HiFT
1.0.0
Ce dépôt contient le code source du package Python HiFT et plusieurs exemples de la façon de l'intégrer avec des modèles Pytorch, tels que ceux de l'étreinte. Nous ne soutenons que Pytorch pour l'instant. Voir notre article pour une description détaillée de · HiFT . HiFT prend en charge FPFT de modèles 7B pour les appareils de mémoire GPU 24 g sous une précision mixte sans utiliser de techniques de sauvegarde de mémoire et divers optimisateurs, notamment AdamW , AdaGrad , SGD , etc.
Hift: une stratégie de réglage des paramètres complets hiérarchiques
Yongkang Liu, Yiqun Zhang, Qian Li, Tong Liu, Shi Feng, Daling Wang, Yifei Zhang, Hinrich Schütze
Papier: https://arxiv.org/abs/2401.15207
26/1/2024 : Publier la première version du manuscrit HiFT
25/2/2024 : Publiez la deuxième version du manuscrit et du code source HiFT
1/5/2024 : Prise en charge de Hift mise à jour pour LoRA
10/5/2024 : Adaptez l'optimiseur fourni par BitsandBytes
13/5/2024 *: Adapt Adalora , LoRA , IA3 , P_tuning , Prefix_tuning , Prompt_tuning PEFT Method.
Il y a plusieurs répertoires dans ce dépôt:
hift , qui doit être installé pour exécuter les exemples que nous fournissons;NER basé sur HiFT , QA , classification , text generation , instruction fine-tuning et une implémentation d'exemple pre-training . Le modèle 7B du réglage fin de l'instruction sur A6000 (48G), et les résultats expérimentaux montrent que la longueur de séquence maximale prise en charge par Hift est de 2800. Au-delà de cette limite, des problèmes OOM peuvent se produire.
| Modèle | Longueur max seq | Taille du lot maximum |
|---|---|---|
| llama2-7b (alpaga) | 512 | 8 |
| llama2-7b (vicuna) | 2800 | 1 |
Instruction Modèle 7b fin sur RTX3090 (24g). Si vous utilisez plusieurs GPU pour une formation distribuée sur RTX 3090/4000 , ajoutez les commandes suivantes avant d'exécuter: export NCCL_IB_DISABLE=1 ; export NCCL_P2P_DISABLE=1
| Modèle | Longueur max seq | Taille du lot maximum |
|---|---|---|
| llama2-7b (alpaga) | 512 | 3 |
| llama2-7b (vicuna) | 1400 | 1 |
pytorch > = 2.1.1; transformers == 4.36.2pip install -r requirements.txtconda install mpi4py==3.1.4pip install flash-attn==2.5.8 hift pip install hifthift importation ### generation task
from hift import HiFTSeq2SeqTrainer,GetCallBack,peft_function,Seq2SeqTrainer
### classification taks
from hift import HiFTrainer,GetCallBack,PEFTrainer,peft_function
### QA task
from hift import HiFTQuestionAnsweringTrainer,GetCallBack,QuestionAnsweringTrainer,peft_function
HiFT @dataclass
class HiFTArguments(ModelArguments):
HiTaskType: str = field(
default="SEQ_CLS",
metadata={"help": ("HiTaskType should be consistent with PEFT TaskType" )},
)
peft_type: str = field(
default=None,
metadata={"help": ("peft_type should be in [lora,adalora,ia3,p_tuning,prefix_tuning,prompt_tuning]" )},
)
init_text:str = field(
default="Predict if sentiment of this review is positive, negative or neutral",
metadata={
"help": (
"the init prompt text for prompt tuning"
)
},
)
lora_rank: int = field(
default=8,
metadata={"help": ("rank for lora or adalora" )},
)
peft_path : Optional[str] = field(default=None)
virtual_tokens:int = field(
default=20,
metadata={"help": ("the number of virtual tokens for p_tuning, prefix_tuning and prefix_tuning" )},
)
group_element: int = field(
default=1,
metadata={"help": ("number element for each group parameters" )},
)
optimizer_strategy: str = field(
default="down2up",
metadata={"help": ("optimizer strategy of ['down2up','down2up','random']" )},
)
hier_tuning: bool = field(
default=False,
metadata={
"help": (
"hierarchical optimization for LLMS"
)
},
)
freeze_layers: List[str] = field(
default_factory=list,
metadata={
"help": (
"Index of the frozen layer"
)
},
)
HitaskType doit être cohérent avec PEFT TaskType .
Classification des séquences , tâches à choix multiples :
TaskType.SEQ_CLSQuestion Tâche de réponse :
TaskType.QUESTION_ANSTâche d'étiquetage de séquence :
TaskType.TOKEN_CLSTâche de génération :
TaskType.CAUSAL_LM
Group_element : le nombre de couches incluses dans un bloc. La valeur par défaut est 1 .
