HiFT
1.0.0
Dieses Repo enthält den Quellcode des Python -Paket HiFT und mehrere Beispiele für die Integration in Pytorch -Modelle, wie z. B. die im Umarmungsgesicht. Wir unterstützen Pytorch nur vorerst. In unserem Artikel finden Sie eine detaillierte Beschreibung von · HiFT . HiFT unterstützt FPFT von 7B -Modellen für 24G -GPU -Speichergeräte unter gemischter Genauigkeit, ohne dass Speichersparetechniken und verschiedene Optimierer wie AdamW , AdaGrad , SGD usw. verwendet werden.
Hift: Eine hierarchische Vollparameter-Feinabstimmungsstrategie
Yongkang Liu, Yiqun Zhang, Qian Li, Tong Liu, Shi Feng, Daling Wang, Yifei Zhang, Hinrich Schütze
Papier: https://arxiv.org/abs/2401.15207
26/1/2024 : Veröffentlichen Sie die erste Version von HiFT Manuscript
25/2/2024 : Veröffentlichen Sie die zweite Version von HiFT Manuscript und Quellcode
05.01.2024 : Aktualisierter Hift -Support für LoRA
05.10.2024 : Passen Sie den von BitsandBytes bereitgestellten Optimierer an
13/5/2024*: Adalora , LoRA , IA3 , P_tuning , Prefix_tuning , Prompt_tuning PEFT -Methode anpassen.
In diesem Repo gibt es mehrere Verzeichnisse:
hift , der installiert werden muss, um die von uns bereitgestellten Beispiele auszuführen.HiFT -basierter NER , QA , classification , text generation , instruction fine-tuning und Beispielimplementierung pre-training . Befehlsfeinabeinstellungsmodell auf A6000 (48 g), und die experimentellen Ergebnisse zeigen, dass die durch HIFT unterstützte maximale Sequenzlänge 2800 beträgt. Über diese Grenze hinaus können OOM Probleme auftreten.
| Modell | Max SEQ Länge | Max Batchgröße |
|---|---|---|
| LAMA2-7B (Alpaka) | 512 | 8 |
| LAMA2-7B (Vicuna) | 2800 | 1 |
Befehl Fine-Tuning 7B-Modell auf RTX3090 (24G). Wenn Sie mehrere GPUs für verteiltes Training auf RTX 3090/4000 verwenden, fügen Sie die folgenden Befehle hinzu, bevor Sie ausgeführt werden: export NCCL_IB_DISABLE=1 ; export NCCL_P2P_DISABLE=1
| Modell | Max SEQ Länge | Max Batchgröße |
|---|---|---|
| LAMA2-7B (Alpaka) | 512 | 3 |
| LAMA2-7B (Vicuna) | 1400 | 1 |
pytorch > = 2.1.1; transformers == 4.36.2pip install -r requirements.txtconda install mpi4py==3.1.4pip install flash-attn==2.5.8 hift installieren pip install hifthift -Paket importieren ### generation task
from hift import HiFTSeq2SeqTrainer,GetCallBack,peft_function,Seq2SeqTrainer
### classification taks
from hift import HiFTrainer,GetCallBack,PEFTrainer,peft_function
### QA task
from hift import HiFTQuestionAnsweringTrainer,GetCallBack,QuestionAnsweringTrainer,peft_function
HiFT -Konfiguration hinzu @dataclass
class HiFTArguments(ModelArguments):
HiTaskType: str = field(
default="SEQ_CLS",
metadata={"help": ("HiTaskType should be consistent with PEFT TaskType" )},
)
peft_type: str = field(
default=None,
metadata={"help": ("peft_type should be in [lora,adalora,ia3,p_tuning,prefix_tuning,prompt_tuning]" )},
)
init_text:str = field(
default="Predict if sentiment of this review is positive, negative or neutral",
metadata={
"help": (
"the init prompt text for prompt tuning"
)
},
)
lora_rank: int = field(
default=8,
metadata={"help": ("rank for lora or adalora" )},
)
peft_path : Optional[str] = field(default=None)
virtual_tokens:int = field(
default=20,
metadata={"help": ("the number of virtual tokens for p_tuning, prefix_tuning and prefix_tuning" )},
)
group_element: int = field(
default=1,
metadata={"help": ("number element for each group parameters" )},
)
optimizer_strategy: str = field(
default="down2up",
metadata={"help": ("optimizer strategy of ['down2up','down2up','random']" )},
)
hier_tuning: bool = field(
default=False,
metadata={
"help": (
"hierarchical optimization for LLMS"
)
},
)
freeze_layers: List[str] = field(
default_factory=list,
metadata={
"help": (
"Index of the frozen layer"
)
},
)
HitaskType sollte mit PEFT TaskType übereinstimmen.
