TopClus
1.0.0
ซอร์สโค้ดที่ใช้สำหรับ การค้นพบหัวข้อผ่านการจัดกลุ่มพื้นที่แฝงของการแสดงรูปแบบภาษาที่ผ่านการฝึกอบรม เผยแพร่ใน www 2022
ต้องใช้ GPU อย่างน้อยหนึ่งตัวในการเรียกใช้รหัส
ก่อนที่จะทำงานคุณต้องติดตั้งแพ็คเกจที่จำเป็นก่อนโดยพิมพ์คำสั่งต่อไปนี้ (โดยใช้สภาพแวดล้อมเสมือนจริง):
pip3 install -r requirements.txt
คุณต้องดาวน์โหลดทรัพยากรต่อไปนี้ใน NLTK:
import nltk
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('universal_tagset')
TopClus เป็นวิธีการค้นพบหัวข้อที่ไม่ได้รับการดูแลซึ่งร่วมกันแบบจำลองคำเอกสารและหัวข้อในพื้นที่ทรงกลมแฝงที่ได้มาจากการแสดงแบบจำลองภาษาที่ผ่านการฝึกอบรม
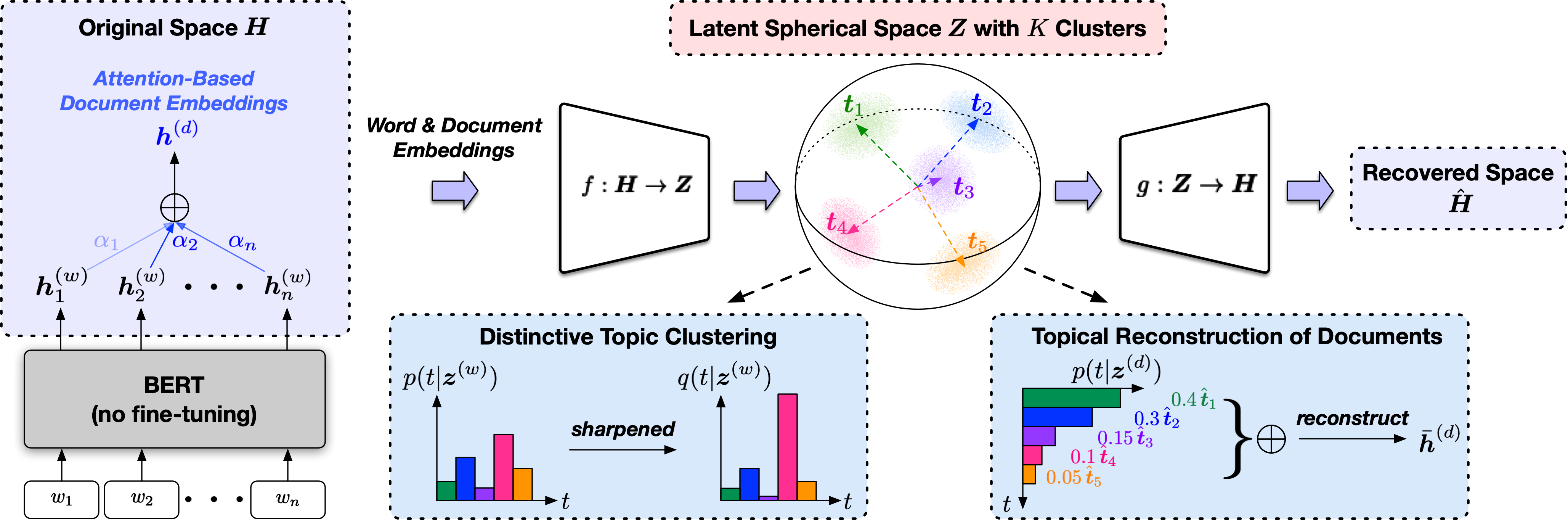
สคริปต์รายการคือ src/trainer.py และความหมายของอาร์กิวเมนต์บรรทัดคำสั่งจะปรากฏขึ้นเมื่อพิมพ์
python src/trainer.py -h
ผลการค้นหาหัวข้อจะถูกเขียนไปยัง results_${dataset}
เราให้บริการสคริปต์สองตัวอย่าง nyt.sh และ yelp.sh สำหรับการค้นพบหัวข้อใน New York Times และ Yelp Review Corpora ที่ใช้ในกระดาษตามลำดับ คุณต้องแยกไฟล์ข้อความออกจากไฟล์ .tar.gz tarball ภายใต้ datasets/nyt และ datasets/yelp
คุณสามารถคาดหวังว่าจะได้รับผลลัพธ์ดังต่อไปนี้ (ID หัวข้อเป็นแบบสุ่ม):
On New York Times:
Topic 20: months,weeks,days,decades,years,hours,decade,seconds,moments,minutes
Topic 28: weapons,missiles,missile,nuclear,grenades,explosions,explosives,launcher,bombs,bombing
Topic 30: healthcare,medical,medicine,physicians,patients,health,hospitals,bandages,medication,physician
Topic 41: economic,commercially,economy,business,industrial,industry,market,consumer,trade,commerce
Topic 46: senate,senator,congressional,legislators,legislatures,ministry,legislature,minister,ministerial,parliament
Topic 72: government,administration,governments,administrations,mayor,gubernatorial,mayoral,mayors,public,governor
Topic 77: aircraft,airline,airplane,airlines,voyage,airplanes,aviation,planes,spacecraft,flights
