HiFT
1.0.0
repo นี้มีซอร์สโค้ดของ Python Package HiFT และตัวอย่างหลายประการของวิธีการรวมเข้ากับโมเดล Pytorch เช่นที่อยู่ในใบหน้ากอด ตอนนี้เราสนับสนุน Pytorch เท่านั้น ดูเอกสารของเราสำหรับคำอธิบายโดยละเอียดเกี่ยวกับ· HiFT HiFT SGD FPFT ของ AdaGrad 7B สำหรับอุปกรณ์หน่วยความจำขนาด 24G GPU ภายใต้ความแม่นยำแบบผสมโดยไม่ต้อง AdamW เทคนิคการประหยัดหน่วยความจำใด ๆ
HIFT: กลยุทธ์การปรับจูนพารามิเตอร์แบบเต็มลำดับชั้น
Yongkang Liu, Yiqun Zhang, Qian Li, Tong Liu, Shi Feng, Daling Wang, Yifei Zhang, Hinrich Schütze
กระดาษ: https://arxiv.org/abs/2401.15207
26/1/2024 : เผยแพร่ HiFT Manuscript เวอร์ชันแรก
25/2/2024 : เผยแพร่ต้นฉบับ HiFT รุ่นที่สองและซอร์สโค้ดรุ่นที่สอง
1/5/2024 : อัปเดต HIFT Support สำหรับ LoRA
10/5/2024 : ปรับตัวเพิ่มประสิทธิภาพโดย Bitsandbytes
13/5/2024*: ปรับ Adalora , LoRA , IA3 , P_tuning , Prefix_tuning , Prompt_tuning วิธี peft
มีหลายไดเรกทอรีใน repo นี้:
hift ซึ่งจำเป็นต้องติดตั้งเพื่อเรียกใช้ตัวอย่างที่เรามีให้NER -based- HiFT , QA , classification , text generation , instruction fine-tuning และการใช้งานก่อนการ pre-training การเรียนการสอนการปรับแต่ง 7B แบบจำลองบน A6000 (48G) และผลการทดลองแสดงให้เห็นว่าความยาวลำดับสูงสุดที่สนับสนุนโดย HIFT คือ 2800 เกินขีด จำกัด นี้ปัญหา OOM อาจเกิดขึ้น
| แบบอย่าง | ความยาวสูงสุด seq | ขนาดแบทช์สูงสุด |
|---|---|---|
| LLAMA2-7B (Alpaca) | 512 | 8 |
| LLAMA2-7B (Vicuna) | 2800 | 1 |
คำแนะนำการปรับแต่ง 7B รุ่นบน RTX3090 (24G) หากคุณใช้ GPU หลายตัวสำหรับการฝึกอบรมแบบกระจายบน RTX 3090/4000 ให้เพิ่มคำสั่งต่อไปนี้ก่อนที่จะทำงาน: export NCCL_IB_DISABLE=1 ; export NCCL_P2P_DISABLE=1
| แบบอย่าง | ความยาวสูงสุด seq | ขนาดแบทช์สูงสุด |
|---|---|---|
| LLAMA2-7B (Alpaca) | 512 | 3 |
| LLAMA2-7B (Vicuna) | 1400 | 1 |
pytorch > = 2.1.1; transformers == 4.36.2pip install -r requirements.txtconda install mpi4py==3.1.4pip install flash-attn==2.5.8 hift pip install hifthift ### generation task
from hift import HiFTSeq2SeqTrainer,GetCallBack,peft_function,Seq2SeqTrainer
### classification taks
from hift import HiFTrainer,GetCallBack,PEFTrainer,peft_function
### QA task
from hift import HiFTQuestionAnsweringTrainer,GetCallBack,QuestionAnsweringTrainer,peft_function
HiFT @dataclass
class HiFTArguments(ModelArguments):
HiTaskType: str = field(
default="SEQ_CLS",
metadata={"help": ("HiTaskType should be consistent with PEFT TaskType" )},
)
peft_type: str = field(
default=None,
metadata={"help": ("peft_type should be in [lora,adalora,ia3,p_tuning,prefix_tuning,prompt_tuning]" )},
)
init_text:str = field(
default="Predict if sentiment of this review is positive, negative or neutral",
metadata={
"help": (
"the init prompt text for prompt tuning"
)
},
)
lora_rank: int = field(
default=8,
metadata={"help": ("rank for lora or adalora" )},
)
peft_path : Optional[str] = field(default=None)
virtual_tokens:int = field(
default=20,
metadata={"help": ("the number of virtual tokens for p_tuning, prefix_tuning and prefix_tuning" )},
)
group_element: int = field(
default=1,
metadata={"help": ("number element for each group parameters" )},
)
optimizer_strategy: str = field(
