HiFT
1.0.0
Este repositorio contiene el código fuente del paquete Python HiFT y varios ejemplos de cómo integrarlo con los modelos de Pytorch, como los que están en abrazo. Solo apoyamos a Pytorch por ahora. Vea nuestro artículo para obtener una descripción detallada de · HiFT . HiFT admite FPFT de modelos 7B para dispositivos de memoria de GPU de 24 g bajo precisión mixta sin usar técnicas de ahorro de memoria y varios optimizadores, incluidos AdamW , AdaGrad , SGD , etc.
HIFT: una estrategia jerárquica de parámetros completos ajustados
Yongkang Liu, Yiqun Zhang, Qian Li, Tong Liu, Shi Feng, Daling Wang, Yifei Zhang, Hinrich Schütze
Documento: https://arxiv.org/abs/2401.15207
26/1/2024 : Publique la primera versión del manuscrito HiFT
25/2/2024 : Publique la segunda versión del manuscrito HiFT y el código fuente
5/5/2024 : Soporte actualizado de HIFT para LoRA
10/5/2024 : Adapte el optimizador proporcionado por bitsandbytes
13/5/2024*: Adapte Adalora , LoRA , IA3 , P_tuning , Prefix_tuning , Prompt_tuning Peft Method.
Hay varios directorios en este repositorio:
hift , que debe instalarse para ejecutar los ejemplos que proporcionamos;NER basados en HiFT , QA , classification , text generation , instruction fine-tuning e implementación de ejemplo pre-training . Instrucción Modelo 7B ajustado en A6000 (48 g), y los resultados experimentales muestran que la longitud de secuencia máxima respaldada por HIFT es 2800. Más allá de este límite, pueden ocurrir problemas OOM .
| Modelo | Longitud máxima de seq | Tamaño de lote máximo |
|---|---|---|
| Llama2-7b (Alpaca) | 512 | 8 |
| Llama2-7b (vicuna) | 2800 | 1 |
Instrucción Autorización FINA Modelo 7B en RTX3090 (24 g). Si usa múltiples GPU para capacitación distribuida en RTX 3090/4000 , agregue los siguientes comandos antes de ejecutar: export NCCL_IB_DISABLE=1 ; export NCCL_P2P_DISABLE=1
| Modelo | Longitud máxima de seq | Tamaño de lote máximo |
|---|---|---|
| Llama2-7b (Alpaca) | 512 | 3 |
| Llama2-7b (vicuna) | 1400 | 1 |
pytorch > = 2.1.1; transformers == 4.36.2pip install -r requirements.txtconda install mpi4py==3.1.4pip install flash-attn==2.5.8 hift pip install hifthift ### generation task
from hift import HiFTSeq2SeqTrainer,GetCallBack,peft_function,Seq2SeqTrainer
### classification taks
from hift import HiFTrainer,GetCallBack,PEFTrainer,peft_function
### QA task
from hift import HiFTQuestionAnsweringTrainer,GetCallBack,QuestionAnsweringTrainer,peft_function
HiFT @dataclass
class HiFTArguments(ModelArguments):
HiTaskType: str = field(
default="SEQ_CLS",
metadata={"help": ("HiTaskType should be consistent with PEFT TaskType" )},
)
peft_type: str = field(
default=None,
metadata={"help": ("peft_type should be in [lora,adalora,ia3,p_tuning,prefix_tuning,prompt_tuning]" )},
)
init_text:str = field(
default="Predict if sentiment of this review is positive, negative or neutral",
metadata={
"help": (
"the init prompt text for prompt tuning"
)
},
)
lora_rank: int = field(
default=8,
metadata={"help": ("rank for lora or adalora" )},
)
peft_path : Optional[str] = field(default=None)
virtual_tokens:int = field(
default=20,
metadata={"help": ("the number of virtual tokens for p_tuning, prefix_tuning and prefix_tuning" )},
)
group_element: int = field(
default=1,
metadata={"help": ("number element for each group parameters" )},
)
optimizer_strategy: str = field(
default="down2up",
metadata={"help": ("optimizer strategy of ['down2up','down2up','random']" )},
)
hier_tuning: bool = field(
default=False,
metadata={
"help": (
"hierarchical optimization for LLMS"
)
},
)
freeze_layers: List[str] = field(
default_factory=list,
metadata={
"help": (
"Index of the frozen layer"
)
},
)
HitaskType debe ser consistente con PEFT TaskType .
Clasificación de secuencia , tareas de opción múltiple :
TaskType.SEQ_CLSTarea de respuesta a las preguntas :
TaskType.QUESTION_ANSTarea de etiquetado de secuencia :
TaskType.TOKEN_CLSTarea de generación :
TaskType.CAUSAL_LM
Group_element : el número de capas incluidas en un bloque. El valor predeterminado es 1 .
