Projeto: Zeroth
- Projeto Coreano ASR de Kaldi ASR
- Receita Offcial agora (https://github.com/kaldi-asr/kaldi/tree/master/egs/zerroth_korean/s5)
- Licença: Apache 2.0
- Fórum: https://groups.google.com/forum/#!forum/zerroth-help
Zeroth é um projeto de código aberto para o reconhecimento de fala coreano implementado usando o kit kaldi.
Este projeto foi desenvolvido como parte da plataforma AI da Atlas Labs (https://www.atlaslabs.ai), o que permite que as empresas adicionem inteligência às suas comunicações B2C.
Ao introduzir uma receita oficial de Kaldi coreana, o projeto Zeroth pretende tornar o reconhecimento coreano de fala mais amplamente acessível a todos.
Como o nome Zeroth, ou o 0º, sugere, o objetivo deste projeto é o ponto de partida e uma peça fundamental sobre a qual qualquer pessoa pode construir novos produtos e serviços usando reconhecimento de fala.
Esperamos que você ache este projeto útil e dê as boas -vindas a qualquer oportunidade de discutir ou trabalhar juntos.
Contato: Lucas Jo ([email protected])
Obrigado especial
- Zeroth foi desenvolvido em colaboração com Wonkyum Lee ([email protected]) em [Gridspace Inc.] (https://www.gridspace.com).
Links mencionados
- [OpenSlr] (http://www.openslr.org/40/)
- [Seminário de Ciência de Dados] (http://www.fastcampus.co.kr/data_camp_lab/) @ fastcampus
- Workshop @ kmobile
- [Entrevista] (http://blog.naver.com/fastcampus/221181060609) com fastcampus
- [Deep Learning - Campo de reconhecimento de fala] (http://www.fastcampus.co.kr/data_camp_dsr/) @ fastcampus
0. Visão geral
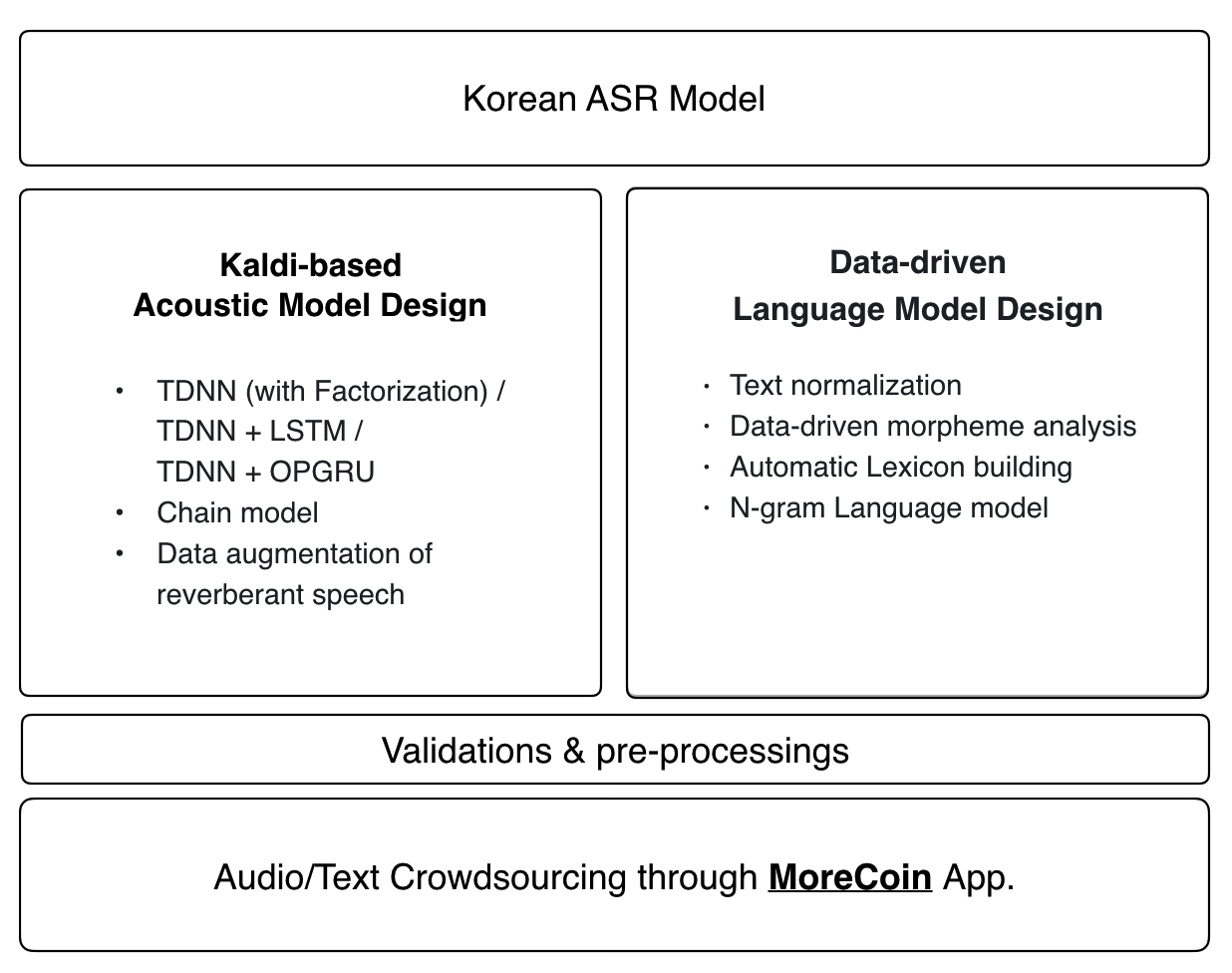
1. Dados de áudio
- 16 de julho de 2018: 95,7 horas (46.347 utensílios, 181 palestrantes, 27.330 Uniq. Frases)
- 9 de abril de 2018: 76,6 horas (35.139 utterâncias, 137 palestrantes, 16.472 Uniq. Frases)
- 3 de fevereiro de 2018: 51,6 horas transcritas de áudio coreano para dados de treinamento (22.263 utensílios, 105 alto -falantes, 3000 frases)
- Licença: [CC por 4.0] (https://creativecommons.org/license/by/4.0/)
- Agora, 51,6 horas de áudio e dados LM estão disponíveis no OpenSLR
- O Audio Crowdsource da Morecoin está crescendo. 70 horas de base de dados de áudio de código aberto serão abertas por volta de abril de 2018. Você pode doar o seu embora o aplicativo de gravação de voz
- [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin).
- [Morecoin (iox)] (https://apps.apple.com/ph/app/morecoin/id1351621392?ign-mpt=uo%3D2)
