HiFT
1.0.0
Этот репо содержит исходный код HiFT пакета Python и несколько примеров того, как интегрировать его с моделями Pytorch, например, в обнимающем лицо. Мы только поддерживаем Pytorch. Смотрите нашу статью для подробного описания · HiFT . HiFT поддерживает FPFT моделей 7B для устройств памяти 24G GPU под смешанной точностью без использования каких -либо методов сохранения памяти и различных оптимизаторов, включая AdamW , AdaGrad , SGD и т. Д.
Hift: иерархическая полная стратегия точной настройки параметров
Yongkang Liu, Yiqun Zhang, Qian Li, Tong Liu, Shi Feng, Daling Wang, Yifei Zhang, Hinrich Schütze
Бумага: https://arxiv.org/abs/2401.15207
26/1/2024 : опубликовать первую версию HiFT Manuscript
25/2/2024 : опубликовать вторую версию рукописи HiFT и исходного кода
1/5/2024 : Обновленная поддержка HIFT для LoRA
05.10.2024 : адаптируйте оптимизатор, предоставленный BitsAndbytes
13/5/2024*: адаптировать Adalora , LoRA , IA3 , P_tuning , Prefix_tuning , Prompt_tuning PEFT Метод PEFT.
В этом репо есть несколько каталогов:
hift пакета, который необходимо установить для запуска приведенных нами примеров;HiFT на основе NER , QA , classification , text generation , instruction fine-tuning и пример pre-training . Инструкция тонкая настройка 7B модели на A6000 (48G), и экспериментальные результаты показывают, что максимальная длина последовательности, поддерживаемая HIFT, составляет 2800. Помимо этого предела, могут возникнуть проблемы OOM .
| Модель | Максимальная длина SEQ | Максимальный размер партии |
|---|---|---|
| Llama2-7B (альпака) | 512 | 8 |
| Llama2-7B (Vicuna) | 2800 | 1 |
Инструкция тонкая настройка 7B Модель на RTX3090 (24G). Если вы используете несколько графических процессоров для распределенного обучения на RTX 3090/4000 , добавьте следующие команды перед запуском: export NCCL_IB_DISABLE=1 ; export NCCL_P2P_DISABLE=1
| Модель | Максимальная длина SEQ | Максимальный размер партии |
|---|---|---|
| Llama2-7B (альпака) | 512 | 3 |
| Llama2-7B (Vicuna) | 1400 | 1 |
pytorch > = 2,1,1; transformers == 4.36.2pip install -r requirements.txtconda install mpi4py==3.1.4pip install flash-attn==2.5.8 hift pip install hifthift ### generation task
from hift import HiFTSeq2SeqTrainer,GetCallBack,peft_function,Seq2SeqTrainer
### classification taks
from hift import HiFTrainer,GetCallBack,PEFTrainer,peft_function
### QA task
from hift import HiFTQuestionAnsweringTrainer,GetCallBack,QuestionAnsweringTrainer,peft_function
HiFT @dataclass
class HiFTArguments(ModelArguments):
HiTaskType: str = field(
default="SEQ_CLS",
metadata={"help": ("HiTaskType should be consistent with PEFT TaskType" )},
)
peft_type: str = field(
default=None,
metadata={"help": ("peft_type should be in [lora,adalora,ia3,p_tuning,prefix_tuning,prompt_tuning]" )},
)
init_text:str = field(
default="Predict if sentiment of this review is positive, negative or neutral",
metadata={
"help": (
"the init prompt text for prompt tuning"
)
},
)
lora_rank: int = field(
default=8,
metadata={"help": ("rank for lora or adalora" )},
)
peft_path : Optional[str] = field(default=None)
virtual_tokens:int = field(
default=20,
metadata={"help": ("the number of virtual tokens for p_tuning, prefix_tuning and prefix_tuning" )},
)
group_element: int = field(
default=1,
metadata={"help": ("number element for each group parameters" )},
)
optimizer_strategy: str = field(
default="down2up",
metadata={"help": ("optimizer strategy of ['down2up','down2up','random']" )},
)
hier_tuning: bool = field(
default=False,
metadata={
"help": (
"hierarchical optimization for LLMS"
)
},
)
freeze_layers: List[str] = field(
default_factory=list,
metadata={
"help": (
"Index of the frozen layer"
)
},
)
HitaskType должен соответствовать PEFT Tasktype .
