정의합니다. 각로드 객체 함수 위의 @register('name') 태그는 구성의 name 속성에 연결됩니다.
구성의 일부 개체와 관련된 특수 cache_id 속성을 알 수 있습니다. 예를 들어, configs/toxicity/train_iql.yaml 의 train_dataset 참조하십시오. 이 속성은 구성 관리자 에게이 ID와 관련된 첫 번째 객체를 캐시하도록 지시 한 다음이 cache_id 사용하여 후속 객체 구성을 위해이 캐시 된 객체를 반환합니다.
모든 구성의 경우 리포 루트와 관련된 경로를 사용하십시오.
REPO의 각 작업 (Wordle, Visual Dialogue 및 Reddit 댓글)은 몇 가지 기본 클래스를 구현합니다. 일단 구현되면 모든 오프라인 RL 알고리즘을 플러그 앤 플레이 방식으로 작업에 적용 할 수 있습니다. 자신의 작업을 만들기 위해 구현해야 할 사항에 대한 개요는 "자신의 작업 만들기"섹션을 참조하십시오. 아래에서, 우리는 이것을 가능하게하는 주요 추상화를 간략하게 설명합니다.
data.language_environment.Language_Environment - 정책이 상호 작용할 수있는 작업 POMDP 환경을 나타냅니다. 체육관과 같은 인터페이스가 있습니다.data.language_environment.Policy - 환경과 상호 작용할 수있는 정책을 나타냅니다. src/models/ 의 각 오프라인 RL 알고리즘에는 해당 정책이 있습니다.data.language_environment.Language_Observation - 환경에 의해 반환되고 정책에 입력되는 텍스트 관찰을 나타냅니다.data.language_environment.interact_environment - 환경, 정책 및 선택적으로 현재 관찰 및 환경 상호 작용 루프를 실행하는 함수. 현재 관찰이 제공되지 않으면 환경을 재설정하여 초기 상태를 자동으로 가져옵니다.data.rl_data.DataPoint - 모든 작업에서 모든 오프라인 RL 에이전트에 입력 한 표준화 된 데이터 형식을 정의합니다. 이러한 데이터 구조는 주어진 Language_Observation 에서 자동으로 생성됩니다.data.rl_data.TokenReward - 모든 단일 토큰에 제공된 보상 함수를 정의하며, 이는보다 미세한 곡물 제어를 배우는 데 사용할 수 있습니다. 이것은 환경의 보상 위에 제공되며, 이는 모든 토큰이 아니라 상호 작용의 전환 후에 나옵니다. 우리의 모든 실험에서 우리는이 보상을 상수 0으로 설정하여 효과가 없습니다.data.tokenizer.Tokenizer - 문자열을 토큰 시퀀스로 그리고 언어 모델에 입력하여 공급할 수있는 방법을 지정합니다.data.rl_data.RL_Dataset - DataPoint 객체를 반환하고 오프라인 RL 에이전트를 훈련시키는 데 사용되는 데이터 세트 객체를 정의합니다. RL_Dataset 에는 두 가지 버전이 있습니다.List_RL_DatasetIterable_RL_Dataset
여기서 우리는 Wordle 작업의 모든 구성 요소를 설명하고 문서화합니다.
예제 스크립트의 대부분은 구성 관리자가 자동으로 수행되며 구성을 변경하여 해당 매개 변수를 편집 할 수 있습니다. 그러나 구성을 사용하여 우회하고 자신의 코드베이스와 함께 Wordle 작업을 사용하려면 아래의 스크립트 및 문서를 참조하여이를 수행하는 방법에 대해서는 아래의 스크립트와 문서를 참조 할 수 있습니다.
Commandline에서 Wordle을 재생하기위한 간단한 예제 스크립트.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from wordle . policy import UserPolicy
from data . language_environment import interact_environment
from utils . misc import convert_path
game_vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( game_vocab )
policy = UserPolicy ()
interact_environment ( env , policy )src/wordle/wordle_game.pysrc/wordle/wordle_env.pysrc/wordle/policy.pysrc/wordle/wordle_dataset.py게임을 유효한 MDP로 만들기 위해 환경은 기본 상태를 알려진 문자 제약 세트로 나타내며, 이들을 사용하여 각 턴마다 이러한 모든 제약 조건을 충족하는 단어의 어휘를 필터링합니다. 그런 다음이 필터링 된 단어 목록에서 임의의 단어를 선택하고 환경에서 반환 한 색상 전환을 결정하는 데 사용됩니다. 이 새로운 색상 전환은 알려진 문자 제약 세트를 업데이트합니다.
Wordle Environment는 단어 목록을 취합니다. 일부 단어 목록은 data/wordle/word_lists/ 에 나와 있지만 자유롭게 만들 수 있습니다.
포함 된 단어 목록은 다음과 같습니다.
단어 목록은 위의 예에서와 같이 Vocabulary 객체를 통해 환경에로드됩니다.
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))어휘는 단어 목록뿐만 아니라 주어진 상태의 모든 알려진 문자 제약 조건을 충족하는 필터링 된 단어 목록을 추적합니다. 이 목록은 환경에서 전환을 계산하는 데 사용되며 일부 손으로 제작 된 정책에 의해 사용됩니다.
이러한 필터링 된 목록을 실시간으로 생성하면 환경 상호 작용 프로세스가 느려질 수 있습니다. 이것은 일반적으로 문제가되어서는 안되지만 정책에서 많은 데이터를 신속하게 종합하려면 병목 현상이 될 수 있습니다. 이를 극복하기 위해 모든 Vocabulary 객체는 cache 인수를 저장하는데, 주어진 상태와 관련된 필터링 된 단어 목록을 캐시합니다. vocab.cache.load(f_path) 및 vocab.cache.dump() 사용하면이 캐시를로드하고 저장할 수 있습니다. 예를 들어, data/wordle/vocab_cache_wordle_official.pkl wordle_official.txt 단어 목록의 큰 캐시입니다.
캐시를 저장하는 것 외에도 Vocabulary 객체는 src/wordle/wordle_game.py 의 방법을 따르는 것입니다.
