HiFT
1.0.0
このレポは、PythonパッケージHiFTのソースコードと、それを抱きしめているようなPytorchモデルと統合する方法のいくつかの例が含まれています。今のところPytorchのみをサポートしています。 HiFTの詳細な説明については、私たちの論文を参照してください。 HiFT 、メモリ保存技術やAdamW 、 AdaGrad 、 SGDなどを含むさまざまなオプティマイザーを使用せずに、24g GPUメモリデバイスの7BモデルのFPFTを混合精度下でサポートします。
HIFT:階層的な完全なパラメーター微調整戦略
Yongkang Liu、Yiqun Zhang、Qian Li、Tong Liu、Shi Feng、Daling Wang、Yifei Zhang、HinrichSchütze
論文:https://arxiv.org/abs/2401.15207
26/1/2024 : HiFT原稿の最初のバージョンを公開します
25/2/2024 : HiFT原稿とソースコードの2番目のバージョンを公開
1/5/2024 : LoRAのHIFTサポートを更新しました
10/5/2024 :bitsandbytesが提供するオプティマイザーを適応させます
13/5/2024*: Adalora 、 LoRA 、 IA3 、 P_tuning 、 Prefix_tuning 、 Prompt_tuning PEFTメソッドを適応させます。
このリポジトリにはいくつかのディレクトリがあります。
hiftのソースコードを含みます。これは、提供する例を実行するためにインストールする必要があります。HiFTベースのNER 、 QA 、 classification 、 text generation 、 instruction fine-tuning 、およびpre-trainingの実装が含まれています。A6000(48G)の微調整7Bモデルと実験結果は、HIFTでサポートされている最大シーケンス長が2800であることを示しています。この制限を超えると、 OOM問題が発生する可能性があります。
| モデル | 最大seqの長さ | 最大バッチサイズ |
|---|---|---|
| llama2-7b(alpaca) | 512 | 8 |
| llama2-7b(vicuna) | 2800 | 1 |
rtx3090(24g)の微調整7bモデル。 RTX 3090/4000で分散トレーニングに複数のGPUを使用する場合は、実行する前に次のコマンドを追加しますexport NCCL_IB_DISABLE=1 ; export NCCL_P2P_DISABLE=1
| モデル | 最大seqの長さ | 最大バッチサイズ |
|---|---|---|
| llama2-7b(alpaca) | 512 | 3 |
| llama2-7b(vicuna) | 1400 | 1 |
pytorch > = 2.1.1; transformers == 4.36.2pip install -r requirements.txtconda install mpi4py==3.1.4pip install flash-attn==2.5.8 hiftのインストールpip install hifthiftパッケージをインポートします ### generation task
from hift import HiFTSeq2SeqTrainer,GetCallBack,peft_function,Seq2SeqTrainer
### classification taks
from hift import HiFTrainer,GetCallBack,PEFTrainer,peft_function
### QA task
from hift import HiFTQuestionAnsweringTrainer,GetCallBack,QuestionAnsweringTrainer,peft_function
HiFT構成を追加します @dataclass
class HiFTArguments(ModelArguments):
HiTaskType: str = field(
default="SEQ_CLS",
metadata={"help": ("HiTaskType should be consistent with PEFT TaskType" )},
)
peft_type: str = field(
default=None,
metadata={"help": ("peft_type should be in [lora,adalora,ia3,p_tuning,prefix_tuning,prompt_tuning]" )},
)
init_text:str = field(
default="Predict if sentiment of this review is positive, negative or neutral",
metadata={
"help": (
"the init prompt text for prompt tuning"
)
},
)
lora_rank: int = field(
default=8,
metadata={"help": ("rank for lora or adalora" )},
)
peft_path : Optional[str] = field(default=None)
virtual_tokens:int = field(
default=20,
metadata={"help": ("the number of virtual tokens for p_tuning, prefix_tuning and prefix_tuning" )},
)
group_element: int = field(
default=1,
metadata={"help": ("number element for each group parameters" )},
)
optimizer_strategy: str = field(
default="down2up",
metadata={"help": ("optimizer strategy of ['down2up','down2up','random']" )},
)
hier_tuning: bool = field(
default=False,
metadata={
"help": (
"hierarchical optimization for LLMS"
)
},
)
freeze_layers: List[str] = field(
default_factory=list,
metadata={
"help": (
"Index of the frozen layer"
)
},
)
hitaskTypeは、 PEFT taskTypeと一致する必要があります。
シーケンス分類、複数選択タスク:
TaskType.SEQ_CLS質問に答えるタスク:
TaskType.QUESTION_ANSシーケンスラベル付けタスク:
TaskType.TOKEN_CLS生成タスク:
TaskType.CAUSAL_LM
Group_Element :ブロックに含まれるレイヤー数。デフォルト値は1です。
freeze_layers :微調整中にフリーズしたいレイヤー。対応するレイヤーのインデックスを提供する必要があります。埋め込み層のインデックスは0 、最初のレイヤーのインデックスは1 、...