Классификация последовательности , задачи с множественным выбором :
TaskType.SEQ_CLSЗадача ответа на вопрос :
TaskType.QUESTION_ANSЗадача маркировки последовательности :
TaskType.TOKEN_CLSЗадача генерации :
TaskType.CAUSAL_LM
Group_Element : количество слоев, включенных в блок. Значение по умолчанию 1 .
freeze_layers : слои, которые вы хотите заморозить во время точной настройки. Вы должны предоставить индекс соответствующего слоя. Индекс встроенного слоя равен 0 , индекс первого слоя составляет 1 , ...
HiFT HiFT наследует тренер Huggingface, поэтому вы можете напрямую использовать тренер, предоставленный Hift, чтобы заменить оригинального тренера.
if model_args.hier_tuning:#hier_tuning
trainer = HiFTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
model=model,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator
)
else:
trainer = PEFTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
QA Задача
if model_args.hier_tuning:
trainer = HiFTQuestionAnsweringTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
else:
trainer = QuestionAnsweringTrainer(
peft_type = model_args.peft_type,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
Задача поколения
if model_args.hier_tuning:#hier_tuning
trainer = HiFTSeq2SeqTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
tokenizer=tokenizer,
data_collator=data_collator
)
else:
trainer = Seq2SeqTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
HiFT поддерживает любую модель. Это очень легко адаптироваться к HiFT .
- Определите типы задач, поддерживаемые вашей моделью в
TaskTInterface.- Обеспечивает
regular expressionsдляembedding layerи различныхheader layersзадач. Цель регулярного выражения - однозначно идентифицировать название слоя соответствующего слоя.- Обеспечить регулярные выражения, за исключением встраивания слоя и слоя заголовка в интерфейс
others_pattern.
Самый простой способ состоит в том, чтобы предоставить имена слоев для всех слоев в интерфейсе others_pattern , а другие интерфейсы возвращают пустой список [] . Ниже приведен пример Роберты.
class RobertaCallBack(HiFTCallBack):
def __init__(self,freeze_layers,strategy,taskType,peft_type=None):
super().__init__(freeze_layers,strategy,taskType,peft_type)
self.TaskTInterface = [TaskType.SEQ_CLS,TaskType.TOKEN_CLS,TaskType.QUESTION_ANS]
self.check_task_type(taskType,"RoBERTa",self.TaskTInterface)
@property
def emb_pattern(self):
if self.peft_type:
return [rf'.embedding.']
else:
return [rf'.embeddings.']
@property
def seq_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def token_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def qa_cls_head(self):
if self.peft_type:
return ["qa_outputs"]
else:
return ["qa_outputs"]
@property
def others_pattern(self):
if self.peft_type:
return [rf'.d+.']
else:
return [rf'.d+.']
