Proyek: Zeroth
- Proyek Sumber Terbuka ASR Korea yang berbasis di Kaldi
- Resep Offcial Sekarang (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Lisensi: Apache 2.0
- Forum: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth adalah proyek open source untuk pengenalan suara Korea yang diimplementasikan menggunakan Kaldi Toolkit.
Proyek ini dikembangkan sebagai bagian dari platform AI bahasa Atlas Labs (https://www.atlaslabs.ai), yang memungkinkan perusahaan untuk menambah kecerdasan pada komunikasi B2C mereka.
Dengan memperkenalkan resep resmi Korea Kaldi, proyek Zeroth bertujuan untuk membuat pengakuan ucapan Korea lebih luas dapat diakses oleh semua orang.
Seperti nama Zeroth, atau yang ke -0, menunjukkan, proyek ini bertujuan untuk menjadi titik awal dan bagian dasar di mana siapa pun dapat membangun produk dan layanan baru menggunakan pengenalan suara.
Kami harap Anda menemukan proyek ini bermanfaat dan menyambut peluang apa pun untuk berdiskusi atau bekerja bersama.
Hubungi: Lucas Jo ([email protected])
Terima kasih khusus
- Zeroth dikembangkan bekerja sama dengan Wonkyum Lee ([email protected]) di [Gridspace Inc.] (https://www.gridspace.com).
Tautan yang disebutkan
- [Openslr] (http://www.openslr.org/40/)
- [Seminar Ilmu Data] (http://www.fastcampus.co.kr/data_camp_lab/) @ fastcampus
- Workshop @ kmobile
- [Wawancara] (http://blog.naver.com/fastcampus/221181060609) dengan fastcampus
- [Deep Learning - Kamp Pengenalan Pidato] (http://www.fastcampus.co.kr/data_camp_dsr/) @ fastcampus
0. Ikhtisar
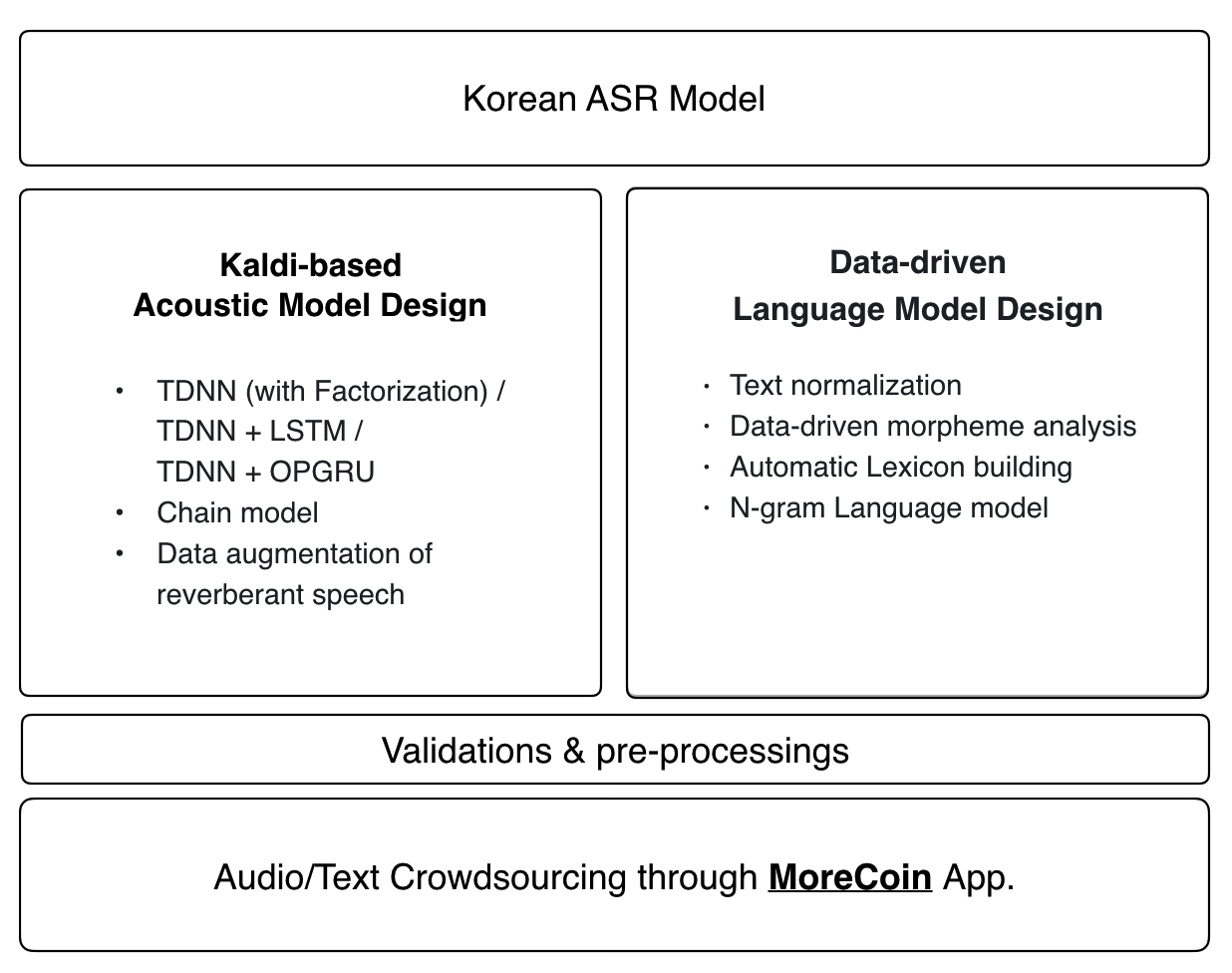
1. Data audio
- 16 Juli 2018: 95,7 jam (46.347 ucapan, 181 pembicara, 27.330 UNIQ. Kalimat)
- 9 April 2018: 76,6 jam (35.139 ucapan, 137 pembicara, 16.472 UNIQ. Kalimat)
- 3 Februari 2018: 51,6 jam audio Korea yang ditranskripsi untuk data pelatihan (22.263 ucapan, 105 pembicara, 3000 kalimat)
- Lisensi: [CC oleh 4.0] (https://creativecommons.org/licenses/by/4.0/)
- Sekarang 51,6 jam data audio dan lm tersedia di openslr
- Audio Crowdsource dari Morecoin tumbuh. 70 jam basis data audio open-source akan dibuka sekitar April 2018. Anda dapat menyumbangkan aplikasi Anda melalui aplikasi perekaman suara
- [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin).
