HiFT
1.0.0
يحتوي هذا الريبو على الكود المصدري لحزمة Python HiFT وعدة أمثلة على كيفية دمجها مع نماذج Pytorch ، مثل تلك الموجودة في وجه المعانقة. نحن ندعم فقط Pytorch في الوقت الحالي. انظر ورقتنا للحصول على وصف مفصل لـ · HiFT . يدعم HiFT FPFT من نماذج 7B لأجهزة ذاكرة GPU 24G تحت دقة مختلطة دون استخدام أي تقنيات حفظ الذاكرة ومحسّنات مختلفة بما في ذلك AdamW و AdaGrad و SGD ، إلخ.
HIFT: استراتيجية صقل المعلمة الكاملة التسلسل الهرمي
Yongkang Liu ، Yiqun Zhang ، Qian Li ، Tong Liu ، Shi Feng ، Daling Wang ، Yifei Zhang ، Hinrich Schütze
ورقة: https://arxiv.org/abs/2401.15207
26/1/2024 : نشر النسخة الأولى من مخطوط HiFT
25/2/2024 : نشر الإصدار الثاني من مخطوطات HiFT ورمز المصدر
1/5/2024 : دعم HIFT المحدث لـ LoRA
10/5/2024 : تكييف المحسن الذي توفره Bitsandbytes
13/5/2024*: Adapt Adalora ، LoRA ، IA3 ، P_tuning ، Prefix_tuning ، Prompt_tuning peft.
هناك العديد من الدلائل في هذا الريبو:
hift ، والذي يجب تثبيته لتشغيل الأمثلة التي نقدمها ؛NER المستند إلى HiFT ، QA ، classification ، text generation ، instruction fine-tuning ، وتنفيذ مثال pre-training . تعليمة صقل النموذج 7B على A6000 (48G) ، والنتائج التجريبية تبين أن الحد الأقصى لطول التسلسل المدعوم من HIFT هو 2800. بعد هذا الحد ، قد تحدث مشكلات OOM .
| نموذج | ماكس سيك طول | حجم الدُفعة القصوى |
|---|---|---|
| llama2-7b (الألبكة) | 512 | 8 |
| llama2-7b (Vicuna) | 2800 | 1 |
تعليمات صقل نموذج 7B على RTX3090 (24G). إذا كنت تستخدم وحدات معالجة الرسومات المتعددة للتدريب الموزع على RTX 3090/4000 ، فأضف الأوامر التالية قبل التشغيل: export NCCL_IB_DISABLE=1 ؛ export NCCL_P2P_DISABLE=1
| نموذج | ماكس سيك طول | حجم الدُفعة القصوى |
|---|---|---|
| llama2-7b (الألبكة) | 512 | 3 |
| llama2-7b (Vicuna) | 1400 | 1 |
pytorch > = 2.1.1 ؛ transformers == 4.36.2pip install -r requirements.txtconda install mpi4py==3.1.4pip install flash-attn==2.5.8 hift pip install hifthift ### generation task
from hift import HiFTSeq2SeqTrainer,GetCallBack,peft_function,Seq2SeqTrainer
### classification taks
from hift import HiFTrainer,GetCallBack,PEFTrainer,peft_function
### QA task
from hift import HiFTQuestionAnsweringTrainer,GetCallBack,QuestionAnsweringTrainer,peft_function
HiFT @dataclass
class HiFTArguments(ModelArguments):
HiTaskType: str = field(
default="SEQ_CLS",
metadata={"help": ("HiTaskType should be consistent with PEFT TaskType" )},
)
peft_type: str = field(
default=None,
metadata={"help": ("peft_type should be in [lora,adalora,ia3,p_tuning,prefix_tuning,prompt_tuning]" )},
)
init_text:str = field(
default="Predict if sentiment of this review is positive, negative or neutral",
metadata={
"help": (
"the init prompt text for prompt tuning"
)
},
)
lora_rank: int = field(
default=8,
metadata={"help": ("rank for lora or adalora" )},
)
peft_path : Optional[str] = field(default=None)
virtual_tokens:int = field(
default=20,
metadata={"help": ("the number of virtual tokens for p_tuning, prefix_tuning and prefix_tuning" )},
)
group_element: int = field(
default=1,
metadata={"help": ("number element for each group parameters" )},
)
optimizer_strategy: str = field(
default="down2up",
metadata={"help": ("optimizer strategy of ['down2up','down2up','random']" )},
)
hier_tuning: bool = field(
default=False,
metadata={
"help": (
"hierarchical optimization for LLMS"
)
},
)
freeze_layers: List[str] = field(
default_factory=list,
metadata={
"help": (
"Index of the frozen layer"
)
},
)
يجب أن يكون HitaskType متسقًا مع PEFT TaskType .
