HiFT
1.0.0
Este repositório contém o código -fonte do pacote Python HiFT e vários exemplos de como integrá -lo aos modelos Pytorch, como os de abraçar o rosto. Só apoiamos Pytorch por enquanto. Consulte nosso artigo para uma descrição detalhada de · HiFT . HiFT suporta FPFT de modelos 7B para dispositivos de memória GPU 24G sob precisão mista sem usar nenhuma técnica de economia de memória e vários otimizadores, incluindo AdamW , AdaGrad , SGD , etc.
Hift: uma estratégia hierárquica de ajuste fino de parâmetro completo
Yongkang Liu, Yiqun Zhang, Qian Li, Tong Liu, Shi Feng, Daling Wang, Yifei Zhang, Hinrich Schütze
Papel: https://arxiv.org/abs/2401.15207
26/1/2024 : Publique a primeira versão do manuscrito HiFT
25/2/2024 : Publique a segunda versão do manuscrito HiFT e código -fonte
1/5/2024 : Suporte de hift atualizado para LoRA
05/10/2024 : Adapte o otimizador fornecido por BitsandBytes
13/5/2024*: Adapte Adalora , LoRA , IA3 , P_tuning , Prefix_tuning , Prompt_tuning PEFT Method.
Existem vários diretórios neste repo:
hift , que precisa ser instalado para executar os exemplos que fornecemos;NER , QA HiFT classification , text generation , instruction fine-tuning e implementação de exemplo pre-training . Instruções Modelo 7b de ajuste fino em A6000 (48G), e os resultados experimentais mostram que o comprimento máximo da sequência suportado pelo HIFT está 2800. Além desse limite, os problemas OOM podem ocorrer.
| Modelo | MAX SEQ Length | Tamanho máximo em lote |
|---|---|---|
| LLAMA2-7B (ALPACA) | 512 | 8 |
| llama2-7b (Vicuna) | 2800 | 1 |
Instruções Modelo 7b de ajuste fino no RTX3090 (24G). Se você usar várias GPUs para treinamento distribuído no RTX 3090/4000 , adicione os seguintes comandos antes de executar: export NCCL_IB_DISABLE=1 ; export NCCL_P2P_DISABLE=1
| Modelo | MAX SEQ Length | Tamanho máximo em lote |
|---|---|---|
| LLAMA2-7B (ALPACA) | 512 | 3 |
| llama2-7b (Vicuna) | 1400 | 1 |
pytorch > = 2.1.1; transformers == 4.36.2pip install -r requirements.txtconda install mpi4py==3.1.4pip install flash-attn==2.5.8 hift pip install hifthift ### generation task
from hift import HiFTSeq2SeqTrainer,GetCallBack,peft_function,Seq2SeqTrainer
### classification taks
from hift import HiFTrainer,GetCallBack,PEFTrainer,peft_function
### QA task
from hift import HiFTQuestionAnsweringTrainer,GetCallBack,QuestionAnsweringTrainer,peft_function
HiFT @dataclass
class HiFTArguments(ModelArguments):
HiTaskType: str = field(
default="SEQ_CLS",
metadata={"help": ("HiTaskType should be consistent with PEFT TaskType" )},
)
peft_type: str = field(
default=None,
metadata={"help": ("peft_type should be in [lora,adalora,ia3,p_tuning,prefix_tuning,prompt_tuning]" )},
)
init_text:str = field(
default="Predict if sentiment of this review is positive, negative or neutral",
metadata={
"help": (
"the init prompt text for prompt tuning"
)
},
)
lora_rank: int = field(
default=8,
metadata={"help": ("rank for lora or adalora" )},
)
peft_path : Optional[str] = field(default=None)
virtual_tokens:int = field(
default=20,
metadata={"help": ("the number of virtual tokens for p_tuning, prefix_tuning and prefix_tuning" )},
)
group_element: int = field(
default=1,
metadata={"help": ("number element for each group parameters" )},
)
optimizer_strategy: str = field(
default="down2up",
metadata={"help": ("optimizer strategy of ['down2up','down2up','random']" )},
)
hier_tuning: bool = field(
default=False,
metadata={
"help": (
"hierarchical optimization for LLMS"
)
},
)
freeze_layers: List[str] = field(
default_factory=list,
metadata={
"help": (
"Index of the frozen layer"
)
},
)
HitaSkType deve ser consistente com PEFT TaskType .
Classificação de sequência , tarefas de múltipla escolha :
TaskType.SEQ_CLSTarefa de resposta a perguntas :
TaskType.QUESTION_ANSTarefa de rotulagem de sequência :
TaskType.TOKEN_CLSTarefa de geração :
TaskType.CAUSAL_LM
group_element : o número de camadas incluídas em um bloco. O valor padrão é 1 .
