Проект: нуль
- Корейский проект с открытым исходным кодом, базирующаяся в Калди
- Рецепт сейчас (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Лицензия: Apache 2.0
- Форум: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth является проектом с открытым исходным кодом для корейского распознавания речи, реализованного с использованием инструментария Kaldi.
Этот проект был разработан в рамках языковой платформы AI AI (https://www.atlaslabs.ai), которая позволяет предприятиям добавлять интеллектуальные связи в свои коммуникации B2C.
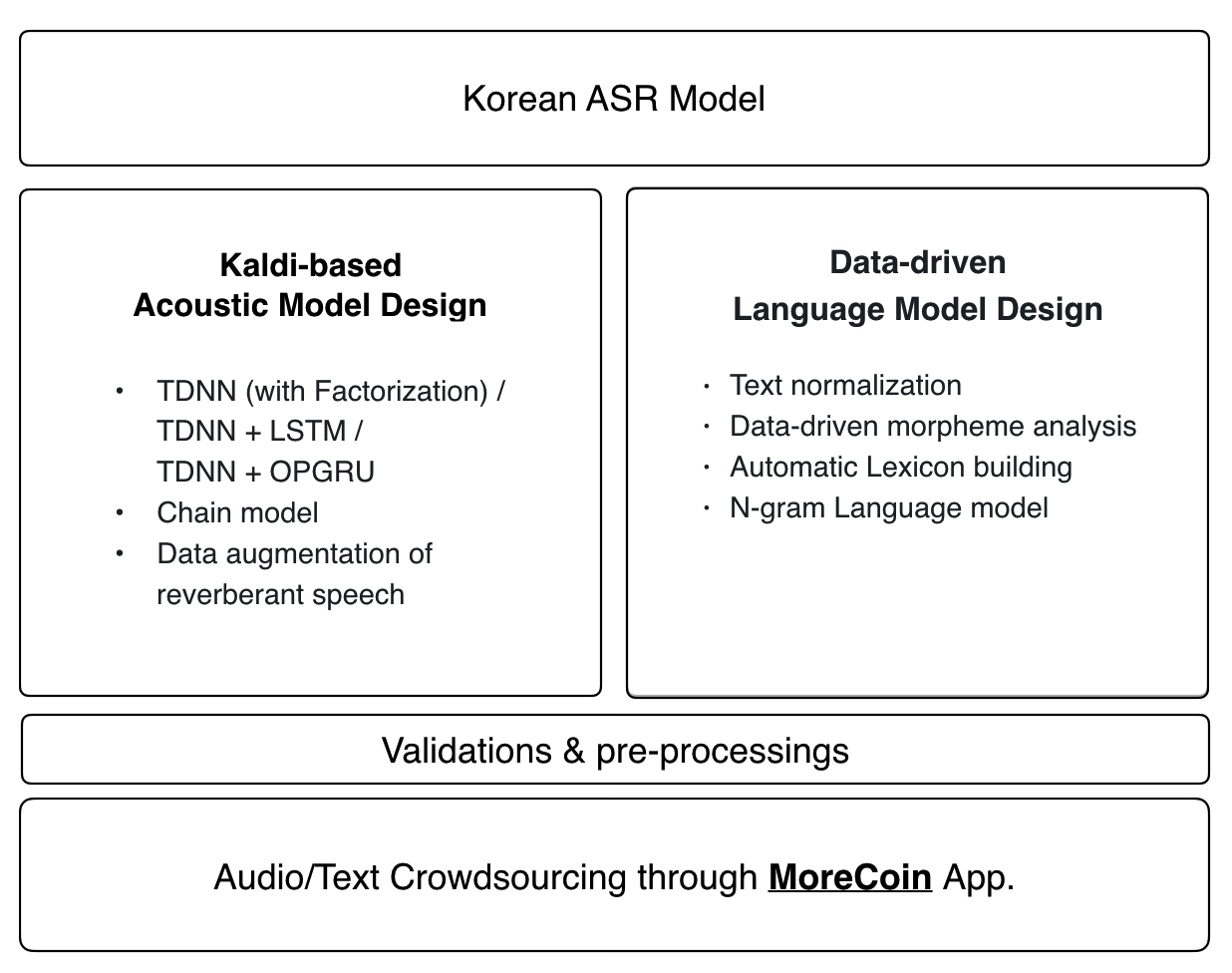
Представляя официальный корейский рецепт Калди, проект нулевого значения направлен на то, чтобы сделать корейское признание речи более доступным для всех.