HiFTトレーナーを使用しますHiFT Huggingfaceのトレーナーを継承するため、Hiftが提供するトレーナーを直接使用して元のトレーナーを交換できます。
if model_args.hier_tuning:#hier_tuning
trainer = HiFTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
model=model,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator
)
else:
trainer = PEFTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
QAタスク
if model_args.hier_tuning:
trainer = HiFTQuestionAnsweringTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
else:
trainer = QuestionAnsweringTrainer(
peft_type = model_args.peft_type,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
生成タスク
if model_args.hier_tuning:#hier_tuning
trainer = HiFTSeq2SeqTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
tokenizer=tokenizer,
data_collator=data_collator
)
else:
trainer = Seq2SeqTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
HiFTあらゆるモデルをサポートします。 HiFTに適応するのは非常に簡単です。
TaskTInterfaceでモデルによってサポートされているタスクタイプを定義します。embedding layerとさまざまなタスクheader layersのregular expressionsを提供します。正規表現の目的は、対応するレイヤーのレイヤー名を一意に識別することです。others_patternインターフェイスに埋め込み層とヘッダー層を除く正規表現を提供します。
最も簡単な方法は、 others_patternインターフェイスのすべてのレイヤーのレイヤー名を提供することであり、他のインターフェイスは空のリスト[]を返します。以下はロベルタの例です。
class RobertaCallBack(HiFTCallBack):
def __init__(self,freeze_layers,strategy,taskType,peft_type=None):
super().__init__(freeze_layers,strategy,taskType,peft_type)
self.TaskTInterface = [TaskType.SEQ_CLS,TaskType.TOKEN_CLS,TaskType.QUESTION_ANS]
self.check_task_type(taskType,"RoBERTa",self.TaskTInterface)
@property
def emb_pattern(self):
if self.peft_type:
return [rf'.embedding.']
else:
return [rf'.embeddings.']
@property
def seq_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def token_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def qa_cls_head(self):
if self.peft_type:
return ["qa_outputs"]
else:
return ["qa_outputs"]
@property
def others_pattern(self):
if self.peft_type:
return [rf'.d+.']
else:
return [rf'.d+.']
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/output_vicuna"
port=$(shuf -i25000-30000 -n1)
#--fsdp "full_shard auto_wrap"
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/vicuna_train.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--optim "lion_32bit"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--data_path data/dummy_conversation.json
--eval_data_path data/sharegpt_clean.json
--output_dir $output_dir/model
--num_train_epochs 3
--do_train
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--evaluation_strategy "steps"
--eval_steps 1500
--save_strategy "steps"
--save_steps 1500
--save_total_limit 8
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0
--lr_scheduler_type "linear"
--logging_steps 10
--model_max_length 2800
--lazy_preprocess True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/instruct_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/instruct_tuning.py
--model_type opt
--HiTaskType "CAUSAL_LM"
--optim "adamw_torch"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path opt-7b
--dataset_dir alpaca_data
--validation_split_percentage 0.01
--per_device_train_batch_size 12
--per_device_eval_batch_size 8
--do_train
--do_eval
--seed 12345
--fp16
--tf32 true
--num_train_epochs 1
--lr_scheduler_type "cosine"
--learning_rate 1e-5
--warmup_ratio 0.0
--weight_decay 0.0
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--evaluation_strategy steps
--eval_steps 100
--save_steps 200
--preprocessing_num_workers 4
--max_seq_length 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### This is just a demo. Please adjust the parameters based on your data.