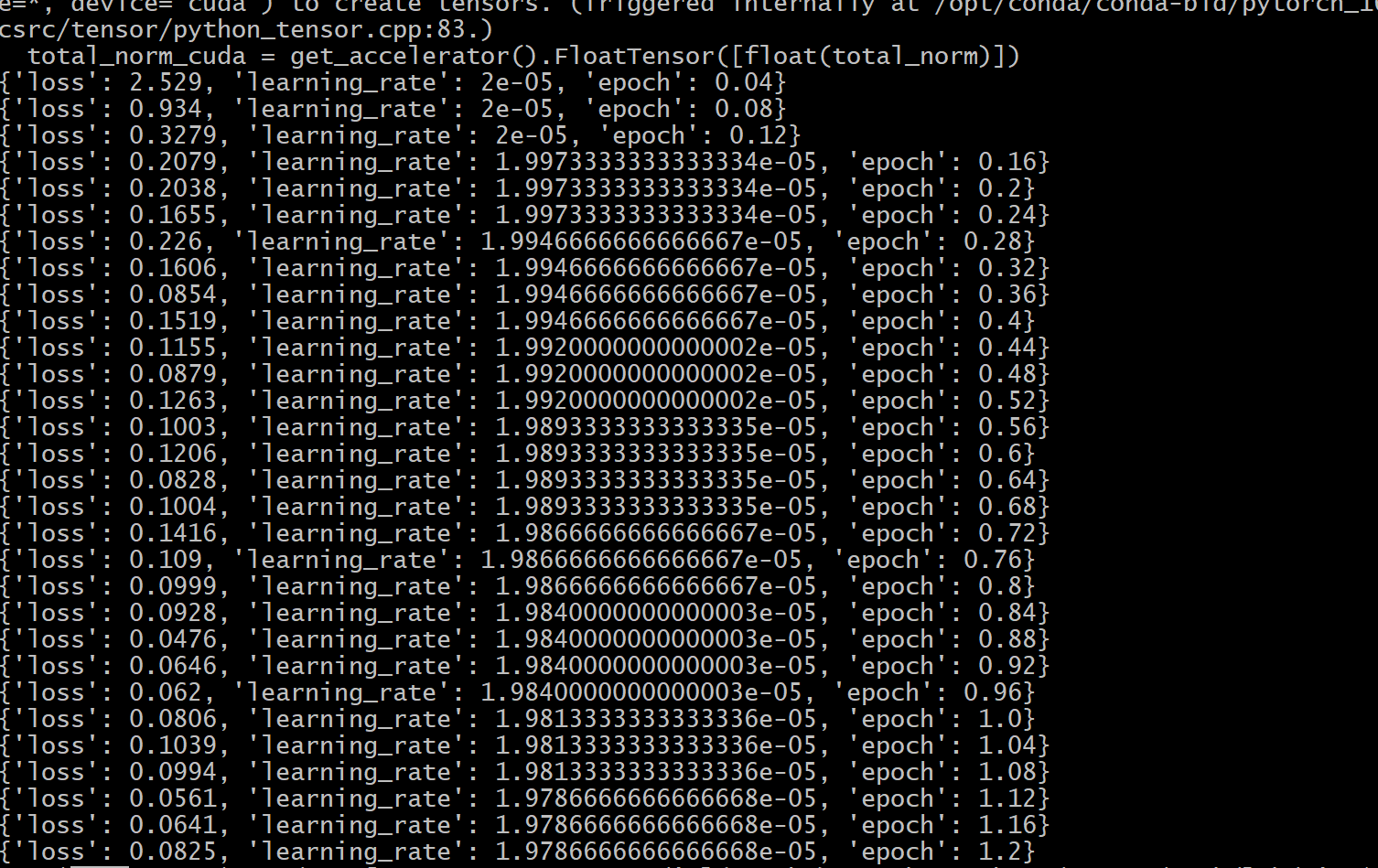
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/output_vicuna"
port=$(shuf -i25000-30000 -n1)
#--fsdp "full_shard auto_wrap"
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/vicuna_train.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--optim "lion_32bit"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--data_path data/dummy_conversation.json
--eval_data_path data/sharegpt_clean.json
--output_dir $output_dir/model
--num_train_epochs 3
--do_train
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--evaluation_strategy "steps"
--eval_steps 1500
--save_strategy "steps"
--save_steps 1500
--save_total_limit 8
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0
--lr_scheduler_type "linear"
--logging_steps 10
--model_max_length 2800
--lazy_preprocess True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
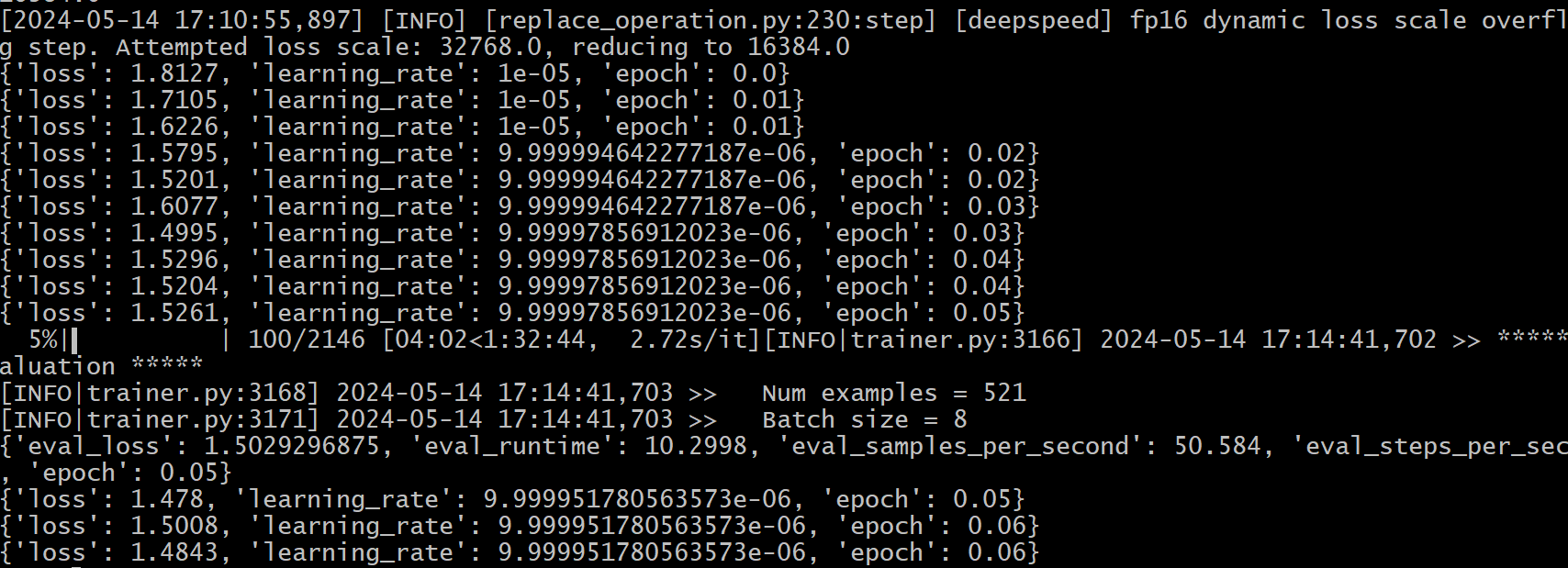
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/instruct_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/instruct_tuning.py
--model_type opt
--HiTaskType "CAUSAL_LM"
--optim "adamw_torch"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path opt-7b