Как предполагает название Zeroth, или 0th, цель этого проекта станет отправной точкой и основой, на которой каждый может создавать новые продукты и услуги, используя распознавание речи.
Мы надеемся, что вы найдете этот проект полезным и приветствуем любые возможности для обсуждения или совместной работы.
Контакт: Лукас Джо ([email protected])
Особая благодарность
- Zeroth был разработан в сотрудничестве с Wunkyum Lee ([email protected]) на [Gridspace Inc.] (https://www.gridspace.com).
Упомянутые ссылки
- [OpenSlr] (http://www.openslr.org/40/)
- [Семинар по науке о данных] (http://www.fastcampus.co.kr/data_camp_lab/) @ fastcampus
- Мастерская @ kmobile
- [Интервью] (http://blog.naver.com/fastcampus/221181060609) с FastCampus
- [Глубокое обучение - лагерь распознавания речи] (http://www.fastcampus.co.kr/data_camp_dsr/) @ fastcampus
0. Обзор
1. Аудиоданные
- 16 июля 2018 года: 95,7 часа (46 347 высказываний, 181 докладчики, 27 330 Uniq. Приговоры)
- 9 апреля 2018: 76,6 часа (35 139 высказываний, 137 докладчиков, 16 472 Uniq. Предложения)
- 3 февраля 2018 года: 51,6 часа транскрибированного корейского аудио для данных обучения (22 263 высказывания, 105 докладчиков, 3000 предложений)
- Лицензия: [cc by 4.0] (https://creativecommons.org/licenses/by/4.0/)
- Теперь 51,6 -часовые данные аудио и LM доступны в OpenSlr
- Аудио краудсорсин от Morecoin растет. 70 часов аудиобазы с открытым исходным кодом будут открыты около апреля 2018 года. Вы можете пожертвовать свое, хотя приложение для записи голоса
- [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin).
- [Morecoin (iox)] (https://apps.apple.com/ph/app/morecoin/id1351621392?ign-mpt=uo%3D2)
Мы предлагаем приложение для записи голоса [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin), которое вы можете использовать для участия в создании нашей базы данных с открытым исходным координатом корейских учебных данных.
2. Требования
- [Требования] Описание пакетов, необходимых для запуска проекта Zeroth: https://github.com/goodatlas/zeroth/wiki/requirements)
- [Требования-2] Дополнительные пакеты для выполнения кода для языковой модели и фонетического словаря: (https://github.com/goodatlas/zeroth/wiki/requirement-2)
Акустическая модель
Последний рецепт Калди применяется к акустической модели нуля:
- Tdnn (с факторизацией) / tdnn + lstm / tdnn + opgru
- Цепная модель
- Увеличение данных реверберальной речи
Языковая модель и лексика
Языковая модель Zeroth и фонетический словарь используют сквозное подход, управляемый данными. Любые вклады в нашу базу данных с открытым исходным кодом будут автоматически включены в новейшую языковую модель и фонетический словарь.
Чтобы создать пользовательскую языковую модель и фонетический словарь: [s5/data/local/lm/readme.md] (https://github.com/goodatlas/zeroth/blob/master/s5/data/local/lm/readme.md).
Корпус (корпус)
- Учебные предложения: 109 037 699
- Тестовые предложения: 12,115208
- Всего: 121,152,907
Фонетический словарь
- Уникальные слова: 30,064,143
- Уникальные слова с самой высокой частотой 98%: 8 069 252
- Уникальные морфемы: 465,253
- Размер фонетического словаря с учетом разнообразия произношения: 686,839
Языковая модель
- Тест на недоумение 3-грамм: PPL = 221,2969 (12,115208 предложений, 194 940 635 слов, 0 OOVS)
- Тест на недоумение 4-граммового: PPL = 187,2058 (12,115208 предложений, 194 940 635 слов, 0 OOVS)
Проект: нуль
- 칼디를 이용하여 한국어 음성인식 오픈소스 오픈소스
- 이제 칼디 공식 예제입니다 예제입니다 (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Лицензия: Apache 2.0
- 포럼: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth 프로젝트는 Kaldi Open Source Tool-Kit 을 한국어 한국어 음성인식기를 구현하는 프로젝트 입니다. 이 프로젝트는 기업이 ai 를 고객 추가하는 데 데 도움이되는 (주) 아틀라스가이드의 Язык ai 플랫폼 일부로서 개발되었습니다 개발되었습니다. Официальный рецепт калди 에 버전을 소개하는 것을 시작으로 시작으로, 많은 사람들의 참여를 통해 사용할 수 있는 음성인식기를 만들어 나갈 수 있도록 것을 목표로하는 목표로하는 프로젝트입니다. 제로스라는 이름은 0-th, 즉 0 번째를 의미합니다. 이름이 의미하는 이 프로젝트를 통해 음성인식기를 만들기 위해 필요한 모든 과정을 처음부터 끝까지 해보고 토론할 수 있기를 바랍니다.