default="down2up",
metadata={"help": ("optimizer strategy of ['down2up','down2up','random']" )},
)
hier_tuning: bool = field(
default=False,
metadata={
"help": (
"hierarchical optimization for LLMS"
)
},
)
freeze_layers: List[str] = field(
default_factory=list,
metadata={
"help": (
"Index of the frozen layer"
)
},
)
HitaskType ควรสอดคล้องกับ PEFT tatstype
การจำแนกลำดับ , งานแบบปรนัย :
TaskType.SEQ_CLSงานตอบคำถาม :
TaskType.QUESTION_ANSงาน การติดฉลากลำดับ :
TaskType.TOKEN_CLSงาน สร้าง :
TaskType.CAUSAL_LM
group_element : จำนวนเลเยอร์ที่รวมอยู่ในบล็อก ค่าเริ่มต้นคือ 1
Freeze_layers : เลเยอร์ที่คุณต้องการหยุดในระหว่างการปรับแต่ง คุณควรจัดทำดัชนีของเลเยอร์ที่เกี่ยวข้อง ดัชนี ของเลเยอร์ฝังคือ 0 ดัชนีของเลเยอร์แรกคือ 1 , ...
HiFT Trainer HiFT สืบทอดเทรนเนอร์ของ HuggingFace ดังนั้นคุณสามารถใช้เทรนเนอร์ที่จัดทำโดย HIFT โดยตรงเพื่อแทนที่ Trainer ดั้งเดิม
if model_args.hier_tuning:#hier_tuning
trainer = HiFTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
model=model,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator
)
else:
trainer = PEFTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
งาน QA
if model_args.hier_tuning:
trainer = HiFTQuestionAnsweringTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
else:
trainer = QuestionAnsweringTrainer(
peft_type = model_args.peft_type,
eval_examples=eval_examples if training_args.do_eval else None,
post_process_function=post_processing_function,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics)
งานสร้าง
if model_args.hier_tuning:#hier_tuning
trainer = HiFTSeq2SeqTrainer(
hiFThandler = GetCallBack(model_args.model_name_or_path),
HiTaskType = model_args.HiTaskType,
group_element = model_args.group_element,
strategy = model_args.optimizer_strategy,
hier_tuning= model_args.hier_tuning,
peft_type = model_args.peft_type,
freeze_layers = model_args.freeze_layers,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
tokenizer=tokenizer,
data_collator=data_collator
)
else:
trainer = Seq2SeqTrainer(
peft_type = model_args.peft_type,
args=training_args,
model=model,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
HiFT รองรับรุ่นใด ๆ มันง่ายมากที่จะปรับให้เข้ากับ HiFT
- กำหนดประเภทงานที่สนับสนุนโดยโมเดลของคุณใน
TaskTInterface- แสดง
regular expressionsสำหรับembedding layerและheader layersหัวงานที่แตกต่างกัน วัตถุประสงค์ของนิพจน์ทั่วไปคือการระบุชื่อเลเยอร์ของเลเยอร์ที่เกี่ยวข้องโดยเฉพาะ- ให้การแสดงออกปกติยกเว้นเลเยอร์ฝังและเลเยอร์ส่วนหัวในส่วนต่อ
others_pattern
วิธีที่ง่ายที่สุดคือการให้ชื่อเลเยอร์สำหรับเลเยอร์ทั้งหมดในอินเตอร์เฟส others_pattern และอินเตอร์เฟสอื่น ๆ กลับรายการที่ว่างเปล่า [] ด้านล่างเป็นตัวอย่างของ Roberta
class RobertaCallBack(HiFTCallBack):
def __init__(self,freeze_layers,strategy,taskType,peft_type=None):
super().__init__(freeze_layers,strategy,taskType,peft_type)
self.TaskTInterface = [TaskType.SEQ_CLS,TaskType.TOKEN_CLS,TaskType.QUESTION_ANS]
self.check_task_type(taskType,"RoBERTa",self.TaskTInterface)
@property
def emb_pattern(self):
if self.peft_type:
return [rf'.embedding.']