__init__ def __init__ ( self , all_vocab : List [ str ],
wordle_state : Optional [ WordleState ],
cache : Optional [ Cache ] = None ,
fill_cache : bool = True ) -> None입력 :
all_vocab: List[str] - 단어 목록.wordle_state: Optional[WordleState] - 필터링 된 단어 목록을 생성 할 상태, 상태가 제공되지 않으면 단어가 필터링되지 않습니다.cache: Optional[Cache]=None - 위에서 설명한대로 필터링 된 어휘의 캐시.fill_cache: bool=True - 캐시에 추가할지 여부. 반품 : None
from_file def from_file ( cls , vocab_file : str , fill_cache : bool = True ) -> Vocabulary입력 :
vocab_file: str - 단어를로드 할 파일. 이 방법은 길이가 5 글자 인 단어 만 선택합니다.fill_cache: bool=True - 캐시에 추가할지 여부. 반환 : Vocabulary
filtered_vocab_size def filtered_vocab_size ( self ) -> int반품 : 필터링 된 어휘의 크기
all_vocab_size def all_vocab_size ( self ) -> int반품 : 필터링되지 않은 완전한 어휘의 크기
get_random_word_filtered def get_random_word_filtered ( self ) -> str반환 : 필터링 된 목록에서 임의의 단어.
get_random_word_all def get_random_word_all ( self ) -> str반환 : 완전한 필터링 된 목록에서 임의의 단어.
update_vocab def update_vocab ( self , wordle_state : WordleState ) -> Vocabulary입력 :
wordle_state: WordleState - 알려진 문자 제약 세트를 나타내는 Wordle State 객체. 반환 : wordle_state 에 따라 필터링되는 새로운 Vocabulary 개체.
__str__ def __str__ ( self ) -> str반환 : 터미널에 인쇄하기위한 필터링 된 단어 목록의 문자열 표현.
WordleEnvironment 어휘 객체를 입력으로 받아 들여 환경에서 가능한 올바른 단어 세트를 정의합니다.
from wordle . wordle_env import WordleEnvironment
from wordle . wordle_game import Vocabulary
from utils . misc import convert_path
vocab = Vocabulary . from_file ( convert_path ( 'data/wordle/word_lists/wordle_official.txt' ))
env = WordleEnvironment ( vocab )
initial_obs = env . reset ()
next_obs , reward , terminal = env . step ( "snake" ) 위에서 볼 수 있듯이 환경은 src/wordle/wordle_env.py 의 체육관과 같은 인터페이스를 구현합니다.
__init__ def __init__ ( self , vocab : Vocabulary ) -> None입력 :
vocab: Vocabulary - 환경의 어휘. 반품 : None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]입력 :
action: Vocabulary - 환경에서 에이전트의 행동을 나타내는 일련의 텍스트.반품 : (관찰, 보상, 터미널) 튜플.
reset def reset ( self ) -> WordleObservation반환 : 관찰.
is_terminal def is_terminal ( self ) -> bool반품 : 상호 작용이 종료되었는지를 나타내는 부울.
우리는 다양한 게임 플레이 레벨을 다루는 수제 수작업 정책 세트를 구현합니다. 이들 모두는 src/wordle/policy.py 에서 구현됩니다. 여기서 우리는 각각을 설명합니다.
UserPolicy from wordle . policy import UserPolicy
policy = UserPolicy ( hint_policy = None , vocab = None )설명:
터미널에서 플레이합시다.
입력 :
hint_policy: Optional[Policy] - 어떤 단어를 사용할 것인지에 대한 힌트를 원할 경우 쿼리해야 할 다른 정책.vocab: Optional[Union[str, Vocabulary]] - 추측 가능한 단어의 Vocabulary . 지정되지 않으면 5 글자 순서의 숯이 유효한 추측입니다. StartWordPolicy from wordle . policy import StartWordPolicy
policy = StartWordPolicy ()설명:
첫 번째 단어에만 적용됩니다. 선별 된 고품질 시작 단어 목록에서 단어를 무작위로 선택합니다.
입력 :
start_words: Optional[List[str]]=None - 선별 된 시작 단어 목록을 무시합니다. OptimalPolicy from wordle . policy import OptimalPolicy
policy = OptimalPolicy ()설명:
근시 적으로 알려진 모든 문자 제약을 충족시키는 단어 목록에서 가장 높은 정보를 얻습니다. 최적의 플레이는 NP- 하드 이므로이 정책은 실제로 최적이 아닙니다. 그러나 그것은 매우 높은 수준에서 재생되며 대략적인 성능 상한으로 사용될 수 있습니다. 이 정책은 단어 목록 크기의 성능 2 차로 계산에 매우 느립니다. 계산을 저장하려면 self.cache.load(f_path) 및 self.cache.dump() 사용하면 캐시를로드하고 저장할 수 있습니다. 예를 들어, data/wordle/optimal_policy_cache_wordle_official.pkl wordle_official.txt Word List 의이 정책에 대한 캐시를 나타냅니다.
입력 :
start_word_policy: Optional[Policy]=None - 첫 번째 단어는 일반적으로 정보 이득을 계산하는 데 가장 비싸기 때문에 첫 번째 단어 만 호출 할 다른 정책을 지정할 수 있습니다.progress_bar: bool=False - 계산하는 데 시간이 오래 걸릴 수 있으므로 self.act 에 대한 각 호출에 대한 진행률 표시 줄을 표시하는 옵션을 남깁니다. RepeatPolicy from wordle . policy import RepeatPolicy
policy = RepeatPolicy ( start_word_policy = None , first_n = 2 )설명:
이미 사용 된 first_n 단어 중 하나를 무작위로 반복합니다. 이것은 첫 번째 단어에서 운이 좋지 않으면 결코 이길 수 없기 때문에 최대의 차선책입니다.
입력 :
start_word_policy: Optional[Policy] - 첫 번째 단어를 선택하는 데 사용할 정책. None 환경 어휘에서 단어를 무작위로 선택하십시오.first_n: Optional[int] - 정책은 역사상 first_n 단어에서 다음 단어를 무작위로 선택합니다. None 전체 기록에서 무작위로 선택합니다. RandomMixturePolicy from wordle . policy import RandomMixturePolicy
policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )설명:
확률 (1 - prob_smart) 이있는 단어 목록에서 무작위로 완전한 단어를 선택하고 확률 prob_smart 있는 모든 알려진 문자 제약 조건을 충족하는 단어 목록에서 임의의 단어를 선택합니다.
