Projekt: Zeroth
- Kaldi ansässiges koreanisches ASR Open-Source-Projekt
- Offcial Rezept jetzt (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Lizenz: Apache 2.0
- Forum: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth ist ein Open -Source -Projekt für die koreanische Spracherkennung, die mit dem Kaldi -Toolkit implementiert wird.
Dieses Projekt wurde als Teil der Sprach -AI -Plattform von Atlas Labs (https://www.atlaslabs.ai) entwickelt, mit der Unternehmen ihre B2C -Kommunikation Intelligenz hinzufügen können.
Durch die Einführung eines offiziellen koreanischen Kaldi -Rezepts zielt das Zeroth -Projekt darauf ab, die koreanische Sprachanerkennung für alle allgemeiner zugänglich zu machen.
Wie der Name Zeroth oder der 0. aussetzt, zielt das Ziel dieses Projekts, der Ausgangspunkt und ein grundlegender Stück zu sein, auf den jeder mit Spracherkennung neue Produkte und Dienstleistungen bauen kann.
Wir hoffen, dass Sie dieses Projekt nützlich finden, und begrüßen die Möglichkeiten, zusammen zu diskutieren oder zusammenzuarbeiten.
Kontakt: Lucas Jo ([email protected])
Besonderer Dank
- Zeroth wurde in Zusammenarbeit mit Wonkyum Lee ([email protected]) unter [Gridspace Inc.] (https://www.gridspace.com) entwickelt.
Erwähnte Links
- [OpenSLR] (http://www.opensslr.org/40/)
- [Data Science Seminar] (http://www.fastcampus.co.kr/data_camp_lab/) @ fastcampus
- Workshop @ Kmobile
- [Interview] (http://blog.naver.com/fastcampus/221181060609) mit Fastcampus
- [Deep Learning - Spracherkennungscamp] (http://www.fastcampus.co.kr/data_camp_dsr/) @ fastcampus
0. Übersicht
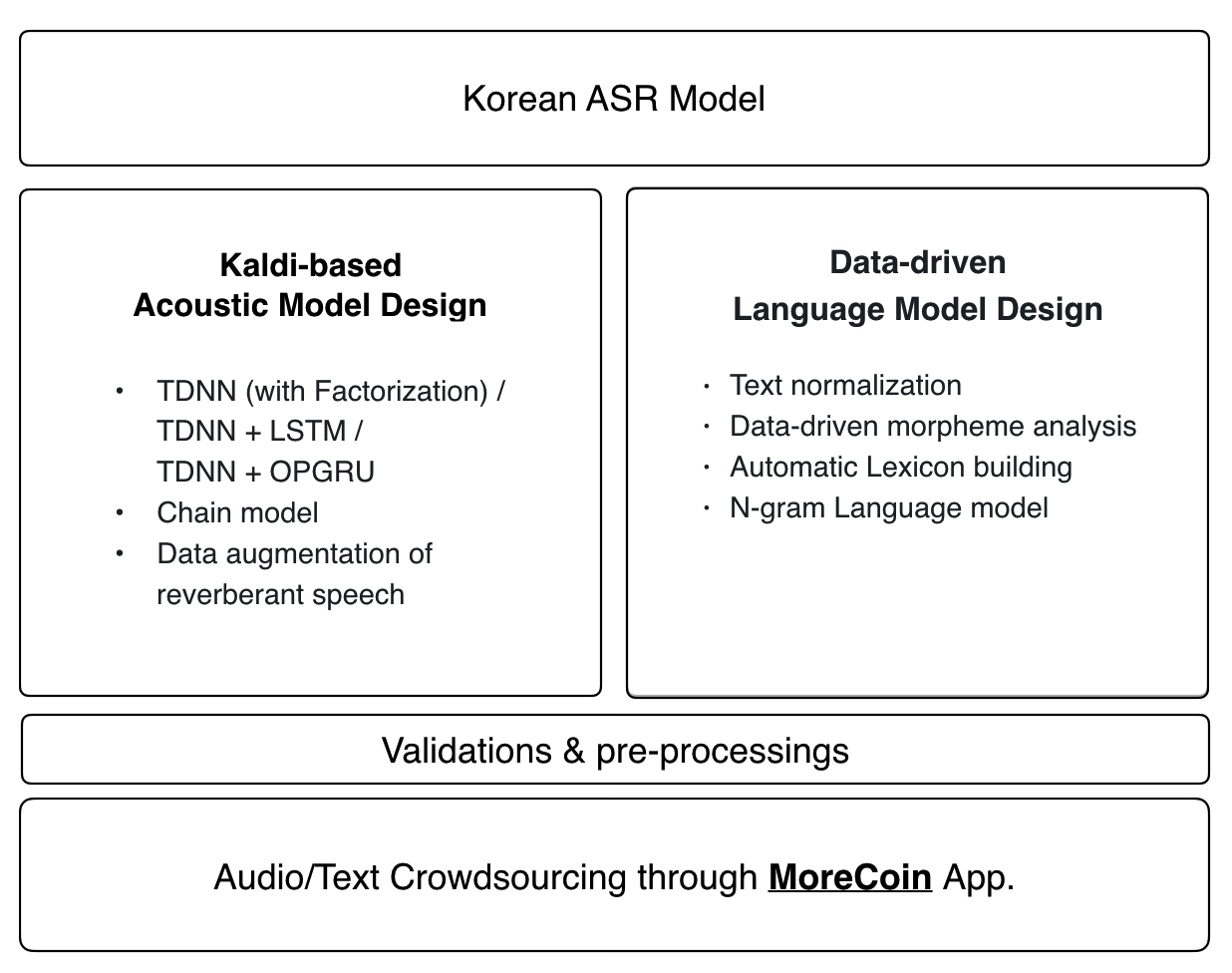
1. Audiodaten
- 16. Juli 2018: 95,7 Stunden (46.347 Äußerungen, 181 Redner, 27.330 Uniq. Sätze)
- 9. April 2018: 76,6 Stunden (35.139 Äußerungen, 137 Sprecher, 16.472 Uniq. Sätze)
- 3. Februar 2018: 51,6 Stunden transkribierte koreanische Audio für Schulungsdaten (22.263 Äußerungen, 105 Lautsprecher, 3000 Sätze)
- Lizenz: [CC von 4.0] (https://creativcommons.org/licenses/by/4.0/)
- Jetzt sind 51,6 Stunden Audio- und LM -Daten bei OpenSLR verfügbar
- Audio Crowdsource von Morecoin wächst. 70 Stunden Open-Source-Audio-Datenbasi
- [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin).
- [Morecoin (IOX)] (https://apps.apple.com/ph/app/morecoin/id1351621392?ign-mpt=uo%3D2)
Wir bieten eine Sprachaufzeichnungs -App [Morecoin (Android)] (https://play.google.com/store/apps/details?id=com.goodatlas.morecoin) an, mit denen Sie an der Erstellung unserer Open -Source -Datenbank koreanischer Trainingsdaten teilnehmen können.