- [Morecoin (IOX)] (https://apps.apple.com/ph/app/morecoin/id1351621392?ign-mpt=uo%3d2)
Kami menawarkan aplikasi perekaman suara [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin) yang dapat Anda gunakan untuk berpartisipasi dalam membangun basis data sumber terbuka kami tentang data pelatihan Korea.
2. Persyaratan
- [Persyaratan] Deskripsi paket yang diperlukan untuk menjalankan proyek Zeroth: https://github.com/goodatlas/zeroth/wiki/requirements)
- [Persyaratan-2] Paket tambahan untuk menjalankan kode untuk model bahasa dan kamus fonetik: (https://github.com/goodatlas/zeroth/wiki/requirement-2)
Model akustik
Resep Kaldi terbaru diterapkan pada model akustik Zeroth:
- Tdnn (dengan faktorisasi) / tdnn + lstm / tdnn + opgru
- Model rantai
- Augmentasi data ucapan gema
Model Bahasa & Leksikon
Model bahasa Zeroth dan kamus fonetik menggunakan pendekatan yang didorong oleh data ujung ke ujung. Setiap kontribusi untuk basis data audio open source kami akan secara otomatis dimasukkan ke dalam model bahasa terbaru dan kamus fonetik.
Untuk membuat model bahasa khusus dan kamus fonetik: [S5/data/lokal/lm/readme.md] (https://github.com/goodatlas/zeroth/blob/master/s5/data/local/lm/readme.md).
Corpus (Corpus)
- Kalimat Pelatihan: 109.037.699
- Kalimat Uji: 12.115.208
- Total: 121.152.907
Kamus Fonetik
- Kata -kata unik: 30.064.143
- Kata -kata unik dengan frekuensi 98% tertinggi: 8.069.252
- Morfem Unik: 465.253
- Ukuran kamus fonetik mempertimbangkan keragaman pengucapan: 686.839
Model Bahasa
- Tes Perplexity 3-gram: ppl = 221.2969 (12.115.208 kalimat, 194.940.635 kata, 0 OOVS)
- Tes Perplexity 4-gram: ppl = 187.2058 (12.115.208 kalimat, 194.940.635 kata, 0 OOVS)
Proyek: Zeroth
- 칼디를 이용하여 구축하는 한국어 음성인식 오픈소스
- 이제 칼디 공식 한국어 예제입니다 (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Lisensi: Apache 2.0
- 포럼: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth 프로젝트는 Kaldi Open Source Tool-Kit 을 사용해서 한국어 음성인식기를 구현하는 프로젝트 입니다. 이 프로젝트는 기업이 ai 를 고객 서비스에 추가하는 데 도움이되는 (주) 아틀라스가이드의 bahasa Ai 플랫폼 개발의 일부로서 개발되었습니다. Resep resmi Kaldi 에 한국어 버전을 소개하는 것을 시작으로, 많은 사람들의 참여를 통해 누구나 사용할 수 있는 음성인식기를 만들어 나갈 수 있도록 하는 것을 목표로하는 프로젝트입니다. 제로스라는 이름은 0-th, 즉 0 번째를 의미합니다. 이름이 의미하는 것처럼 이 프로젝트를 통해 음성인식기를 만들기 위해 필요한 모든 과정을 처음부터 끝까지 함께 해보고 토론할 수 있기를 바랍니다.