Freeze_layers : les calques que vous souhaitez congeler pendant le réglage fin. Vous devez fournir l'index de la couche correspondante. L' indice de la couche d'incorporation est de 0 , l'index de la première couche est 1 , ...
HiFT HiFT hérite de l'entraîneur de Hugging Face, vous pouvez donc utiliser directement l'entraîneur fourni par Hift pour remplacer l'entraîneur d'origine.
if model_args.hier_tuning:#hier_tuning
trainer = HiFTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
model=model,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator
)
else:
trainer = PEFTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
Tâche d'AQ
if model_args.hier_tuning:
trainer = HiFTQuestionAnsweringTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
else:
trainer = QuestionAnsweringTrainer(
peft_type = model_args.peft_type,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
Tâche de génération
if model_args.hier_tuning:#hier_tuning
trainer = HiFTSeq2SeqTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
tokenizer=tokenizer,
data_collator=data_collator
)
else:
trainer = Seq2SeqTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
HiFT prend en charge tout modèle. Il est très facile de s'adapter à HiFT .
- Définissez les types de tâches pris en charge par votre modèle dans
TaskTInterface.- Fournit
regular expressionspour laembedding layeret différentesheader layersde tâche. Le but de l'expression régulière est d'identifier de manière unique le nom de la couche de la couche correspondante.- Fournissez des expressions régulières à l'exception de la couche d'intégration et de la couche d'en-tête dans l'interface
others_pattern.
Le moyen le plus simple consiste à fournir les noms de calques pour toutes les couches de l'interface others_pattern , et les autres interfaces renvoient une liste vide [] . Vous trouverez ci-dessous l'exemple de Roberta.
class RobertaCallBack(HiFTCallBack):
def __init__(self,freeze_layers,strategy,taskType,peft_type=None):
super().__init__(freeze_layers,strategy,taskType,peft_type)
self.TaskTInterface = [TaskType.SEQ_CLS,TaskType.TOKEN_CLS,TaskType.QUESTION_ANS]
self.check_task_type(taskType,"RoBERTa",self.TaskTInterface)
@property
def emb_pattern(self):
if self.peft_type:
return [rf'.embedding.']
else:
return [rf'.embeddings.']
@property
def seq_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def token_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def qa_cls_head(self):
if self.peft_type:
return ["qa_outputs"]
else:
return ["qa_outputs"]
@property
def others_pattern(self):
if self.peft_type:
return [rf'.d+.']
else:
return [rf'.d+.']
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/output_vicuna"
port=$(shuf -i25000-30000 -n1)
#--fsdp "full_shard auto_wrap"
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/vicuna_train.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--optim "lion_32bit"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--data_path data/dummy_conversation.json
--eval_data_path data/sharegpt_clean.json
--output_dir $output_dir/model
--num_train_epochs 3
--do_train
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--evaluation_strategy "steps"
--eval_steps 1500
--save_strategy "steps"
--save_steps 1500
--save_total_limit 8
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0
--lr_scheduler_type "linear"
--logging_steps 10
--model_max_length 2800
--lazy_preprocess True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/instruct_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/instruct_tuning.py
--model_type opt
--HiTaskType "CAUSAL_LM"
--optim "adamw_torch"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path opt-7b
--dataset_dir alpaca_data
--validation_split_percentage 0.01
--per_device_train_batch_size 12
--per_device_eval_batch_size 8
--do_train
--do_eval
--seed 12345
--fp16
--tf32 true
--num_train_epochs 1
--lr_scheduler_type "cosine"
--learning_rate 1e-5
--warmup_ratio 0.0
--weight_decay 0.0
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--evaluation_strategy steps
--eval_steps 100
--save_steps 200
--preprocessing_num_workers 4
--max_seq_length 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### This is just a demo. Please adjust the parameters based on your data.
