프로젝트 : Zeroth
- 칼디에 기반을 둔 한국 ASR 오픈 소스 프로젝트
- Offcial Recipe Now (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- 라이센스 : Apache 2.0
- 포럼 : https://groups.google.com/forum/# !forum/zeroth-help
Zeroth는 Kaldi Toolkit을 사용하여 구현 된 한국 음성 인식을위한 오픈 소스 프로젝트입니다.
이 프로젝트는 Atlas Labs (https://www.atlaslabs.ai) Language AI 플랫폼의 일부로 개발되었으며, 이는 기업이 B2C 커뮤니케이션에 인텔리전스를 추가 할 수 있습니다.
한국의 한국 칼디 레시피를 소개함으로써 제로 프로젝트는 한국의 음성 인식을 모든 사람에게보다 광범위하게 접근 할 수 있도록하는 것을 목표로합니다.
Zeroth 또는 0th라는 이름으로,이 프로젝트는 출발점이자 누구나 스피치 인식을 사용하여 누구나 신제품과 서비스를 구축 할 수있는 기본 작품입니다.
이 프로젝트가 유용하고 토론하거나 함께 일할 수있는 기회를 환영합니다.
연락처 : Lucas Jo ([email protected])
특별한 감사
- Zeroth는 [Gridspace Inc.] (https://www.gridspace.com)의 Wonkyum Lee ([email protected])와 공동으로 개발되었습니다.
언급 된 링크
- [openslr] (http://www.openslr.org/40/)
- [데이터 과학 세미나] (http://www.fastcampus.co.kr/data_camp_lab/) @ fastcampus
- 워크숍 @ kmobile
- [인터뷰] (http://blog.naver.com/fastcampus/221181060609)
- [딥 러닝 - 음성 인식 캠프] (http://www.fastcampus.co.kr/data_camp_dsr/) @ fastcampus
0. 개요
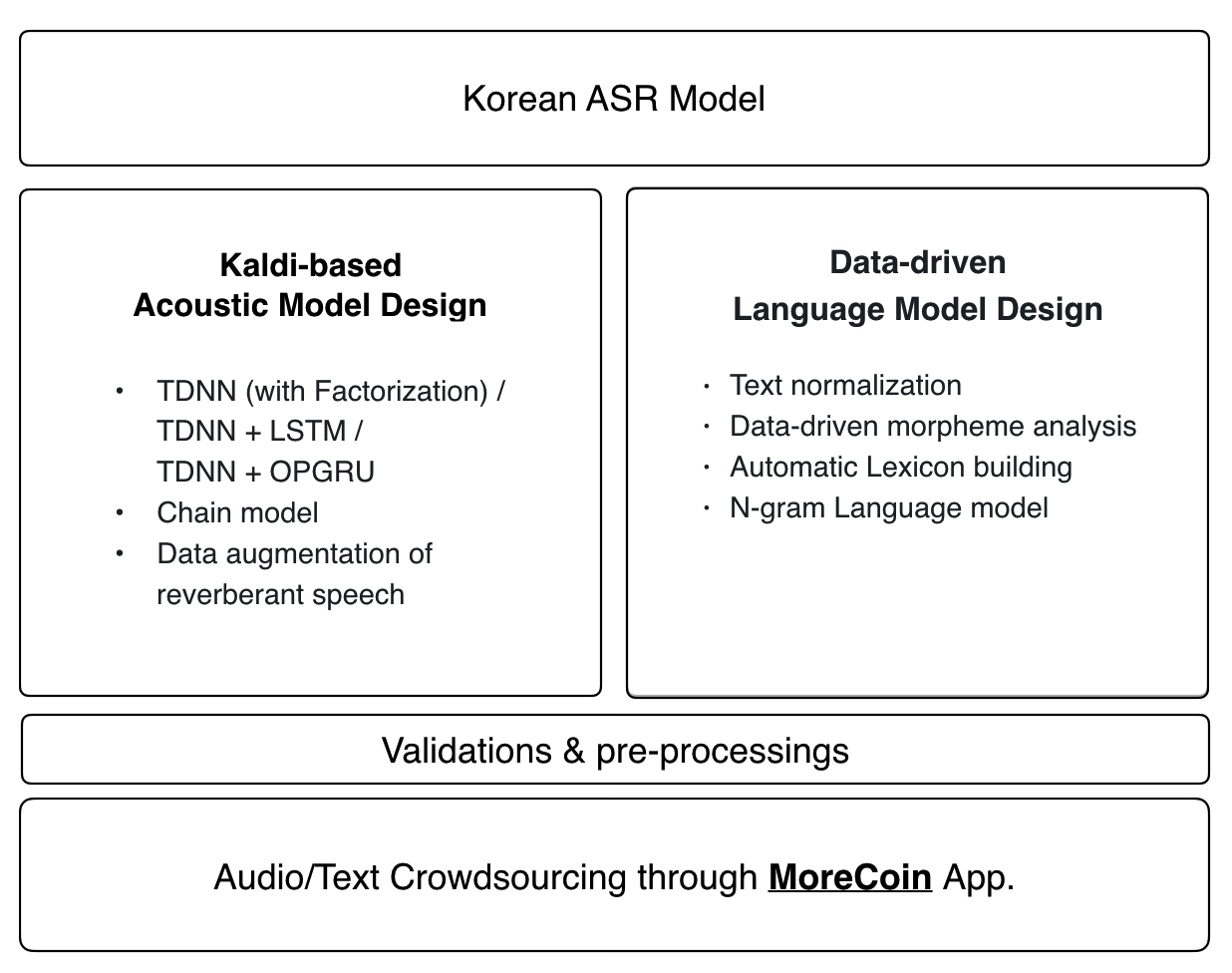
1. 오디오 데이터
- 2018 년 7 월 16 일 : 95.7 시간 (46,347 개의 발언, 181 명의 스피커, 27,330 Uniq. 문장)
- 2018 년 4 월 9 일 : 76.6 시간 (35,139 개의 발언, 137 명의 스피커, 16,472 Uniq. 문장)
- 2018 년 2 월 3 일 : 51.6 시간 훈련 데이터를위한 한국 오디오 전사 (22,263 개의 발언, 105 개의 스피커, 3000 문장)
- 라이센스 : [CC by 4.0] (https://creativecommons.org/licenses/by/4.0/)
- 이제 51.6 시간 오디오 및 LM 데이터를 OpenSLR에서 사용할 수 있습니다.
- Morecoin의 오디오 크라우드 소스가 성장하고 있습니다. 70 시간의 오픈 소스 오디오 데이터베이스가 2018 년 4 월경에 열립니다. 음성 녹음 앱을 통해 기부 할 수 있습니다.
- [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin).
- [Morecoin (iox)] (https://apps.apple.com/ph/app/morecoin/id1351621392?ign-mpt=uo%3d2)