Freeze_layers : capas que desea congelar durante el ajuste fino. Debe proporcionar el índice de la capa correspondiente. El índice de la capa de incrustación es 0 , el índice de la primera capa es 1 , ...
HiFT Trainer HiFT hereda el entrenador de Huggingface, por lo que puede usar directamente el entrenador proporcionado por Hift para reemplazar el entrenador original.
if model_args.hier_tuning:#hier_tuning
trainer = HiFTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
model=model,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator
)
else:
trainer = PEFTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
Tarea de control de calidad
if model_args.hier_tuning:
trainer = HiFTQuestionAnsweringTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
else:
trainer = QuestionAnsweringTrainer(
peft_type = model_args.peft_type,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
Tarea de generación
if model_args.hier_tuning:#hier_tuning
trainer = HiFTSeq2SeqTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
tokenizer=tokenizer,
data_collator=data_collator
)
else:
trainer = Seq2SeqTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
HiFT admite cualquier modelo. Es muy fácil adaptarse a HiFT .
- Defina los tipos de tareas compatibles con su modelo en
TaskTInterface.- Proporciona
regular expressionspara laembedding layery diferentesheader layersde tareas. El propósito de la expresión regular es identificar de manera única el nombre de la capa de la capa correspondiente.- Proporcione expresiones regulares, excepto la capa de incrustación y la capa de encabezado en la interfaz
others_pattern.
La forma más simple es proporcionar los nombres de capas para todas las capas en la interfaz others_pattern , y las otras interfaces devuelven una lista vacía [] . A continuación se muestra el ejemplo de Roberta.
class RobertaCallBack(HiFTCallBack):
def __init__(self,freeze_layers,strategy,taskType,peft_type=None):
super().__init__(freeze_layers,strategy,taskType,peft_type)
self.TaskTInterface = [TaskType.SEQ_CLS,TaskType.TOKEN_CLS,TaskType.QUESTION_ANS]
self.check_task_type(taskType,"RoBERTa",self.TaskTInterface)
@property
def emb_pattern(self):
if self.peft_type:
return [rf'.embedding.']
else:
return [rf'.embeddings.']
@property
def seq_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def token_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def qa_cls_head(self):
if self.peft_type:
return ["qa_outputs"]
else:
return ["qa_outputs"]
@property
def others_pattern(self):
if self.peft_type:
return [rf'.d+.']
else:
return [rf'.d+.']
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/output_vicuna"
port=$(shuf -i25000-30000 -n1)
#--fsdp "full_shard auto_wrap"
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/vicuna_train.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--optim "lion_32bit"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--data_path data/dummy_conversation.json
--eval_data_path data/sharegpt_clean.json
--output_dir $output_dir/model
--num_train_epochs 3
--do_train
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--evaluation_strategy "steps"
--eval_steps 1500
--save_strategy "steps"
--save_steps 1500
--save_total_limit 8
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0
--lr_scheduler_type "linear"
--logging_steps 10
--model_max_length 2800
--lazy_preprocess True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/instruct_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/instruct_tuning.py
--model_type opt
--HiTaskType "CAUSAL_LM"
--optim "adamw_torch"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path opt-7b
--dataset_dir alpaca_data
--validation_split_percentage 0.01
--per_device_train_batch_size 12
--per_device_eval_batch_size 8
--do_train
--do_eval
--seed 12345
--fp16
--tf32 true
--num_train_epochs 1
--lr_scheduler_type "cosine"
--learning_rate 1e-5
--warmup_ratio 0.0
--weight_decay 0.0
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--evaluation_strategy steps
--eval_steps 100
--save_steps 200
--preprocessing_num_workers 4
--max_seq_length 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### This is just a demo. Please adjust the parameters based on your data.
