HiFT
1.0.0
此存儲庫包含Python軟件包HiFT的源代碼,以及如何將其與Pytorch型號集成在一起的幾個示例,例如擁抱面孔的模型。我們目前僅支持Pytorch。有關· HiFT的詳細說明,請參見我們的論文。 HiFT支持在混合精度下為24G GPU內存設備的7B型號的FPFT,而無需使用任何存儲器保存技術和各種優化器,包括AdamW , AdaGrad , SGD等。
hift:分層完整參數微調策略
Yongkang Liu,Yiqun Zhang,Qian Li,Tong Liu,Shi Feng,Daling Wang,Yifei Zhang,HinrichSchütze
論文:https://arxiv.org/abs/2401.15207
26/1/2024 :發布第一個版本的HiFT手稿
25/2/2024 :發布第二版的HiFT手稿和源代碼
1/5/2024 :更新了LoRA的HIFT支持
10/5/2024 :調整BitSandBytes提供的優化器
13/5/2024*:Adapt Adalora , LoRA , IA3 , P_tuning , Prefix_tuning , Prompt_tuning peft方法。
此存儲庫中有幾個目錄:
hift的源代碼,需要安裝它以運行我們提供的示例;HiFT的NER , QA , classification , text generation , instruction fine-tuning和pre-training示例實現。指令對A6000(48G)上的微調7B模型,實驗結果表明,HIFT支持的最大序列長度為2800。在此限制之外,可能會出現OOM問題。
| 模型 | 最大SEQ長度 | 最大批處理大小 |
|---|---|---|
| Llama2-7b(羊駝) | 512 | 8 |
| Llama2-7b(Vicuna) | 2800 | 1 |
RTX3090(24G)上的指令微調7B型號。如果您在RTX 3090/4000上使用多個GPU進行分佈式培訓,請在運行之前添加以下命令: export NCCL_IB_DISABLE=1 ; export NCCL_P2P_DISABLE=1
| 模型 | 最大SEQ長度 | 最大批處理大小 |
|---|---|---|
| Llama2-7b(羊駝) | 512 | 3 |
| Llama2-7b(Vicuna) | 1400 | 1 |
pytorch > = 2.1.1; transformers == 4.36.2pip install -r requirements.txtconda install mpi4py==3.1.4pip install flash-attn==2.5.8 hift pip install hifthift軟件包 ### generation task
from hift import HiFTSeq2SeqTrainer,GetCallBack,peft_function,Seq2SeqTrainer
### classification taks
from hift import HiFTrainer,GetCallBack,PEFTrainer,peft_function
### QA task
from hift import HiFTQuestionAnsweringTrainer,GetCallBack,QuestionAnsweringTrainer,peft_function
HiFT配置 @dataclass
class HiFTArguments(ModelArguments):
HiTaskType: str = field(
default="SEQ_CLS",
metadata={"help": ("HiTaskType should be consistent with PEFT TaskType" )},
)
peft_type: str = field(
default=None,
metadata={"help": ("peft_type should be in [lora,adalora,ia3,p_tuning,prefix_tuning,prompt_tuning]" )},
)
init_text:str = field(
default="Predict if sentiment of this review is positive, negative or neutral",
metadata={
"help": (
"the init prompt text for prompt tuning"
)
},
)
lora_rank: int = field(
default=8,
metadata={"help": ("rank for lora or adalora" )},
)
peft_path : Optional[str] = field(default=None)
virtual_tokens:int = field(
default=20,
metadata={"help": ("the number of virtual tokens for p_tuning, prefix_tuning and prefix_tuning" )},
)
group_element: int = field(
default=1,
metadata={"help": ("number element for each group parameters" )},
)
optimizer_strategy: str = field(
default="down2up",
metadata={"help": ("optimizer strategy of ['down2up','down2up','random']" )},
)
hier_tuning: bool = field(
default=False,
metadata={
"help": (
"hierarchical optimization for LLMS"
)
},
)
freeze_layers: List[str] = field(
default_factory=list,
metadata={
"help": (
"Index of the frozen layer"
)
},
)
hitaskType應與PEFT TaskType一致。
序列分類,多項選擇任務:
TaskType.SEQ_CLS問題回答任務:
TaskType.QUESTION_ANS序列標籤任務:
TaskType.TOKEN_CLS生成任務:
TaskType.CAUSAL_LM
group_element :塊中包含的層數。默認值為1 。
Freeze_layers :在微調過程中要凍結的層。您應該提供相應層的索引。嵌入層的索引為0 ,第一層的索引為1 ,...
