Projet: Zeroth
- Projet open-source coréen ASR basé à Kaldi
- Recette Offcial Now (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Licence: Apache 2.0
- Forum: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth est un projet open source pour la reconnaissance vocale coréenne implémentée à l'aide de la boîte à outils Kaldi.
Ce projet a été développé dans le cadre de la plate-forme AI linguistique (https://www.atlaslabs.ai) d'Atlas Labs, qui permet aux entreprises d'ajouter de l'intelligence à leurs communications B2C.
En introduisant une recette officielle de Kaldi coréenne, le projet Zeroth vise à rendre la reconnaissance vocale coréenne plus largement accessible à tous.
Comme le nom Zeroth, ou le 0ème, le suggère, ce projet est le point de départ et un article fondamental sur lequel n'importe qui peut construire de nouveaux produits et services en utilisant la reconnaissance vocale.
Nous espérons que vous trouverez ce projet utile et accueillez toutes les opportunités de discuter ou de travailler ensemble.
Contact: Lucas Jo ([email protected])
Merci spécial
- Zeroth a été développé en collaboration avec Wancyum Lee ([email protected]) à [GridSpace Inc.] (https://www.gridspace.com).
Liens mentionnés
- [Openslr] (http://www.openslr.org/40/)
- [Séminaire sur la science des données] (http://www.fastcampus.co.kr/data_camp_lab/) @ fastcampus
- Atelier @ kmobile
- [Entretien] (http://blog.naver.com/fastcampus/211181060609) avec FastCampus
- [Deep Learning - Camp de reconnaissance vocale] (http://www.fastcampus.co.kr/data_camp_dsr/) @ FastCampus
0. Présentation
1. Données audio
- 16 juillet 2018: 95,7 heures (46 347 énoncés, 181 conférenciers, 27 330 Uniq. Phrases)
- 9 avril 2018: 76,6 heures (35 139 énoncés, 137 conférenciers, 16 472 phrases Uniq.)
- 3 février 2018: 51,6 heures transcrites audio coréen pour les données de formation (22 263 énoncés, 105 conférenciers, 3000 phrases)
- Licence: [CC par 4.0] (https://creativecommons.org/licenses/by/4.0/)
- Maintenant, les données audio et LM de 51,6 heures sont disponibles sur OpenSLR
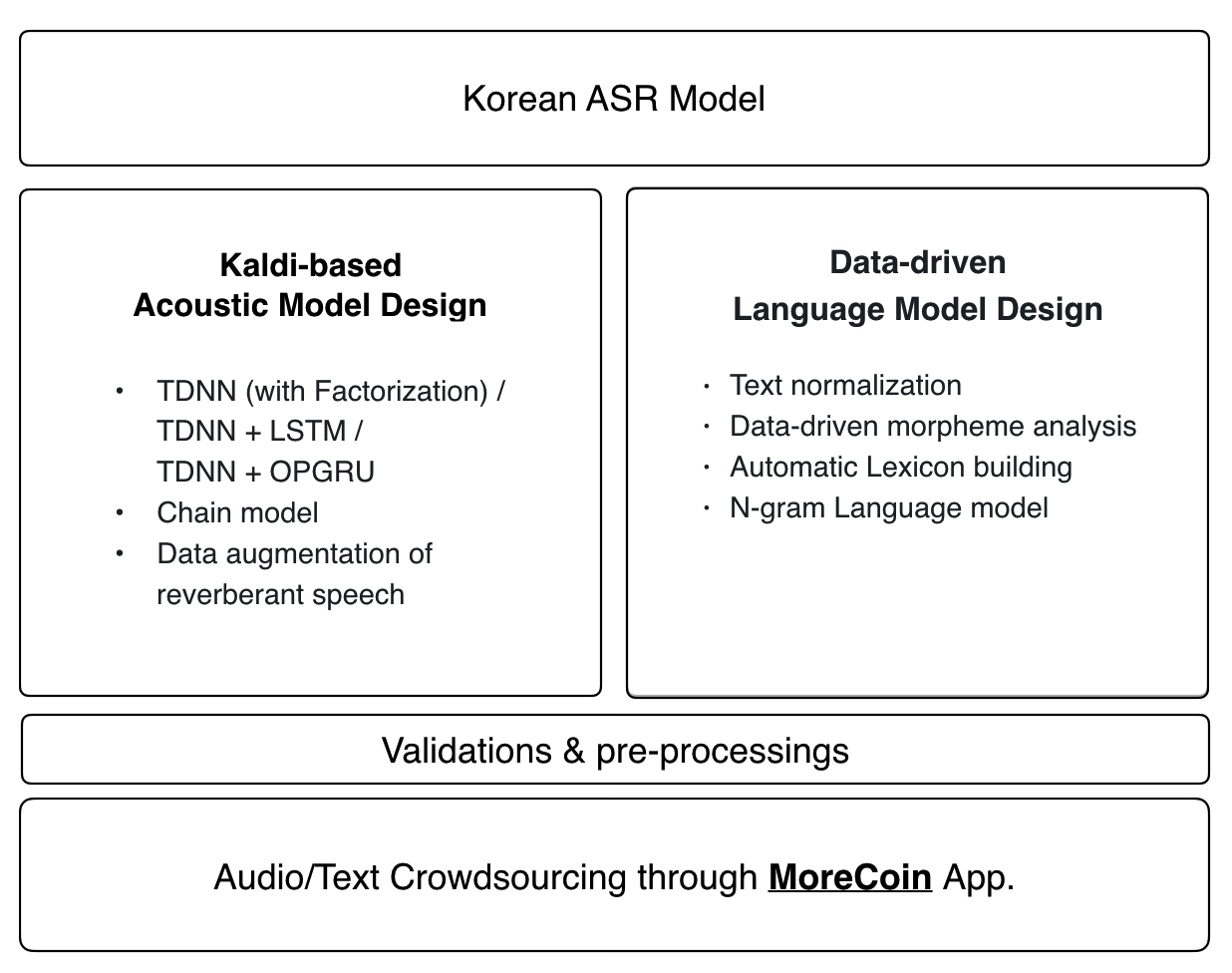
- Le crowdsource audio de Morecoin augmente. 70 heures de base de données audio open source seront ouvertes vers avril 2018.
- [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin).
- [Morecoin (iox)] (https://apps.apple.com/ph/app/morecoin/id1351621392?ign-mpt=uo%3d2)