export num_gpus=8
export output_dir="outputs/pretrain_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES=0 torchrun --master_port "$port" examples/pretrain_tuning.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path llama2-7b
--dataset_dir "data"
--data_cache_dir "data_cache_dir"
--validation_split_percentage 0.001
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--do_train
--seed 12345
--fp16
--max_steps 1000
--lr_scheduler_type cosine
--learning_rate 1e-5
--warmup_ratio 0.05
--weight_decay 0.01
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--save_steps 500
--preprocessing_num_workers 8
--block_size 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--hier_tuning
--group_element $1
--optimizer_strategy $2
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
# CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" python -m torch.distributed.launch --nproc_per_node=$num_gpus run_glue.py
CUDA_VISIBLE_DEVICES=7 torchrun --master_port "$port" examples/run_generation.py
--model_name_or_path llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--padding_side "left"
--group_by_length
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--weight_decay 0
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/run_generation.py
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--deepspeed "dsconfig/zero0_config.json"
--padding_side "left"
--group_by_length
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--hier_tuning
--weight_decay 0
--group_element $1
--optimizer_strategy $2
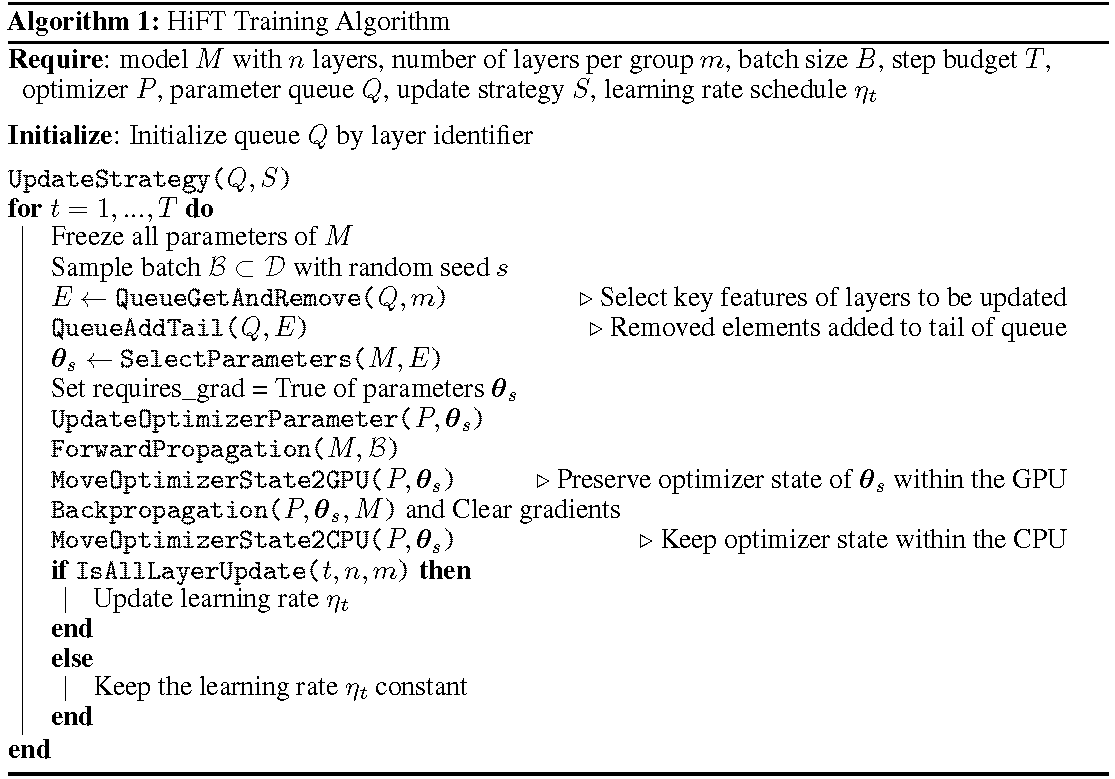
El proceso de capacitación detallado se muestra en el algoritmo. El primer paso es determinar la estrategia de actualización. Luego congela todas las capas. Las capas a actualizar, denotadas por
HiFT iterativamente actualiza un subconjunto de parámetros en cada paso de entrenamiento, y modificará el parámetro completo después de múltiples pasos. Esto reduce enormemente los requisitos de memoria de la GPU para los modelos de lenguaje de AtuningLarge de ajuste fino permite el cambio de tareas eficiente durante el despliegue, todo sin introducir latencia de inferencia. Hift también supera a varios otros métodos de adaptación que incluyen adaptador, ajuste de prefijo y ajuste fino.
HiFT es un método de ajuste de parámetro completo independiente del modelo e independiente del optimizador que puede integrarse con el método PEFT.
Optimizers : La última versión de HiFT se adapta a los optimizadores Adam , AdamW , SGD , Adafactor y Adagrad .
Modelo : La última versión de HiFT es compatible con BERT , RoBERTa , GPT-2 , GPTNeo , GPT-NeoX , OPT y modelos LLaMA-based .
Experimentos en OPT-13B (con 1000 ejemplos). ICL : aprendizaje en contexto; LP : sondeo lineal; FPFT : ajuste completo; Prefijo: prefijo-ajuste. Todos los experimentos usan indicaciones de MEZO.