تصنيف التسلسل ، مهام الاختيار من متعدد :
TaskType.SEQ_CLSسؤال الإجابة على السؤال:
TaskType.QUESTION_ANSتسلسل تسمية المهمة:
TaskType.TOKEN_CLSمهمة الجيل :
TaskType.CAUSAL_LM
Group_Element : عدد الطبقات المدرجة في كتلة. القيمة الافتراضية هي 1 .
Freeze_layers : الطبقات التي تريد تجميدها أثناء ضبطها. يجب عليك توفير فهرس الطبقة المقابلة. فهرس طبقة التضمين هو 0 ، فهرس الطبقة الأولى هو 1 ، ...
HiFT Trainer يرث HiFT مدرب Huggingface ، بحيث يمكنك استخدام المدرب الذي توفره HIFT مباشرة لاستبدال المدرب الأصلي.
if model_args.hier_tuning:#hier_tuning
trainer = HiFTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
model=model,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator
)
else:
trainer = PEFTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
مهمة QA
if model_args.hier_tuning:
trainer = HiFTQuestionAnsweringTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
else:
trainer = QuestionAnsweringTrainer(
peft_type = model_args.peft_type,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
مهمة التوليد
if model_args.hier_tuning:#hier_tuning
trainer = HiFTSeq2SeqTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
tokenizer=tokenizer,
data_collator=data_collator
)
else:
trainer = Seq2SeqTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
يدعم HiFT أي نموذج. من السهل جدًا التكيف مع HiFT .
- حدد أنواع المهام التي يدعمها النموذج الخاص بك في
TaskTInterface.- يوفر
regular expressionsلطبقةembedding layerوطبقاتheader layersالمهمة المختلفة. الغرض من التعبير العادي هو تحديد اسم طبقة الطبقة المقابلة بشكل فريد.- توفير تعبيرات منتظمة باستثناء تضمين طبقة وطبقة رأس في واجهة
others_pattern.
إن أبسط طريقة هي توفير أسماء الطبقة لجميع الطبقات في واجهة others_pattern ، والواجهات الأخرى تُرجع قائمة فارغة [] . فيما يلي مثال روبرتا.
class RobertaCallBack(HiFTCallBack):
def __init__(self,freeze_layers,strategy,taskType,peft_type=None):
super().__init__(freeze_layers,strategy,taskType,peft_type)
self.TaskTInterface = [TaskType.SEQ_CLS,TaskType.TOKEN_CLS,TaskType.QUESTION_ANS]
self.check_task_type(taskType,"RoBERTa",self.TaskTInterface)
@property
def emb_pattern(self):
if self.peft_type:
return [rf'.embedding.']
else:
return [rf'.embeddings.']
@property
def seq_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def token_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def qa_cls_head(self):
if self.peft_type:
return ["qa_outputs"]
else:
return ["qa_outputs"]
@property
def others_pattern(self):
if self.peft_type:
return [rf'.d+.']
else:
return [rf'.d+.']