입력 :
prob_smart: float - 무작위로 완전히 알려진 문자 제약을 충족시키는 단어를 선택할 확률.vocab: Optional[Union[str, Vocabulary]] - 선택할 단어 목록. None 정책은 기본적으로 환경의 단어 목록으로 기본적으로 나타납니다. WrongPolicy from wordle . policy import WrongPolicy
from wordle . wordle_game import Vocabulary
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
policy = WrongPolicy ( vocab )설명:
알려진 모든 문자 제약을 충족시키지 못하는 단어 목록에서 단어를 무작위로 선택하여 올바른 단어가 될 수는 없습니다. 단어 목록의 모든 단어가 문자 제약을 충족하면 목록에서 무작위로 단어를 선택합니다. 이 정책은 매우 차선책입니다.
입력 :
vocab: Union[str, Vocabulary] - 선택할 단어 목록. MixturePolicy from wordle . policy import MixturePolicy , OptimalPolicy , RandomMixturePolicy
policy1 = OptimalPolicy ()
policy2 = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MixturePolicy ( prob1 = 0.5 , policy1 = policy1 , policy2 = policy2 )설명:
주어진 두 가지 정책을 혼합합니다. 확률 prob1 사용하여 policy1 에서 선택하고 확률 (1 - prob1) 있는 policy2 에서 선택하십시오.
입력 :
prob1: float - policy1 에서 조치를 선택할 확률 1.policy1: Policy - 조치를 선택하는 첫 번째 정책. 확률 prob1 로 선택됩니다.policy1: Policy - 조치를 선택하는 두 번째 정책. 확률 (1 - prob1) 으로 선택됩니다. MonteCarloPolicy from wordle . policy import MonteCarloPolicy
sample_policy = RandomMixturePolicy ( prob_smart = 0.5 , vocab = None )
policy = MonteCarloPolicy ( n_samples = 5 , sample_policy = sample_policy )설명:
정책을 취하고 환경에서 Monte Carlo 롤아웃의 n_samples 실행하고 롤아웃 과정에서 가장 높은 평균 보상을받은 다음 조치를 선택합니다.
입력 :
n_samples: int - 실행할 Monte Carlo 롤아웃 수.sample_policy: Policy - 롤아웃을 샘플링하는 정책. 
위의 정책 중 하나는 오프라인 RL 에이전트를 훈련시키는 데 사용할 수있는 데이터 세트를 생성하는 데 사용될 수 있습니다. 우리는 src/wordle/wordle_dataset.py 에서 두 가지 종류의 합성 데이터 세트를 구현합니다.
wordle.wordle_dataset.WordleListDataset - 파일에서 Wordle Games를로드합니다.wordle.wordle_dataset.WordleIterableDataset - 주어진 정책에서 샘플 웨더 게임.WordleListDataset :같은 파일에서 Wordle 데이터 세트를로드하십시오.
from wordle . wordle_dataset import WordleListDataset
from data . rl_data import ConstantTokenReward
data = WordleListDataset . from_file (
file_path = 'data/wordle/expert_wordle_100k.pkl' ,
max_len = None ,
vocab = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
for i in range ( data . size ()):
item = data . get_item ( i )__init__ def __init__ ( self , items : List [ Tuple [ WordleObservation , Optional [ Dict [ str , Any ]]]], max_len : Optional [ int ], token_reward : TokenReward ) -> None입력 :
items: List[Tuple[WordleObservation, Optional[Dict[str, Any]]]] - (wordleobservation, metadata_dict)의 튜플 형태의 데이터 목록. Metadata_dict의 모든 종류의 메타 데이터는 데이터 포인트에 저장할 수있는 모든 종류의 메타 데이터입니다.max_len: Optional[int] - 데이터 세트의 최대 시퀀스 길이는 모든 토큰 시퀀스를이 길이로 잘립니다. None 시퀀스가 잘리지 않습니다.token_reward: TokenReward 시퀀스에 적용 할 토큰 수준의 보상. 우리는 모든 실험에 대해 끊임없는 보상을 사용합니다. 반품 : None
from_file def from_file ( cls , file_path : str , max_len : Optional [ int ], vocab : Optional [ Vocabulary ], token_reward : TokenReward ) -> WordleListDataset입력 :
file_path: str - 데이터 피클 파일의 경로.max_len: Optional[int] - 데이터 세트의 최대 시퀀스 길이는 모든 토큰 시퀀스를이 길이로 잘립니다. None 시퀀스가 잘리지 않습니다.vocab: Optional[Vocabulary] - 다른 환경 어휘에서 데이터 세트를 시뮬레이션합니다. None 경우 기본값은 데이터 세트를 작성하는 데 사용 된 것과 동일한 어휘를 사용하는 것입니다.token_reward: TokenReward 시퀀스에 적용 할 토큰 수준의 보상. 우리는 모든 실험에 대해 끊임없는 보상을 사용합니다. 반환 : WordleListDataset 객체.
get_item def get_item ( self , idx : int ) -> DataPoint입력 :
idx: int - 데이터 세트의 인덱스. 반환 : DataPoint 객체.
size def size ( self ) -> int반환 : 데이터 세트의 크기.
scripts/data/wordle/ 의 다음 스크립트는 Wordle 데이터를 종합하는 데 사용할 수 있습니다.
| 스크립트 | 설명 |
|---|---|
generate_data.py | 구성에 지정된 주어진 정책의 여러 게임을 샘플링하고 파일에 저장합니다. |
generate_data_mp.py | 여러 프로세스에서 샘플 게임을 제외하고 generate_data.py 와 동일합니다. |
generate_adversarial_data.py | 단일 단계 RL 방법과 다중 단계 방법의 차이를 보여주기 위해 설계된 논문의 섹션 5에 설명 된 데이터 세트를 종합합니다. |
generate_adversarial_data_mp.py | 여러 프로세스에서 샘플 게임을 제외하고 generate_adversarial_data.py 와 동일합니다. |
generate_data_branch.py | 주어진 "전문가"정책에서 게임을 샘플링 한 다음 게임의 각 행동에서 "차선책"정책은 다수의 새로운 게임을 샘플링합니다. |
generate_data_branch_mp.py | 여러 프로세스에서 샘플 게임을 제외하고 generate_data_branch.py 와 동일합니다. |
제공된 합성 Wordle 데이터 세트는 data/wordle/ 에 있습니다.