export num_gpus=8
export output_dir="outputs/pretrain_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES=0 torchrun --master_port "$port" examples/pretrain_tuning.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path llama2-7b
--dataset_dir "data"
--data_cache_dir "data_cache_dir"
--validation_split_percentage 0.001
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--do_train
--seed 12345
--fp16
--max_steps 1000
--lr_scheduler_type cosine
--learning_rate 1e-5
--warmup_ratio 0.05
--weight_decay 0.01
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--save_steps 500
--preprocessing_num_workers 8
--block_size 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--hier_tuning
--group_element $1
--optimizer_strategy $2
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
# CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" python -m torch.distributed.launch --nproc_per_node=$num_gpus run_glue.py
CUDA_VISIBLE_DEVICES=7 torchrun --master_port "$port" examples/run_generation.py
--model_name_or_path llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--padding_side "left"
--group_by_length
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--weight_decay 0
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/run_generation.py
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--deepspeed "dsconfig/zero0_config.json"
--padding_side "left"
--group_by_length
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--hier_tuning
--weight_decay 0
--group_element $1
--optimizer_strategy $2
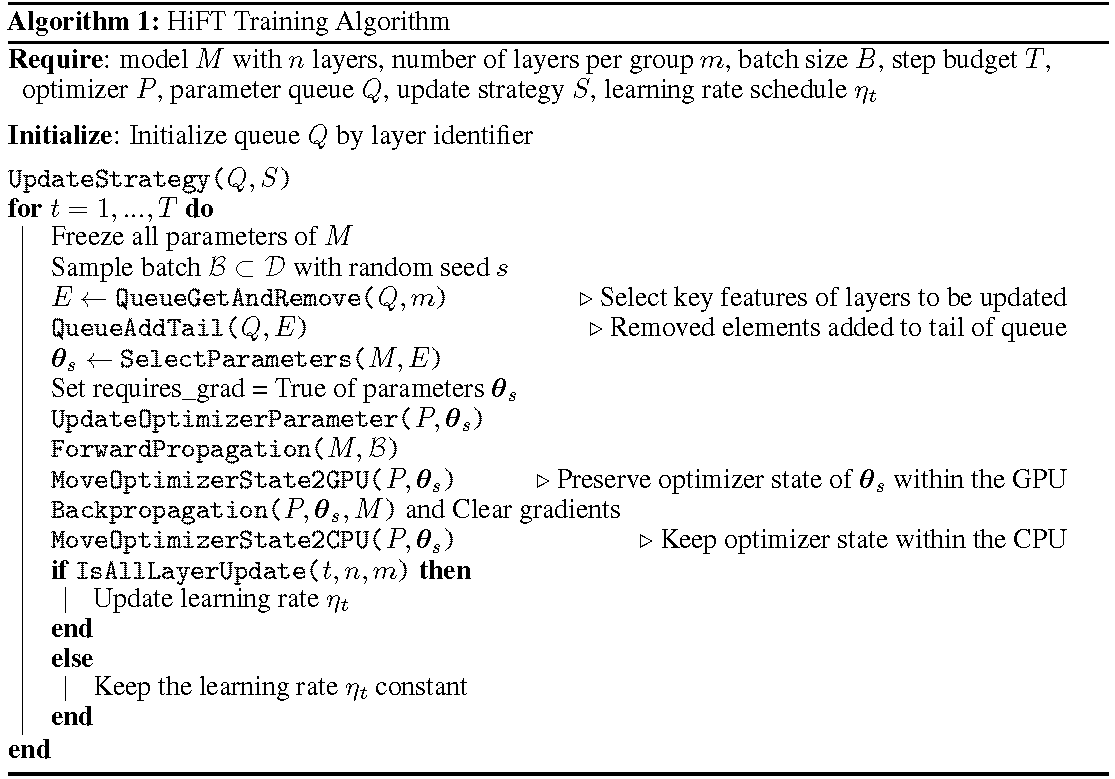
Le processus de formation détaillé est illustré dans l'algorithme. La première étape consiste à déterminer la stratégie de mise à jour. Géliez ensuite toutes les couches. Les couches à mettre à jour, indiquées par
HiFT met à jour itérative un sous-ensemble de paramètres à chaque étape de formation, et il modifiera le paramètre complet après plusieurs étapes. Cela réduit considérablement les exigences de la mémoire GPU pour les modèles de langage à réglage fin, permet un changement de tâche efficace pendant le déploiement sans introduire la latence d'inférence. Hift surpasse également plusieurs autres méthodes d'adaptation, notamment l'adaptateur, le préfixe et le réglage fin.
HiFT est une méthode d'administration de paramètre complète indépendante du modèle et indépendant de l'optimiseur qui peut être intégrée à la méthode PEFT.
Optimisateurs : la dernière version de HiFT est adaptée aux optimisateurs Adam , AdamW , SGD , Adafactor et Adagrad .
Modèle : La dernière version de HiFT prend en charge les modèles basés sur BERT , RoBERTa , GPT-2 , GPTNeo , GPT-NeoX , OPT et LLaMA-based .
Expériences sur OPT-13B (avec 1000 exemples). ICL : apprentissage dans le contexte; LP : sondage linéaire; FPFT : Fonction complète du réglage; Préfixe: préfixe-tun. Toutes les expériences utilisent des invites de Mezo.