Sequenzklassifizierung , Multiple -Choice -Aufgaben :
TaskType.SEQ_CLSFrage Antwortaufgabe :
TaskType.QUESTION_ANSSequenzbezeichnungsaufgabe :
TaskType.TOKEN_CLSErzeugungsaufgabe :
TaskType.CAUSAL_LM
Group_Element : Die Anzahl der in einem Block enthaltenen Ebenen. Standardwert ist 1 .
Freeze_Layers : Schichten, die Sie während der Feinabstimmung einfrieren möchten. Sie sollten den Index der entsprechenden Schicht bereitstellen. Der Index der Einbettungsschicht beträgt 0 , der Index der ersten Schicht ist 1 , ...
HiFT Trainer HiFT erbt den Trainer von SuggingFace, sodass Sie den von Hift bereitgestellten Trainer direkt verwenden können, um den ursprünglichen Trainer zu ersetzen.
if model_args.hier_tuning:#hier_tuning
trainer = HiFTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
model=model,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator
)
else:
trainer = PEFTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
QA -Aufgabe
if model_args.hier_tuning:
trainer = HiFTQuestionAnsweringTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
else:
trainer = QuestionAnsweringTrainer(
peft_type = model_args.peft_type,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
Generation Aufgabe
if model_args.hier_tuning:#hier_tuning
trainer = HiFTSeq2SeqTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
tokenizer=tokenizer,
data_collator=data_collator
)
else:
trainer = Seq2SeqTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
HiFT unterstützt jedes Modell. Es ist sehr einfach, sich an HiFT anzupassen.
- Definieren Sie die von Ihrem Modell in
TaskTInterfaceunterstützten Tasktypen.- Bietet
regular expressionsfür dieembedding layerund verschiedene Aufgabenheader layers. Der Zweck des regulären Ausdrucks besteht darin, den Schichtnamen der entsprechenden Schicht eindeutig zu identifizieren.- Geben Sie regelmäßige Ausdrücke mit Ausnahme der Einbettung von Schicht und Headerschicht in
others_pattern-Schnittstelle an.
Der einfachste Weg ist es, die Ebenennamen für alle Ebenen in others_pattern Schnittstellen anzugeben, und die anderen Schnittstellen geben eine leere Liste [] zurück. Unten ist das Beispiel der Roberta.
class RobertaCallBack(HiFTCallBack):
def __init__(self,freeze_layers,strategy,taskType,peft_type=None):
super().__init__(freeze_layers,strategy,taskType,peft_type)
self.TaskTInterface = [TaskType.SEQ_CLS,TaskType.TOKEN_CLS,TaskType.QUESTION_ANS]
self.check_task_type(taskType,"RoBERTa",self.TaskTInterface)
@property
def emb_pattern(self):
if self.peft_type:
return [rf'.embedding.']
else:
return [rf'.embeddings.']
@property
def seq_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def token_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def qa_cls_head(self):
if self.peft_type:
return ["qa_outputs"]
else:
return ["qa_outputs"]
@property
def others_pattern(self):
if self.peft_type:
return [rf'.d+.']
else:
return [rf'.d+.']