| 파일 | 설명 |
|---|---|
expert_wordle_100k_1.pkl | OptimalPolicy 에서 샘플링 된 100K 게임. |
expert_wordle_100k_2.pkl | 또 다른 100k 게임은 OptimalPolicy 에서 샘플링되었습니다. |
expert_wordle_adversarial_20k.pkl | 단일 단계 RL 방법과 다중 단계 방법의 차이를 보여주기 위해 설계된 논문의 섹션 5에 설명 된 데이터 세트. |
expert_wordle_branch_100k.pkl | 100k 게임은 WrongPolicy 에서 OptimalPolicy 의 generate_data_branch.py 사용하여 샘플링했습니다. |
expert_wordle_branch_150k.pkl | OptimalPolicy 에서 WrongPolicy 의 generate_data_branch.py 사용하여 샘플링 된 또 다른 150K 게임. |
expert_wordle_branch_2k_10sub.pkl | 2K 게임은 generate_data_branch.py 사용하여 샘플링하여 OptimalPolicy 에서 샘플링 된 액션 당 10 개의 분기가있는 WrongPolicy 의 분기에서 expert_wordle_branch_100k.pkl 보다 훨씬 더 차선책 데이터가 있습니다. |
expert_wordle_branch_20k_10sub.pkl | 2K 게임 대신 20k 게임을 제외하고 expert_wordle_branch_2k_10sub.pkl 과 동일합니다. |
WordleIterableDataset :SO와 같은 정책에서 Wordle 데이터 샘플링을 생성합니다.
from wordle . wordle_dataset import WordleIterableDataset
from wordle . policy import OptimalPolicy
from data . rl_data import ConstantTokenReward
policy = OptimalPolicy ()
vocab = Vocabulary . from_file ( 'data/wordle/word_lists/wordle_official.txt' )
data = WordleIterableDataset (
policy = policy ,
vocab = vocab ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 ),
)
while True :
item = data . sample_item ()__init__ def __init__ ( self , policy : Policy , vocab : Vocabulary , max_len : Optional [ int ], token_reward : TokenReward ) -> None입력 :
policy: Policy - 샘플링 할 정책.vocab: Vocabulary - 환경의 어휘.max_len: Optional[int] - 데이터 세트의 최대 시퀀스 길이는 모든 토큰 시퀀스를이 길이로 잘립니다. None 시퀀스가 잘리지 않습니다.token_reward: TokenReward 시퀀스에 적용 할 토큰 수준의 보상. 우리는 모든 실험에 대해 끊임없는 보상을 사용합니다. 반품 : None
sample_item def sample_item ( self ) -> DataPoint 반환 : DataPoint 객체.
우리는 다음과 같은 Wordle 게임의 200k 이상의 트윗에 대한 대규모 데이터 세트를 가지고 있습니다.
우리는 이러한 색상 전환 제곱에 단어를 개조하여 Wordle 게임의 실제 데이터 세트를 만들 수 있습니다.
원시 트윗 데이터는 data/wordle/tweets.csv 에 나와 있지만, 사용할 수 있으려면 실제 단어를 트윗의 색상 사각형에 개조해야합니다. 이 개조 프로세스를 수행하려면 어휘 목록에서 발생할 수있는 모든 가능한 색상 전환을 캐시하는 전처리 스크립트를 실행해야합니다. guess_vocab (추측 가능한 단어 세트) 및 correct_vocab (환경에서 가능한 올바른 단어 세트). 결과는 wordle.wordle_dataset.WordleHumanDataset 트윗에서 유효한 Wordle 게임을 종합하는 데 사용하는 데이터 구조입니다. 이 스크립트는 scripts/data/wordle/build_human_datastructure.py 입니다. 다음과 같은 스크립트를 호출하십시오.
cd scripts/data/wordle/
python build_human_datastructure.py --guess_vocab=../../../data/wordle/word_lists/wordle_official.txt --correct_vocab=../../../data/wordle/word_lists/wordle_official.txt --tweets_file=../../../data/wordle/tweets.csv --output_file=../../../data/wordle/random_human_tweet_data.json스크립트의 args :
--guess_vocab 추측 가능한 단어 세트를 지정합니다.--correct_vocab 환경에서 가능한 올바른 단어 세트를 지정합니다.--tweets_file 트윗의 원시 CSV 파일을 지정합니다--output_file 출력을 덤프 할 위치를 지정합니다. 우리는 일부 단어 목록에서 전처리를 실행했으며 결과는 data/wordle/ 에 저장되었습니다.
| 단어 목록 | 전처리 트윗 데이터 파일 |
|---|---|
wordle_official.txt | random_human_tweet_data.json |
wordle_official_800.txt | random_human_tweet_data_800.json |
wordle_official_400.txt | random_human_tweet_data_400.json |
wordle_official_200.txt | random_human_tweet_data_200.json |
tweet_words.txt | human_tweet_data_true_word.json |
이 파일 중 하나가 주어지면 Wordle Tweet 데이터 세트를 다음과 같이로드 할 수 있습니다.
from wordle . wordle_dataset import WordleHumanDataset
data = WordleHumanDataset . from_file ( 'data/wordle/random_human_tweet_data_200.json' )
print ( data . sample_item ()) 우리는 실험에서 'data/wordle/random_human_tweet_data_200.json' 사용했습니다.