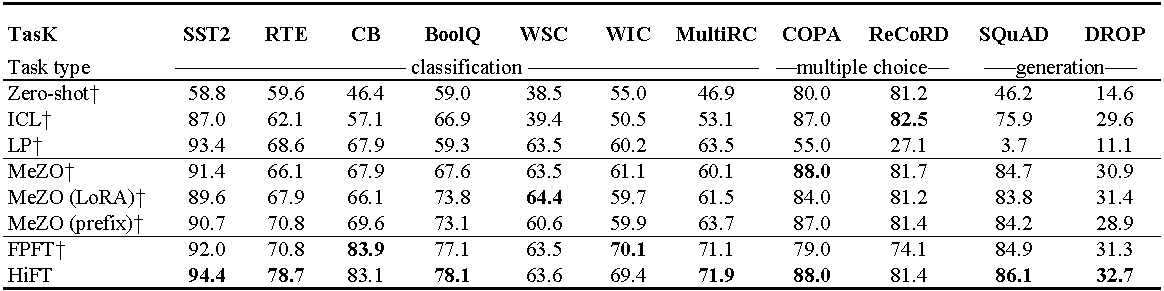
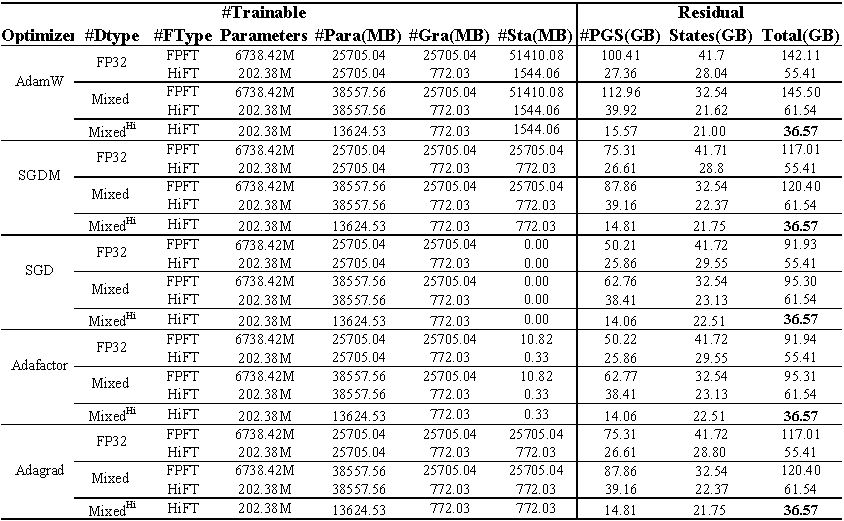
Utilisation de la mémoire GPU de Fine-Tuning Llama (7b) sur l'ensemble de données E2E . Le total représente la mémoire totale utilisée lors du réglage fin. Le mélange représente un réglage fin avec une précision mixte standard et mixte ^ Hi ^ représente la précision mixte adaptée à HiFT . Para représente la mémoire occupée par les paramètres du modèle; GRA représente la mémoire occupée par le dégradé; STA représente la mémoire occupée par l' état d'optimiseur . PGS représente la somme de la mémoire occupée par les paramètres , les gradients et l'état d'optimiseur .
Code source
class FP16_Optimizer(DeepSpeedOptimizer):
def __init__(self,
init_optimizer,
deepspeed=None,
static_loss_scale=1.0,
dynamic_loss_scale=False,
initial_dynamic_scale=2**32,
dynamic_loss_args=None,
verbose=True,
mpu=None,
clip_grad=0.0,
fused_adam_legacy=False,
has_moe_layers=False,
timers=None):
....
self.fp16_groups = []
self.fp16_groups_flat = []
self.fp32_groups_flat = []
...
for i, param_group in enumerate(self.optimizer.param_groups):
...
self.fp32_groups_flat.append(self.fp16_groups_flat[i].clone().float().detach())
...
La mémoire requise pour charger les paramètres 1b est de 3,72 Go (10 ^ 9
Nous réimplémentons l'algorithme de précision mixte pour s'adapter à l'algorithme de réglage fin de HiFT , ce qui garantit que les paramètres de modèle de précision unique n'engagent pas les frais généraux de mémoire GPU supplémentaires.
@article { liu2024hift ,
title = { HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy } ,
author = { Liu, Yongkang and Zhang, Yiqun and Li, Qian and Feng, Shi and Wang, Daling and Zhang, Yifei and Sch{"u}tze, Hinrich } ,
journal = { arXiv preprint arXiv:2401.15207 } ,
year = { 2024 }
}Ce projet accueille les contributions et les suggestions. La plupart des contributions vous obligent à accepter un accord de licence de contributeur (CLA) déclarant que vous avez le droit de faire et en fait, accordez-nous les droits d'utilisation de votre contribution.