HiFT培訓師HiFT繼承了HuggingFace的培訓師,因此您可以直接使用HIFT提供的教練來替換原始教練。
if model_args.hier_tuning:#hier_tuning
trainer = HiFTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
model=model,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator
)
else:
trainer = PEFTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
質量檢查任務
if model_args.hier_tuning:
trainer = HiFTQuestionAnsweringTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
else:
trainer = QuestionAnsweringTrainer(
peft_type = model_args.peft_type,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
生成任務
if model_args.hier_tuning:#hier_tuning
trainer = HiFTSeq2SeqTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
tokenizer=tokenizer,
data_collator=data_collator
)
else:
trainer = Seq2SeqTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
HiFT支持任何模型。適應HiFT非常容易。
- 定義
TaskTInterface中模型支持的任務類型。- 為
embedding layer和不同的任務header layers提供regular expressions。正則表達式的目的是唯一識別相應層的層名。- 在
others_pattern界面中提供除嵌入層和標頭層以外的正則表達式。
最簡單的方法是提供others_pattern界面中所有圖層的圖層名稱,而其他接口返回一個空列表[] 。下面是羅伯塔的例子。
class RobertaCallBack(HiFTCallBack):
def __init__(self,freeze_layers,strategy,taskType,peft_type=None):
super().__init__(freeze_layers,strategy,taskType,peft_type)
self.TaskTInterface = [TaskType.SEQ_CLS,TaskType.TOKEN_CLS,TaskType.QUESTION_ANS]
self.check_task_type(taskType,"RoBERTa",self.TaskTInterface)
@property
def emb_pattern(self):
if self.peft_type:
return [rf'.embedding.']
else:
return [rf'.embeddings.']
@property
def seq_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def token_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def qa_cls_head(self):
if self.peft_type:
return ["qa_outputs"]
else:
return ["qa_outputs"]
@property
def others_pattern(self):
if self.peft_type:
return [rf'.d+.']
else:
return [rf'.d+.']
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/output_vicuna"
port=$(shuf -i25000-30000 -n1)
#--fsdp "full_shard auto_wrap"
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/vicuna_train.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--optim "lion_32bit"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--data_path data/dummy_conversation.json
--eval_data_path data/sharegpt_clean.json
--output_dir $output_dir/model
--num_train_epochs 3
--do_train
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--evaluation_strategy "steps"
--eval_steps 1500
--save_strategy "steps"
--save_steps 1500
--save_total_limit 8
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0
--lr_scheduler_type "linear"
--logging_steps 10
--model_max_length 2800
--lazy_preprocess True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/instruct_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/instruct_tuning.py
--model_type opt
--HiTaskType "CAUSAL_LM"
--optim "adamw_torch"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path opt-7b
--dataset_dir alpaca_data
--validation_split_percentage 0.01
--per_device_train_batch_size 12
--per_device_eval_batch_size 8
--do_train
--do_eval
--seed 12345
--fp16
--tf32 true
--num_train_epochs 1
--lr_scheduler_type "cosine"
--learning_rate 1e-5
--warmup_ratio 0.0
--weight_decay 0.0
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--evaluation_strategy steps
--eval_steps 100
--save_steps 200
--preprocessing_num_workers 4
--max_seq_length 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### This is just a demo. Please adjust the parameters based on your data.