WordleHumanDataset : __init__ def __init__ ( self , games : List [ Tuple [ str , List [ str ]]], transitions : Dict [ str , Dict [ str , List [ str ]]], use_true_word : bool , max_len : Optional [ int ], token_reward : TokenReward , game_indexes : Optional [ List [ int ]], top_p : Optional [ float ]) -> None입력 :
games: List[Tuple[str, List[str]]] - 형식의 튜플 목록 (correct_wordle_word, wordle_transitions_list) wordle_transitions_list 과 같은 트윗의 색상을 나타내는 전환 목록입니다 ["<b><b><y><y><b>", "<g><b><b><b><b>", "<g><g><y><b><b>", "<g><g><g><g><g>"] .transitions: Dict[str, Dict[str, List[str]]] - 올바른 워들 단어를 다른 DICT 매핑 가능한 컬러 전환에 해당 단어에 의해 유도 될 수있는 색상 전환을 그 전환을 유발할 수있는 단어 목록으로 매핑하는 DICT. 이 데이터 구조는 단어를 트윗에 개조하는 데 사용됩니다.use_true_word: bool - True 인 경우 트윗에서지면 진실의 올바른 단어를 사용하십시오.max_len: Optional[int] - 데이터 세트의 최대 시퀀스 길이는 모든 토큰 시퀀스를이 길이로 잘립니다. None 시퀀스가 잘리지 않습니다.token_reward: TokenReward 시퀀스에 적용 할 토큰 수준의 보상. 우리는 모든 실험에 대해 끊임없는 보상을 사용합니다.game_indexes: Optional[List[int]] - 트윗 분할을 만들기위한 인덱스 목록. None 데이터의 모든 항목이 사용됩니다. 우리는 data/wordle/human_eval_idxs.json 과 data/wordle/human_train_idxs.json 무작위로 선택된 열차 및 평가 분할으로 생성되었습니다.top_p: Optional[float] - 데이터의 top_p 을 수행하는 필터. None 데이터가 필터링되지 않습니다. %BC 모델과 함께 사용됩니다. 반품 : None
from_file def from_file ( cls , file_path : str , use_true_word : bool = False , max_len : Optional [ int ] = None , token_reward : Optional [ TokenReward ] = None , top_p : Optional [ float ] = None ) -> WordleHumanDataset입력 :
file_path: str - 데이터를로드하기 위해 JSON 파일의 경로.use_true_word: bool - True 인 경우 트윗에서지면 진실의 올바른 단어를 사용하십시오.max_len: Optional[int] - 데이터 세트의 최대 시퀀스 길이는 모든 토큰 시퀀스를이 길이로 잘립니다. None 시퀀스가 잘리지 않습니다.token_reward: TokenReward 시퀀스에 적용 할 토큰 수준의 보상. 우리는 모든 실험에 대해 끊임없는 보상을 사용합니다.game_indexes: Optional[List[int]] - 트윗 분할을 만들기위한 인덱스 목록. None 데이터의 모든 항목이 사용됩니다. 우리는 data/wordle/human_eval_idxs.json 과 data/wordle/human_train_idxs.json 무작위로 선택된 열차 및 평가 분할으로 생성되었습니다.top_p: Optional[float] - 데이터의 top_p 을 수행하는 필터. None 데이터가 필터링되지 않습니다. %BC 모델과 함께 사용됩니다. 반환 : WordleHumanDataset 객체.
sample_item def sample_item ( self ) -> DataPoint 반환 : DataPoint 객체.
교육 스크립트는 scripts/train/wordle/ 에 있습니다.
| 스크립트 | 설명 |
|---|---|
train_bc.py | BC 에이전트를 훈련시킵니다. |
train_iql.py | ILQL 에이전트를 훈련하십시오. |
평가 스크립트는 scripts/eval/wordle/ 에 있습니다.
| 스크립트 | 설명 |
|---|---|
eval_policy.py | Wordle 환경에서 BC 또는 ILQL 에이전트를 평가하십시오. |
eval_q_rank.py | 단일 단계 RL과 다중 단계 RL 간의 차이를 보여주기 위해 설계된 논문의 5 절에 설명 된 합성 데이터 세트에서 훈련 된 에이전트에 대한 Q 값의 상대 순위를 비교하기위한 평가 스크립트. |
distill_policy_eval.py | eval_policy.py 의 결과를 오류 막대와 함께 인쇄합니다. |
여기서 우리는 코드베이스에서 시각적 대화 데이터를로드하는 방법과 환경을 실행하는 방법을 간략하게 설명합니다. 시각적 대화 환경의 원격 구성 요소를 설정하는 방법은 위의 설정 섹션을 참조하십시오. 데이터 및 환경 객체는 구성 관리자가 자동으로로드하지만 구성 시스템을 우회하고 고유 한 코드베이스로 환경을 사용하려는 경우 이러한 객체를로드, 실행 및 구성하는 방법이 있습니다. 아래에 설명 된 동일한 설정을 구성에서 모두 수정할 수 있습니다.
시각적 대화 환경을로드하는 방법의 예 :
from visdial . visdial_env import VDEnvironment
from visdial . visdial_base import VisDialogueData
from visdial . visdial_dataset import VisDialListDataset
from data . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = VisDialogueData (
data_path = convert_path ( 'data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.json' ),
img_feat_path = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/data_img.h5' ),
split = 'train' ,
reward_cache = convert_path ( 'data/vis_dialogue/processed/visdial_0.5/train_rank_reward_cache1.json' ),
yn_reward_kind = 'none'
)
list_data = VisDialListDataset (
data = data ,
max_len = None ,
token_reward = ConstantTokenReward ( 0.0 )
)
env = VDEnvironment (
dataset = list_data ,
url = 'http://localhost:5000/step_rank' ,
yn_reward = - 2.0 ,
yn_reward_kind = 'none'
)
print ( env . reset ()) 위의 스크립트는 '표준'보상 실험에 대한 데이터 세트 및 환경을 구성한 방법에 해당하지만 데이터 세트를 다르게 구성하려면 수정할 수있는 많은 인수가 있습니다. 데이터 세트 분할을 변경하는 것 외에도 이러한 인수는 작업이나 보상을 변경할 수도 있습니다. 아래에서는 VisDialogueData , VisDialListDataset 및 VDEnvironment 취하는 모든 구성 가능한 매개 변수를 설명합니다.
우리는 VisDialogueData , VisDialListDataset 및 VDEnvironment 의 매개 변수와 방법을 문서화하므로 환경을 직접 구성하는 방법을 알고 있습니다.
VisDialogueData : src/visdial/visdial_base.py 에서 구현 된 VisDialogueData 는 작업의 대화 및 보상 세트를 저장합니다.