else:
return [rf'.embeddings.']
@property
def seq_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def token_cls_head(self):
if self.peft_type:
return ["classifier"]
else:
return ["classifier"]
@property
def qa_cls_head(self):
if self.peft_type:
return ["qa_outputs"]
else:
return ["qa_outputs"]
@property
def others_pattern(self):
if self.peft_type:
return [rf'.d+.']
else:
return [rf'.d+.']
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/output_vicuna"
port=$(shuf -i25000-30000 -n1)
#--fsdp "full_shard auto_wrap"
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/vicuna_train.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--optim "lion_32bit"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--data_path data/dummy_conversation.json
--eval_data_path data/sharegpt_clean.json
--output_dir $output_dir/model
--num_train_epochs 3
--do_train
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--evaluation_strategy "steps"
--eval_steps 1500
--save_strategy "steps"
--save_steps 1500
--save_total_limit 8
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0
--lr_scheduler_type "linear"
--logging_steps 10
--model_max_length 2800
--lazy_preprocess True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### The parameters have not been fine-tuned, this is just a demo. Please adjust the parameters based on your data.
export num_gpus=2
export output_dir="outputs/instruct_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,2" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/instruct_tuning.py
--model_type opt
--HiTaskType "CAUSAL_LM"
--optim "adamw_torch"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path opt-7b
--dataset_dir alpaca_data
--validation_split_percentage 0.01
--per_device_train_batch_size 12
--per_device_eval_batch_size 8
--do_train
--do_eval
--seed 12345
--fp16
--tf32 true
--num_train_epochs 1
--lr_scheduler_type "cosine"
--learning_rate 1e-5
--warmup_ratio 0.0