2. Anforderungen
- [Anforderungen] Beschreibung der Pakete, die zum Ausführen des Zeroth -Projekts erforderlich sind: https://github.com/goodatlas/zeroth/wiki/Requirements)
- [Anforderungen 2] Zusätzliche Pakete zum Ausführen von Code für das Sprachmodell und das phonetische Wörterbuch: (https://github.com/goodatlas/zeroth/wiki/Requirement-2)
Akustisches Modell
Das neueste Kaldi -Rezept wird auf das akustische Modell des Zeroths angewendet:
- Tdnn (mit Faktorisierung) / TDNN + LSTM / TDNN + OPGRU
- Kettenmodell
- Datenvergrößerung der nachhallenden Sprache
Sprachmodell und Lexikon
Das Sprachmodell und das phonetische Wörterbuch von Zeroth verwenden einen datengesteuerten End-to-End-Ansatz. Alle Beiträge zu unserer Open -Source -Audio -Datenbank werden automatisch in das neueste Sprachmodell und das phonetische Wörterbuch integriert.
So erstellen Sie ein benutzerdefiniertes Sprachmodell und ein phonetisches Wörterbuch: [s5/data/local/lm/readme.md] (https://github.com/goodatlas/zeroth/blob/master/s5/data/local/lm/readme.md).
Korpus (Korpus)
- Trainingsessätze: 109.037.699
- Testsätze: 12.115.208
- Gesamt: 121.152.907
Phonetisches Wörterbuch
- Einzigartige Wörter: 30.064.143
- Einzigartige Wörter mit der höchsten Frequenz von 98%: 8.069.252
- Einzigartige Morpheme: 465.253
- Größe des phonetischen Wörterbuchs unter Berücksichtigung der Aussprachevielfalt: 686.839
Sprachmodell
- Verwirrungstest 3-Gramm: PPL = 221,2969 (12.115.208 Sätze, 194.940.635 Wörter, 0 OOVs)
- Verwirrungstest 4-Gramm: PPL = 187,2058 (12.115.208 Sätze, 194.940.635 Wörter, 0 OOVs)
Projekt: Zeroth
- 칼디를 이용하여 구축하는 한국어 음성인식 오픈소스 오픈소스
- 이제 칼디 공식 한국어 예제입니다 (https://github.com/kaldi-asr/kaldi/tree/master/egs/zeroth_korean/s5)
- Lizenz: Apache 2.0
- 포럼: https://groups.google.com/forum/#!forum/zeroth-help
Zeroth 프로젝트는 Kaldi Open Source Tool-Kit 을 사용해서 한국어 음성인식기를 구현하는 입니다 입니다. 이 프로젝트는 기업이 ai 를 고객 서비스에 추가하는 데 도움이되는 (주) 아틀라스가이드의 Sprache ai 플랫폼 개발의 일부로서 개발되었습니다 개발되었습니다 개발되었습니다 개발되었습니다 Kaldi Offizielles Rezept 에 한국어 소개하는 것을 시작으로 시작으로 많은 많은 참여를 통해 누구나 수 수 있는 음성인식기를 만들어 나갈 수 있도록 하는 목표로하는 목표로하는 프로젝트입니다 프로젝트입니다 프로젝트입니다 프로젝트입니다 프로젝트입니다 있는 음성인식기를 음성인식기를 만들어 만들어 만들어 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 있는 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 음성인식기를 만들어 만들어 만들어 만들어 만들어 만들어 음성인식기를 음성인식기를 음성인식기를 음성인식기를 만들어 만들어 나갈 수 있도록 하는 것을 목표로하는 프로젝트입니다. 제로스라는 이름은 0-th, 즉 0 번째를 의미합니다. 이름이 의미하는 것처럼 이 프로젝트를 음성인식기를 만들기 위해 필요한 모든 과정을 처음부터 끝까지 함께 해보고 토론할 수 있기를 바랍니다 바랍니다.