--dataset_dir alpaca_data
--validation_split_percentage 0.01
--per_device_train_batch_size 12
--per_device_eval_batch_size 8
--do_train
--do_eval
--seed 12345
--fp16
--tf32 true
--num_train_epochs 1
--lr_scheduler_type "cosine"
--learning_rate 1e-5
--warmup_ratio 0.0
--weight_decay 0.0
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--evaluation_strategy steps
--eval_steps 100
--save_steps 200
--preprocessing_num_workers 4
--max_seq_length 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
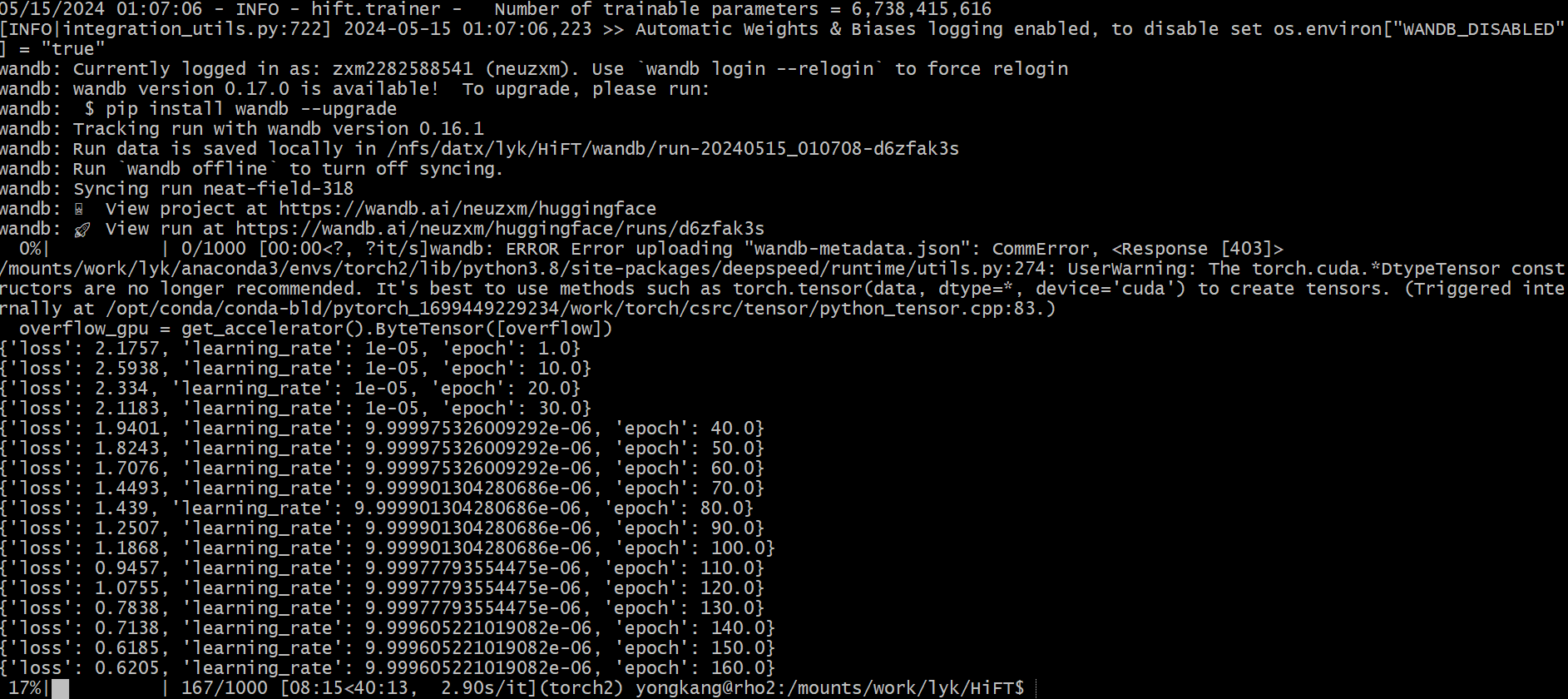
### This is just a demo. Please adjust the parameters based on your data.
export num_gpus=8
export output_dir="outputs/pretrain_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES=0 torchrun --master_port "$port" examples/pretrain_tuning.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path llama2-7b
--dataset_dir "data"
--data_cache_dir "data_cache_dir"
--validation_split_percentage 0.001
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--do_train
--seed 12345
--fp16
--max_steps 1000
--lr_scheduler_type cosine
--learning_rate 1e-5
--warmup_ratio 0.05
