المشروع: Zeroth
- مشروع كوري ASR مفتوح المصدر ومقره Kaldi
- وصفة خارجية الآن (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- الترخيص: Apache 2.0
- المنتدى: https://groups.google.com/forum/#! forum/zeroth-help
Zeroth هو مشروع مفتوح المصدر للتعرف على الكلام الكورية التي تم تنفيذها باستخدام مجموعة أدوات Kaldi.
تم تطوير هذا المشروع كجزء من منصة ATLAS LABS (https://www.atlaslabs.ai) ، والتي تمكن المؤسسات من إضافة ذكاء إلى اتصالات B2C الخاصة بهم.
من خلال تقديم وصفة Kaldi كورية رسمية ، يهدف مشروع Zeroth إلى جعل التعرف على الكلام الكورية في متناول الجميع على نطاق أوسع للجميع.
كما يشير اسم Zeroth ، أو 0th ، فإن هدف هذا المشروع هو نقطة الانطلاق وقطعة أساسية يمكن لأي شخص بناء منتجات وخدمات جديدة باستخدام التعرف على الكلام.
نأمل أن تجد هذا المشروع مفيدًا وترحب بأي فرص للمناقشة أو العمل معًا.
الاتصال: Lucas Jo ([email protected])
شكر خاص
- تم تطوير Zeroth بالتعاون مع Winkyum Lee ([email protected]) على [Gridspace Inc.] (https://www.gridspace.com).
الروابط المذكورة
- [openslr] (http://www.openslr.org/40/)
- [ندوة علوم البيانات] (http://www.fastcampus.co.kr/data_camp_lab/) @ fastcampus
- ورشة @ kmobile
- [مقابلة] (http://blog.naver.com/fastcampus/221181060609) مع fastcampus
- [التعلم العميق - معسكر التعرف على الكلام] (http://www.fastcampus.co.kr/data_camp_dsr/) @ fastcampus
0. نظرة عامة
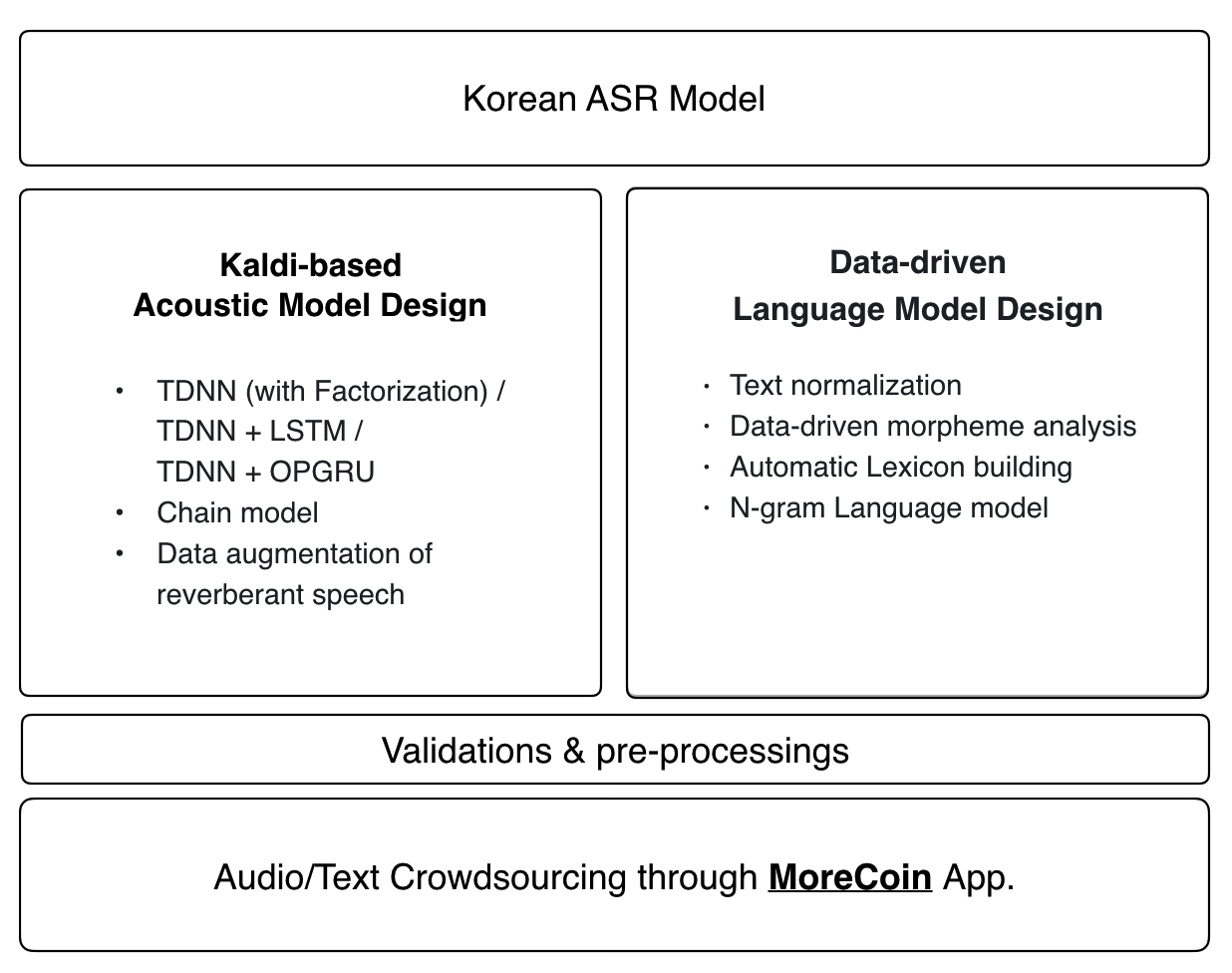
1. بيانات الصوت
- 16 يوليو 2018: 95.7 ساعة (46،347 كلامًا ، 181 متحدثًا ، 27330 جمل Uniq.