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/output_vicuna"
port=$(shuf -i25000-30000 -n1)
#--fsdp "full_shard auto_wrap"
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/vicuna_train.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--optim "lion_32bit"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--data_path data/dummy_conversation.json
--eval_data_path data/sharegpt_clean.json
--output_dir $output_dir/model
--num_train_epochs 3
--do_train
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--evaluation_strategy "steps"
--eval_steps 1500
--save_strategy "steps"
--save_steps 1500
--save_total_limit 8
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0
--lr_scheduler_type "linear"
--logging_steps 10
--model_max_length 2800
--lazy_preprocess True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/instruct_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/instruct_tuning.py
--model_type opt
--HiTaskType "CAUSAL_LM"
--optim "adamw_torch"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path opt-7b
--dataset_dir alpaca_data
--validation_split_percentage 0.01
--per_device_train_batch_size 12
--per_device_eval_batch_size 8
--do_train
--do_eval
--seed 12345
--fp16
--tf32 true
--num_train_epochs 1
--lr_scheduler_type "cosine"
--learning_rate 1e-5
--warmup_ratio 0.0
--weight_decay 0.0
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--evaluation_strategy steps
--eval_steps 100
--save_steps 200
--preprocessing_num_workers 4
--max_seq_length 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### This is just a demo. Please adjust the parameters based on your data.
export num_gpus=8
export output_dir="outputs/pretrain_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES=0 torchrun --master_port "$port" examples/pretrain_tuning.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path llama2-7b
--dataset_dir "data"
--data_cache_dir "data_cache_dir"
--validation_split_percentage 0.001
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--do_train
--seed 12345
--fp16
--max_steps 1000
--lr_scheduler_type cosine
--learning_rate 1e-5
--warmup_ratio 0.05
--weight_decay 0.01
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--save_steps 500
--preprocessing_num_workers 8
