TopClus
1.0.0
Kode sumber yang digunakan untuk penemuan topik melalui pengelompokan ruang laten representasi model bahasa pretrained , yang diterbitkan dalam www 2022.
Setidaknya satu GPU diperlukan untuk menjalankan kode.
Sebelum berjalan, Anda harus terlebih dahulu menginstal paket yang diperlukan dengan mengetik perintah berikut (menggunakan lingkungan virtual disarankan):
pip3 install -r requirements.txt
Anda juga perlu mengunduh sumber daya berikut di NLTK:
import nltk
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('universal_tagset')
TopClus adalah metode penemuan topik yang tidak diawasi yang bersama -sama memodelkan kata -kata, dokumen, dan topik dalam ruang bola laten yang berasal dari representasi model bahasa pretrain.
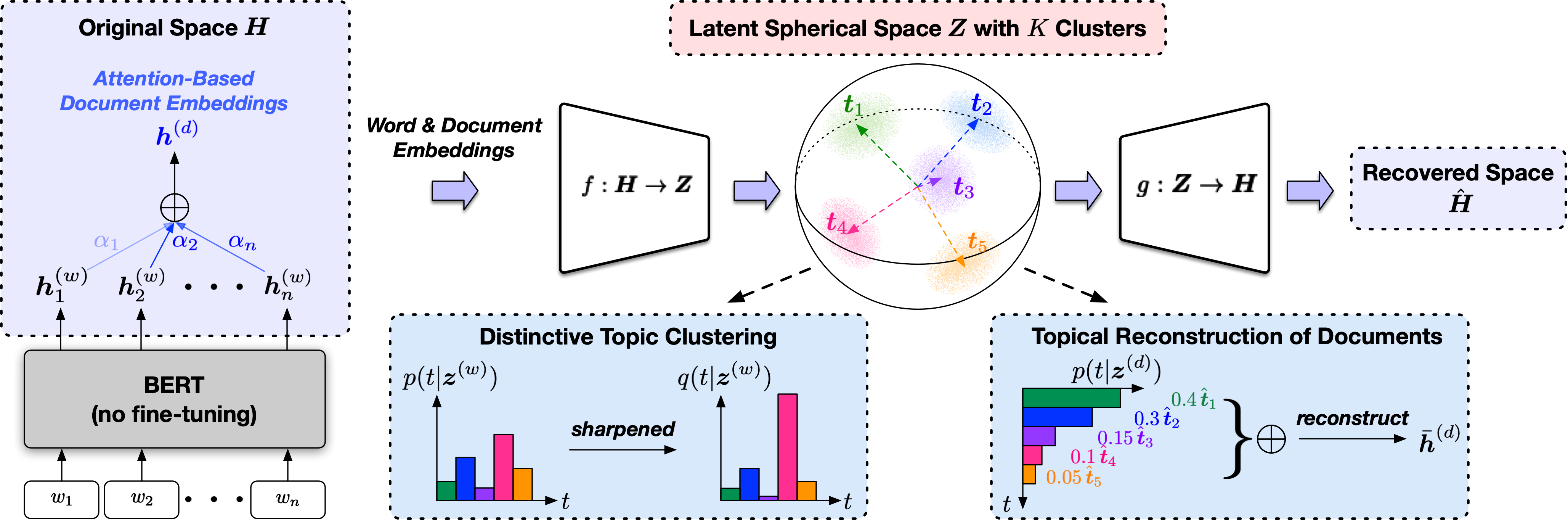
Skrip entri adalah src/trainer.py dan makna argumen baris perintah akan ditampilkan saat mengetik
python src/trainer.py -h
Hasil penemuan topik akan ditulis ke results_${dataset} .
Kami memberikan dua contoh skrip nyt.sh dan yelp.sh untuk menjalankan Topic Discovery di New York Times dan Yelp Review Corpora yang digunakan dalam makalah, masing -masing. Anda harus terlebih dahulu mengekstrak file teks dari file tarball .tar.gz di bawah datasets/nyt dan datasets/yelp .
Anda bisa berharap mendapatkan hasil seperti yang berikut (ID topik itu acak):
On New York Times:
Topic 20: months,weeks,days,decades,years,hours,decade,seconds,moments,minutes
Topic 28: weapons,missiles,missile,nuclear,grenades,explosions,explosives,launcher,bombs,bombing
Topic 30: healthcare,medical,medicine,physicians,patients,health,hospitals,bandages,medication,physician
Topic 41: economic,commercially,economy,business,industrial,industry,market,consumer,trade,commerce
Topic 46: senate,senator,congressional,legislators,legislatures,ministry,legislature,minister,ministerial,parliament
Topic 72: government,administration,governments,administrations,mayor,gubernatorial,mayoral,mayors,public,governor
Topic 77: aircraft,airline,airplane,airlines,voyage,airplanes,aviation,planes,spacecraft,flights
Topic 88: baseman,outfielder,baseball,innings,pitchers,softball,inning,basketball,shortstop,pitcher
On Yelp Review:
Topic 1: steamed,roasted,fried,shredded,seasoned,sliced,frozen,baked,canned,glazed
Topic 15: nice,cozy,elegant,polite,charming,relaxing,enjoyable,pleasant,helpful,luxurious
Topic 16: spicy,fresh,creamy,stale,bland,salty,fluffy,greasy,moist,cold
Topic 17: flavor,texture,flavors,taste,quality,smells,tastes,flavour,scent,ingredients
Topic 20: japanese,german,australian,moroccan,russian,greece,italian,greek,asian,
Topic 40: drinks,beers,beer,wine,beverages,alcohol,beverage,vodka,champagne,wines
Topic 55: horrible,terrible,shitty,awful,dreadful,worst,worse,disgusting,filthy,rotten
Topic 75: strawberry,berry,onion,peppers,tomato,onions,potatoes,vegetable,mustard,garlic
Embeddings dokumen laten akan disimpan ke results_${dataset}/latent_doc_emb.pt yang dapat digunakan sebagai fitur untuk algoritma pengelompokan (misalnya, k-means).
Jika Anda memiliki label dokumen Ground Truth, Anda dapat memperoleh hasil evaluasi pengelompokan dokumen dengan menyerahkan file label dokumen dan file embedding dokumen laten yang disimpan ke fungsi cluster_eval di src/utils.py . Misalnya:
from src.utils import TopClusUtils
utils = TopClusUtils()
utils.cluster_eval(label_path="datasets/nyt/label_topic.txt", emb_path="results_nyt/latent_doc_emb.pt")
Untuk menjalankan kode pada dataset baru, Anda perlu
your_dataset di bawah datasets .texts.txt (satu dokumen per baris) di bawah your_dataset sebagai korpus target untuk penemuan topik.src/trainer.py dengan argumen baris perintah yang sesuai (nilai default biasanya poin awal yang baik). Harap kutip makalah berikut jika Anda menemukan kode bermanfaat untuk penelitian Anda.
@inproceedings{meng2022topic,
title={Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations},
author={Meng, Yu and Zhang, Yunyi and Huang, Jiaxin and Zhang, Yu and Han, Jiawei},
booktitle={The Web Conference},
year={2022},
}