--weight_decay 0.01
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--save_steps 500
--preprocessing_num_workers 8
--block_size 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--hier_tuning
--group_element $1
--optimizer_strategy $2
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
# CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" python -m torch.distributed.launch --nproc_per_node=$num_gpus run_glue.py
CUDA_VISIBLE_DEVICES=7 torchrun --master_port "$port" examples/run_generation.py
--model_name_or_path llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--padding_side "left"
--group_by_length
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--weight_decay 0
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/run_generation.py
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--deepspeed "dsconfig/zero0_config.json"
--padding_side "left"
--group_by_length
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--hier_tuning
--weight_decay 0
--group_element $1
--optimizer_strategy $2
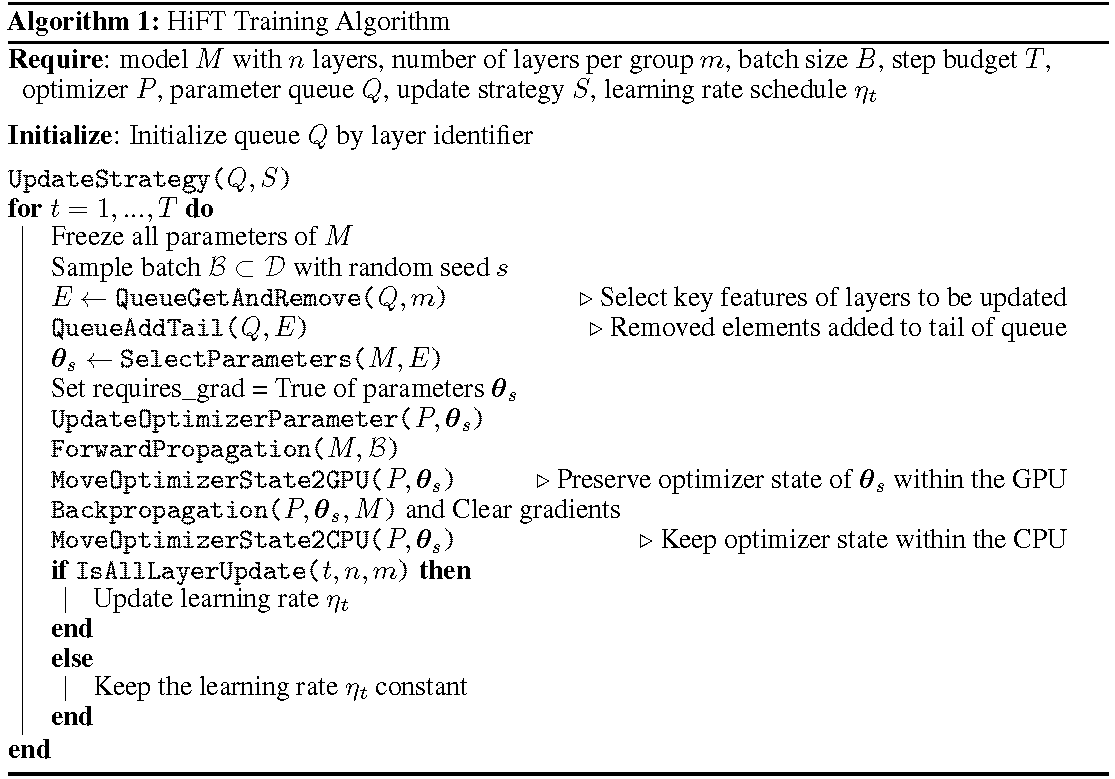