export num_gpus=8
export output_dir="outputs/pretrain_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES=0 torchrun --master_port "$port" examples/pretrain_tuning.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path llama2-7b
--dataset_dir "data"
--data_cache_dir "data_cache_dir"
--validation_split_percentage 0.001
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--do_train
--seed 12345
--fp16
--max_steps 1000
--lr_scheduler_type cosine
--learning_rate 1e-5
--warmup_ratio 0.05
--weight_decay 0.01
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--save_steps 500
--preprocessing_num_workers 8
--block_size 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--hier_tuning
--group_element $1
--optimizer_strategy $2
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
# CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" python -m torch.distributed.launch --nproc_per_node=$num_gpus run_glue.py
CUDA_VISIBLE_DEVICES=7 torchrun --master_port "$port" examples/run_generation.py
--model_name_or_path llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--padding_side "left"
--group_by_length
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--weight_decay 0
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/run_generation.py
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--deepspeed "dsconfig/zero0_config.json"
--padding_side "left"
--group_by_length
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--hier_tuning
--weight_decay 0
--group_element $1
--optimizer_strategy $2
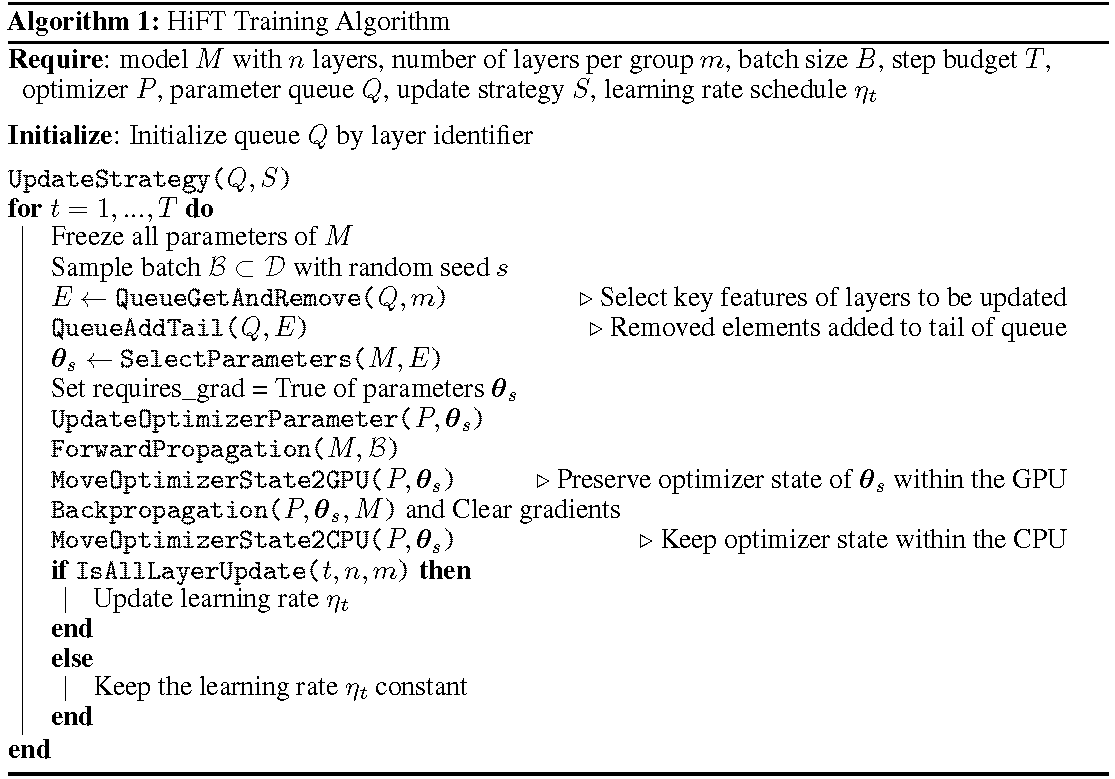
詳細的培訓過程以算法為單位。第一步是確定更新策略。然後凍結所有層。要更新的層,表示
