TopClus
1.0.0
Der Quellcode, der für die Themenentdeckung verwendet wird, über das latente Weltraumclustering von vorbereiteten Sprachmodelldarstellungen , veröffentlicht in www 2022.
Mindestens eine GPU muss den Code ausführen.
Vor dem Ausführen müssen Sie zuerst die erforderlichen Pakete installieren, indem Sie die folgenden Befehle eingeben (mit einer virtuellen Umgebung wird empfohlen):
pip3 install -r requirements.txt
Sie müssen auch die folgenden Ressourcen in NLTK herunterladen:
import nltk
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('universal_tagset')
Topclus ist eine unbeaufsichtigte Themenentdeckungsmethode, die gemeinsam Wörter, Dokumente und Themen in einem latenten kugelförmigen Raum modelliert.
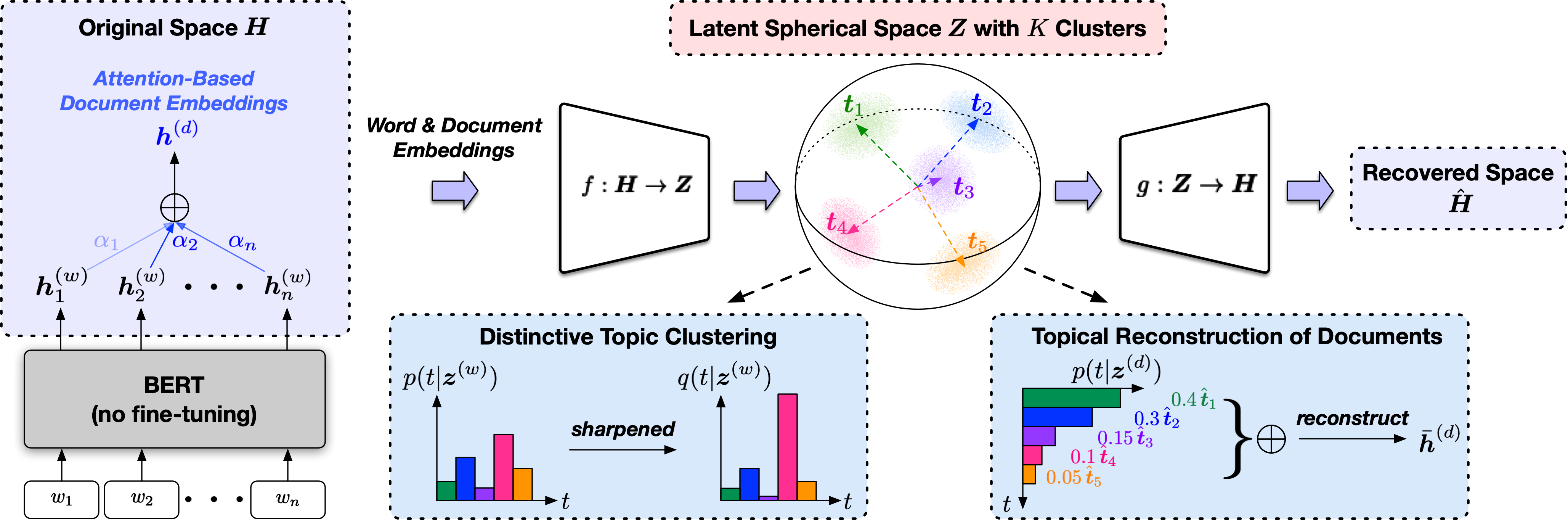
Das Eintragskript ist src/trainer.py und die Bedeutungen der Befehlszeilenargumente werden beim Tippen angezeigt
python src/trainer.py -h
Die Themenerfassungsergebnisse werden in results_${dataset} geschrieben.
Wir bieten zwei Beispiel -Skripte nyt.sh und yelp.sh für die Ausführung von Themenentdeckungen in der New York Times und in der in der Arbeit verwendeten Yelp Review Corpora. Sie müssen zuerst die Textdateien aus den Tarballdateien .tar.gz unter datasets/nyt und datasets/yelp extrahieren.
Sie könnten erwarten, Ergebnisse wie die folgenden zu erhalten (die Themen -IDs sind zufällig):
On New York Times:
Topic 20: months,weeks,days,decades,years,hours,decade,seconds,moments,minutes
Topic 28: weapons,missiles,missile,nuclear,grenades,explosions,explosives,launcher,bombs,bombing
Topic 30: healthcare,medical,medicine,physicians,patients,health,hospitals,bandages,medication,physician
Topic 41: economic,commercially,economy,business,industrial,industry,market,consumer,trade,commerce
Topic 46: senate,senator,congressional,legislators,legislatures,ministry,legislature,minister,ministerial,parliament
Topic 72: government,administration,governments,administrations,mayor,gubernatorial,mayoral,mayors,public,governor
Topic 77: aircraft,airline,airplane,airlines,voyage,airplanes,aviation,planes,spacecraft,flights
Topic 88: baseman,outfielder,baseball,innings,pitchers,softball,inning,basketball,shortstop,pitcher
On Yelp Review:
Topic 1: steamed,roasted,fried,shredded,seasoned,sliced,frozen,baked,canned,glazed
Topic 15: nice,cozy,elegant,polite,charming,relaxing,enjoyable,pleasant,helpful,luxurious
Topic 16: spicy,fresh,creamy,stale,bland,salty,fluffy,greasy,moist,cold
Topic 17: flavor,texture,flavors,taste,quality,smells,tastes,flavour,scent,ingredients
Topic 20: japanese,german,australian,moroccan,russian,greece,italian,greek,asian,
Topic 40: drinks,beers,beer,wine,beverages,alcohol,beverage,vodka,champagne,wines
Topic 55: horrible,terrible,shitty,awful,dreadful,worst,worse,disgusting,filthy,rotten
Topic 75: strawberry,berry,onion,peppers,tomato,onions,potatoes,vegetable,mustard,garlic
Das latente Dokument-Einbettungsdings werden in results_${dataset}/latent_doc_emb.pt gespeichert.
Wenn Sie anhand von Boden -Wahrheitsdokumenten -Bezeichnungen verfügen, können Sie die Ergebnisse der Dokumentenclustering -Bewertung erhalten, indem Sie die Dokument -Label -Datei und die gespeicherte Latent -Dokument -Einbettungsdatei an die Funktion cluster_eval in src/utils.py übergeben. Zum Beispiel:
from src.utils import TopClusUtils
utils = TopClusUtils()
utils.cluster_eval(label_path="datasets/nyt/label_topic.txt", emb_path="results_nyt/latent_doc_emb.pt")
Um den Code in einem neuen Datensatz auszuführen, müssen Sie
your_dataset unter datasets .texts.txt (ein Dokument pro Zeile) unter your_dataset als Zielkorpus für die Themenentdeckung vor.src/trainer.py mit entsprechenden Befehlszeilenargumenten aus (die Standardwerte sind normalerweise gute Startpunkte). Bitte zitieren Sie das folgende Papier, wenn Sie den Code für Ihre Recherche hilfreich finden.
@inproceedings{meng2022topic,
title={Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations},
author={Meng, Yu and Zhang, Yunyi and Huang, Jiaxin and Zhang, Yu and Han, Jiawei},
booktitle={The Web Conference},
year={2022},
}