Подробный процесс обучения показан в алгоритме. Первым шагом является определение стратегии обновления. Затем заморозить все слои. Слои, которые должны быть обновлены, обозначены
HiFT обновляет подмножество параметров на каждом этапе обучения, и он будет изменять полный параметр после нескольких шагов. Это значительно уменьшает требования к памяти графического процессора для моделей языка с тонкой настройкой, обеспечивая эффективное переключение задач во время развертывания без введения задержки вывода. Hift также превосходит несколько других методов адаптации, включая адаптер, настройку префикса и тонкую настройку.
HiFT -это независимый от модели и независимый от оптимизатора метод точной настройки, который может быть интегрирован с методом PEFT.
Оптимизаторы : последняя версия HiFT адаптирована к оптимизаторам Adam , AdamW , SGD , Adafactor и Adagrad .
Модель : Последняя версия HiFT поддерживает модели BERT , RoBERTa , GPT-2 , GPTNeo , GPT-NeoX , OPT и LLaMA-based .
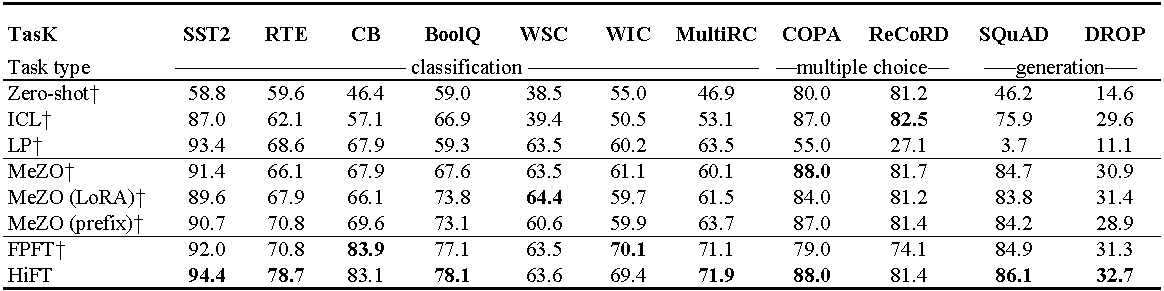
Эксперименты на OPT-13B (с 1000 примеров). ICL : In-Context Learning; LP : линейное зондирование; FPFT : полная точная настройка; Префикс: настройка префикса. Все эксперименты используют подсказки от Mezo.