export num_gpus=8
export output_dir="outputs/pretrain_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES=0 torchrun --master_port "$port" examples/pretrain_tuning.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path llama2-7b
--dataset_dir "data"
--data_cache_dir "data_cache_dir"
--validation_split_percentage 0.001
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--do_train
--seed 12345
--fp16
--max_steps 1000
--lr_scheduler_type cosine
--learning_rate 1e-5
--warmup_ratio 0.05
--weight_decay 0.01
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--save_steps 500
--preprocessing_num_workers 8
--block_size 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--hier_tuning
--group_element $1
--optimizer_strategy $2
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
# CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" python -m torch.distributed.launch --nproc_per_node=$num_gpus run_glue.py
CUDA_VISIBLE_DEVICES=7 torchrun --master_port "$port" examples/run_generation.py
--model_name_or_path llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--padding_side "left"
--group_by_length
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--weight_decay 0
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/run_generation.py
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--deepspeed "dsconfig/zero0_config.json"
--padding_side "left"
--group_by_length
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--hier_tuning
--weight_decay 0
--group_element $1
--optimizer_strategy $2
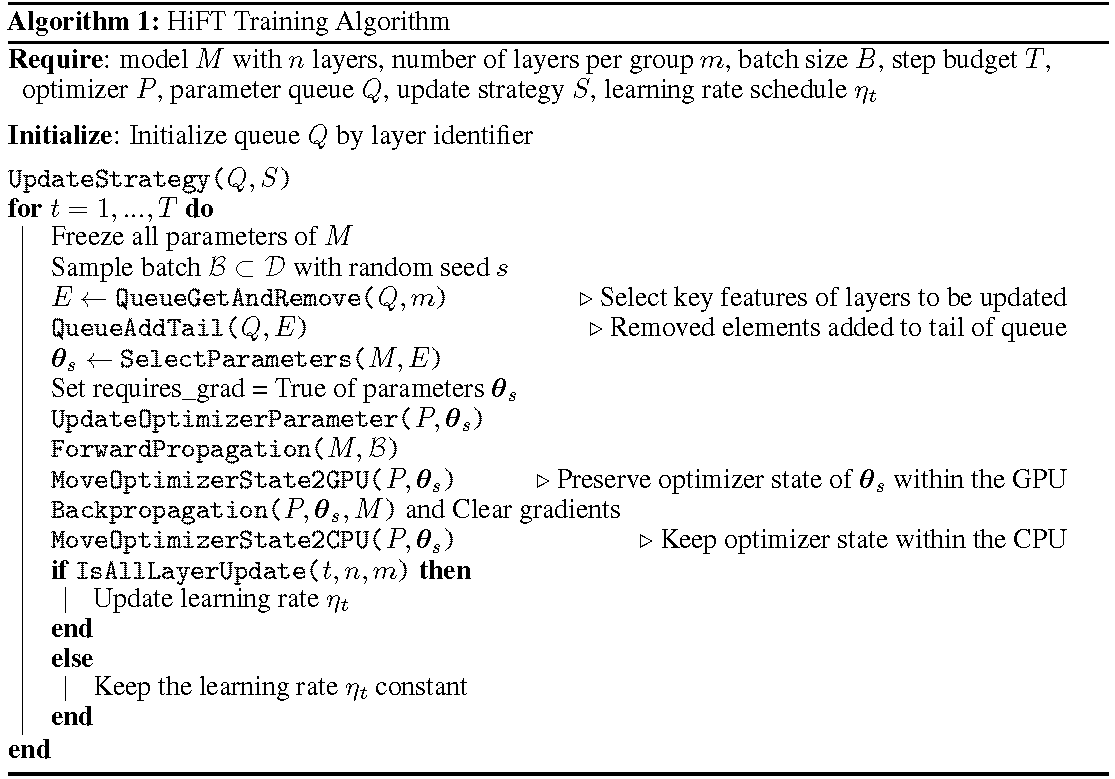
詳細なトレーニングプロセスはアルゴリズムに示されています。最初のステップは、更新戦略を決定することです。次に、すべてのレイヤーをフリーズします。更新されるレイヤー、で示されます
HiFT 、各トレーニングステップでパラメーターのサブセットを繰り返し更新すると、複数のステップの後に完全なパラメーターを変更します。これにより、微調整large言語モデルのGPUメモリ要件が大幅に削減され、推論のレイテンシを導入することなく、展開中に効率的なタスクスイッチングが可能になります。 Hiftは、アダプター、プレフィックス調整、微調整など、他のいくつかの適応方法も上回っています。