--block_size 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--hier_tuning
--group_element $1
--optimizer_strategy $2
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
# CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" python -m torch.distributed.launch --nproc_per_node=$num_gpus run_glue.py
CUDA_VISIBLE_DEVICES=7 torchrun --master_port "$port" examples/run_generation.py
--model_name_or_path llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--padding_side "left"
--group_by_length
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--weight_decay 0
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/run_generation.py
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--deepspeed "dsconfig/zero0_config.json"
--padding_side "left"
--group_by_length
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--hier_tuning
--weight_decay 0
--group_element $1
--optimizer_strategy $2
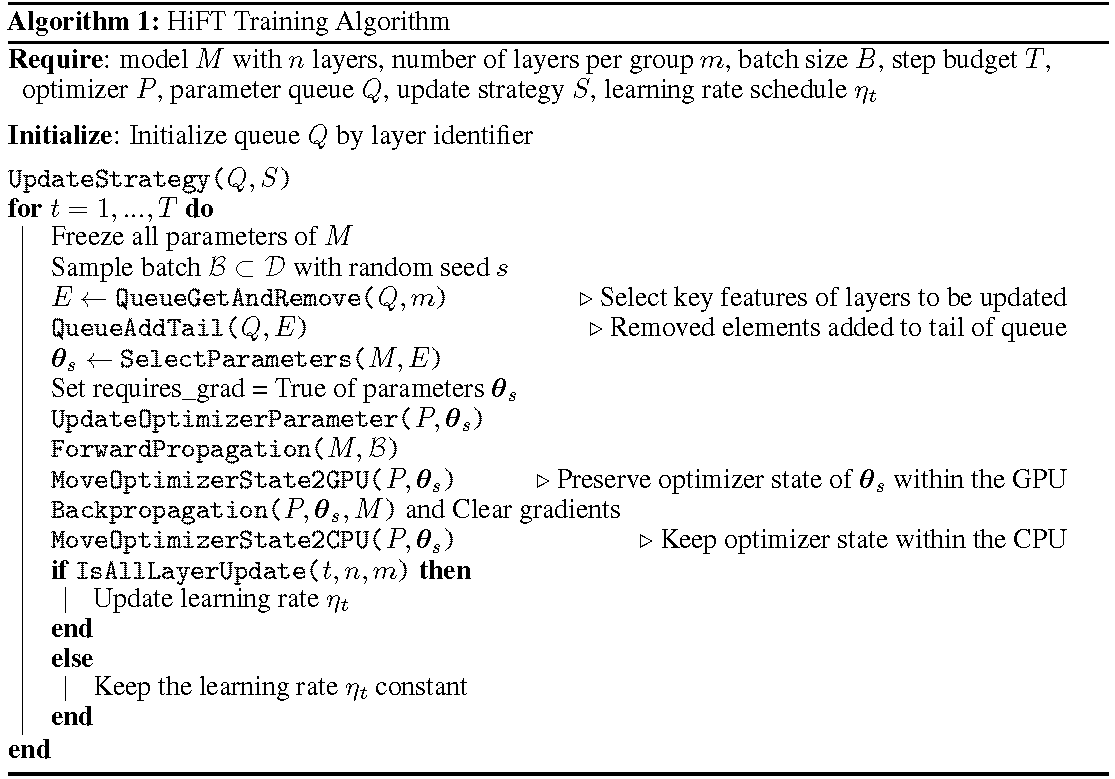
Der detaillierte Trainingsprozess wird im Algorithmus gezeigt. Der erste Schritt besteht darin, die Aktualisierungsstrategie zu bestimmen. Dann alle Schichten einfrieren. Die zu aktualisierten Ebenen, gekennzeichnet durch
HiFT aktualisiert iterativ eine Teilmenge von Parametern bei jedem Trainingsschritt und ändert den vollständigen Parameter nach mehreren Schritten. Dies reduziert die Anforderungen an die GPU-Speicher für feinstörende Sprachmodelle erheblich, ohne dass die Aufgabe während der Bereitstellung aufgaben, ohne Inferenzlatenz einzuführen. Hift übertrifft auch mehrere andere Anpassungsmethoden, darunter Adapter, Präfixabbau und Feinabstimmung.
HiFT ist eine modellunabhängige und optimiererunabhängige Vollparameter-Feinabstimmungsmethode, die in die PEFT-Methode integriert werden kann.
Optimierer : Die neueste Version von HiFT ist an Adam , AdamW , SGD , Adafactor und Adagrad Optimizer angepasst.
Modell : Die neueste Version von HiFT unterstützt die Modelle BERT , RoBERTa , GPT-2 , GPTNeo , GPT-NeoX , OPT und LLaMA-based .
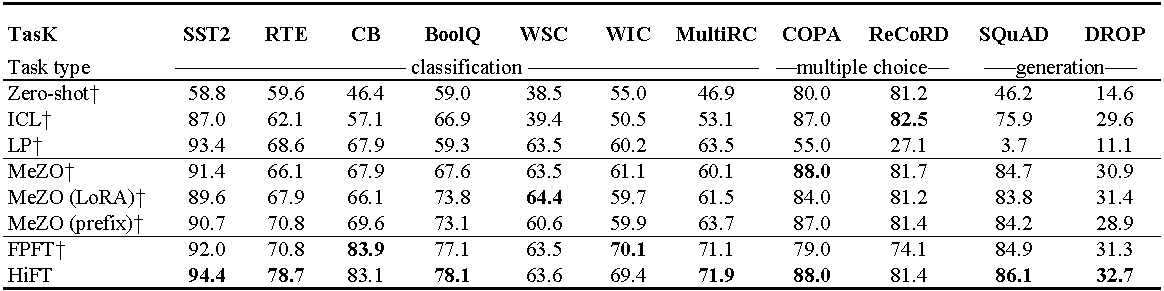
Experimente mit Opt-13b (mit 1000 Beispielen). ICL : In-Kontext-Lernen; LP : Lineare Prüfung; FPFT : Vollständige Feinabstimmung; Präfix: Präfix-Tuning. Alle Experimente verwenden Eingabeaufforderungen von Mezo.
