TopClus
1.0.0
www 2022で公開されている、事前に処理された言語モデル表現の潜在的なスペースクラスタリングによるトピック発見に使用されるソースコード。
コードを実行するには、少なくとも1つのGPUが必要です。
実行する前に、次のコマンドを入力することにより、最初に必要なパッケージをインストールする必要があります(仮想環境を使用することをお勧めします):
pip3 install -r requirements.txt
また、NLTKに次のリソースをダウンロードする必要があります。
import nltk
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('universal_tagset')
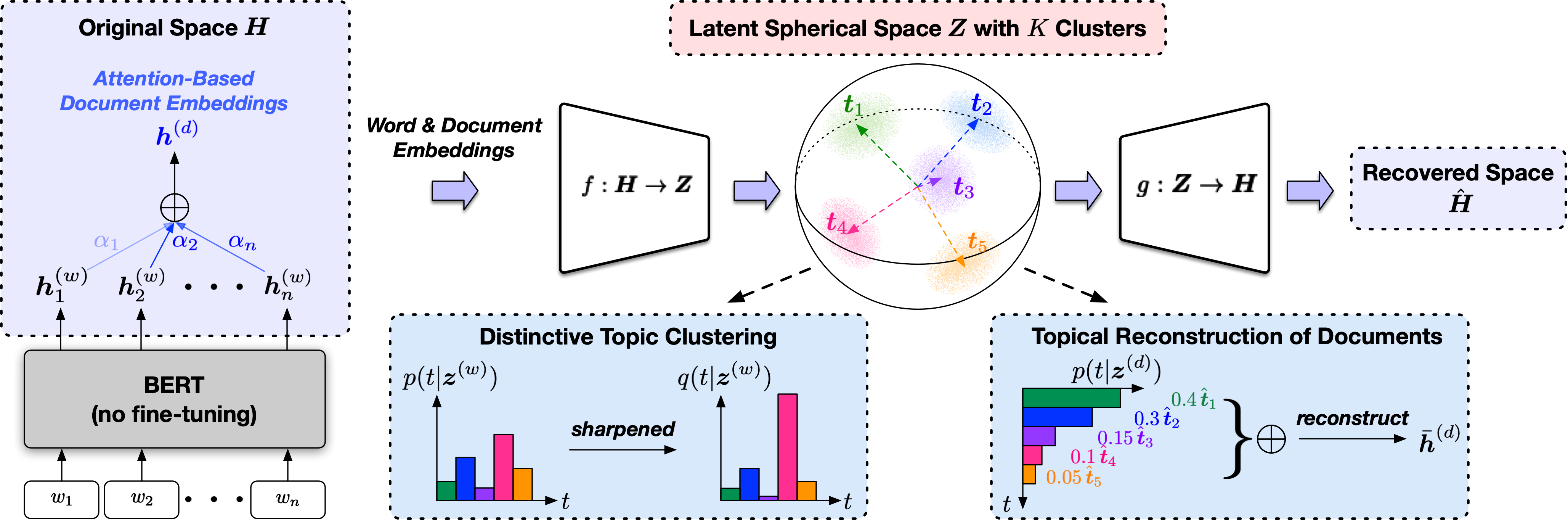
Topclusは、先立った言語モデルの表現から派生した潜在的な球面空間で単語、文書、トピックを共同でモデル化する監視されていないトピック発見方法です。
エントリスクリプトはsrc/trainer.pyであり、コマンドラインの引数の意味が入力時に表示されます
python src/trainer.py -h
トピックの発見結果はresults_${dataset}に書き込まれます。
New York TimesとYelp Review Corporaでそれぞれトピック発見を実行するための2つの例のスクリプトnyt.shとyelp.shを提供します。最初に、 datasets/nytおよびdatasets/yelpの下で.tar.gz Tarballファイルからテキストファイルを抽出する必要があります。
次のような結果を得ることが期待できます(トピックIDはランダムです):
On New York Times:
Topic 20: months,weeks,days,decades,years,hours,decade,seconds,moments,minutes
Topic 28: weapons,missiles,missile,nuclear,grenades,explosions,explosives,launcher,bombs,bombing
Topic 30: healthcare,medical,medicine,physicians,patients,health,hospitals,bandages,medication,physician
Topic 41: economic,commercially,economy,business,industrial,industry,market,consumer,trade,commerce
Topic 46: senate,senator,congressional,legislators,legislatures,ministry,legislature,minister,ministerial,parliament
Topic 72: government,administration,governments,administrations,mayor,gubernatorial,mayoral,mayors,public,governor
Topic 77: aircraft,airline,airplane,airlines,voyage,airplanes,aviation,planes,spacecraft,flights
Topic 88: baseman,outfielder,baseball,innings,pitchers,softball,inning,basketball,shortstop,pitcher
On Yelp Review:
Topic 1: steamed,roasted,fried,shredded,seasoned,sliced,frozen,baked,canned,glazed
Topic 15: nice,cozy,elegant,polite,charming,relaxing,enjoyable,pleasant,helpful,luxurious
Topic 16: spicy,fresh,creamy,stale,bland,salty,fluffy,greasy,moist,cold
Topic 17: flavor,texture,flavors,taste,quality,smells,tastes,flavour,scent,ingredients
Topic 20: japanese,german,australian,moroccan,russian,greece,italian,greek,asian,
Topic 40: drinks,beers,beer,wine,beverages,alcohol,beverage,vodka,champagne,wines
Topic 55: horrible,terrible,shitty,awful,dreadful,worst,worse,disgusting,filthy,rotten
Topic 75: strawberry,berry,onion,peppers,tomato,onions,potatoes,vegetable,mustard,garlic
潜在ドキュメントの埋め込みは、アルゴリズムのクラスタリング(k-means)のクラスタリングに機能として使用できるresults_${dataset}/latent_doc_emb.ptに保存されます。
グラウンドトゥルースドキュメントラベルがある場合は、ドキュメントラベルファイルと保存された潜在ドキュメント埋め込みファイルをsrc/utils.pyのcluster_eval関数に渡すことにより、ドキュメントクラスタリング評価結果を取得できます。例えば:
from src.utils import TopClusUtils
utils = TopClusUtils()
utils.cluster_eval(label_path="datasets/nyt/label_topic.txt", emb_path="results_nyt/latent_doc_emb.pt")
新しいデータセットでコードを実行するには、
datasetsの下にyour_datasetという名前のディレクトリを作成します。your_datasetの下にあるText Corpus texts.txt (1行ごとに1つのドキュメント)を準備します。src/trainer.pyを実行します(通常、デフォルト値は良い開始点です)。 調査に役立つコードを見つけた場合は、次の論文を引用してください。
@inproceedings{meng2022topic,
title={Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations},
author={Meng, Yu and Zhang, Yunyi and Huang, Jiaxin and Zhang, Yu and Han, Jiawei},
booktitle={The Web Conference},
year={2022},
}


