項目:零
- 位於卡爾迪的韓國ASR開源項目
- 立即外食譜(https://github.com/kaldi-asr/kaldi/tree/master/master/egs/zeroth_korean/s5)
- 許可證:Apache 2.0
- 論壇:https://groups.google.com/forum/#! forum/zeroth-help
Zeroth是使用Kaldi工具包實施的韓國語音識別的開源項目。
該項目是作為Atlas Labs(https://www.atlaslabs.ai)語言AI平台的一部分開發的,該平台使企業能夠在其B2C通信中添加智能。
通過介紹官方的韓國卡爾迪食譜,零項目旨在使韓國言語認可更廣泛地訪問所有人。
正如Zeroth的名稱(或0th)所暗示的那樣,該項目的目的是成為起點和基礎作品,任何人都可以使用語音識別來構建新產品和服務。
我們希望您發現這個項目有用,並歡迎任何討論或共同努力的機會。
聯繫人:Lucas Jo([email protected])
特別感謝
- Zeroth是在[GridSpace Inc.](https://www.gridspace.com)上與Wonkyum Lee([email protected])合作開發的。
提到的鏈接
- [openslr](http://www.openslr.org/40/)
- [數據科學研討會](http://www.fastcampus.co.kr/data_camp_lab/) @ fastcampus
- 研討會 @ kmobile
- [訪談](http://blog.naver.com/fastcampus/221181060609)與FastCampus
- [深度學習 - 語音識別營](http://www.fastcampus.co.kr/data_camp_dsr/) @ fastcampus
0。概述
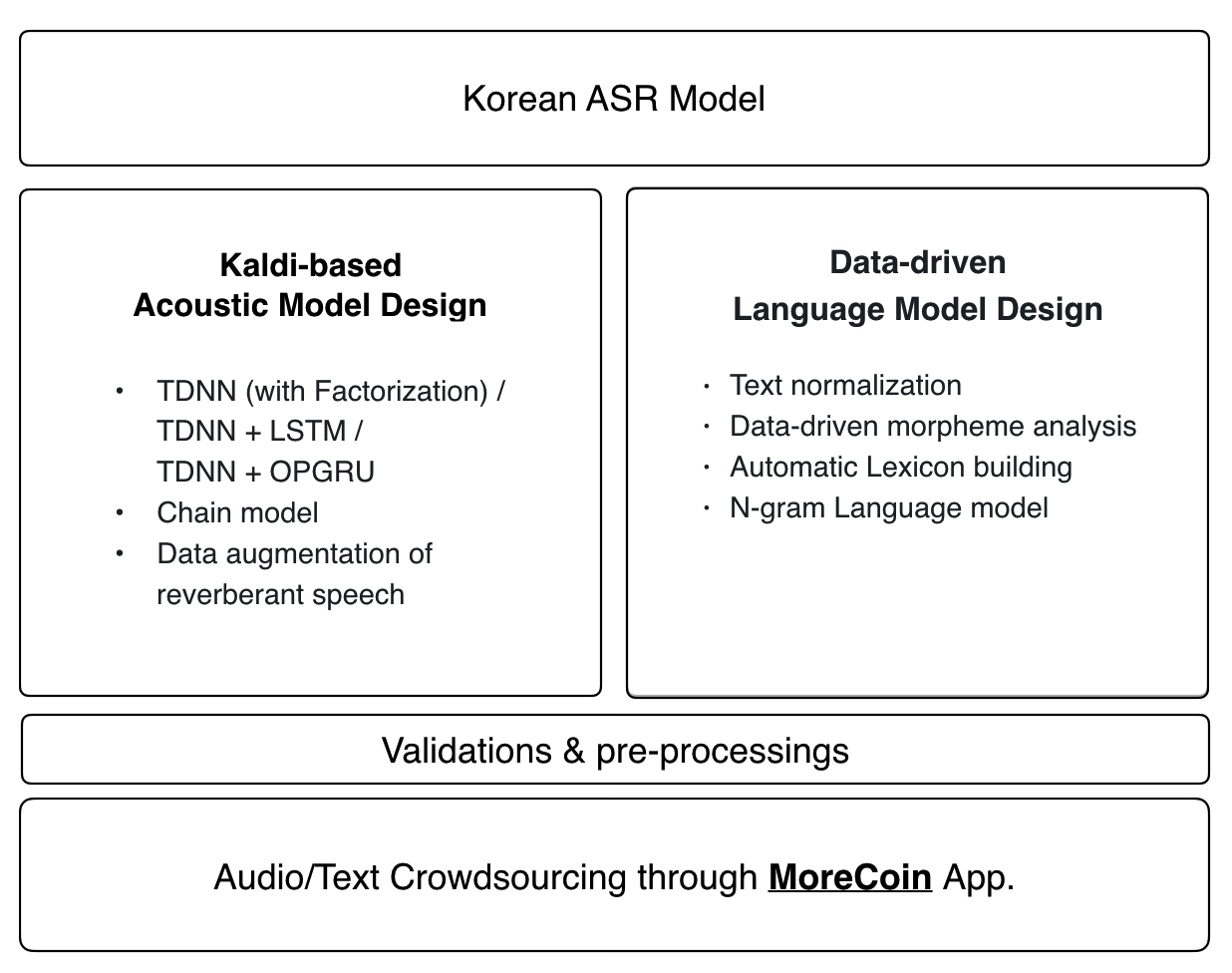
1。音頻數據
- 2018年7月16日:95.7小時(46,347個話語,181位發言人,27,330 Uniq。句子)
- 2018年4月9日:76.6小時(35,139個話語,137個發言人,16,472個Uniq。句子)
- 2018年2月3日:51.6小時抄錄的韓國音頻用於培訓數據(22,263次言論,105位發言人,3000個句子)
- 許可證:[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)
- 現在可以在OpenSLR上獲得51.6小時的音頻和LM數據
- Morecoin的音頻眾包正在增長。 70小時的開源音頻數據庫將在2018年4月左右開放。您可以通過語音錄音應用捐贈您
- [Morecoin(Android)](https://play.google.com/store/apps/details?id=com.goodatlas.morecoin)。
- [Morecoin(IOX)](https://apps.apple.com/ph/app/morecoin/id1351621392?ign-mpt=UO%3D2)