Freeze_layers : Camadas que você deseja congelar durante o ajuste fino. Você deve fornecer o índice da camada correspondente. O índice da camada de incorporação é 0 , o índice da primeira camada é 1 , ...
HiFT HiFT herda o treinador do HuggingFace, para que você possa usar diretamente o treinador fornecido pela Hift para substituir o treinador original.
if model_args.hier_tuning:#hier_tuning
trainer = HiFTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
model=model,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator
)
else:
trainer = PEFTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
Tarefa de controle de qualidade
if model_args.hier_tuning:
trainer = HiFTQuestionAnsweringTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
else:
trainer = QuestionAnsweringTrainer(
peft_type = model_args.peft_type,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
Tarefa de geração
if model_args.hier_tuning:#hier_tuning
trainer = HiFTSeq2SeqTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
tokenizer=tokenizer,
data_collator=data_collator
)
else:
trainer = Seq2SeqTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
HiFT suporta qualquer modelo. É muito fácil de se adaptar ao HiFT .
- Defina os tipos de tarefas suportados pelo seu modelo no
TaskTInterface.- Fornece
regular expressionspara aembedding layere diferentesheader layersde tarefas. O objetivo da expressão regular é identificar exclusivamente o nome da camada da camada correspondente.- Forneça expressões regulares, exceto a camada de incorporação e a camada de cabeçalho na interface
others_pattern.
A maneira mais simples é fornecer os nomes da camada para todas as camadas na interface others_pattern , e as outras interfaces retornam uma lista vazia [] . Abaixo está o exemplo do Roberta.
class RobertaCallBack(HiFTCallBack):
def __init__(self,freeze_layers,strategy,taskType,peft_type=None):
super().__init__(freeze_layers,strategy,taskType,peft_type)
self.TaskTInterface = [TaskType.SEQ_CLS,TaskType.TOKEN_CLS,TaskType.QUESTION_ANS]
self.check_task_type(taskType,"RoBERTa",self.TaskTInterface)
@property
def emb_pattern(self):
if self.peft_type:
return [rf'.embedding.']
else:
return [rf'.embeddings.']
@property
def seq_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def token_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def qa_cls_head(self):
if self.peft_type:
return ["qa_outputs"]
else:
return ["qa_outputs"]
@property
def others_pattern(self):
if self.peft_type:
return [rf'.d+.']
else:
return [rf'.d+.']
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/output_vicuna"
port=$(shuf -i25000-30000 -n1)
#--fsdp "full_shard auto_wrap"
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/vicuna_train.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--optim "lion_32bit"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--data_path data/dummy_conversation.json
--eval_data_path data/sharegpt_clean.json
--output_dir $output_dir/model
--num_train_epochs 3
--do_train
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--evaluation_strategy "steps"
--eval_steps 1500
--save_strategy "steps"
--save_steps 1500
--save_total_limit 8
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0
--lr_scheduler_type "linear"
--logging_steps 10
--model_max_length 2800
--lazy_preprocess True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/instruct_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/instruct_tuning.py
--model_type opt
--HiTaskType "CAUSAL_LM"
--optim "adamw_torch"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path opt-7b
--dataset_dir alpaca_data
--validation_split_percentage 0.01
--per_device_train_batch_size 12
--per_device_eval_batch_size 8
--do_train
--do_eval
--seed 12345
--fp16
--tf32 true
--num_train_epochs 1
--lr_scheduler_type "cosine"
--learning_rate 1e-5
--warmup_ratio 0.0
--weight_decay 0.0
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--evaluation_strategy steps
--eval_steps 100
--save_steps 200
--preprocessing_num_workers 4
--max_seq_length 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### This is just a demo. Please adjust the parameters based on your data.
