Proyecto: Zeroth
- Proyecto coreano ASR de código abierto con sede en Kaldi
- Receta offcial ahora (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Licencia: Apache 2.0
- Foro: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth es un proyecto de código abierto para el reconocimiento de voz coreano implementado utilizando el Kaldi Toolkit.
Este proyecto fue desarrollado como parte de la plataforma AI Language AI de Atlas Labs (https://www.atlaslabs.ai), que permite a las empresas agregar inteligencia a sus comunicaciones B2C.
Al presentar una receta oficial de Kaldi coreano, el proyecto Zeroth tiene como objetivo hacer que el reconocimiento de voz coreano sea más ampliamente accesible para todos.
Como sugiere el nombre de Zeroth, o el 0, el objetivo de este proyecto de ser el punto de partida y una pieza fundamental sobre la cual cualquiera puede construir nuevos productos y servicios utilizando el reconocimiento de voz.
Esperamos que encuentre este proyecto útil y agradezca cualquier oportunidad para discutir o trabajar juntos.
Contacto: Lucas Jo ([email protected])
Agradecimiento especial
- Zeroth fue desarrollado en colaboración con Wonkyum Lee ([email protected]) en [Gridspace Inc.] (https://www.gridspace.com).
Enlaces mencionados
- [OpenSlr] (http://www.openslr.org/40/)
- [Seminario de ciencia de datos] (http://www.fastcampus.co.kr/data_camp_lab/) @ fastcampus
- Taller @ kmobile
- [Entrevista] (http://blog.naver.com/fastcampus/221181060609) con FastCampus
- [Aprendizaje profundo - Campamento de reconocimiento de voz] (http://www.fastcampus.co.kr/data_camp_dsr/) @ fastcampus
0. Descripción general
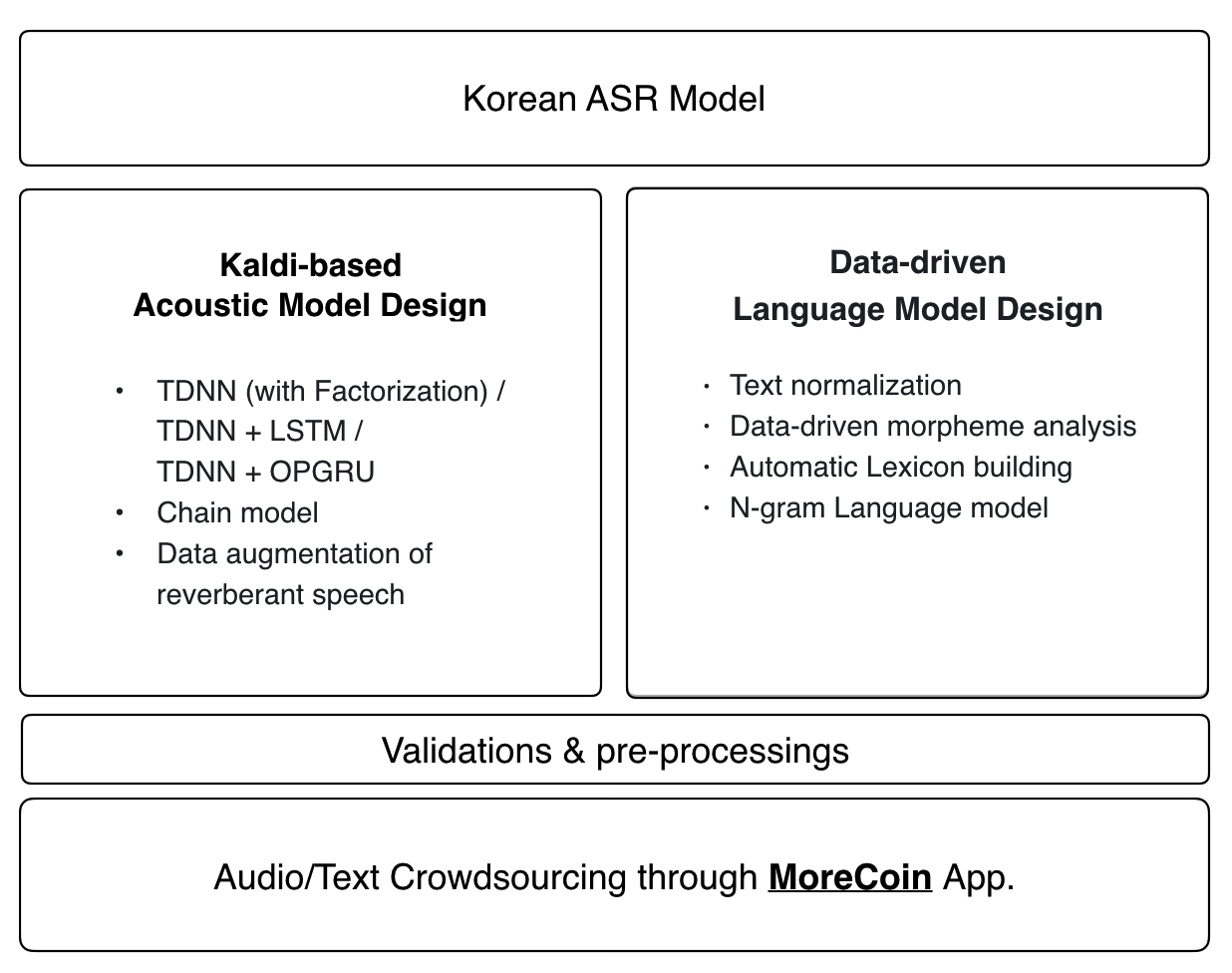
1. Datos de audio
- 16 de julio de 2018: 95.7 horas (46,347 enunciados, 181 oradores, 27,330 oraciones uniq.)