我們提供了一個語音錄製應用程序[Morecoin(Android)](https://play.google.com/store/store/papps/details?id=com.goodatlas.morecoin),您可以參與構建我們的開放量數據的韓國培訓數據庫。
2。要求
- [要求]運行零項目所需的包裝說明:https://github.com/goodatlas/zeroth/wiki/requirements)
- [需求2]其他軟件包執行語言模型和語音詞典的代碼:( https://github.com/goodatlas/zeroth/wiki/requirement-2)
聲學模型
最新的Kaldi食譜應用於Zeroth的聲學模型:
- TDNN(分解) / TDNN + LSTM / TDNN + OPGRU
- 鏈模型
- 迴響語音的數據增強
語言模型和詞典
零語言模型和語音詞典使用端到端數據驅動的方法。對我們的開源音頻數據庫的任何貢獻都將自動納入最新的語言模型和語音詞典中。
創建自定義語言模型和語音詞典:[S5/data/local/lm/readme.md](https://github.com/goodatlas/zeroth/zeroth/blob/master/master/s5/data/data/local/local/lm/readme.md)。
語料庫(語料庫)
- 訓練句子:109,037,699
- 測試句子:12,115,208
- 總計:121,152,907
語音詞典
- 唯一單詞:30,064,143
- 頻率最高的獨特單詞:8,069,252
- 獨特的詞素:465,253
- 語音詞典的大小考慮發音多樣性:686,839
語言模型
- 困惑測試3-gram:ppl = 221.2969(12,115,208句,194,940,635個單詞,0 OOV)
- 困惑測試4-gram:ppl = 187.2058(12,115,208句,194,940,635個單詞,0 OOV)
項目:零
- 칼디를칼디를구축하는한국어음성인식
- 이제(https://github.com/kaldi-asr/kaldi/tree/master/master/egs/zeroth_korean/s5)
- 許可證:Apache 2.0
- 포럼:https://groups.google.com/forum/#! forum/zeroth-help
Zeroth프로젝트는kaldi開源工具kit을을음성인식기를입니다프로젝트입니다。 이기업이ai를를서비스에추가하는데데(주)아틀라스가이드의語言ai플랫폼플랫폼일부로서일부로서。 kaldi官方食譜에한국어소개하는것을,많은사람들의통해사용할수있는만들어나갈수있도록하는프로젝트입니다것을목표로하는목표로하는목표로하는목표로하는목표로하는。 제로스라는제로스라는제로스라는0-th,즉0번째를번째를。 이름이의미하는이음성인식기를음성인식기를위해필요한처음부터끝까지함께해보고수수있기를있기를。
聯繫人:Lucas Jo([email protected])
