TopClus
1.0.0
El código fuente utilizado para el descubrimiento de temas a través de la agrupación espacial latente de representaciones de modelos de lenguaje previos a la aparición , publicado en www 2022.
Se requiere al menos una GPU para ejecutar el código.
Antes de ejecutar, primero debe instalar los paquetes requeridos escribiendo los siguientes comandos (se recomienda usar un entorno virtual)::
pip3 install -r requirements.txt
También debe descargar los siguientes recursos en NLTK:
import nltk
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('universal_tagset')
Topclus es un método de descubrimiento de temas no supervisado que modela conjuntamente palabras, documentos y temas en un espacio esférico latente derivado de representaciones del modelo de lenguaje previamente practicado.
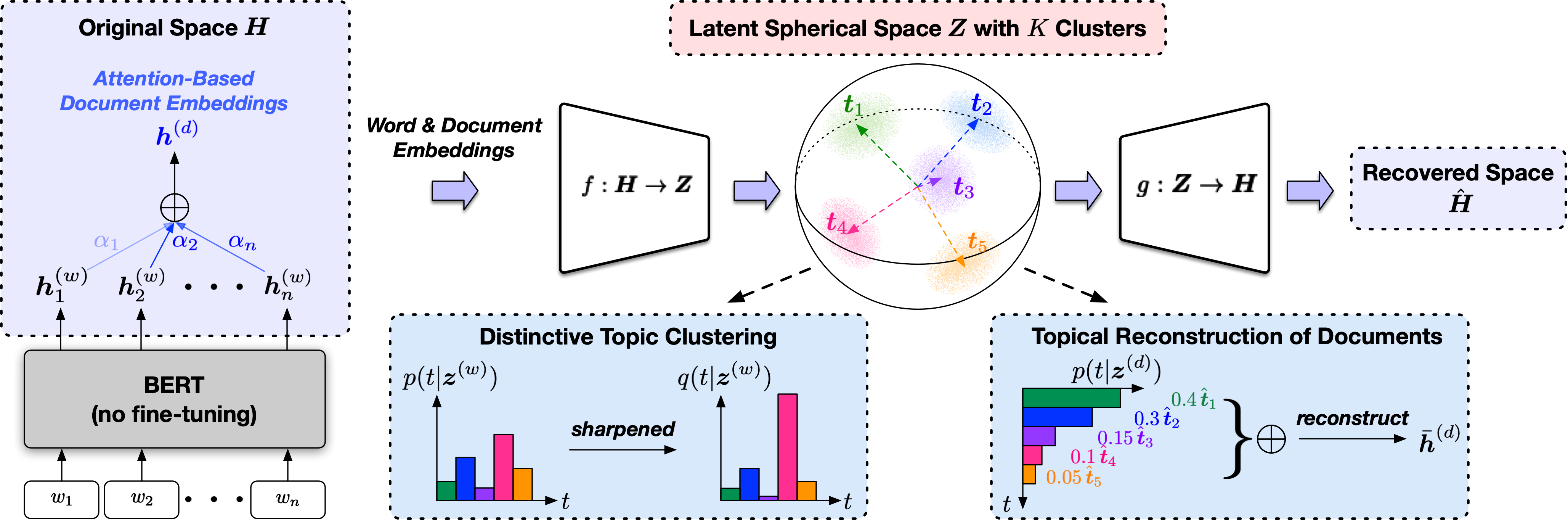
El script de entrada es src/trainer.py y los significados de los argumentos de la línea de comando se mostrarán al escribir
python src/trainer.py -h
Los resultados del descubrimiento del tema se escribirán a results_${dataset} .
Proporcionamos dos scripts de ejemplo nyt.sh y yelp.sh para ejecutar el descubrimiento de temas sobre el New York Times y los corpus de revisión Yelp utilizados en el documento, respectivamente. Primero debe extraer los archivos de texto de los archivos de tarball .tar.gz en datasets/nyt y datasets/yelp .
Puede esperar obtener resultados como los siguientes (las ID de tema son aleatorias):
On New York Times:
Topic 20: months,weeks,days,decades,years,hours,decade,seconds,moments,minutes
Topic 28: weapons,missiles,missile,nuclear,grenades,explosions,explosives,launcher,bombs,bombing
Topic 30: healthcare,medical,medicine,physicians,patients,health,hospitals,bandages,medication,physician
Topic 41: economic,commercially,economy,business,industrial,industry,market,consumer,trade,commerce
Topic 46: senate,senator,congressional,legislators,legislatures,ministry,legislature,minister,ministerial,parliament
Topic 72: government,administration,governments,administrations,mayor,gubernatorial,mayoral,mayors,public,governor
Topic 77: aircraft,airline,airplane,airlines,voyage,airplanes,aviation,planes,spacecraft,flights
Topic 88: baseman,outfielder,baseball,innings,pitchers,softball,inning,basketball,shortstop,pitcher
On Yelp Review:
Topic 1: steamed,roasted,fried,shredded,seasoned,sliced,frozen,baked,canned,glazed
Topic 15: nice,cozy,elegant,polite,charming,relaxing,enjoyable,pleasant,helpful,luxurious
Topic 16: spicy,fresh,creamy,stale,bland,salty,fluffy,greasy,moist,cold
Topic 17: flavor,texture,flavors,taste,quality,smells,tastes,flavour,scent,ingredients
Topic 20: japanese,german,australian,moroccan,russian,greece,italian,greek,asian,
Topic 40: drinks,beers,beer,wine,beverages,alcohol,beverage,vodka,champagne,wines
Topic 55: horrible,terrible,shitty,awful,dreadful,worst,worse,disgusting,filthy,rotten
Topic 75: strawberry,berry,onion,peppers,tomato,onions,potatoes,vegetable,mustard,garlic
Las incrustaciones de documentos latentes se guardarán a results_${dataset}/latent_doc_emb.pt que se pueden usar como características para agrupar algoritmos (por ejemplo, k-means).
Si tiene etiquetas de documentos de verdad en tierra, puede obtener los resultados de la evaluación de la agrupación de documentos al pasar el archivo de etiqueta del documento y el archivo de incrustación de documento latente guardado en la función cluster_eval en src/utils.py . Por ejemplo:
from src.utils import TopClusUtils
utils = TopClusUtils()
utils.cluster_eval(label_path="datasets/nyt/label_topic.txt", emb_path="results_nyt/latent_doc_emb.pt")
Para ejecutar el código en un nuevo conjunto de datos, debe
your_dataset en datasets .texts.txt (un documento por línea) bajo your_dataset como el corpus objetivo para el descubrimiento de temas.src/trainer.py con argumentos de línea de comando apropiados (los valores predeterminados suelen ser buenos puntos de inicio). Cite el siguiente documento si encuentra útil el código para su investigación.
@inproceedings{meng2022topic,
title={Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations},
author={Meng, Yu and Zhang, Yunyi and Huang, Jiaxin and Zhang, Yu and Han, Jiawei},
booktitle={The Web Conference},
year={2022},
}