Kontakt: Lucas Jo ([email protected])
Besonderer Dank
- GridSpace Inc. 사에서 일하고 계신 Wonkyum Lee 님과의 Co-Work 를 통해 이 프로젝트를 있음을 있음을 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 밝힙니다 님과의 님과의 님과의
Erwähnte Links
- Openslr
- 데이터 사이언스 논문 세미나 @ fastcampus
- 워크샵 @ kmobile
- Interview mit Fastcampus
- 딥러닝-음성인식 camp @ fastcampus
0. Übersicht
1. Audiodaten
- 2018.07.16: 95,7 시간 (46.347 발화, 181 명, 27.330 문장)
- 2018.04.09: 76.6 시간 (35,139 발화, 137 명, 16.472 문장)
- 2018.02.03: 51.6 시간 한국어 학습데이터 (22.263 발화, 105 명, 3000 문장)
- Lizenz: CC von 4.0
- 현재 openslr 에서 51.6 시간 lm 데이터를 받아보실 수 있습니다 있습니다.
- 모어코인을 통한 기부로 오픈소스 오디오가 커지고 있습니다. 4 월에는 1 시간 기부시 70 시간 데이터를 받아보실 수 있습니다. 모어코인앱을 통해 음성을 기부해 주세요.
현재 제로스 프로젝트에는 상기와 같은 음성데이터가 포함되어 있습니다. 공개 음성 db 구축에 참여할 수 있는 음성 녹음 앱 모아코인 (Android) 을 과 모아코인 모아코인 (iOS) 제공하고 있으며 있으며 해당 앱을 통해 데이터를 데이터를 시간 기부해주시면 해당 시점까지 구축된 공개 음성 db 에 접근하여 수 있는 권한을 aws temporärer Anmeldung 형태로 발급해 발급해 드립니다 드립니다 드립니다. 한번 발급된 Anmeldeinformationen 은 12 시간 동안 유효합니다. 더 자세한 내용은 aws-temporary-kredentien 페이지를 확인하시기 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다 바랍니다
2. Anforderungen
- 제로스 프로젝트를 실행하는데 필요한 패키지들에 대한 설명은 설명은 위키 페이지를 참조하시기 바랍니다.
- 언어모델과 발음사전을 구현하는 코드를 직접 실행하기 위해서는 위해서는 위해서는 위해서는 위해서는 위해서는 위해서는 위해서는 위해서는 위해서는 위키 참조하여 추가적인 패키지를 설치하시기 바랍니다 바랍니다.
3.. Akustisches Modell
현재 제로스 프로젝트 음향모델에는 아래와 같은 최신 Kaldi Rezept 가 적용되어 있습니다.
- Tdnn (mit Faktorisierung) / TDNN + LSTM / TDNN + OPGRU
- Kettenmodell
- Datenvergrößerung der nachhallenden Sprache
4. Sprachmodell und Lexikon
제로스 프로젝트에 사용되는 언어모델과 발음사전은 처음부터 끝까지 datengesteuert 방식으로 만들어집니다. 아래는 AWS-Temporary-Credential 을 발급받은 경우 오디오 데이터와 함께 자동으로 받아지는 언어모델과 발음사전의 세부사항입니다 세부사항입니다. 개인적으로 직접 특화된 언어모델과 발음사전을 만들고자 하는 경우에는 세부적인 방법이 방법이
s5/data/local/lm/readme.md 에 기술되어 있으니 참조하시기 바랍니다.
말뭉치 (Korpus)
- 훈련된 문장의 수: 109.037.699
- 테스트 문장의 수: 12.115.208
- 전 체: 121.152.907
발음사전 (Lexikon)
- 고유한 단어의 수: 30.064.143
- 상위 98% 빈도 수를 보이는 고유한 단어의 수: 8.069.252
- Datenantrieb 방식으로 찾은 고유한 형태소의 수: 465.253
- 발음 다양성을 고려한 발음사전의 크기: 686.839
언어모델 (Sprachmodell)
- Verwirrungstest 3-Gramm: PPL = 221,2969 (12.115.208 Sätze, 194.940.635 Wörter, 0 OOVs)
- Verwirrungstest 4-Gramm: PPL = 187,2058 (12.115.208 Sätze, 194.940.635 Wörter, 0 OOVs)