--weight_decay 0.0
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--evaluation_strategy steps
--eval_steps 100
--save_steps 200
--preprocessing_num_workers 4
--max_seq_length 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--load_best_model_at_end
--hier_tuning
--group_element $1
--optimizer_strategy $2
### This is just a demo. Please adjust the parameters based on your data.
export num_gpus=8
export output_dir="outputs/pretrain_tuning"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES=0 torchrun --master_port "$port" examples/pretrain_tuning.py
--model_type llama
--HiTaskType "CAUSAL_LM"
--deepspeed "dsconfig/zero0_config.json"
--model_name_or_path llama2-7b
--dataset_dir "data"
--data_cache_dir "data_cache_dir"
--validation_split_percentage 0.001
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--do_train
--seed 12345
--fp16
--max_steps 1000
--lr_scheduler_type cosine
--learning_rate 1e-5
--warmup_ratio 0.05
--weight_decay 0.01
--logging_strategy steps
--logging_steps 10
--save_strategy steps
--save_total_limit 3
--save_steps 500
--preprocessing_num_workers 8
--block_size 512
--output_dir $output_dir/model
--overwrite_output_dir
--logging_first_step True
--torch_dtype float16
--ddp_find_unused_parameters False
--hier_tuning
--group_element $1
--optimizer_strategy $2
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
# CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" python -m torch.distributed.launch --nproc_per_node=$num_gpus run_glue.py
CUDA_VISIBLE_DEVICES=7 torchrun --master_port "$port" examples/run_generation.py
--model_name_or_path llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--padding_side "left"
--group_by_length
--per_device_train_batch_size 1
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--weight_decay 0
export num_gpus=8
export output_dir="outputs/e2e_opt"
port=$(shuf -i25000-30000 -n1)