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/output_vicuna"
port=$(shuf -i25000-30000 -n1)
#--fsdp "full_shard auto_wrap"
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/vicuna_train.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--optim "lion_32bit"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--data_path data/dummy_conversation.json
--eval_data_path data/sharegpt_clean.json
--output_dir $output_dir/model
--num_train_epochs 3
--do_train
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--evaluation_strategy "steps"
--eval_steps 1500
--save_strategy "steps"
--save_steps 1500
--save_total_limit 8
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0
--lr_scheduler_type "linear"
--logging_steps 10
--model_max_length 2800
--lazy_preprocess True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/instruct_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/instruct_tuning.py
--model_type opt
--HiTaskType "CAUSAL_LM"
--optim "adamw_torch"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path opt-7b
--dataset_dir alpaca_data
--validation_split_percentage 0.01
--per_device_train_batch_size 12
--per_device_eval_batch_size 8
--do_train
--do_eval
--seed 12345
--fp16
--tf32 true
--num_train_epochs 1
--lr_scheduler_type "cosine"
--learning_rate 1e-5
--warmup_ratio 0.0
--weight_decay 0.0
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--evaluation_strategy steps
--eval_steps 100
--save_steps 200
--preprocessing_num_workers 4
--max_seq_length 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### This is just a demo. Please adjust the parameters based on your data.
export num_gpus=8
export output_dir="outputs/pretrain_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES=0 torchrun --master_port "$port" examples/pretrain_tuning.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path llama2-7b
--dataset_dir "data"
--data_cache_dir "data_cache_dir"
--validation_split_percentage 0.001
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--do_train
--seed 12345
--fp16
--max_steps 1000
--lr_scheduler_type cosine
--learning_rate 1e-5
--warmup_ratio 0.05
--weight_decay 0.01
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--save_steps 500
--preprocessing_num_workers 8
--block_size 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--hier_tuning