Oferecemos um aplicativo de gravação de voz [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin) que você pode usar para participar da criação de nosso banco de dados de código aberto dos dados de treinamento coreano.
2. Requisitos
- [Requisitos] Descrição dos pacotes necessários para executar o Projeto Zeroth: https://github.com/goodatlas/zerroth/wiki/ReQuirements)
- [Requisitos-2] Pacotes adicionais para executar o código para o modelo de idioma e o dicionário fonético: (https://github.com/goodatlas/zerroth/wiki/requiement-2)
Modelo acústico
A receita mais recente do kaldi é aplicada ao modelo acústico do Zeroth:
- Tdnn (com fatorização) / tdnn + lstm / tdnn + opGru
- Modelo de cadeia
- Aumentação de dados do discurso reverberante
Modelo de idioma e léxico
O modelo de linguagem de Zeroth e o dicionário fonético usam uma abordagem orientada a dados de ponta a ponta. Quaisquer contribuições para o nosso banco de dados de áudio de código aberto serão automaticamente incorporadas ao mais recente modelo de idioma e dicionário fonético.
Para criar um modelo de idioma personalizado e dicionário fonético: [S5/Data/Local/LM/Readme.md] (https://github.com/goodatlas/zerroth/blob/master/s5/data/local/lm/readme.md).
Corpus (corpus)
- Frases de treinamento: 109.037.699
- Frases de teste: 12.115.208
- TOTAL: 121.152.907
Dicionário fonético
- Palavras únicas: 30.064.143
- Palavras únicas com a maior frequência de 98%: 8.069.252
- Morfemas únicos: 465.253
- Tamanho do dicionário fonético, considerando a diversidade de pronúncia: 686.839
Modelo de idioma
- Teste de perplexidade 3 gramas: ppl = 221.2969 (12.115.208 frases, 194.940.635 palavras, 0 oovs)
- Teste de perplexidade 4 gramas: ppl = 187.2058 (12.115.208 frases, 194.940.635 palavras, 0 oovs)
Projeto: Zeroth
- 칼디를 이용하여 구축하는 한국어 음성인식 오픈소스
- 이제 칼디 공식 한국어 예제입니다 (https://github.com/kaldi-asr/kaldi/tree/master/egs/zerroth_korean/s5)
- Licença: Apache 2.0
- 포럼: https://groups.google.com/forum/#!forum/zerroth-help
Zeroth 프로젝트는 kaldi de código aberto ferramenta-kit 을 사용해서 한국어 구현하는 구현하는 프로젝트 입니다. 이 기업이 기업이 ai 를 고객 서비스에 추가하는 데 도움이되는 (주) 아틀라스가이드의 idioma ai 플랫폼 개발의 일부로서 개발되었습니다. Receita oficial de kaldi 에 한국어 버전을 소개하는 것을 시작으로, 많은 사람들의 참여를 통해 누구나 사용할 수 있는 음성인식기를 만들어 나갈 수 있도록 하는 것을 목표로하는 프로젝트입니다. 제로스라는 이름은 0-th, 즉 0 번째를 의미합니다. 이름이 의미하는 것처럼 프로젝트를 통해 음성인식기를 만들기 위해 필요한 모든 과정을 처음부터 끝까지 함께 해보고 토론할 수 있기를 바랍니다.