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7" torchrun --master_port "$port" --nproc_per_node=$num_gpus examples/run_generation.py
--model_name_or_path /mounts/work/lyk/hierFT/llama2-7b
--model_type llama
--HiTaskType "CAUSAL_LM"
--peft_type "lora"
--dataset_name e2e_nlg
--do_train
--do_eval
--deepspeed "dsconfig/zero0_config.json"
--padding_side "left"
--group_by_length
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--save_strategy epoch
--evaluation_strategy epoch
--predict_with_generate
--learning_rate 5e-5
--lr_scheduler_type "linear"
--pad_to_max_length
--max_eval_samples 2000
--model_max_length 512
--num_train_epochs 5
--output_dir $output_dir/model
--overwrite_output_dir
--logging_steps 10
--logging_dir $output_dir/log
--warmup_ratio 0.0
--num_beams 10
--seed 0
--fp16
--weight_decay 0.0
--load_best_model_at_end
--hier_tuning
--weight_decay 0
--group_element $1
--optimizer_strategy $2
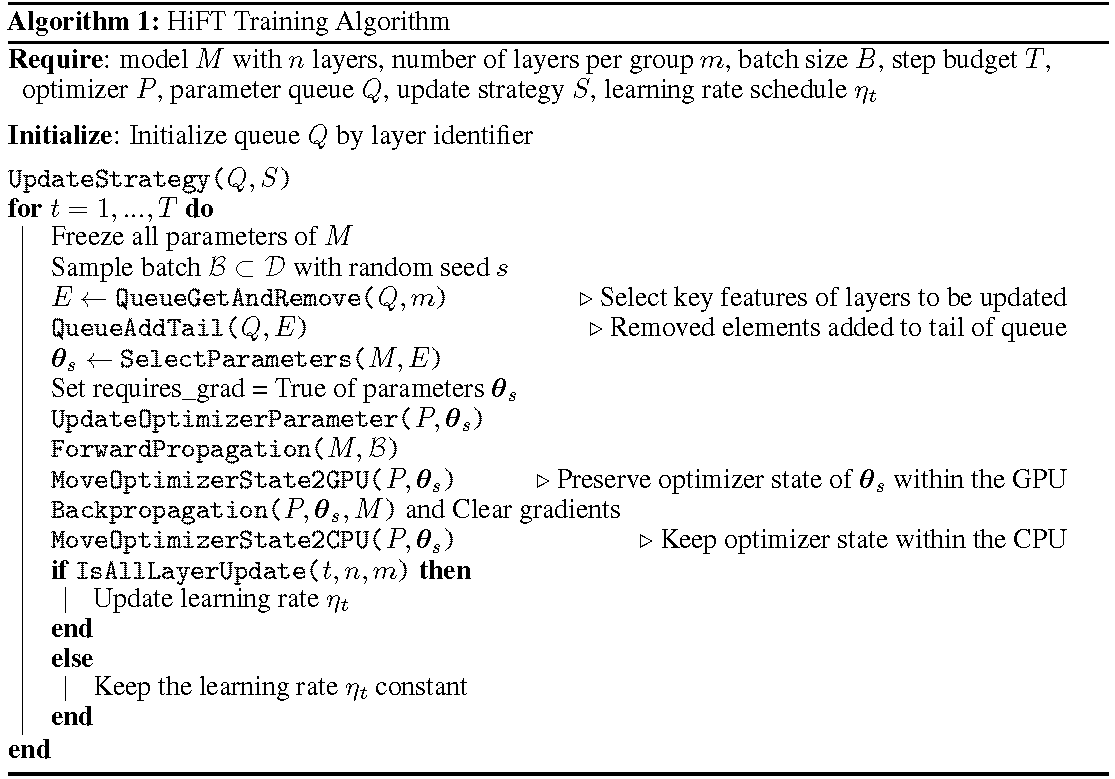
กระบวนการฝึกอบรมโดยละเอียดจะแสดงในอัลกอริทึม ขั้นตอนแรกคือการกำหนดกลยุทธ์การอัปเดต จากนั้นตรึงเลเยอร์ทั้งหมด เลเยอร์ที่จะอัปเดตแสดงโดย
HiFT อัปเดตชุดย่อยของพารามิเตอร์ในแต่ละขั้นตอนการฝึกอบรมและจะแก้ไขพารามิเตอร์เต็มหลังจากหลายขั้นตอน สิ่งนี้จะช่วยลดข้อกำหนดของหน่วยความจำ GPU อย่างมากสำหรับแบบจำลองภาษาที่ปรับแต่งได้อย่างละเอียดช่วยให้การสลับงานที่มีประสิทธิภาพในระหว่างการปรับใช้ทั้งหมดโดยไม่ต้องแนะนำเวลาแฝงการอนุมาน HIFT ยังมีประสิทธิภาพสูงกว่าวิธีการปรับตัวอื่น ๆ อีกหลายวิธีรวมถึงอะแดปเตอร์การปรับแต่งคำนำหน้าและการปรับแต่ง
HiFT เป็นวิธีการปรับจูนแบบเต็มรูปแบบที่ไม่ขึ้นกับโมเดลที่ไม่ขึ้นกับการปรับพารามิเตอร์แบบพารามิเตอร์ที่สามารถรวมเข้ากับวิธี PEFT ได้
Optimizers : HiFT เวอร์ชันล่าสุดถูกดัดแปลงให้เข้ากับ Adam , AdamW , SGD , Adafactor และ Adagrad Optimizers
รุ่น : รุ่นล่าสุดของ HiFT รองรับ BERT , RoBERTa , GPT-2 , GPTNeo , GPT-NeoX , OPT และ LLaMA-based รุ่น
การทดลอง เกี่ยวกับ OPT-13B (พร้อมตัวอย่าง 1,000 ตัวอย่าง) ICL : การเรียนรู้ในบริบท; LP : การตรวจเชิงเส้น; FPFT : การปรับแต่งแบบเต็ม; คำนำหน้า: คำนำหน้าการปรับแต่ง การทดลองทั้งหมดใช้พรอมต์จาก Mezo