Hubungi: Lucas Jo ([email protected])
Terima kasih khusus
- Gridspace Inc. 사에서 일하고 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 계신 진행하고 진행하고 있음을 있음을 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다
Tautan yang disebutkan
- Openslr
- 데이터 사이언스 논문 세미나 @ fastcampus
- 워크샵 @ kmobile
- Wawancara dengan Fastcampus
- 딥러닝-음성인식 Camp @ fastcampus
0. Ikhtisar
1. Data audio
- 2018.07.16: 95.7 시간 (46.347 발화, 181 명, 27.330 문장)
- 2018.04.09: 76.6 시간 (35.139 발화, 137 명, 16.472 문장)
- 2018.02.03: 51.6 시간 한국어 학습데이터 (22.263 발화, 105 명, 3000 문장)
- Lisensi: CC dengan 4.0
- 현재 OpenSlr 에서 51.6 시간 오디와 lm 데이터를 받아보실 수 있습니다.
- 모어코인을 통한 기부로 오픈소스 오디오가 커지고 있습니다. 4 월에는 1 시간 기부시 70 시간 데이터를 받아보실 수 있습니다. 모어코인앱을 통해 음성을 기부해 주세요.
현재 제로스 프로젝트에는 상기와 같은 음성데이터가 포함되어 있습니다. 공개 음성 dB 구축에 참여할 수 있는 음성 녹음 앱 모아코인 모아코인 을 을 을 과 모아코인 모아코인 모아코인 모아코인 기부해주시면 해당 시점까지 구축된 공개 음성 에 접근하여 다운로드할 다운로드할 있는 있는 있는 있는 권한을 있는 있는 있는 있는 있는 있는 해당 해당 시점까지 시점까지 시점까지 공개 공개 음성 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 권한을 있는 있는 있는 있는 있는 있는 한번 발급된 Kredensial 은 12 시간 동안 유효합니다. 더 자세한 내용은 AWS-temporer-kredensial 페이지를 바랍니다 바랍니다
2. Persyaratan
- 제로스 프로젝트를 실행하는데 필요한 패키지들에 대한 설명은 Persyaratan 위키 페이지를 참조하시기 바랍니다.
- 언어모델과 발음사전을 구현하는 코드를 직접 실행하기 위해서는 Persyaratan-2 위키 페이지를 참조하여 추가적인 패키지를 설치하시기 바랍니다.
3. Model akustik
현재 제로스 프로젝트 음향모델에는 아래와 같은 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 최신 같은 같은 같은 같은 같은 같은 같은 같은 같은 같은 같은 같은 같은.
- Tdnn (dengan faktorisasi) / tdnn + lstm / tdnn + opgru
- Model rantai
- Augmentasi data ucapan gema
4. Model Bahasa & Leksikon
제로스 프로젝트에 사용되는 언어모델과 발음사전은 처음부터 끝까지 끝까지 끝까지 끝까지 끝까지 끝까지 끝까지 끝까지 끝까지 끝까지 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 처음부터 아래는 AWS-temporer-kredensial 을 발급받은 경우 오디오 데이터와 함께 자동으로 받아지는 언어모델과 발음사전의 세부사항입니다. 개인적으로 직접 특화된 언어모델과 발음사전을 만들고자 하는 경우에는 세부적인 방법이
S5/data/lokal/lm/readme.md 에 기술되어 있으니 참조하시기 바랍니다.
말뭉치 (corpus)
- 훈련된 문장의 수: 109.037.699
- 테스트 문장의 수: 12.115.208
- 전 체: 121.152.907
발음사전 (leksikon)
- 고유한 단어의 수: 30.064.143
- 상위 98% 빈도 수를 보이는 고유한 단어의 수: 8.069.252
- Data-drive 방식으로 찾은 고유한 형태소의 수: 465.253
- 발음 다양성을 고려한 발음사전의 크기: 686.839
언어모델 (model bahasa)
- Tes Perplexity 3-gram: ppl = 221.2969 (12.115.208 kalimat, 194.940.635 kata, 0 OOVS)
- Tes Perplexity 4-gram: ppl = 187.2058 (12.115.208 kalimat, 194.940.635 kata, 0 OOVS)