__init__ def __init__ ( self , data_path : str , img_feat_path : str , split : str , reward_cache : Optional [ str ] = None , norm_img_feats : bool = True , reward_shift : float = 0.0 , reward_scale : float = 1.0 , addition_scenes : Optional [ List [ Scene ]] = None , mode : str = 'env_stops' , cutoff_rule : Optional [ CutoffRule ] = None , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> None입력 :
data_path: str - 대화 데이터의 경로. 다음 중 하나 여야합니다.data/vis_dialogue/raw/visdial_0.5/visdial_0.5_train.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_val.jsondata/vis_dialogue/raw/visdial_0.5/visdial_0.5_test.jsonimg_feat_path: str - 각 대화에 대한 보상을 계산하는 데 사용되는 이미지 기능의 경로. 항상 data/vis_dialogue/processed/visdial_0.5/data_img.h5 여야합니다.split: str - train , val 또는 test 중 하나. 사용할 이미지 기능의 데이터 세트 분할을 나타냅니다. data_path 분할과 일치해야합니다.reward_cache: Optional[str]=None - 각 대화에 대한 보상이 저장됩니다. None 모든 보상을 None . 우리는 두 가지 보상 기능에 대한 캐시를 제공합니다.data/vis_dialogue/processed/visdial_0.5/[split]_rank_reward_cache1.json , [split] 은 train , val 또는 test 중 하나로 대체됩니다.data/vis_dialogue/processed/visdial_0.5/[split]_reward_cache2.json , 여기서 [split] 은 train , val 또는 test 중 하나로 대체됩니다.norm_img_feats: bool=True - 이미지 기능을 정규화할지 여부.reward_shift: float=0.0 - 보상을이 금액으로 바꿉니다.reward_scale: float=1.0 - 보상을이 금액으로 확장하십시오.addition_scenes: Optional[List[Scene]]=None - 데이터 세트에 추가 데이터를 주입합니다.mode: str='env_stops' - ['agent_stops', 'env_stops', '10_stop'] . 작업의 일부 속성을 제어합니다. 우리는 env_stops 사용합니다mode='env_stops' 는 cutoff_rule 에 따라 환경 상호 작용을 일찍 중지하십시오.mode='agent_stops' 경우 에이전트는 작업 중에 특수 <stop> 토큰을 생성하여 상호 작용을 중지합니다. 가능한 모든 조치 후에 <stop> 배치하여 데이터를 보강합니다.mode='10_stop' 인 경우 시각적 대화 데이터 세트에서 표준과 같이 10 라운드 상호 작용 후에 플레이는 항상 중지됩니다.cutoff_rule: Optional[CutoffRule]=None - mode='env_stops' 인 경우에만 적용됩니다. 환경이 상호 작용을 일찍 중지 해야하는시기를 결정하는 함수를 구현합니다. 우리는 모든 실험에서 visdial.visdial_base.PercentileCutoffRule(1.0, 0.5) 의 기본값을 사용합니다.yn_reward: float=-2.0 예/아니오 질문을 요청하기 위해 추가 해야하는 보상 형벌.yn_reward_kind: str='none' - 예/아니오 질문이 있는지 결정하는 데 사용하도록 문자열 일치 휴리스틱을 지정합니다. ['none', 'soft', 'hard', 'conservative'] 중 하나 여야합니다.'none' : 예/아니오 질문을 처벌하지 마십시오. 이것은 우리 논문의 standard 보상에 해당합니다.'soft' : 응답에 "yes" 또는 "no" 포함 된 경우 질문을 벌금을 부과합니다.'hard' : 응답이 문자열 "yes" 또는 "no" 와 정확히 일치하는 경우 질문을 처벌합니다. 이것은 우리 논문의 "y/n" 보상에 해당합니다.'conservative' : 응답이 여러 문자열과 일치하는 휴리스틱 중 하나를 만족하는 경우 질문을 벌이십시오. 이것은 우리 논문의 "conservative y/n" 보상에 해당합니다. 반품 : None
__len__ def __len__ ( self ) -> int반환 : 데이터 세트의 크기.
__getitem__ def __getitem__ ( self , i : int ) -> Scene입력 :
i: int - 데이터 세트 인덱스.반환 : 데이터 세트의 항목.
VisDialListDataset : src/visdial/visdial_dataset.py 에서 구현 된 VisDialListDataset VisDialogueData 감싸고 오프라인 RL 에이전트를 훈련시키는 데 사용할 수있는 DataPoint 형식으로 변환합니다.
__init__ def __init__ ( self , data : VisDialogueData , max_len : Optional [ int ], token_reward : TokenReward , top_p : Optional [ float ] = None , bottom_p : Optional [ float ] = None ) -> None입력 :
data: VisDialogueData - 모든 원시 데이터를 저장하는 시각적 대화 데이터 객체입니다.max_len: Optional[int] - 데이터 세트의 최대 시퀀스 길이는 모든 토큰 시퀀스를이 길이로 잘립니다. None 시퀀스가 잘리지 않습니다.token_reward: TokenReward 시퀀스에 적용 할 토큰 수준의 보상. 우리는 모든 실험에 대해 끊임없는 보상을 사용합니다.top_p: Optional[float] - 데이터의 top_p 을 수행하는 필터. None 데이터가 필터링되지 않습니다. %BC 모델과 함께 사용됩니다.bottom_p: Optional[float] - 데이터의 수행 bottom_p 을 수행하는 필터. None 데이터가 필터링되지 않습니다. 반품 : None
size def size ( self ) -> int반환 : 데이터 세트의 크기.
get_item def get_item ( self , idx : int ) -> DataPoint입력 :
i: int - 데이터 세트 인덱스. 반환 : 데이터 세트의 DataPoint .
VDEnvironment : src/visdial/visdial_env.py 에서 구현 된 VDEnvironment 오프라인 RL 에이전트가 평가 시간에 상호 작용하는 시각적 대화 환경을 정의합니다. 환경에는 로컬 호스트 서버에 연결하는 것이 포함되며 설정 섹션에서 회전하는 방법을 설명합니다.
__init__ def __init__ ( self , dataset : RL_Dataset , url : str , reward_shift : float = 0.0 , reward_scale : float = 1.0 , actor_stop : bool = False , yn_reward : float = - 2.0 , yn_reward_kind : str = 'none' ) -> None입력 :
dataset: RL_Dataset - RL_Dataset 취합니다. 위와 같이 구체적으로 VisDialListDataset . 이 데이터 세트는 초기 상태를 선택하는 데 사용됩니다.url: str - 환경을 밟는 URL. 이 URL에 해당하는 LocalHost 웹 서버를 초기화하는 방법에 대한 설정 섹션의 지침을 따르십시오.reward_shift: float=0.0 - 보상을이 금액으로 바꿉니다.reward_scale: float=1.0 - 보상을이 금액으로 확장하십시오.actor_stop: bool=False - 액터가 특별한 <stop> 토큰을 생성하여 일찍 상호 작용을 중지하도록 허용합니다.yn_reward: float=-2.0 예/아니오 질문을 요청하기 위해 추가 해야하는 보상 형벌.yn_reward_kind: str='none' - 예/아니오 질문이 있는지 결정하는 데 사용하도록 문자열 일치 휴리스틱을 지정합니다. ['none', 'soft', 'hard', 'conservative'] 중 하나 여야합니다.'none' : 예/아니오 질문을 처벌하지 마십시오. 이것은 우리 논문의 standard 보상에 해당합니다.'soft' : 응답에 "yes" 또는 "no" 포함 된 경우 질문을 벌금을 부과합니다.'hard' : 응답이 문자열 "yes" 또는 "no" 와 정확히 일치하는 경우 질문을 처벌합니다. 이것은 우리 논문의 "y/n" 보상에 해당합니다.'conservative' : 응답이 여러 문자열과 일치하는 휴리스틱 중 하나를 만족하는 경우 질문을 벌이십시오. 이것은 우리 논문의 "conservative y/n" 보상에 해당합니다. 반품 : None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]입력 :
action: Vocabulary - 환경의 어휘반품 : (관찰, 보상, 터미널) 튜플.
reset def reset ( self ) -> WordleObservation반환 : 관찰
is_terminal def is_terminal ( self ) -> bool반품 : 상호 작용이 종료되었는지를 나타내는 부울.
