TopClus
1.0.0
通過預審計的語言模型表示的潛在空間聚類用於主題發現的源代碼,於www 2022發表。
運行代碼需要至少一個GPU。
在運行之前,您需要首先通過輸入以下命令來安裝所需的軟件包(建議使用虛擬環境):
pip3 install -r requirements.txt
您還需要在NLTK中下載以下資源:
import nltk
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('universal_tagset')
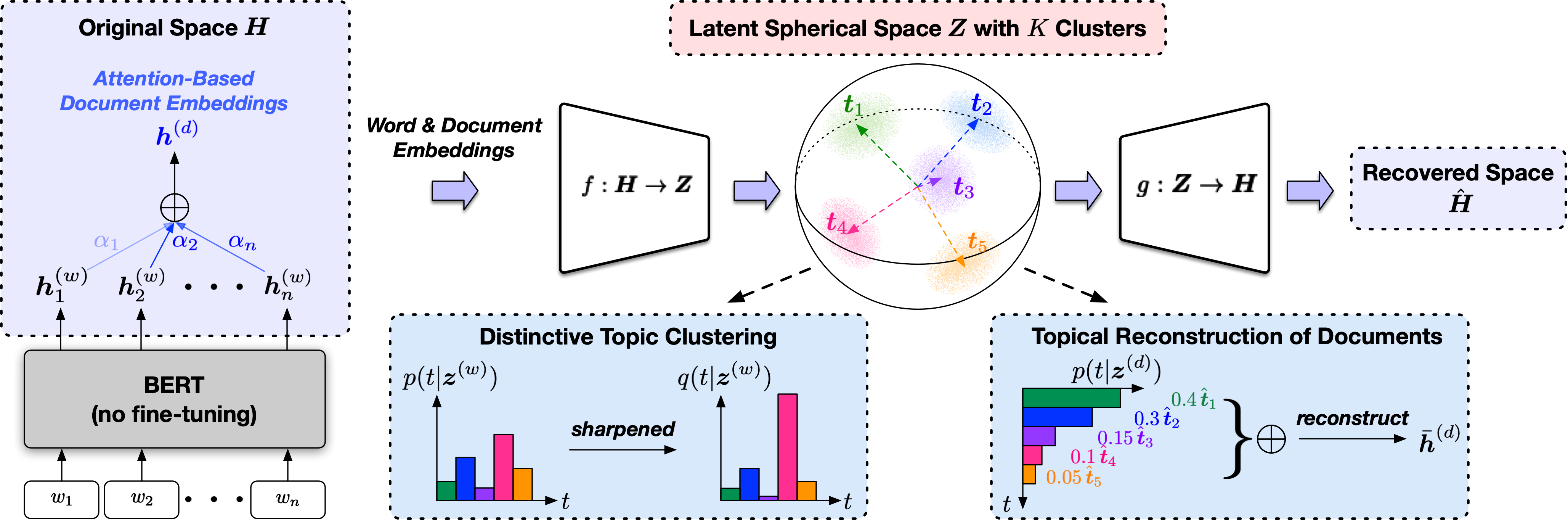
TopClus是一種無監督的主題發現方法,它可以在審前的語言模型表示的潛在球形空間中共同建模單詞,文檔和主題。
輸入腳本是src/trainer.py ,命令行參數的含義將在鍵入時顯示
python src/trainer.py -h
主題發現結果將寫入results_${dataset} 。
我們提供了兩個示例腳本nyt.sh和yelp.sh ,以分別在《紐約時報》和本文中使用的Yelp評論CORPORA上運行主題。您需要首先從datasets/nyt和datasets/yelp下的.tar.gz Tarball文件中提取文本文件。
您可以期望像以下結果一樣獲得結果(主題ID是隨機的):
On New York Times:
Topic 20: months,weeks,days,decades,years,hours,decade,seconds,moments,minutes
Topic 28: weapons,missiles,missile,nuclear,grenades,explosions,explosives,launcher,bombs,bombing
Topic 30: healthcare,medical,medicine,physicians,patients,health,hospitals,bandages,medication,physician
Topic 41: economic,commercially,economy,business,industrial,industry,market,consumer,trade,commerce
Topic 46: senate,senator,congressional,legislators,legislatures,ministry,legislature,minister,ministerial,parliament
Topic 72: government,administration,governments,administrations,mayor,gubernatorial,mayoral,mayors,public,governor
Topic 77: aircraft,airline,airplane,airlines,voyage,airplanes,aviation,planes,spacecraft,flights
Topic 88: baseman,outfielder,baseball,innings,pitchers,softball,inning,basketball,shortstop,pitcher
On Yelp Review:
Topic 1: steamed,roasted,fried,shredded,seasoned,sliced,frozen,baked,canned,glazed
Topic 15: nice,cozy,elegant,polite,charming,relaxing,enjoyable,pleasant,helpful,luxurious
Topic 16: spicy,fresh,creamy,stale,bland,salty,fluffy,greasy,moist,cold
Topic 17: flavor,texture,flavors,taste,quality,smells,tastes,flavour,scent,ingredients
Topic 20: japanese,german,australian,moroccan,russian,greece,italian,greek,asian,
Topic 40: drinks,beers,beer,wine,beverages,alcohol,beverage,vodka,champagne,wines
Topic 55: horrible,terrible,shitty,awful,dreadful,worst,worse,disgusting,filthy,rotten
Topic 75: strawberry,berry,onion,peppers,tomato,onions,potatoes,vegetable,mustard,garlic
潛在文檔嵌入將保存到results_${dataset}/latent_doc_emb.pt可用作聚類算法的功能(例如,k-means)。
如果您有地面真相文檔標籤,則可以通過將文檔標籤文件和保存的潛在文檔嵌入文件傳遞給src/utils.py中的cluster_eval函數來獲得文檔群集評估結果。例如:
from src.utils import TopClusUtils
utils = TopClusUtils()
utils.cluster_eval(label_path="datasets/nyt/label_topic.txt", emb_path="results_nyt/latent_doc_emb.pt")
要在新數據集上執行代碼,您需要
datasets集下創建一個名為your_dataset的目錄。your_dataset下準備一個文本語料庫texts.txt (每行)作為主題發現的目標語料庫。src/trainer.py (默認值通常是良好的起點)。 如果您發現代碼有助於研究,請引用以下論文。
@inproceedings{meng2022topic,
title={Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations},
author={Meng, Yu and Zhang, Yunyi and Huang, Jiaxin and Zhang, Yu and Han, Jiawei},
booktitle={The Web Conference},
year={2022},
}