- 9 أبريل 2018: 76.6 ساعة (35،139 كلمة ، 137 متحدثًا ، 16،472 جمل.
- 3 فبراير 2018: 51.6 ساعة تم نسخ الصوت الكوري لبيانات التدريب (22،263 كلمة ، 105 مكبرات صوت ، 3000 جملة)
- الترخيص: [CC by 4.0] (https://creativecommons.org/licenses/by/4.0/)
- الآن تتوفر بيانات صوتية و LM 51.6 ساعة في Openslr
- الصوت الحشود الصوتي من موريكوين ينمو. سيتم فتح 70 ساعة من قاعدة بيانات الصوت المفتوحة المصدر في حوالي أبريل 2018. يمكنك التبرع بك من خلال تطبيق التسجيل الصوتي
- [morecoin (Android)] (https://play.google.com/store/apps/details؟id=com.goodatlas.morecoin).
- [morecoin (IOX)] (https://apps.apple.com/ph/app/morecoin/id1351621392؟ign-mpt=uo٪3d2)
نحن نقدم تطبيق تسجيل صوتي [morecoin (Android)] (https://play.google.com/store/apps/details؟id=com.goodatlas.morecoin) يمكنك استخدامه للمشاركة في بناء قاعدة بيانات المصدر المفتوح لدينا لبيانات التدريب الكورية.
2. المتطلبات
- [المتطلبات] وصف الحزم اللازمة لتشغيل مشروع Zeroth: https://github.com/goodatlas/zeroth/wiki/Requirements)
- [المتطلبات -2] حزم إضافية لتنفيذ رمز لنموذج اللغة والقاموس الصوتي: (https://github.com/goodatlas/zeroth/wiki/Requirement-2)
نموذج صوتي
يتم تطبيق أحدث وصفة Kaldi على نموذج Zeroth الصوتي:
- TDNN (مع العوامل) / TDNN + LSTM / TDNN + OPGRU
- نموذج سلسلة
- زيادة البيانات من الكلام الصدغي
نموذج اللغة والمعجم
يستخدم نموذج لغة Zeroth والقاموس الصوتي نهجًا مدفوعًا بالبيانات من طرف إلى طرف. سيتم دمج أي مساهمات في قاعدة بيانات الصوت المفتوحة المصدر تلقائيًا في أحدث نموذج لغوي وقاموس صوتي.
لإنشاء نموذج لغة مخصصة وقاموس صوتي: [S5/DATA/LCING/LM/README.MD] (https://github.com/goodatlas/zeroth/blob/master/s5/data/local/lm/readme.md).
Corpus (Corpus)
- جمل التدريب: 109،037،699
- جمل الاختبار: 12،115،208
- المجموع: 121،152،907
القاموس الصوتي
- كلمات فريدة: 30،064،143
- كلمات فريدة مع أعلى 98 ٪ التردد: 8،069،252
- أشكال فريدة من نوعها: 465،253
- حجم القاموس الصوتي مع الأخذ في الاعتبار تنوع النطق: 686،839
نموذج اللغة
- اختبار الحيرة 3-غرام: PPL = 221.2969 (12،115،208 جمل ، 194،940،635 كلمة ، 0 OOVS)
- اختبار الحيرة 4-غرام: PPL = 187.2058 (12،115،208 جمل ، 194،940،635 كلمة ، 0 OOVS)
المشروع: Zeroth
- 칼디를 이용하여 구축하는 한국어 음성인식
- 이제 칼디 공식 한국어 예제입니다 (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- الترخيص: Apache 2.0
- 포럼: https://groups.google.com/forum/#! Forum/zeroth-help
Zeroth 프로젝트는 Kaldi Open Source Tool-kit 을 사용해서 한국어 음성인식기를 구현하는 프로젝트 입니다. 이 프로젝트는 기업이 ai 를 고객 서비스에 추가하는 데 (주) 아틀라스가이드의 اللغة ai 플랫폼 개발의 일부로서. وصفة Kaldi الرسمية 에 한국어 버전을 것을 시작으로 ، 많은 사람들의 참여를 통해 누구나 사용할 수 있는 음성인식기를 나갈 수 있도록 하는 것을 목표로하는. 제로스라는 이름은 0-th ، 즉 0 번째를 의미합니다. 이름이 의미하는 것처럼 이 프로젝트를 통해 만들기 만들기 위해 모든 과정을 과정을 처음부터 함께 해보고 해보고 수 있기를 바랍니다.