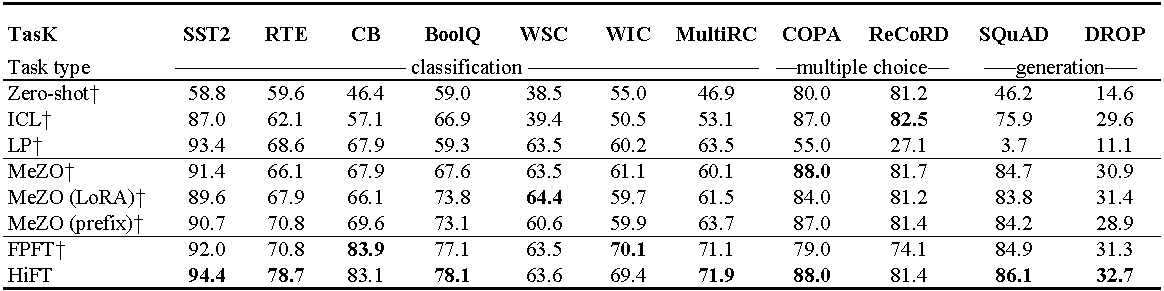
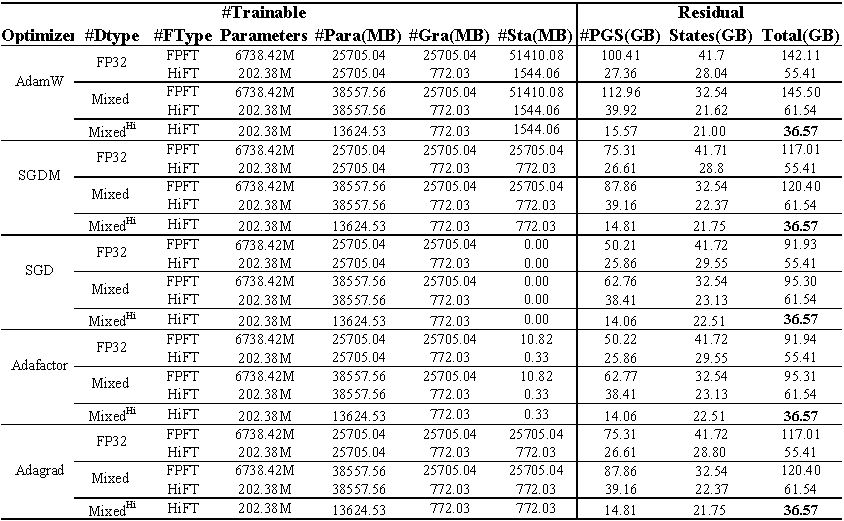
Uso de memoria de GPU de LLAMA ajustado (7b) en el conjunto de datos E2E . El total representa la memoria total utilizada durante el ajuste fino. Mixto representa el ajuste fino con precisión mixta estándar y mixta^ Hi^ representa la precisión mixta adaptada a HiFT . PARA representa la memoria ocupada por los parámetros del modelo; GRA representa la memoria ocupada por el gradiente; STA representa la memoria ocupada por el estado del optimizador . PGS representa la suma de memoria ocupada por parámetros , gradientes y estado optimizador .
Código fuente
class FP16_Optimizer(DeepSpeedOptimizer):
def __init__(self,
init_optimizer,
deepspeed=None,
static_loss_scale=1.0,
dynamic_loss_scale=False,
initial_dynamic_scale=2**32,
dynamic_loss_args=None,
verbose=True,
mpu=None,
clip_grad=0.0,
fused_adam_legacy=False,
has_moe_layers=False,
timers=None):
....
self.fp16_groups = []
self.fp16_groups_flat = []
self.fp32_groups_flat = []
...
for i, param_group in enumerate(self.optimizer.param_groups):
...
self.fp32_groups_flat.append(self.fp16_groups_flat[i].clone().float().detach())
...
La memoria requerida para cargar parámetros 1b es 3.72GB (10^9
Reimpalificamos el algoritmo de precisión mixta para adaptarnos al algoritmo de ajuste de HiFT , que garantiza que los parámetros del modelo de precisión única no incurran en la sobrecarga de memoria de GPU adicional.
@article { liu2024hift ,
title = { HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy } ,
author = { Liu, Yongkang and Zhang, Yiqun and Li, Qian and Feng, Shi and Wang, Daling and Zhang, Yifei and Sch{"u}tze, Hinrich } ,
journal = { arXiv preprint arXiv:2401.15207 } ,
year = { 2024 }
}Este proyecto da la bienvenida a las contribuciones y sugerencias. La mayoría de las contribuciones requieren que acepte un Acuerdo de Licencia de Contributor (CLA) que declare que tiene derecho y realmente hacernos los derechos para utilizar su contribución.