우리는 한국 교육 데이터의 오픈 소스 데이터베이스 구축에 참여하는 데 사용할 수있는 음성 녹음 앱 [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin)를 제공합니다.
2. 요구 사항
- [요구 사항] Zeroth 프로젝트를 실행하는 데 필요한 패키지 설명 : https://github.com/goodatlas/zeroth/wiki/requirements)
- [요구 사항 -2] 언어 모델 및 음성 사전에 대한 코드를 실행하기위한 추가 패키지 : (https://github.com/goodatlas/zeroth/wiki/requirement-2)
음향 모델
최신 Kaldi 레시피는 Zeroth의 음향 모델에 적용됩니다.
- tdnn (인수 분해 포함) / tdnn + lstm / tdnn + opgru
- 체인 모델
- 반향 연설의 데이터 확대
언어 모델 및 사전
Zeroth의 언어 모델 및 발음 사전은 엔드 투 엔드 데이터 중심 접근 방식을 사용합니다. 오픈 소스 오디오 데이터베이스에 대한 모든 기여는 자동으로 최신 언어 모델 및 발음 사전에 통합됩니다.
사용자 정의 언어 모델 및 음성 사전을 만들려면 : [S5/Data/local/lm/readme.md] (https://github.com/goodatlas/zeroth/blob/master/s5/data/local/lm/readme.md).
코퍼스 (코퍼스)
- 훈련 문장 : 109,037,699
- 시험 문장 : 12,115,208
- 총 : 121,152,907
음성 사전
- 독특한 단어 : 30,064,143
- 98% 빈도가 가장 높은 고유 단어 : 8,069,252
- 독특한 형태소 : 465,253
- 발음 다양성을 고려한 음성 사전의 크기 : 686,839
언어 모델
- Perplexity Test 3-Gram : PPL = 221.2969 (12,115,208 문장, 194,940,635 단어, 0 OOV)
- Perplexity Test 4-Gram : PPL = 187.2058 (12,115,208 문장, 194,940,635 단어, 0 OOVS)
프로젝트 : Zeroth
- 칼디를 칼디를 구축하는 이용하여 음성인식 오픈소스 오픈소스
- 이제 이제 공식 칼디 예제입니다 (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- 라이센스 : Apache 2.0
- 포럼 : https://groups.google.com/forum/# !forum/zeroth-help
Zeroth ald Kaldi 오픈 소스 도구 키트을 사용해서 한국어 음성인식기를 구현하는 프로젝트입니다. 이이 기업이 기업이 ai를를 고객 서비스에 추가하는 데 도움이되는 도움이되는 (주) 아틀라스가이드의 언어 ai 플랫폼 개발의 일부로서 개발되었습니다. 칼디 공식 레시피 official 한국어 한국어 버전을 소개하는 것을 시작으로, 많은 사람들의 참여를 참여를 통해 누구나 사용할 수있는있는 음성인식기를 만들어 나갈 수 있도록하는 것을 목표로하는 프로젝트입니다 프로젝트입니다. 제로스라는 제로스라는 0-th, 즉 0 번째를 의미합니다. 이름이 이름이 것처럼 의미하는 의미하는 프로젝트를 통해 음성인식기를 음성인식기를 만들기 위해 필요한 모든 모든 과정을 처음부터 끝까지 함께 해보고 토론할 수 있기를 바랍니다 바랍니다.