HiFT 、PEFTメソッドと統合できるモデルに依存しないオプティマイザーに依存しないフルパラメーター微調整方法です。
オプティマイザー: HiFTの最新バージョンは、 Adam 、 AdamW 、 SGD 、 Adafactor 、 Adagrad Optimizersに適合しています。
モデル: HiFTの最新バージョンは、 BERT 、 RoBERTa 、 GPT-2 、 GPTNeo 、 GPT-NeoX 、 OPTおよびLLaMA-basedモデルをサポートしています。
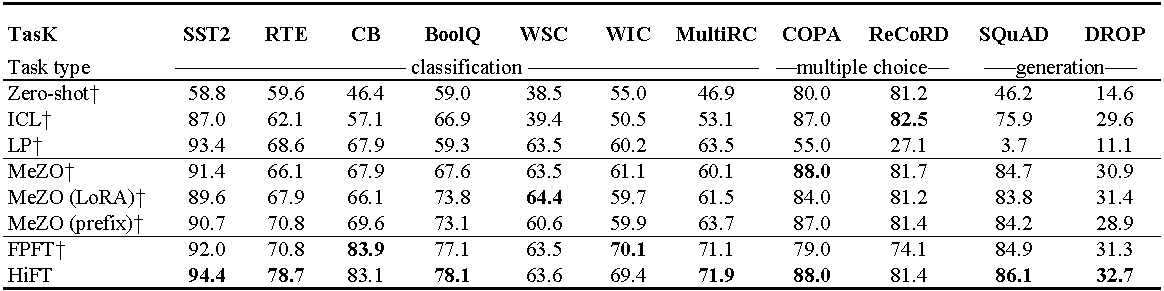
OPT-13Bでの実験(1000の例を使用)。 ICL :コンテキスト学習。 LP :線形調査。 FPFT :完全な微調整。プレフィックス:プレフィックスチューニング。すべての実験では、メゾのプロンプトが使用されます。
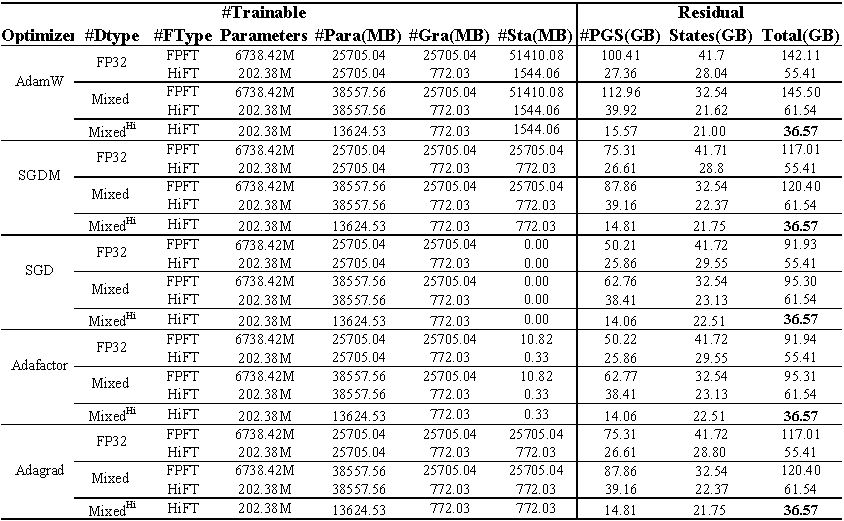
E2Eデータセットでの微調整llama(7b)のGPUメモリ使用。合計は、微調整中に使用される総メモリを表します。混合は、標準の混合精度と混合^ hi^を微調整することを表します^ hi^は、 HiFTに適合した混合精度を表します。 PARAは、モデルパラメーターで占めるメモリを表します。 GRAは、勾配が占めるメモリを表します。 STAは、オプティマイザー状態が占めるメモリを表します。 PGSは、パラメーター、勾配、およびオプティマイザー状態で占めるメモリの合計を表します。
ソースコード
class FP16_Optimizer(DeepSpeedOptimizer):
def __init__(self,
init_optimizer,
deepspeed=None,
static_loss_scale=1.0,
dynamic_loss_scale=False,
initial_dynamic_scale=2**32,
dynamic_loss_args=None,
verbose=True,
mpu=None,
clip_grad=0.0,
fused_adam_legacy=False,
has_moe_layers=False,
timers=None):
....
self.fp16_groups = []
self.fp16_groups_flat = []
self.fp32_groups_flat = []
...
for i, param_group in enumerate(self.optimizer.param_groups):
...
self.fp32_groups_flat.append(self.fp16_groups_flat[i].clone().float().detach())
...
1Bパラメーターをロードするために必要なメモリは3.72GB (10^9です
HiFTの微調整アルゴリズムに適応するために混合精度のアルゴリズムを再実装します。これにより、単一の精度モデルパラメーターが追加のGPUメモリオーバーヘッドが発生しないようにします。
@article { liu2024hift ,
title = { HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy } ,
author = { Liu, Yongkang and Zhang, Yiqun and Li, Qian and Feng, Shi and Wang, Daling and Zhang, Yifei and Sch{"u}tze, Hinrich } ,
journal = { arXiv preprint arXiv:2401.15207 } ,
year = { 2024 }
}このプロジェクトは、貢献と提案を歓迎します。ほとんどの貢献では、貢献者ライセンス契約(CLA)に同意する必要があります。


