TopClus
1.0.0
Le code source utilisé pour la découverte de sujets via le regroupement d'espace latente des représentations de modèles de langage prétrait , publié dans WWW 2022.
Au moins un GPU est nécessaire pour exécuter le code.
Avant d'exécuter, vous devez d'abord installer les packages requis en tapant les commandes suivantes (l'utilisation d'un environnement virtuel est recommandée):
pip3 install -r requirements.txt
Vous devez également télécharger les ressources suivantes dans NLTK:
import nltk
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('universal_tagset')
Topclus est une méthode de découverte de sujets non supervisée qui modélise conjointement les mots, les documents et les sujets dans un espace sphérique latent dérivé des représentations de modèle de langage pré-entraîné.
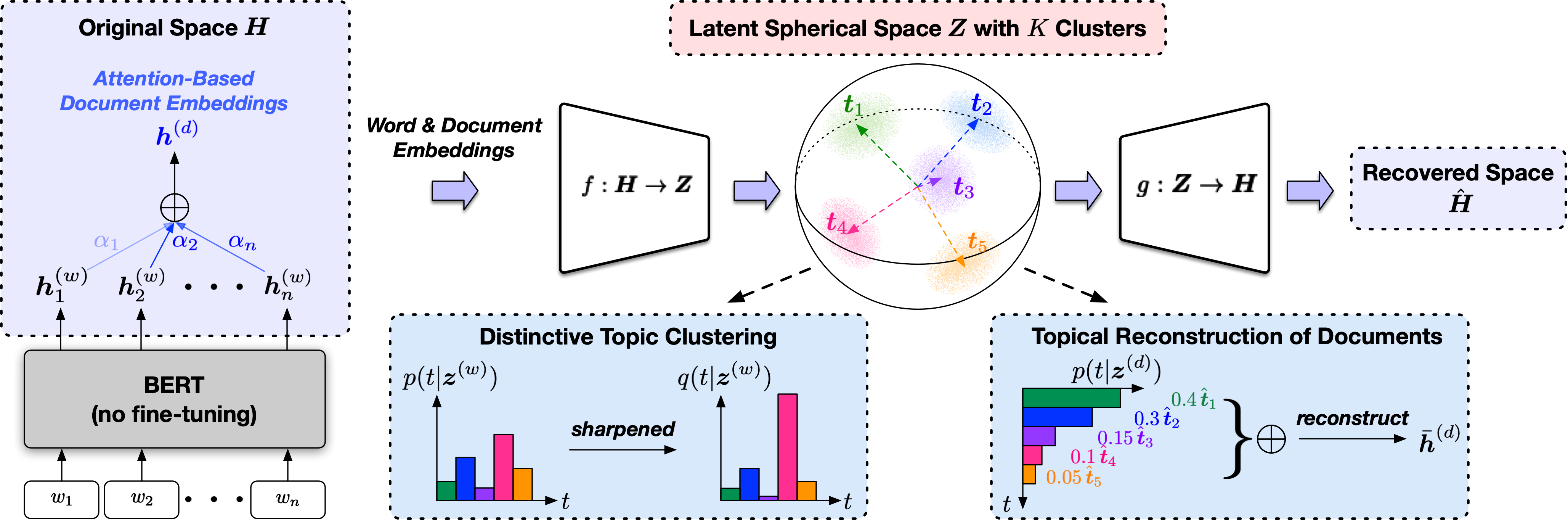
Le script d'entrée est src/trainer.py et les significations des arguments de ligne de commande seront affichées lors de la saisie
python src/trainer.py -h
Les résultats de la découverte de sujets seront écrits sur results_${dataset} .
Nous fournissons deux exemples de scripts nyt.sh et yelp.sh pour exécuter la découverte du sujet sur le New York Times et les corpus de revue Yelp utilisés dans le document, respectivement. Vous devez d'abord extraire les fichiers texte des fichiers tarball .tar.gz sous datasets/nyt et datasets/yelp .
Vous pouvez vous attendre à obtenir des résultats comme les suivants (les identifiants de sujet sont aléatoires):
On New York Times:
Topic 20: months,weeks,days,decades,years,hours,decade,seconds,moments,minutes
Topic 28: weapons,missiles,missile,nuclear,grenades,explosions,explosives,launcher,bombs,bombing
Topic 30: healthcare,medical,medicine,physicians,patients,health,hospitals,bandages,medication,physician
Topic 41: economic,commercially,economy,business,industrial,industry,market,consumer,trade,commerce
Topic 46: senate,senator,congressional,legislators,legislatures,ministry,legislature,minister,ministerial,parliament
Topic 72: government,administration,governments,administrations,mayor,gubernatorial,mayoral,mayors,public,governor
Topic 77: aircraft,airline,airplane,airlines,voyage,airplanes,aviation,planes,spacecraft,flights
Topic 88: baseman,outfielder,baseball,innings,pitchers,softball,inning,basketball,shortstop,pitcher
On Yelp Review:
Topic 1: steamed,roasted,fried,shredded,seasoned,sliced,frozen,baked,canned,glazed
Topic 15: nice,cozy,elegant,polite,charming,relaxing,enjoyable,pleasant,helpful,luxurious
Topic 16: spicy,fresh,creamy,stale,bland,salty,fluffy,greasy,moist,cold
Topic 17: flavor,texture,flavors,taste,quality,smells,tastes,flavour,scent,ingredients
Topic 20: japanese,german,australian,moroccan,russian,greece,italian,greek,asian,
Topic 40: drinks,beers,beer,wine,beverages,alcohol,beverage,vodka,champagne,wines
Topic 55: horrible,terrible,shitty,awful,dreadful,worst,worse,disgusting,filthy,rotten
Topic 75: strawberry,berry,onion,peppers,tomato,onions,potatoes,vegetable,mustard,garlic
Le document latent incorpore sera enregistré sur results_${dataset}/latent_doc_emb.pt qui peut être utilisé comme fonctionnalités pour regrouper des algorithmes (par exemple, k-means).
Si vous avez des étiquettes de documents de vérité au sol, vous pouvez obtenir les résultats de l'évaluation du clustering de documents en passant le fichier d'étiquette de document et le fichier d'intégration du document latent enregistré à la fonction cluster_eval dans src/utils.py . Par exemple:
from src.utils import TopClusUtils
utils = TopClusUtils()
utils.cluster_eval(label_path="datasets/nyt/label_topic.txt", emb_path="results_nyt/latent_doc_emb.pt")
Pour exécuter le code sur un nouvel ensemble de données, vous devez
your_dataset sous datasets .texts.txt (un document par ligne) sous your_dataset comme corpus cible pour la découverte de la rubrique.src/trainer.py avec des arguments de ligne de commande appropriés (les valeurs par défaut sont généralement de bons points de début). Veuillez citer l'article suivant si vous trouvez le code utile pour vos recherches.
@inproceedings{meng2022topic,
title={Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations},
author={Meng, Yu and Zhang, Yunyi and Huang, Jiaxin and Zhang, Yu and Han, Jiawei},
booktitle={The Web Conference},
year={2022},
}