연락처 : Lucas Jo ([email protected])
특별한 감사
- Gridspace Inc. ace 일하고 일하고 계신 계신 wonkyum lee 님과의 공동 작업를 통해이이 프로젝트를 진행하고 밝힙니다 밝힙니다.
언급 된 링크
- Openslr
- sastcampus
- 워크샵 @ kmobile
- FastCampus와의 인터뷰
- 딥러닝 -PASTCAMPUS @ CAMP @ CAMP
0. 개요
1. 오디오 데이터
- 2018.07.16 : 95.7 시간 (46,347 발화, 181 명, 27,330 문장)
- 2018.04.09 : 76.6 ℃
- 2018.02.03 : 51.6 시간 한국어 학습데이터 (22,263 발화, 105 명, 3000 문장)
- 라이센스 : CC x 4.0
- Openslr ens 51.6 시간 오디와 오디와 lm 데이터를 받아보실 수 있습니다 있습니다.
- 모어코인을 모어코인을 기부로 통한 오디오가 오디오가 커지고 있습니다. 4 기부시 1 시간 월에는 70 시간 시간 데이터를 받아보실 수 있습니다. 모어코인앱을 모어코인앱을 음성을 통해주세요.
현재 현재 프로젝트에는 제로스 제로스 같은 음성데이터가 포함되어 있습니다 있습니다. 공개 음성 DB 구축에 참여할 수 있는 음성 녹음 앱 모아코인(Android)을 과 모아코인(iOS)제공하고 있으며, 해당 앱을 통해 음성 데이터를 1시간 기부해주시면 해당 시점까지 구축된 공개 음성 DB에 접근하여 다운로드할 수 있는 권한을 AWS temporary credential 형태로 발급해 드립니다. 한번 한번 자격 증명 발급된 12 시간 동안 유효합니다. 더 더 내용은 내용은 aws-temporary-thredential 페이지를 확인하시기 바랍니다 바랍니다
2. 요구 사항
- 제로스 제로스 제로스 실행하는데 프로젝트를 패키지들에 대한 설명은 설명은 요구 사항 위키 페이지를 참조하시기 바랍니다 바랍니다.
- 언어모델과 언어모델과 언어모델과 구현하는 발음사전을 직접 실행하기 위해서는 위해서는 요구 사항 -2 위키 페이지를 참조하여 추가적인 패키지를 설치하시기 바랍니다.
3. 음향 모델
현재 현재 프로젝트 제로스 제로스 아래와 같은 최신 최신 kaldi 레시피가 적용되어 있습니다.
- tdnn (인수 분해 포함) / tdnn + lstm / tdnn + opgru
- 체인 모델
- 반향 연설의 데이터 확대
4. 언어 모델 및 어휘
제로스 제로스 사용되는 사용되는 프로젝트에 발음사전은 처음부터 끝까지 끝까지 데이터 중심 방식으로 만들어집니다 만들어집니다. 아래는 aws-temporary-credential을 발급받은 경우 오디오 오디오 데이터와 함께 자동으로 받아지는 언어모델과 발음사전의 세부사항입니다 세부사항입니다. 개인적으로 개인적으로 개인적으로 특화된 직접 발음사전을 만들고자 만들고자하는 경우에는 세부적인 방법이 방법이
s5/data/local/lm/readme.md에 기술되어 있으니 참조하시기 바랍니다.
말뭉치 (코퍼스)
- 훈련된 훈련된 수 : 109,037,699
- 테스트 테스트 수 : 12,115,208
- 전 전 : 121,152,907
발음사전 (Lexicon)
- 고유한 고유한 수 : 30,064,143
- 상위 98%% 수를 보이는 보이는 고유한 수 수 : 8,069,252
- 데이터 드라이브 방식으로 ive 고유한 형태소의 수 : 465,253
- 발음 발음 고려한 다양성을 크기 : 686,839
언어모델 (언어 모델)
- Perplexity Test 3-Gram : PPL = 221.2969 (12,115,208 문장, 194,940,635 단어, 0 OOV)
- Perplexity Test 4-Gram : PPL = 187.2058 (12,115,208 문장, 194,940,635 단어, 0 OOVS)