Nous proposons une application d'enregistrement vocal [MoreCoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin) que vous pouvez utiliser pour participer à la construction de notre base de données open source de données de formation coréen.
2. Exigences
- [Exigences] Description des packages nécessaires pour exécuter le projet Zeroth: https://github.com/goodatlas/zeroth/wiki/Requirements)
- [Exigences-2] Packages supplémentaires pour exécuter du code pour le modèle de langue et le dictionnaire phonétique: (https://github.com/goodatlas/zeroth/wiki/Requiment-2)
Modèle acoustique
La dernière recette de Kaldi est appliquée au modèle acoustique du Zeroth:
- TDNN (avec factorisation) / TDNN + LSTM / TDNN + OPGRU
- Modèle de chaîne
- Augmentation des données du discours réverbérant
Modèle de langue et lexique
Le modèle linguistique de Zeroth et le dictionnaire phonétique utilisent une approche basée sur les données de bout en bout. Toute contribution à notre base de données audio open source sera automatiquement intégrée dans le dernier modèle de langue et le dictionnaire phonétique.
Pour créer un modèle de langage personnalisé et un dictionnaire phonétique: [S5 / Data / Local / LM / Readme.md] (https://github.com/goodatlas/zeroth/blob/master/s5/data/local/lm/readme.md).
Corpus (corpus)
- Connaissances de formation: 109 037 699
- Phrases de test: 12 115 208
- Total: 121 152 907
Dictionnaire phonétique
- Mots uniques: 30 064 143
- Mots uniques avec la fréquence la plus élevée de 98%: 8 069 252
- Morphèmes uniques: 465 253
- Taille du dictionnaire phonétique Considérant la diversité de la prononciation: 686 839
Modèle de langue
- Test de perplexité 3 grammes: ppl = 221,2969 (12 115 208 phrases, 194 940 635 mots, 0 oovs)
- Test de perplexité 4-gramme: PPL = 187,2058 (12 115 208 phrases, 194 940 635 mots, 0 oovs)
Projet: Zeroth
- 칼디를 이용하여 구축하는 한국어 음성인식 오픈소스
- 이제 칼디 공식 한국어 예제입니다 (https://github.com/kaldidi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Licence: Apache 2.0
- 포럼: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth 프로젝트는 Kaldi Open Source-Tool-Kit 을 사용해서 한국어 음성인식기를 구현하는 프로젝트 입니다. 이 프로젝트는 기업이 ai 를 고객 서비스에 추가하는 데 도움이되는 (주) 아틀라스가이드의 Langue ai 플랫폼 개발의 일부로서 일부로서 개발되었습니다. Recette officielle de Kaldi 에 한국어 버전을 소개하는 것을 시작으로, 많은 사람들의 참여를 통해 누구나 사용할 수 있는 음성인식기를 만들어 나갈 수 있도록 하는 것을 것을 목표로하는 프로젝트입니다. 제로스라는 이름은 0 -th, 즉 0 번째를 의미합니다. 이름이 의미하는 것처럼 이 프로젝트를 통해 음성인식기를 만들기 위해 필요한 모든 과정을 처음부터 끝까지 함께 해보고 토론할 수 수 있기를 바랍니다.