--group_element $1
--optimizer_strategy $2
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
# CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" python -m torch.distributed.launch --nproc_per_node=$num_gpus run_glue.py
CUDA_VISIBLE_DEVICES=7 torchrun --master_port "$port" examples/run_generation.py
--model_name_or_path llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--padding_side "left"
--group_by_length
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--weight_decay 0
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/run_generation.py
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--deepspeed "dsconfig/zero0_config.json"
--padding_side "left"
--group_by_length
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--hier_tuning
--weight_decay 0
--group_element $1
--optimizer_strategy $2
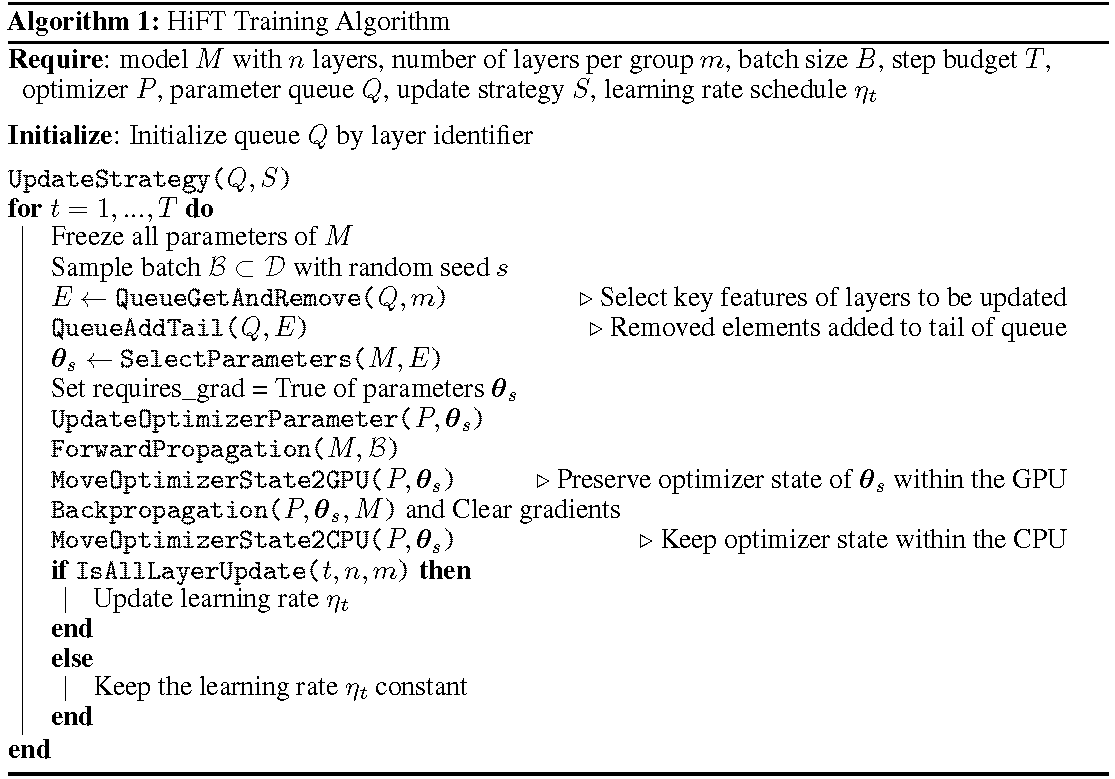
تظهر عملية التدريب التفصيلية في الخوارزمية. الخطوة الأولى هي تحديد استراتيجية التحديث. ثم تجميد جميع الطبقات. الطبقات المراد تحديثها ، تدل عليها
يقوم HiFT بشكل تكراري بتحديث مجموعة فرعية من المعلمات في كل خطوة تدريب ، وسوف يعدل المعلمة الكاملة بعد خطوات متعددة. هذا يقلل بشكل كبير من متطلبات ذاكرة GPU لنماذج لغة الاستثارة التي تتيح التبديل الفعال للمهمة أثناء النشر كل ذلك دون إدخال زمن استنتاج. يتفوق HIFT أيضًا على العديد من أساليب التكيف الأخرى بما في ذلك المحول ، وضبط البادئة ، والضبط.
HiFT عبارة عن طريقة صقل معلمة مستقلة عن النموذج ومحسّنة مستقلة والتي يمكن دمجها مع طريقة PEFT.
المُحسّنات : يتم تكييف أحدث إصدار من HiFT مع مُحسّنات Adam و AdamW و SGD و Adafactor و Adagrad .
النموذج : يدعم أحدث إصدار من HiFT BERT و RoBERTa و GPT-2 و GPTNeo و GPT-NeoX و OPT و LLaMA-based .
تجارب على OPT-13B (مع 1000 أمثلة). ICL : التعلم داخل السياق ؛ LP : التحقيق الخطي ؛ FPFT : صقل كامل كامل. بادئة: بادئة ضبط. تستخدم جميع التجارب مطالبات من Mezo.
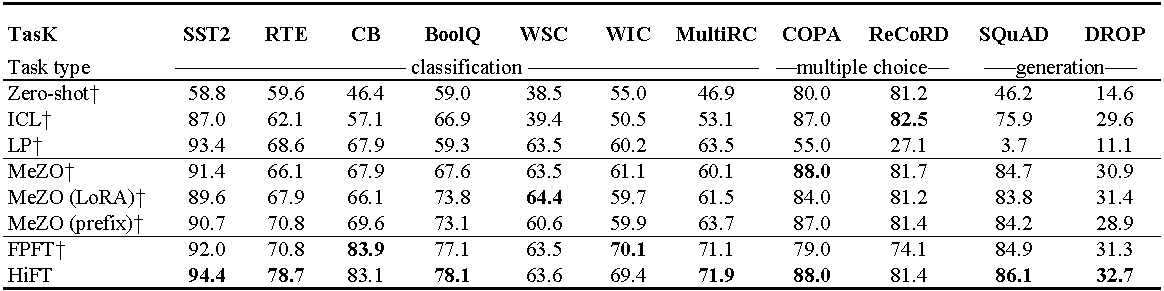
استخدام ذاكرة GPU من صقل لاما (7 ب) على مجموعة بيانات E2E . يمثل المجموع إجمالي الذاكرة المستخدمة أثناء الضبط الدقيق. يمثل المختلط صقلًا دقيقًا بدقة مختلطة قياسية ومختلطة^ hi^ يمثل الدقة المختلطة المكيفة مع HiFT . تمثل الفقرة الذاكرة التي تشغلها معلمات النموذج ؛ يمثل GRA الذاكرة التي يشغلها التدرج ؛ يمثل STA الذاكرة التي تشغلها حالة المحسن . يمثل PGS مجموع الذاكرة التي تشغلها المعلمات والتدرجات وحالة المُحسّنة .