特別感謝
- GridSpace Inc.사에서사에서일하고wonkyum lee님과의共同工作。
提到的鏈接
- Openslr
- 데이터데이터 @ @ fastcampus
- 워크샵 @ kmobile
- FastCampus的訪談
- 딥러닝-음성인식營地 @ fastcampus
0。概述
1。音頻數據
- 2018.07.16:95.7시간(46,347발화,181명,27,330문장)
- 2018.04.09:76.6시간(35,139발화,137명,16,472문장)
- 2018.02.03:51.6시간한국어(22,263발화,105명,3000문장)
- 許可證:CC由4.0
- 현재openslr에서51.6시간lm데이터를데이터를수수수。
- 모어코인을모어코인을오픈소스오디오가커지고。 4월에는1시간70시간시간받아보실수있습니다。 모어코인앱을모어코인앱을기부해주세요。
현재제로스상기와같은포함되어있습니다。 db db구축에구축에참여할(android)을을을(ios)제공하고제공하고제공하고제공하고제공하고제공하고제공하고제공하고제공하고제공하고제공하고녹음앱(ios)제공하고,해당해당제공하고,해당해당제공하고제공하고앱앱앱녹음녹음녹음녹음녹음녹음녹음앱앱앱앱앱녹음녹음녹음녹음녹음앱앱앱앱녹음앱녹음 sudmential은발급된은시간시간동안유효합니다유효합니다。 더자세한자세한aws-temporary-Credential페이지를페이지를바랍니다
2。要求
- 要求要求위키위키위키참조하시기페이지를참조하시기참조하시기참조하시기바랍니다。
- 언어모델과언어모델과구현하는코드를직접실행하기실행하기실행하기실행하기직접위키위키위키패키지를설치하시기설치하시기。
3。聲學模型
Kaldi食譜가가가가가적용되어적용되어있습니다적용되어있습니다
- TDNN(分解) / TDNN + LSTM / TDNN + OPGRU
- 鏈模型
- 迴響語音的數據增強
4。語言模型和詞典
數據驅動的방식으로방식으로방식으로방식으로만들어집니다。 아래는aws-temporary-Credential을을경우함께자동으로언어모델과발음사전의발음사전의발음사전의。 개인적으로개인적으로특화된발음사전을만들고자하는경우에는세부적인
s5/data/local/lm/readme.md에기술되어참조하시기。
말뭉치(語料庫)
- 훈련된문장의:109,037,699
- 테스트:12,115,208
- 전:121,152,907
발음사전(詞典)
- 고유한고유한:30,064,143
- 98%빈도빈도보이는고유한단어의단어의:8,069,252
- 數據驅動방식으로방식으로고유한:465,253
- 발음다양성을고려한:686,839
언어모델(語言模型)
- 困惑測試3-gram:ppl = 221.2969(12,115,208句,194,940,635個單詞,0 OOV)
- 困惑測試4-gram:ppl = 187.2058(12,115,208句,194,940,635個單詞,0 OOV)