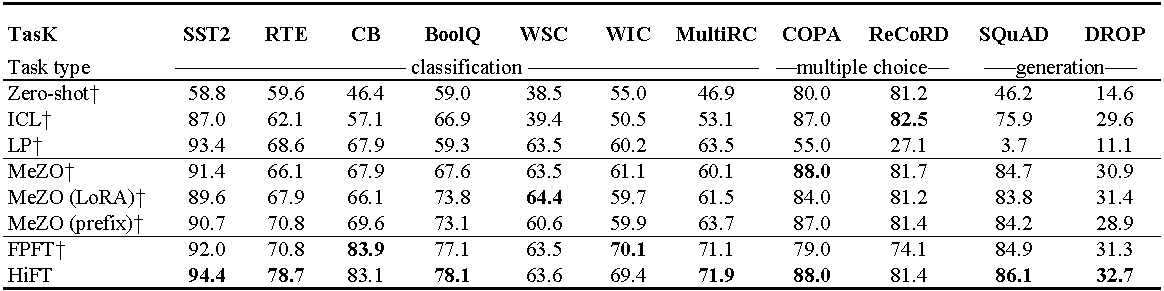
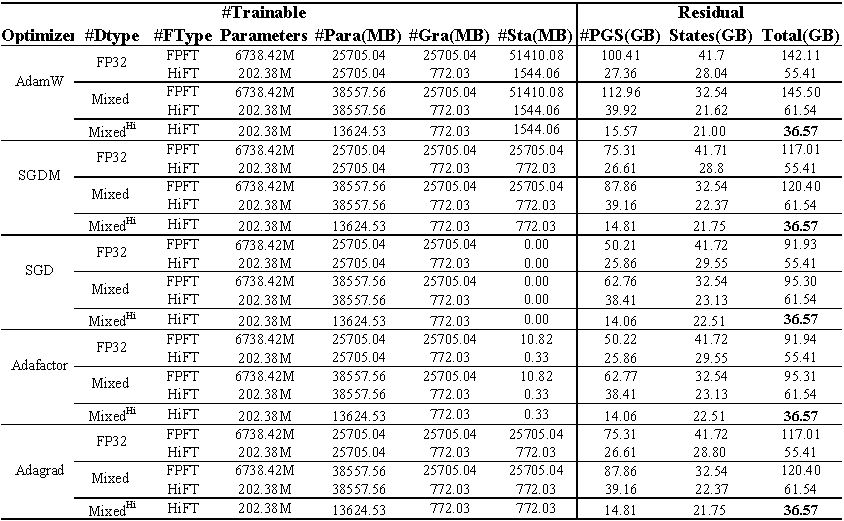
การใช้หน่วยความจำ GPU ของการปรับแต่ง Llama (7B) บนชุดข้อมูล E2E ทั้งหมด แสดงถึงหน่วยความจำทั้งหมดที่ใช้ในระหว่างการปรับแต่ง การผสม แสดงถึงการปรับแต่งอย่างละเอียดด้วย ความแม่นยำผสมมาตรฐาน และ ผสม^ hi^ หมายถึงความแม่นยำผสมที่ปรับให้เข้ากับ HiFT Para หมายถึงหน่วยความจำที่ครอบครองโดย พารามิเตอร์ แบบจำลอง GRA แสดงถึงความทรงจำที่ครอบครองโดยการไล่ระดับสี; STA แสดงถึงหน่วยความจำที่ถูกครอบครองโดย สถานะเครื่องมือเพิ่มประสิทธิภาพ PGS แสดงถึงผลรวมของหน่วยความจำที่ถูกครอบครองโดย พารามิเตอร์ การไล่ระดับสี และ สถานะเครื่องมือเพิ่มประสิทธิภาพ
รหัสต้นฉบับ
class FP16_Optimizer(DeepSpeedOptimizer):
def __init__(self,
init_optimizer,
deepspeed=None,
static_loss_scale=1.0,
dynamic_loss_scale=False,
initial_dynamic_scale=2**32,
dynamic_loss_args=None,
verbose=True,
mpu=None,
clip_grad=0.0,
fused_adam_legacy=False,
has_moe_layers=False,
timers=None):
....
self.fp16_groups = []
self.fp16_groups_flat = []
self.fp32_groups_flat = []
...
for i, param_group in enumerate(self.optimizer.param_groups):
...
self.fp32_groups_flat.append(self.fp16_groups_flat[i].clone().float().detach())
...
หน่วยความจำที่จำเป็นในการโหลดพารามิเตอร์ 1B คือ 3.72GB (10^9
เราปรับปรุงอัลกอริทึมความแม่นยำแบบผสมเพื่อปรับให้เข้ากับอัลกอริทึมการปรับแต่งของ HiFT ซึ่งทำให้มั่นใจได้ว่าพารามิเตอร์แบบจำลองความแม่นยำเดียวจะไม่ได้รับค่าใช้จ่าย GPU หน่วยความจำเพิ่มเติม
@article { liu2024hift ,
title = { HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy } ,
author = { Liu, Yongkang and Zhang, Yiqun and Li, Qian and Feng, Shi and Wang, Daling and Zhang, Yifei and Sch{"u}tze, Hinrich } ,
journal = { arXiv preprint arXiv:2401.15207 } ,
year = { 2024 }
}โครงการนี้ยินดีต้อนรับการมีส่วนร่วมและข้อเสนอแนะ การมีส่วนร่วมส่วนใหญ่กำหนดให้คุณต้องยอมรับข้อตกลงใบอนุญาตผู้มีส่วนร่วม (CLA) ประกาศว่าคุณมีสิทธิ์และทำจริงให้สิทธิ์ในการใช้การบริจาคของคุณ