HiFT迭代在每個訓練步驟中更新參數的子集,並且將在多個步驟後修改完整參數。這大大降低了微調語言模型的GPU內存需求,可以在部署過程中進行有效的任務轉換,而無需引入推理潛伏期。 HIFT還勝過其他幾種適應方法,包括適配器,前綴調整和微調。
HiFT是一種獨立於模型和優化器獨立的全參數微調方法,可以與PEFT方法集成。
優化器:最新版本的HiFT適用於Adam , AdamW , SGD , Adafactor和Adagrad優化器。
模型: HiFT的最新版本支持BERT , RoBERTa , GPT-2 , GPTNeo , GPT-NeoX , OPT和LLaMA-based模型。
Opt-13b的實驗(有1000個示例)。 ICL :在文章中學習; LP :線性探測; FPFT :全面調節;前綴:前綴調整。所有實驗都使用Mezo的提示。
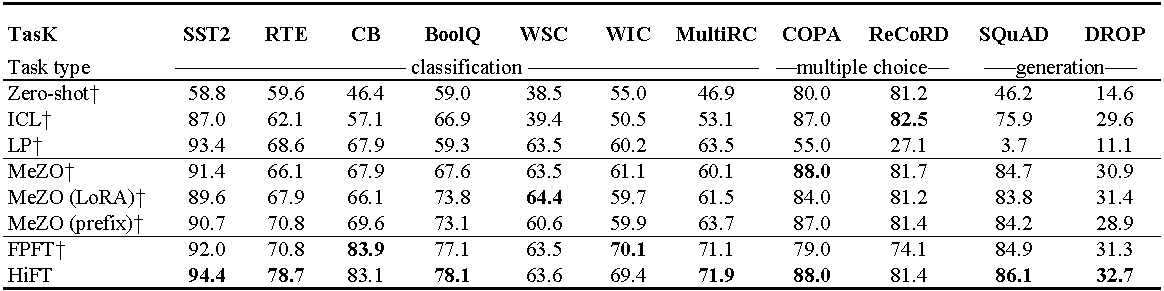
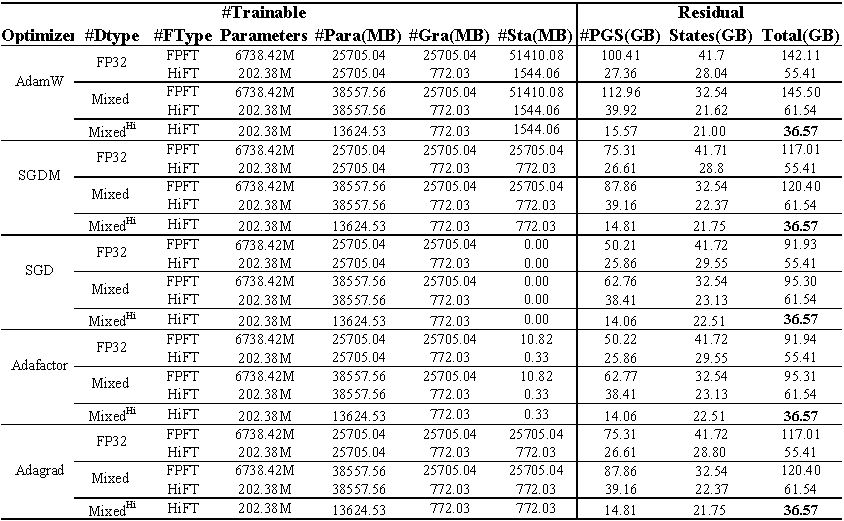
E2E數據集上微調駱駝(7b)的GPU內存使用情況。總計代表微調過程中使用的總內存。混合表示具有標準混合精度的微調和混合^ HI^表示適合HiFT的混合精度。 Para表示模型參數所佔據的內存; GRA代表梯度佔據的記憶; STA表示優化器狀態佔據的內存。 PGS表示參數,梯度和優化器狀態所佔據的內存之和。
原始碼
class FP16_Optimizer(DeepSpeedOptimizer):
def __init__(self,
init_optimizer,
deepspeed=None,
static_loss_scale=1.0,
dynamic_loss_scale=False,
initial_dynamic_scale=2**32,
dynamic_loss_args=None,
verbose=True,
mpu=None,
clip_grad=0.0,
fused_adam_legacy=False,
has_moe_layers=False,
timers=None):
....
self.fp16_groups = []
self.fp16_groups_flat = []
self.fp32_groups_flat = []
...
for i, param_group in enumerate(self.optimizer.param_groups):
...
self.fp32_groups_flat.append(self.fp16_groups_flat[i].clone().float().detach())
...
加載1b參數所需的內存為3.72GB (10^9
我們重新實現混合精確算法以適應HiFT的微調算法,該算法確保單位模型參數不會引起其他GPU內存開銷。
@article { liu2024hift ,
title = { HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy } ,
author = { Liu, Yongkang and Zhang, Yiqun and Li, Qian and Feng, Shi and Wang, Daling and Zhang, Yifei and Sch{"u}tze, Hinrich } ,
journal = { arXiv preprint arXiv:2401.15207 } ,
year = { 2024 }
}該項目歡迎貢獻和建議。大多數捐款要求您同意撰寫貢獻者許可協議(CLA),宣布您有權並實際上授予我們使用您的貢獻的權利。