Contact: Lucas Jo ([email protected])
Merci spécial
- Gridspace Inc. 사에서 일하고 계신 wonkyum lee 님과의 co-travail 를 통해 이 프로젝트를 진행하고 있음을 있음을 밝힙니다.
Liens mentionnés
- OpenSLR
- 데이터 사이언스 논문 세미나 세미나 @ fastcampus
- 워크샵 @ kmobile
- Entretien avec FastCampus
- 딥러닝 - 음성인식 Camp @ FastCampus
0. Présentation
1. Données audio
- 2018.07.16: 95,7 시간 (46 347 발화, 181 명, 27 330 문장)
- 2018.04.09: 76,6 시간 (35 139 발화, 137 명, 16 472 문장)
- 2018.02.03: 51,6 시간 한국어 학습데이터 (22 263 발화, 105 명, 3000 문장)
- Licence: CC par 4.0
- 현재 OpenSLR 에서 51,6 시간 오디와 LM 데이터를 받아보실 수 있습니다.
- 모어코인을 통한 기부로 오픈소스 오디오가 커지고 있습니다. 4 월에는 1 시간 기부시 70 시간 데이터를 받아보실 수 수. 모어코인앱을 통해 음성을 기부해 주세요.
현재 제로스 프로젝트에는 상기와 같은 음성데이터가 포함되어 있습니다. 공개 음성 DB 구축에 참여할 수 있는 음성 녹음 앱 모아코인 (Android) 을 과 모아코인 (iOS) 제공하고 있으며, 해당 앱을 통해 음성 데이터를 1 시간 기부해주시면 해당 시점까지 구축된 공개 음성 DB 에 접근하여 다운로드할 수 있는 권한을 AWS IMPRÉDENCE TEMPORARY 형태로 발급해 드립니다. 한번 발급된 Création d'identification 은 12 시간 동안 유효합니다. 더 자세한 내용은 AWS-temporaire-créatif 페이지를 확인하시기 바랍니다
2. Exigences
- 제로스 프로젝트를 실행하는데 필요한 패키지들에 대한 설명은 exigences 위키 페이지를 참조하시기 바랍니다.
- 언어모델과 발음사전을 구현하는 코드를 직접 실행하기 위해서는 exigences-2 위키 페이지를 참조하여 추가적인 패키지를 패키지를 설치하시기 바랍니다.
3. Modèle acoustique
현재 제로스 프로젝트 음향모델에는 아래와 같은 최신 Kaldi Recette 가 적용되어 있습니다.
- TDNN (avec factorisation) / TDNN + LSTM / TDNN + OPGRU
- Modèle de chaîne
- Augmentation des données du discours réverbérant
4. Modèle de langue et lexique
제로스 프로젝트에 사용되는 언어모델과 발음사전은 처음부터 끝까지 Prise des données 방식으로 만들어집니다. 아래는 AWS-temporaire-créatif 을 발급받은 경우 오디오 데이터와 함께 자동으로 받아지는 언어모델과 발음사전의 발음사전의 세부사항입니다. 개인적으로 직접 특화된 언어모델과 발음사전을 만들고자 하는 경우에는 세부적인 세부적인
s5 / data / local / lm / readme.md 에 기술되어 있으니 참조하시기 바랍니다 바랍니다.
말뭉치 (corpus)
- 훈련된 문장의 수: 109 037 699
- 테스트 문장의 수: 12 115 208
- 전 체: 121,152 907
발음사전 (lexique)
- 고유한 단어의 수: 30 064,143
- 상위 98% 빈도 수를 보이는 고유한 단어의 수 수: 8 069 252
- Data-Drive 방식으로 찾은 고유한 형태소의 수: 465,253
- 발음 다양성을 고려한 발음사전의 크기: 686 839
언어모델 (modèle de langue)
- Test de perplexité 3 grammes: ppl = 221,2969 (12 115 208 phrases, 194 940 635 mots, 0 oovs)
- Test de perplexité 4-gramme: PPL = 187,2058 (12 115 208 phrases, 194 940 635 mots, 0 oovs)