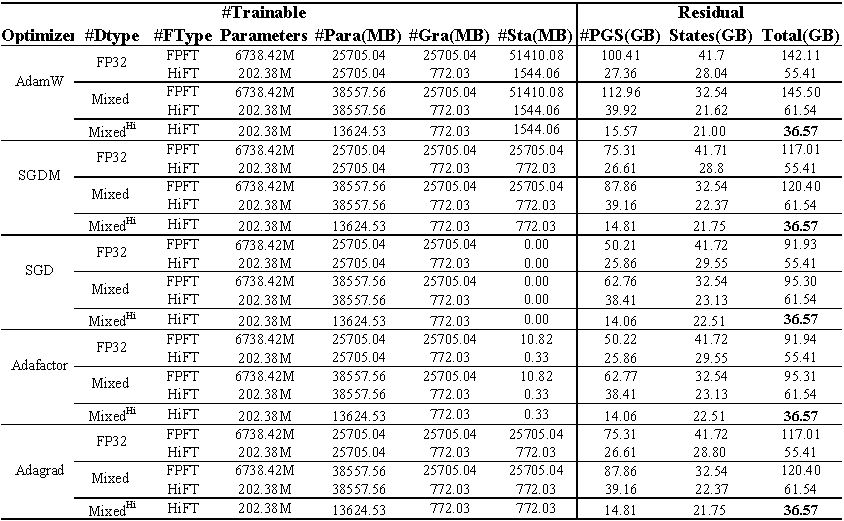
Использование памяти графического процессора с тонкой настройкой ламы (7b) в наборе данных E2E . Всего представляет общую память, используемую во время точной настройки. Смешанный представляет тонкую настройку со стандартной смешанной точностью , а смешанный^ hi^ представляет смешанную точность, адаптированную к HiFT . PARA представляет память, занятую параметрами модели; GRA представляет память, занятую градиентом; STA представляет память, занятую состоянием оптимизатора . PGS представляет сумму памяти, занятой параметрами , градиентами и состоянием оптимизатора .
Исходный код
class FP16_Optimizer(DeepSpeedOptimizer):
def __init__(self,
init_optimizer,
deepspeed=None,
static_loss_scale=1.0,
dynamic_loss_scale=False,
initial_dynamic_scale=2**32,
dynamic_loss_args=None,
verbose=True,
mpu=None,
clip_grad=0.0,
fused_adam_legacy=False,
has_moe_layers=False,
timers=None):
....
self.fp16_groups = []
self.fp16_groups_flat = []
self.fp32_groups_flat = []
...
for i, param_group in enumerate(self.optimizer.param_groups):
...
self.fp32_groups_flat.append(self.fp16_groups_flat[i].clone().float().detach())
...
Память, необходимая для загрузки параметров 1b , составляет 3,72 ГБ (10^9
Мы переопределяем алгоритм смешанного назначения, чтобы адаптироваться к алгоритму тонкоостренной настройки HiFT , который гарантирует, что параметры модели с одной реакцией не требуют дополнительных накладных расходов памяти графического процессора.
@article { liu2024hift ,
title = { HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy } ,
author = { Liu, Yongkang and Zhang, Yiqun and Li, Qian and Feng, Shi and Wang, Daling and Zhang, Yifei and Sch{"u}tze, Hinrich } ,
journal = { arXiv preprint arXiv:2401.15207 } ,
year = { 2024 }
}Этот проект приветствует вклады и предложения. Большинство взносов требуют, чтобы вы согласились с лицензионным соглашением о участнике (CLA), заявив, что вы имеете право и фактически предоставить нам права на использование вашего вклада.