교육 스크립트는 scripts/train/vis_dial/ 입니다.
| 스크립트 | 설명 |
|---|---|
train_bc.py | BC 에이전트를 훈련시킵니다. |
train_chai.py | 차이 요원을 훈련시킵니다. |
train_cql.py | CQL 에이전트를 훈련하십시오. |
train_dt.py | 의사 결정 변압기 에이전트를 훈련하십시오. |
train_iql.py | ILQL 에이전트를 훈련하십시오. |
train_psi.py | 훈련 |
train_utterance.py | 발화 수준의 ILQL 에이전트를 훈련하십시오. |
평가 스크립트는 scripts/eval/vis_dial/ 입니다.
| 스크립트 | 설명 |
|---|---|
eval_policy.py | 시각적 대화 환경에서 에이전트를 평가하십시오. |
top_advantage.py | 모델에서 가장 큰 이점을 가진 질문을 찾습니다. |
distill_policy_eval.py | eval_policy.py 의 결과를 오류 막대와 함께 인쇄합니다. |
Here we outline how to load the Reddit comments data in our codebase and how to execute the environment. See the setup section above for how to setup the toxicity filter reward. The data and environment objects are loaded automatically by the config manager, but if you want to by-pass the config system and use the task with your own codebase, here's how you should load, execute, and configure these objects. The same settings described below can all be modified in the configs as well.
An example of how to load the Reddit comment environment:
from toxicity . toxicity_env import ToxicityEnvironment
from toxicity . reddit_comments_base import RedditData
from toxicity . reward_fs import toxicity_reward
from utils . misc import convert_path
idxs = json . load ( open ( convert_path ( 'data/reddit_comments/train_idxs.json' ), 'r' ))
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = idxs ,
reward_f = toxicity_reward
)
env = ToxicityEnvironment (
data = data ,
reward_f = toxicity_reward
)
print ( env . reset ())
The above script corresponds to how we configured the environment for our toxicity reward experiments, but if you want to configure the environment differently, there are a few arguments you can modify. These arguments can also change the task or reward. Below we describe all the different configurable parameters that our reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment take.
We document the parameters and methods for our different Reddit comment reward functions, RedditData , ToxicityListDataset , and ToxicityEnvironment , so that you know how to configure the environment yourself.
Here we outline the 4 main reward functions we use for our Reddit comment task. Each of these rewards is implemented in src/toxicity/reward_fs.py .
toxicity_reward from toxicity . reward_fs import toxicity_reward
reward_f = toxicity_reward ()설명:
The "toxicity" reward from our paper, which queries the GPT-3 toxicity filter. It assigns a value of "0" to non-toxic comments, a value of "1" to moderately toxic comments, and a value of "2" to very toxic comments.
toxicity_noised_reward from toxicity . reward_fs import toxicity_noised_reward
reward_f = toxicity_noised_reward ()설명:
The "noised toxicity" reward from our paper, which is the same as toxicity_noised_reward but induces additional noise. Specifically, it re-assigns comments labeled as "1" (moderately toxic) to either "0" (non-toxic) or "2" (extremely toxic) with equal probability.
score_human_reward from toxicity . reward_fs import score_human_reward
from utils . misc import convert_path
reward_f = score_human_reward (
reddit_path = convert_path ( 'data/reddit_comments/' ),
indexes = None
)설명:
The "upvotes real" reward from our paper, which gives a reward of +1 for positive upvote comments and -1 for negative upvote comments. This uses the ground truth upvotes in the data, so it only applies to comments in the dataset and cannot be used for evaluation. If you input a string not present in the data, it will error. The arguments to this function specify what data to load.
Inputs:
reddit_path: str – a path to the data.indexes: List[int] – a split of indexes in the data to use. If None , it considers all the data. model_reward from toxicity . reward_fs import score_human_reward
from toxicity . reddit_comments_base import RedditData
from toxicity . toxicity_dataset import ToxicityListDataset
from toxicity . reward_model import RobertaBinaryRewardModel
from utils . rl_data import ConstantTokenReward
from utils . misc import convert_path
data = RedditData (
path = convert_path ( 'data/reddit_comments/' ),
indexes = None ,
reward_f = None
)
listdata = ToxicityListDataset (
data = data ,
max_len = 512 ,
token_reward = ConstantTokenReward ( 0.0 )
)
model = RobertaBinaryRewardModel (
data = listdata ,
device = 'cuda' ,
roberta_kind = 'roberta-base' ,
freeze_roberta = False ,
reward_cuttoff = 0.0
)
model . load_state_dict ( torch . load ( convert_path ( 'outputs/toxicity/upvote_reward/model.pkl' ), map_location = 'cpu' ))
reward_f = score_human_reward ( model = model )설명:
The "upvotes model" reward from our paper, which gives a reward of +1 if the given model predicts that the comment will get a positive number of upvotes and a reward of -1 otherwise. The model checkpoint we used for our experiments is at: outputs/toxicity/upvote_reward/model.pkl
Inputs:
model: RewardModel : the reward model implemented in src/toxicity/reward_model.py . The model should be first trained and loaded from a pytorch checkpoint.RedditData : RedditData , implemented in src/toxicity/reddit_comments_base.py , stores the raw Reddit comments data.
__init__ def __init__ ( self , path : str , indexes : Optional [ List [ int ]], reward_f : Optional [ Callable [[ str ], float ]], reward_cache : Optional [ Cache ] = None , reward_shift : float = 0.0 , reward_scale : float = 1.0 ) -> NoneInputs:
path: str – the path to the Reddit data.indexes: Optional[List[int]] – a list of indexes to create a split of the data. Randomly selected, training, validation, and test splits are in the json files:data/reddit_comments/train_idxs.jsondata/reddit_comments/eval_idxs.jsondata/reddit_comments/test_idxs.jsonreward_f: Optional[Callable[[str], float]] – the reward function to use.reward_cache: Optional[Cache]=None – a cache of reward values, so you don't have to recompute them everytime.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount. Returns: None
__len__ def __len__ ( self ) -> intReturns: the size of the dataset.
__getitem__ def __getitem__ ( self , idx : int ) -> SceneInputs:
idx: int – the dataset index.Returns: an item from the dataset.