export num_gpus=8
export output_dir="outputs/pretrain_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES=0 torchrun --master_port "$port" examples/pretrain_tuning.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path llama2-7b
--dataset_dir "data"
--data_cache_dir "data_cache_dir"
--validation_split_percentage 0.001
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--do_train
--seed 12345
--fp16
--max_steps 1000
--lr_scheduler_type cosine
--learning_rate 1e-5
--warmup_ratio 0.05
--weight_decay 0.01
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--save_steps 500
--preprocessing_num_workers 8
--block_size 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--hier_tuning
--group_element $1
--optimizer_strategy $2
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
# CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" python -m torch.distributed.launch --nproc_per_node=$num_gpus run_glue.py
CUDA_VISIBLE_DEVICES=7 torchrun --master_port "$port" examples/run_generation.py
--model_name_or_path llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--padding_side "left"
--group_by_length
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--weight_decay 0
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/run_generation.py
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--deepspeed "dsconfig/zero0_config.json"
--padding_side "left"
--group_by_length
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--hier_tuning
--weight_decay 0
--group_element $1
--optimizer_strategy $2
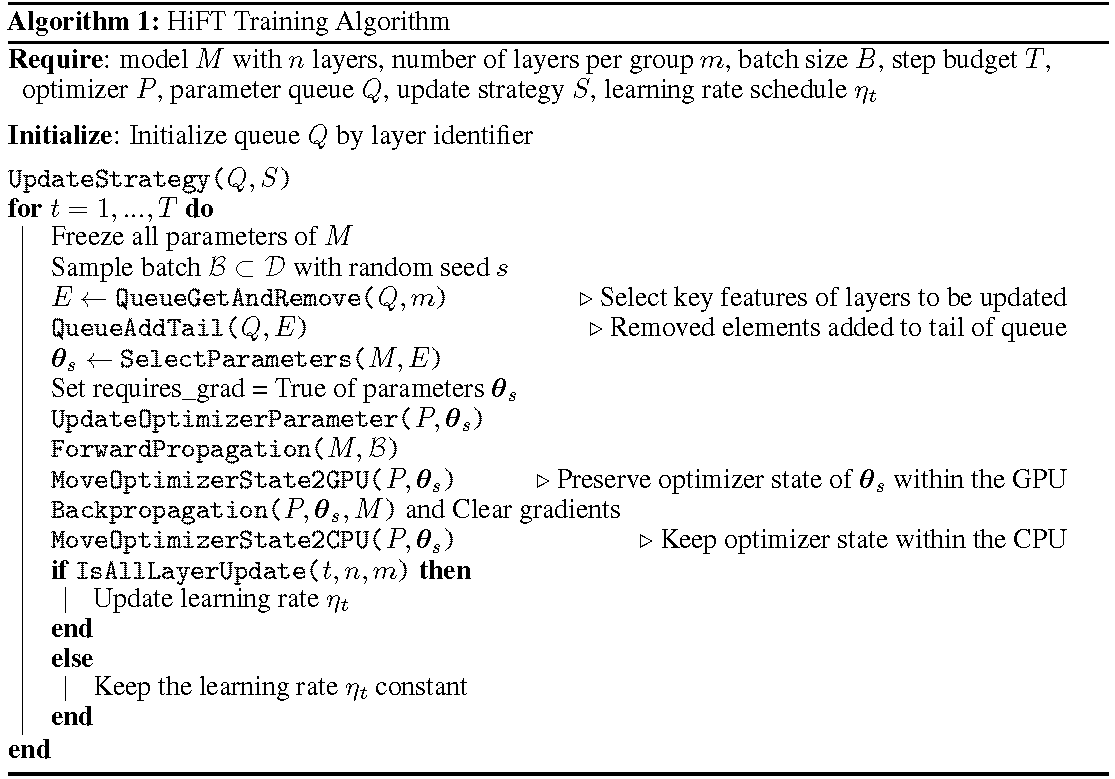
O processo de treinamento detalhado é mostrado no algoritmo. O primeiro passo é determinar a estratégia de atualização. Em seguida, congele todas as camadas. As camadas a serem atualizadas, denotadas por
HiFT atualiza iterativamente um subconjunto de parâmetros em cada etapa de treinamento e modificará o parâmetro completo após várias etapas. Isso reduz bastante os requisitos de memória da GPU para modelos de linguagem de ajuste fino, permite que a troca de tarefas eficiente durante a implantação, tudo sem introduzir latência de inferência. O HIFT também supera vários outros métodos de adaptação, incluindo adaptador, ajuste de prefixo e ajuste fino.
HiFT é um método de ajuste fino independente e independente do otimizador que pode ser integrado ao método PEFT.
Otimizadores : A versão mais recente do HiFT é adaptada aos otimizadores Adam , AdamW , SGD , Adafactor e Adagrad .
Modelo : A versão mais recente do HiFT suporta BERT , RoBERTa , GPT-2 , GPTNeo , GPT-NeoX , OPT e modelos LLaMA-based .