Contato: Lucas Jo ([email protected])
Obrigado especial
- Gridspace Inc. 사에서 계신 계신 Wonkyum lee 님과의 Co-trabalho 를 통해 이 프로젝트를 진행하고 있음을 밝힙니다.
Links mencionados
- OpenSlr
- 데이터 사이언스 논문 세미나 @ fastcampus
- 워크샵 @ kmobile
- Entrevista com o fastcampus
- 딥러닝-음성인식 Camp @ fastcampus
0. Visão geral
1. Dados de áudio
- 2018.07.16: 95.7 시간 (46.347 발화, 181 명, 27.330 문장)
- 2018.04.09: 76.6 시간 (35.139 발화, 137 명, 16.472 문장)
- 2018.02.03: 51.6 시간 한국어 학습데이터 (22.263 발화, 105 명, 3000 문장)
- Licença: CC por 4.0
- 현재 Openlr 에서 51.6 시간 오디와 lm 데이터를 받아보실 수 있습니다.
- 모어코인을 통한 기부로 오픈소스 오디오가 커지고 있습니다. 4 월에는 1 시간 기부시 70 시간 데이터를 받아보실 수 있습니다. 모어코인앱을 통해 음성을 기부해 주세요.
현재 제로스 프로젝트에는 상기와 같은 음성데이터가 포함되어 있습니다. 공개 음성 DB 구축에 참여할 수 있는 음성 녹음 앱 모아코인(Android)을 과 모아코인(iOS)제공하고 있으며, 해당 앱을 통해 음성 데이터를 1시간 기부해주시면 해당 시점까지 구축된 공개 음성 DB에 접근하여 다운로드할 수 있는 권한을 AWS temporary credential 형태로 발급해 드립니다. 한번 발급된 Credencial 은 12 시간 동안 유효합니다. 더 자세한 내용은 AWS-CREDENCIAL 페이지를 확인하시기 바랍니다 바랍니다 바랍니다
2. Requisitos
- 제로스 프로젝트를 실행하는데 필요한 패키지들에 대한 설명은 requisitos 위키 페이지를 참조하시기 바랍니다.
- 언어모델과 발음사전을 구현하는 코드를 직접 실행하기 위해서는 requisitos-2 위키 페이지를 참조하여 추가적인 패키지를 설치하시기 바랍니다.
3. Modelo acústico
현재 제로스 프로젝트 음향모델에는 아래와 같은 최신 Receita kaldi 가 적용되어 있습니다.
- Tdnn (com fatorização) / tdnn + lstm / tdnn + opGru
- Modelo de cadeia
- Aumentação de dados do discurso reverberante
4. Modelo de idioma e léxico
제로스 프로젝트에 사용되는 언어모델과 발음사전은 끝까지 끝까지 orientado a dados 방식으로 만들어집니다. 아래는 AWS-CREDENCIAL 을 발급받은 경우 오디오 데이터와 함께 자동으로 언어모델과 발음사전의 발음사전의 세부사항입니다. 개인적으로 직접 특화된 언어모델과 발음사전을 만들고자 하는 경우에는 세부적인 방법이
s5/dados/local/lm/readme.md 에 기술되어 있으니 참조하시기 바랍니다.
말뭉치 (corpus)
- 훈련된 문장의 수: 109.037.699
- 테스트 문장의 수: 12.115.208
- 전 체: 121.152.907
발음사전 (léxico)
- 고유한 단어의 수: 30.064.143
- 상위 98% 빈도 수를 보이는 고유한 단어의 수: 8.069.252
- Data-drive 방식으로 찾은 고유한 형태소의 수: 465,253
- 발음 다양성을 고려한 발음사전의 크기: 686.839
언어모델 (Modelo de idioma)
- Teste de perplexidade 3 gramas: ppl = 221.2969 (12.115.208 frases, 194.940.635 palavras, 0 oovs)
- Teste de perplexidade 4 gramas: ppl = 187.2058 (12.115.208 frases, 194.940.635 palavras, 0 oovs)