ToxicityListDataset : ToxicityListDataset , implemented in src/toxicity/toxicity_dataset.py , wraps around RedditData and converts it into a DataPoint format that can be used to train offline RL agents.
__init__ def __init__ ( self , data : RedditData , max_len : Optional [ int ], token_reward : TokenReward , cuttoff : Optional [ float ] = None , resample_timeout : float = 0.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – a Reddit comment data object that stores all the raw data.max_len: Optional[int] – the maximum sequence length in the dataset, will truncate all token sequences to this length. If None , then sequences will not be truncated.token_reward: TokenReward – the token-level reward to apply to the sequences. We use a constant reward of 0 per-token for all experiments.cuttoff: Optional[float]=None – filter out all comments from the dataset with reward less than cuttoff . If None , no data will be filtered. Used with %BC models.resample_timeout: float=0.0 – when cuttoff is not equal to None , comments are stochastically sampled iid from the dataset, like an iterable, even though the dataset has a list-type interface. It uniformly re-samples from the dataset until it finds a comment with a reward that satisfies the cuttoff. In the case of the "toxicity" reward, this re-sampling can cause rate-limit errors on the GPT-3 API, so we allow you to add a resample_timeout to fix this issue: a timeout of roughly 0.05 should fix rate-limit issues.include_parent: bool=True – whether to condition on the parent comment in the thread. If False , models will be trained to generate comments unconditionally. Returns: None
size def size ( self ) -> intReturns: the size of the dataset.
get_item def get_item ( self , idx : int ) -> DataPointInputs:
i: int – the dataset index. Returns: a DataPoint from the dataset.
ToxicityEnvironment : ToxicityEnvironment , implemented in src/toxicity/toxicity_env.py , defines the Reddit comment generation environment, which our offline RL agents interact with at evaluation time.
__init__ def __init__ ( self , data : RedditData , reward_f : Optional [ Callable [[ str ], float ]], reward_shift : float = 0.0 , reward_scale : float = 1.0 , include_parent : bool = True ) -> NoneInputs:
data: RedditData – the dataset used to select initial state parent comments to condition on.reward_f: Optional[Callable[[str], float]] – the reward function to use.reward_shift: float=0.0 – shift the reward by this amount.reward_scale: float=1.0 – scale the reward by this amount.include_parent: bool=True – specifies whether to condition on the previous comment or post in the Reddit thread. Returns: None
step def step ( self , action : str ) -> Tuple [ WordleObservation , float , bool ]Inputs:
action: Vocabulary – the environment's vocabularyReturns: an (observation, reward, terminal) tuple.
reset def reset ( self ) -> WordleObservationReturns: an observation
is_terminal def is_terminal ( self ) -> boolReturns: a boolean indicating if the interaction has terminated.
Training scripts are in scripts/train/toxicity/ .
| 스크립트 | 설명 |
|---|---|
train_bc.py | Train a BC agent. |
train_iql.py | Train an ILQL agent. |
train_upvote_reward.py | Train the upvote reward model. |
Evaluation scripts are in scripts/eval/toxicity/ .
| 스크립트 | 설명 |
|---|---|
eval_policy.py | Evaluate an agent in the Reddit comments environment. |
distill_policy_eval.py | Prints out the result of eval_policy.py with error bars. |
All tasks – Wordle, Visual Dialogue, Reddit – have a corresponding environment and dataset implemented in the codebase, as described above. And all offline RL algorithms in the codebase are trained, executed, and evaluated on one of these given environments and datasets.
You can similarly define your own tasks that can easily be run on all these offline RL algorithms. This codebase implements a simple set of RL environment abstractions that make it possible to define your own environments and datasets that can plug-and-play with any of the offline RL algorithms.
All of the core abstractions are defined in src/data/ . Here we outline what needs to be implemented in order to create your own tasks. For examples, see the implementations in src/wordle/ , src/vis_dial/ , and src/toxicity/ .
All tasks must implement subclasses of: Language_Observation and Language_Environment , which are in src/data/language_environment.py .
Language_Observation :This class represents the observations from the environment that will be input to your language model.
A Language_Observation must define the following two functions.
to_sequence def to_sequence ( self ) -> Tuple [ List [ str , Optional [ float ]], bool ]:설명:
A function which converts the observation object into a standard format that can be input to the language model and used for training.
보고:
__str__ def __str__ ( self ) -> str :설명:
This is only used to print the observation to the terminal. It should convert the observation into some kind of string that is interpretable by a user.
Returns: a string.
Language_Environment :This class represents a gym-style environment for online interaction, which is only used for evaluation.
A Language_Environment must define the following three functions.
step def step ( self , action : str ) -> Tuple [ Language_Observation , float , bool ]:설명:
Just like a standard gym environment, given an action in the form of a string, step the environment forward.
Returns: a tuple of (Language_Observation, reward, terminal).
reset def reset ( self ) -> Language_Observation :설명:
This resets the environment to an initial state.
Returns: the corresponding initial Language_Observation
is_terminal def is_terminal ( self ) -> bool :설명:
Outputs whether the environment has reached a terminal state.
Returns: a boolean indicating if the environment has reached a terminal state.
All tasks must implement subclasses of either List_RL_Dataset or Iterable_RL_Dataset or both, which are defined in src/data/rl_data.py .
List_RL_Dataset :This class represents a list dataset (or an indexable dataset of finite length) that can be used to train offline RL agents.
A List_RL_Dataset must define the following two functions.
get_item def get_item ( self , idx : int ) -> DataPoint설명:
This gets an item from the dataset at a given index.
Returns: a DataPoint object from the dataset.
size def size ( self ) -> int설명:
Returns the size of the dataset.
Returns: the dataset's size.
Iterable_RL_Dataset :This class represents an iterable dataset (or a non-indexable dataset that stochastically samples datapoints iid) that can be used to train offline RL agents.
A Iterable_RL_Dataset must define the following function.
sample_item def sample_item ( self ) -> DataPoint설명:
Samples a datapoint from the dataset.
Returns: a DataPoint object from the dataset.