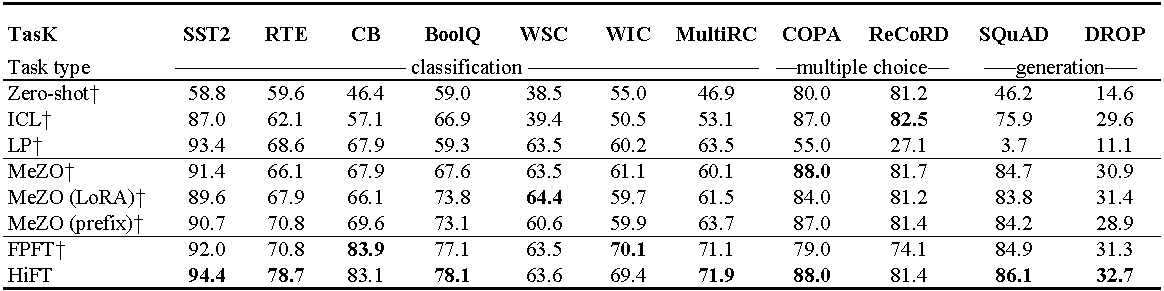
Experimentos no OPT-13B (com 1000 exemplos). ICL : aprendizado no contexto; LP : sondagem linear; FPFT : ajuste fino completo; Prefixo: T-Tuning de prefixo. Todas as experiências usam instruções de Mezo.
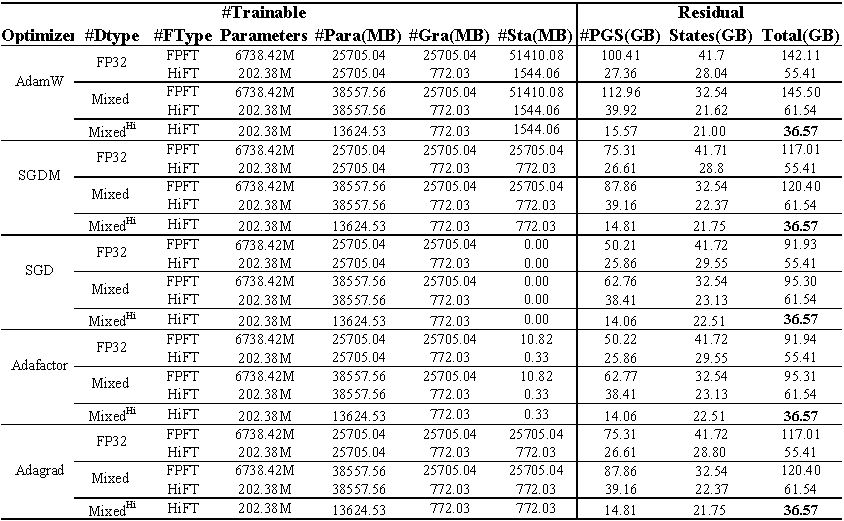
Uso da memória da GPU da llama de ajuste fino (7B) no conjunto de dados E2E . O total representa a memória total usada durante o ajuste fino. O misturado representa o ajuste fino com precisão mista padrão e misto^ Hi^ representa a precisão mista adaptada para HiFT . O para representa a memória ocupada pelos parâmetros do modelo; GRA representa a memória ocupada pelo gradiente; O STA representa a memória ocupada pelo estado do otimizador . O PGS representa a soma da memória ocupada por parâmetros , gradientes e estado de otimizador .
Código -fonte
class FP16_Optimizer(DeepSpeedOptimizer):
def __init__(self,
init_optimizer,
deepspeed=None,
static_loss_scale=1.0,
dynamic_loss_scale=False,
initial_dynamic_scale=2**32,
dynamic_loss_args=None,
verbose=True,
mpu=None,
clip_grad=0.0,
fused_adam_legacy=False,
has_moe_layers=False,
timers=None):
....
self.fp16_groups = []
self.fp16_groups_flat = []
self.fp32_groups_flat = []
...
for i, param_group in enumerate(self.optimizer.param_groups):
...
self.fp32_groups_flat.append(self.fp16_groups_flat[i].clone().float().detach())
...
A memória necessária para carregar parâmetros 1b é de 3,72 GB (10^9
Reimpletamos o algoritmo de precisão mista para se adaptar ao algoritmo de ajuste fino do HiFT , o que garante que os parâmetros do modelo de precisão única não incorrem na sobrecarga adicional da memória da GPU.
@article { liu2024hift ,
title = { HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy } ,
author = { Liu, Yongkang and Zhang, Yiqun and Li, Qian and Feng, Shi and Wang, Daling and Zhang, Yifei and Sch{"u}tze, Hinrich } ,
journal = { arXiv preprint arXiv:2401.15207 } ,
year = { 2024 }
}Este projeto recebe contribuições e sugestões. A maioria das contribuições exige que você concorde com um Contrato de Licença de Colaborador (CLA) declarando que você tem o direito e, na verdade, concede -nos os direitos de usar sua contribuição.