- 9 de abril de 2018: 76.6 horas (35,139 enunciados, 137 oradores, 16,472 oraciones uniq.)
- 3 de febrero de 2018: 51.6 Horas de audio coreano transcrito para datos de capacitación (22,263 enunciados, 105 altavoces, 3000 oraciones)
- Licencia: [CC por 4.0] (https://createivecommons.org/licenses/by/4.0/)
- Ahora los datos de audio y LM de 51.6 horas están disponibles en OpenSLR
- El crowdsource de audio de Morecoin está creciendo. Se abrirán 70 horas de base de datos de audio de código abierto alrededor de abril de 2018. Puede donar la suya a través de la aplicación de grabación de voz
- [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin).
- [Morecoin (IOX)] (https://apps.apple.com/ph/app/morecoin/id1351621392?ign-mpt=uo%3D2)
Ofrecemos una aplicación de grabación de voz [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin) que puede usar para participar en la creación de nuestra base de datos de código abierto de datos de capacitación coreana.
2. Requisitos
- [Requisitos] Descripción de los paquetes necesarios para ejecutar el proyecto Zeroth: https://github.com/goodatlas/zeroth/wiki/requirements)
- [Requisitos-2] Paquetes adicionales para ejecutar código para el modelo de idioma y el diccionario fonético: (https://github.com/goodatlas/zeroth/wiki/requirement-2)
Modelo acústico
La última receta de Kaldi se aplica al modelo acústico del Zeroth:
- TDNN (con factorización) / TDNN + LSTM / TDNN + OPGRU
- Modelo de cadena
- Aumento de datos del discurso reverberante
Modelo de idioma y léxico
El modelo lingüístico de Zeroth y el diccionario fonético utilizan un enfoque de extremo a extremo basado en datos. Cualquier contribución a nuestra base de datos de audio de código abierto se incorporará automáticamente al último modelo de idioma y al diccionario fonético.
Para crear un modelo de lenguaje personalizado y un diccionario fonético: [s5/data/local/lm/readme.md] (https://github.com/goodatlas/zeroth/blob/master/s5/data/local/lm/readme.md).
Corpus (corpus)
- Frases de capacitación: 109,037,699
- Oraciones de prueba: 12,115,208
- Total: 121,152,907
Diccionario fonético
- Palabras únicas: 30,064,143
- Palabras únicas con la frecuencia más alta del 98%: 8,069,252
- Morfemas únicos: 465,253
- Tamaño del diccionario fonético considerando la diversidad de pronunciación: 686,839
Modelo
- Prueba de perplejidad de 3 gramos: PPL = 221.2969 (12,115,208 oraciones, 194,940,635 palabras, 0 OOV)
- Prueba de perplejidad 4 gramos: PPL = 187.2058 (12,115,208 oraciones, 194,940,635 palabras, 0 OOV)
Proyecto: Zeroth
- 칼디를 이용하여 구축하는 한국어 음성인식 오픈소스
- 이제 칼디 공식 한국어 예제입니다 예제입니다 (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Licencia: Apache 2.0
- 포럼: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth 프로젝트는 Kaldi Open Source Tool-kit 을 사용해서 한국어 음성인식기를 구현하는 프로젝트 입니다. 이 프로젝트는 기업이 ai 를 고객 서비스에 추가하는 데 도움이되는 (주) 아틀라스가이드의 lenguaje ai 플랫폼 개발의 일부로서 개발되었습니다. Receta oficial de Kaldi 에 한국어 버전을 소개하는 것을 시작으로, 많은 사람들의 참여를 통해 누구나 사용할 수 있는 음성인식기를 만들어 나갈 수 있도록 하는 하는 것을 프로젝트입니다. 제로스라는 이름은 0-th, 즉 0 번째를 의미합니다. 이름이 의미하는 것처럼 이 프로젝트를 통해 음성인식기를 만들기 위해 필요한 모든 과정을 처음부터 끝까지 함께 해보고 토론할 수 있기를 바랍니다.