Контакт: Лукас Джо ([email protected])
Особая благодарность
- Gridspace Inc. 사에서 계신 계신 Wonkyum Lee 님과의 Copork 를 통해 이 진행하고 있음을 밝힙니다 밝힙니다.
Упомянутые ссылки
- OpenSlr
- 데이터 사이언스 논문 세미나 @ fastcampus
- 워크샵 @ kmobile
- Интервью с FastCampus
- 딥러닝-음성인식 Camp @ fastcampus
0. Обзор
1. Аудиоданные
- 2018.07.16: 95,7 시간 (46 347 발화, 181 명, 27 330 문장)
- 2018.04.09: 76,6 시간 (35,139 발화, 137 명, 16 472 문장)
- 2018.02.03: 51,6 시간 한국어 학습데이터 (22,263 발화, 105 명, 3000 문장)
- Лицензия: CC по 4.0
- 현재 OpenSlr 에서 51.6 시간 오디와 lm 데이터를 받아보실 수 있습니다.
- 모어코인을 통한 기부로 오디오가 커지고 있습니다. 4 월에는 1 시간 기부시 70 시간 데이터를 받아보실 수 있습니다. 모어코인앱을 통해 음성을 기부해 주세요.
현재 제로스 프로젝트에는 같은 음성데이터가 포함되어 있습니다. 공개 음성 db 구축에 수 있는 음성 녹음 앱 모아코인 (Android) 을 모아코인 모아코인 (ios) 제공하고 있으며 해당 앱을 통해 음성 데이터를 1 시간 기부해주시면 해당 시점까지 공개 음성 db 에 다운로드할 수 있는 권한을 권한을 권한을 해당 구축된 공개 음성 db 한번 발급된 Учетные данные 은 12 시간 동안 유효합니다. 더 자세한 내용은 aws-treemporary-credentials 페이지를 확인하시기 바랍니다 바랍니다 바랍니다 바랍니다
2. Требования
- 제로스 프로젝트를 실행하는데 필요한 대한 설명은 설명은 Требования 위키 페이지를 참조하시기 바랍니다.
- 언어모델과 발음사전을 구현하는 코드를 실행하기 위해서는 위해서는 Требования-2 위키 참조하여 참조하여 추가적인 패키지를 설치하시기 바랍니다.
3. Акустическая модель
현재 제로스 프로젝트 음향모델에는 아래와 같은 최신 최신 최신 최신 최신 가 적용되어 있습니다 있습니다.
- Tdnn (с факторизацией) / tdnn + lstm / tdnn + opgru
- Цепная модель
- Увеличение данных реверберальной речи
4. Языковая модель и лексика
제로스 프로젝트에 사용되는 언어모델과 처음부터 끝까지 끝까지, управляемое данными 방식으로 만들어집니다. 아래는 AWS-TERPERARY-CREDENTIAL 을 발급받은 경우 데이터와 데이터와 함께 자동으로 받아지는 언어모델과 발음사전의 세부사항입니다. 개인적으로 직접 언어모델과 발음사전을 만들고자 하는 경우에는 세부적인 방법이 방법이
s5/data/local/lm/readme.md 에 기술되어 있으니 참조하시기 바랍니다.
말뭉치 (Корпус)
- 훈련된 문장의 수: 109 037,699
- 테스트 문장의 수: 12,115208
- 전 체: 121,152,907
발음사전 (лексикон)
- 고유한 단어의 수: 30,064,143
- 상위 98% 빈도 보이는 고유한 단어의 수: 8,069 252
- Data-Drive 방식으로 찾은 고유한 수 수: 465,253
- 발음 다양성을 고려한 크기 크기: 686,839
언어모델 (Языковая модель)
- Тест на недоумение 3-грамм: PPL = 221,2969 (12,115208 предложений, 194 940 635 слов, 0 OOVS)
- Тест на недоумение 4-граммового: PPL = 187,2058 (12,115208 предложений, 194 940 635 слов, 0 OOVS)


