TopClus
1.0.0
الكود المصدري المستخدم لاكتشاف الموضوع من خلال تجميع المساحة الكامنة لتمثيلات نموذج اللغة المسبق ، المنشورة في www 2022.
مطلوب وحدة معالجة الرسومات واحدة على الأقل لتشغيل الرمز.
قبل التشغيل ، تحتاج أولاً إلى تثبيت الحزم المطلوبة عن طريق كتابة الأوامر التالية (باستخدام بيئة افتراضية يوصى بها):
pip3 install -r requirements.txt
تحتاج أيضًا إلى تنزيل الموارد التالية في NLTK:
import nltk
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('universal_tagset')
TopClus هي طريقة اكتشاف موضوع غير خاضعة للإشراف تقوم بتصوير الكلمات والمستندات والمواضيع في مساحة كروية كامنة مستمدة من تمثيلات نموذج اللغة المسبق.
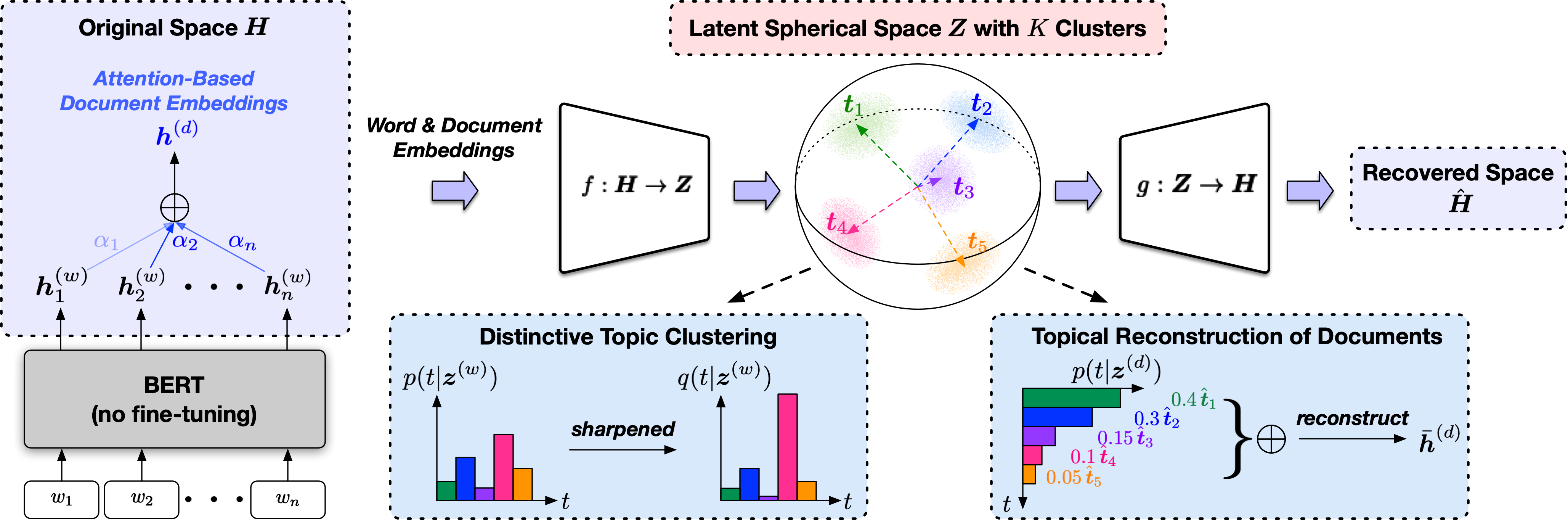
البرنامج النصي للإدخال هو src/trainer.py وسيتم عرض معاني وسيطات سطر الأوامر عند الكتابة
python src/trainer.py -h
سيتم كتابة نتائج اكتشاف الموضوع إلى results_${dataset} .
نحن نقدم اثنين من البرامج النصية مثال nyt.sh و yelp.sh لتشغيل اكتشاف الموضوع في نيويورك تايمز وشركة مراجعة YELP المستخدمة في الورقة ، على التوالي. تحتاج أولاً إلى استخراج الملفات النصية من ملفات Tarball .tar.gz ضمن datasets/nyt ومجموعات datasets/yelp .
يمكن أن تتوقع الحصول على نتائج مثل ما يلي (معرفات الموضوع عشوائي):
On New York Times:
Topic 20: months,weeks,days,decades,years,hours,decade,seconds,moments,minutes
Topic 28: weapons,missiles,missile,nuclear,grenades,explosions,explosives,launcher,bombs,bombing
Topic 30: healthcare,medical,medicine,physicians,patients,health,hospitals,bandages,medication,physician
Topic 41: economic,commercially,economy,business,industrial,industry,market,consumer,trade,commerce
Topic 46: senate,senator,congressional,legislators,legislatures,ministry,legislature,minister,ministerial,parliament
Topic 72: government,administration,governments,administrations,mayor,gubernatorial,mayoral,mayors,public,governor
Topic 77: aircraft,airline,airplane,airlines,voyage,airplanes,aviation,planes,spacecraft,flights
Topic 88: baseman,outfielder,baseball,innings,pitchers,softball,inning,basketball,shortstop,pitcher
On Yelp Review:
Topic 1: steamed,roasted,fried,shredded,seasoned,sliced,frozen,baked,canned,glazed
Topic 15: nice,cozy,elegant,polite,charming,relaxing,enjoyable,pleasant,helpful,luxurious
Topic 16: spicy,fresh,creamy,stale,bland,salty,fluffy,greasy,moist,cold
Topic 17: flavor,texture,flavors,taste,quality,smells,tastes,flavour,scent,ingredients
Topic 20: japanese,german,australian,moroccan,russian,greece,italian,greek,asian,
Topic 40: drinks,beers,beer,wine,beverages,alcohol,beverage,vodka,champagne,wines
Topic 55: horrible,terrible,shitty,awful,dreadful,worst,worse,disgusting,filthy,rotten
Topic 75: strawberry,berry,onion,peppers,tomato,onions,potatoes,vegetable,mustard,garlic
سيتم حفظ تضمينات المستند الكامن على results_${dataset}/latent_doc_emb.pt التي يمكن استخدامها كميزات لخوارزميات التجميع (على سبيل المثال ، K-means).
إذا كان لديك ملصقات مستندات الحقيقة ، فيمكنك الحصول على نتائج تقييم مجموعات المستندات عن طريق تمرير ملف تسمية المستند وملف تضمين المستند الكامن المحفوظ إلى وظيفة cluster_eval في src/utils.py . على سبيل المثال:
from src.utils import TopClusUtils
utils = TopClusUtils()
utils.cluster_eval(label_path="datasets/nyt/label_topic.txt", emb_path="results_nyt/latent_doc_emb.pt")
لتنفيذ الرمز على مجموعة بيانات جديدة ، تحتاج إلى ذلك
your_dataset ضمن datasets .texts.txt نصية نصية your_datasetsrc/trainer.py مع وسيطات سطر الأوامر المناسبة (عادة ما تكون القيم الافتراضية نقاط بداية جيدة). يرجى الاستشهاد بالورقة التالية إذا وجدت الرمز مفيدًا لبحثك.
@inproceedings{meng2022topic,
title={Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations},
author={Meng, Yu and Zhang, Yunyi and Huang, Jiaxin and Zhang, Yu and Han, Jiawei},
booktitle={The Web Conference},
year={2022},
}