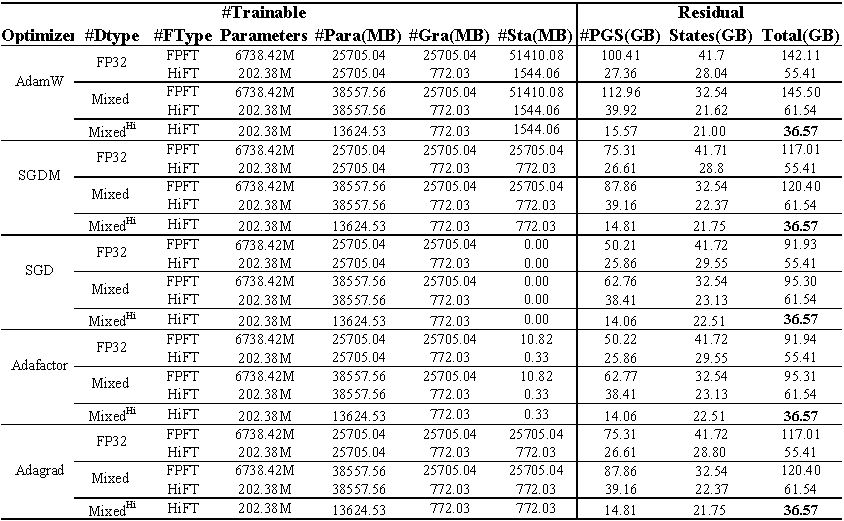
GPU-Speicherverbrauch von Feinabstimmungslama (7B) im E2E- Datensatz. Die Gesamtsumme repräsentiert den gesamten Speicher, der während der Feinabstimmung verwendet wird. Mischung stellt eine Feinabstimmung mit Standard-gemischter Präzision dar und ist die gemischte Präzision, die an HiFT angepasst ist. Para repräsentiert den Speicher, der durch die Modellparameter besetzt ist; GRA repräsentiert die von dem Gradienten besetzte Erinnerung; STA repräsentiert den Speicher, der vom Optimiererzustand besetzt ist. PGS repräsentiert die Summe des Speichers, der durch Parameter , Gradienten und Optimiererzustand besetzt ist.
Quellcode
class FP16_Optimizer(DeepSpeedOptimizer):
def __init__(self,
init_optimizer,
deepspeed=None,
static_loss_scale=1.0,
dynamic_loss_scale=False,
initial_dynamic_scale=2**32,
dynamic_loss_args=None,
verbose=True,
mpu=None,
clip_grad=0.0,
fused_adam_legacy=False,
has_moe_layers=False,
timers=None):
....
self.fp16_groups = []
self.fp16_groups_flat = []
self.fp32_groups_flat = []
...
for i, param_group in enumerate(self.optimizer.param_groups):
...
self.fp32_groups_flat.append(self.fp16_groups_flat[i].clone().float().detach())
...
Der zum Laden von 1B -Parametern erforderliche Speicher beträgt 3,72 GB (10^9
Wir werden den Algorithmus mit gemischter Präzision neu eingestuft, um sich an HiFT Feinabstimmungsalgorithmus anzupassen, wodurch sichergestellt wird, dass Modellparameter mit Einzelprezisionsmodells keine zusätzlichen GPU-Speicher-Overhead entstehen.
@article { liu2024hift ,
title = { HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy } ,
author = { Liu, Yongkang and Zhang, Yiqun and Li, Qian and Feng, Shi and Wang, Daling and Zhang, Yifei and Sch{"u}tze, Hinrich } ,
journal = { arXiv preprint arXiv:2401.15207 } ,
year = { 2024 }
}Dieses Projekt begrüßt Beiträge und Vorschläge. In den meisten Beiträgen müssen Sie einer Mitarbeiters Lizenzvereinbarung (CLA) zustimmen, in der Sie erklären, dass Sie das Recht haben und uns tatsächlich tun, um uns die Rechte zu gewähren, Ihren Beitrag zu verwenden.