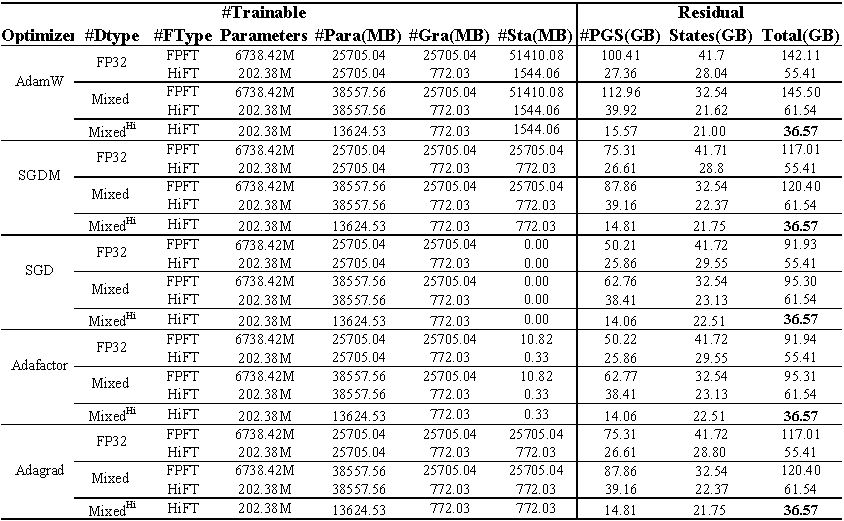
رمز المصدر
class FP16_Optimizer(DeepSpeedOptimizer):
def __init__(self,
init_optimizer,
deepspeed=None,
static_loss_scale=1.0,
dynamic_loss_scale=False,
initial_dynamic_scale=2**32,
dynamic_loss_args=None,
verbose=True,
mpu=None,
clip_grad=0.0,
fused_adam_legacy=False,
has_moe_layers=False,
timers=None):
....
self.fp16_groups = []
self.fp16_groups_flat = []
self.fp32_groups_flat = []
...
for i, param_group in enumerate(self.optimizer.param_groups):
...
self.fp32_groups_flat.append(self.fp16_groups_flat[i].clone().float().detach())
...
الذاكرة المطلوبة لتحميل معلمات 1B هي 3.72 جيجابايت (10^9
نحن نعيد تنفيذ خوارزمية الدقة المختلطة للتكيف مع خوارزمية ضبط HiFT الدقيقة ، والتي تضمن أن معلمات نموذج الدقة الواحدة لا تتحمل النفقات العامة لذاكرة GPU إضافية.
@article { liu2024hift ,
title = { HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy } ,
author = { Liu, Yongkang and Zhang, Yiqun and Li, Qian and Feng, Shi and Wang, Daling and Zhang, Yifei and Sch{"u}tze, Hinrich } ,
journal = { arXiv preprint arXiv:2401.15207 } ,
year = { 2024 }
}يرحب هذا المشروع بالمساهمات والاقتراحات. تطلب منك معظم المساهمات الموافقة على اتفاقية ترخيص المساهم (CLA) مع إعلان أن لديك الحق في ذلك في الواقع ، ويفعلنا في الواقع حقوق استخدام مساهمتك.