Topic 88: baseman,outfielder,baseball,innings,pitchers,softball,inning,basketball,shortstop,pitcher
On Yelp Review:
Topic 1: steamed,roasted,fried,shredded,seasoned,sliced,frozen,baked,canned,glazed
Topic 15: nice,cozy,elegant,polite,charming,relaxing,enjoyable,pleasant,helpful,luxurious
Topic 16: spicy,fresh,creamy,stale,bland,salty,fluffy,greasy,moist,cold
Topic 17: flavor,texture,flavors,taste,quality,smells,tastes,flavour,scent,ingredients
Topic 20: japanese,german,australian,moroccan,russian,greece,italian,greek,asian,
Topic 40: drinks,beers,beer,wine,beverages,alcohol,beverage,vodka,champagne,wines
Topic 55: horrible,terrible,shitty,awful,dreadful,worst,worse,disgusting,filthy,rotten
Topic 75: strawberry,berry,onion,peppers,tomato,onions,potatoes,vegetable,mustard,garlic
การฝังเอกสารแฝงจะถูกบันทึกลงใน results_${dataset}/latent_doc_emb.pt ซึ่งสามารถใช้เป็นคุณสมบัติในการจัดกลุ่มอัลกอริทึม (เช่น k-mean)
หากคุณมีฉลากเอกสารความจริงพื้นฐานคุณสามารถรับผลการประเมินผลการจัดกลุ่มเอกสารโดยผ่านไฟล์ฉลากเอกสารและไฟล์ฝังเอกสารแฝงที่บันทึกไว้ในฟังก์ชัน cluster_eval ใน src/utils.py ตัวอย่างเช่น:
from src.utils import TopClusUtils
utils = TopClusUtils()
utils.cluster_eval(label_path="datasets/nyt/label_topic.txt", emb_path="results_nyt/latent_doc_emb.pt")
ในการเรียกใช้รหัสในชุดข้อมูลใหม่คุณต้อง
your_dataset ภายใต้ datasetstexts.txt (หนึ่งเอกสารต่อบรรทัด) ภายใต้ your_dataset เป็นคลังเป้าหมายสำหรับการค้นพบหัวข้อsrc/trainer.py ด้วยอาร์กิวเมนต์บรรทัดคำสั่งที่เหมาะสม (ค่าเริ่มต้นมักจะเป็นจุดเริ่มต้นที่ดี) โปรดอ้างอิงกระดาษต่อไปนี้หากคุณพบว่ารหัสที่เป็นประโยชน์สำหรับการวิจัยของคุณ
@inproceedings{meng2022topic,
title={Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations},
author={Meng, Yu and Zhang, Yunyi and Huang, Jiaxin and Zhang, Yu and Han, Jiawei},
booktitle={The Web Conference},
year={2022},
}