الاتصال: Lucas Jo ([email protected])
شكر خاص
الروابط المذكورة
- openslr
- 데이터 사이언스 논문 세미나 @ fastcampus
- 워크샵 @ kmobile
- مقابلة مع Fastcampus
- 딥러닝-음성인식 camp @ fastcampus
0. نظرة عامة
1. بيانات الصوت
- 2018.07.16: 95.7 시간 (46،347 발화 ، 181 명 ، 27،330 문장)
- 2018.04.09: 76.6 시간 (35،139 발화 ، 137 명 ، 16،472 문장)
- 2018.02.03: 51.6 시간 한국어 학습데이터 (22،263 발화 ، 105 명 ، 3000 문장)
- الترخيص: CC بحلول 4.0
- 현재 openslr 에서 51.6 시간 오디와 lm 데이터를 받아보실 수 있습니다.
- 모어코인을 통한 기부로 오픈소스 오디오가 커지고 있습니다. 4 월에는 1 시간 기부시 70 시간 데이터를 받아보실 수 있습니다. 모어코인앱을 통해 음성을 기부해 주세요.
현재 제로스 프로젝트에는 상기와 같은 음성데이터가 포함되어 있습니다. 공개 음성 db 구축에 참여할 수 있는 녹음 녹음 앱 (Android) 을 과 모아코인 (iOS) 제공하고 있으며 ، 해당 앱을 통해 음성 데이터를 1 시간 해당 시점까지 구축된 구축된 공개 공개 공개 공개 에 에 다운로드할 있는 있는 권한을 권한을 형태로 형태로 형태로 발급해 형태로 발급해. 한번 발급된 بيانات الاعتماد 은 12 시간 동안 유효합니다. 더 자세한 내용은 AWS-페이지를 페이지를 페이지를 페이지를 바랍니다
2. المتطلبات
- 제로스 프로젝트를 실행하는데 필요한 패키지들에 대한 설명은 설명은 위키 위키 참조하시기 참조하시기.
- 언어모델과 발음사전을 구현하는 코드를 직접 실행하기 위해서는 المتطلبات -2 위키 참조하여 참조하여 추가적인 패키지를 설치하시기 바랍니다.
3. نموذج صوتي
현재 제로스 프로젝트 음향모델에는 아래와 같은 최신 kaldi وصفة 가 적용되어 있습니다.
- TDNN (مع العوامل) / TDNN + LSTM / TDNN + OPGRU
- نموذج سلسلة
- زيادة البيانات من الكلام الصدغي
4. نموذج اللغة والمعجم
제로스 프로젝트에 사용되는 언어모델과 발음사전은 처음부터 끝까지 يحركها 방식으로 방식으로 만들어집니다. 아래는 AWS-TERSPORARY-CREDINALITY 을 발급받은 경우 오디오 함께 함께 자동으로 받아지는 언어모델과 발음사전의. 개인적으로 직접 특화된 언어모델과 발음사전을 만들고자 하는 경우에는 세부적인
S5/DATA/LOCAL/LM/README.MD 에 있으니 있으니 참조하시기 바랍니다.
말뭉치 (Corpus)
- 훈련된 문장의 수: 109،037،699
- 테스트 문장의 수: 12،115،208
- 전 체: 121،152،907
발음사전 (معجم)
- 고유한 단어의 수: 30،064،143
- 상위 98 ٪ 빈도 수를 보이는 단어의 수: 8،069،252
- Data-Drive 방식으로 찾은 고유한 수: 465،253
- 발음 다양성을 고려한 발음사전의 크기: 686،839
언어모델 (نموذج اللغة)
- اختبار الحيرة 3-غرام: PPL = 221.2969 (12،115،208 جمل ، 194،940،635 كلمة ، 0 OOVS)
- اختبار الحيرة 4-غرام: PPL = 187.2058 (12،115،208 جمل ، 194،940،635 كلمة ، 0 OOVS)