Contacto: Lucas Jo ([email protected])
Agradecimiento especial
- Gridspace Inc. 사에서 일하고 계신 Wonkyum Lee 님과의 Co-work 를 통해 이 프로젝트를 진행하고 있음을 밝힙니다.
Enlaces mencionados
- Openslr
- 데이터 사이언스 논문 세미나 @ FastCampus
- 워크샵 @ kmobile
- Entrevista con FastCampus
- 딥러닝-음성인식 음성인식 Camp @ FastCampus
0. Descripción general
1. Datos de audio
- 2018.07.16: 95.7 시간 (46,347 발화, 181 명, 27,330 문장)
- 2018.04.09: 76.6 시간 (35,139 발화, 137 명, 16,472 문장)
- 2018.02.03: 51.6 시간 한국어 학습데이터 (22,263 발화, 105 명, 3000 문장)
- Licencia: CC por 4.0
- 현재 OpenSlr 에서 51.6 시간 오디와 lm 데이터를 받아보실 수 있습니다.
- 모어코인을 통한 기부로 오픈소스 오디오가 커지고 있습니다. 4 월에는 1 시간 기부시 70 시간 데이터를 받아보실 수 있습니다. 모어코인앱을 통해 음성을 기부해 주세요.
현재 제로스 프로젝트에는 상기와 같은 음성데이터가 포함되어 있습니다. 공개 음성 db 구축에 참여할 수 있는 음성 녹음 앱 모아코인 (android) 을 과 모아코인 (iOS) 제공하고 있으며 있으며 해당 앱을 통해 음성 데이터를 1 시간 기부해주시면 해당 시점까지 구축된 음성 음성 음성 db 에 접근하여 다운로드할 다운로드할 있는 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 권한을 형태로 발급해 발급해. 한번 발급된 Credencial 은 12 시간 동안 유효합니다. 더 자세한 내용은 AWS-Temporáneo-Credencial 페이지를 확인하시기 바랍니다
2. Requisitos
- 제로스 프로젝트를 실행하는데 필요한 패키지들에 대한 대한 설명은 requisitos 위키 페이지를 참조하시기 바랍니다.
- 언어모델과 발음사전을 구현하는 코드를 직접 실행하기 실행하기 위해서는 requisitos-2 위키 페이지를 참조하여 추가적인 패키지를 설치하시기 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 eléctrica.
3. Modelo acústico
현재 제로스 프로젝트 음향모델에는 아래와 같은 최신 최신 receta kaldi 가 적용되어 있습니다.
- TDNN (con factorización) / TDNN + LSTM / TDNN + OPGRU
- Modelo de cadena
- Aumento de datos del discurso reverberante
4. Modelo de idioma y léxico
제로스 프로젝트에 사용되는 언어모델과 발음사전은 처음부터 끝까지 끝까지 끝까지 방식으로 방식으로 만들어집니다 만들어집니다 만들어집니다 만들어집니다 만들어집니다 만들어집니다. 아래는 AWS-Temporáneo-Credencial 을 발급받은 경우 오디오 데이터와 함께 자동으로 받아지는 언어모델과 발음사전의 세부사항입니다 세부사항입니다. 개인적으로 직접 특화된 언어모델과 발음사전을 만들고자 하는 경우에는 세부적인 방법이
S5/data/local/lm/readme.md 에 기술되어 있으니 참조하시기 바랍니다.
말뭉치 (corpus)
- 훈련된 문장의 수: 109,037,699
- 테스트 문장의 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 uct.
- 전 체: 121,152,907
발음사전 (léxico)
- 고유한 단어의 수: 30,064,143
- 상위 98% 빈도 수를 보이는 고유한 단어의 수 수: 8,069,252
- Data-Drive 방식으로 찾은 고유한 형태소의 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 수 형태소의 수 형태소의
- 발음 다양성을 고려한 발음사전의 크기: 686,839
언어모델 (modelo de idioma)
- Prueba de perplejidad de 3 gramos: PPL = 221.2969 (12,115,208 oraciones, 194,940,635 palabras, 0 OOV)
- Prueba de perplejidad 4 gramos: PPL = 187.2058 (12,115,208 oraciones, 194,940,635 palabras, 0 OOV)


