L2M
1.0.0
Thomas Schmied 1 ,Markus Hofmarcher 2 ,Fabian Paischer 1 ,Razvan PacScanu 3,4 ,Sepp Hochreiter 1,5
1 Ellis Unit Linz和Lit AI實驗室,機器學習研究所,約翰內斯開普勒大學林茲,奧地利
2 JKU LIT SAL ESPML實驗室,機器學習研究所,約翰內斯開普勒大學林茲,奧地利
3 Google DeepMind
4 UCL
5奧地利維也納人工智能高級研究所(IARAI)
該存儲庫包含“在Neurips 2023接受的RL中調節預訓練模型”的源代碼。本文可在此處獲得。
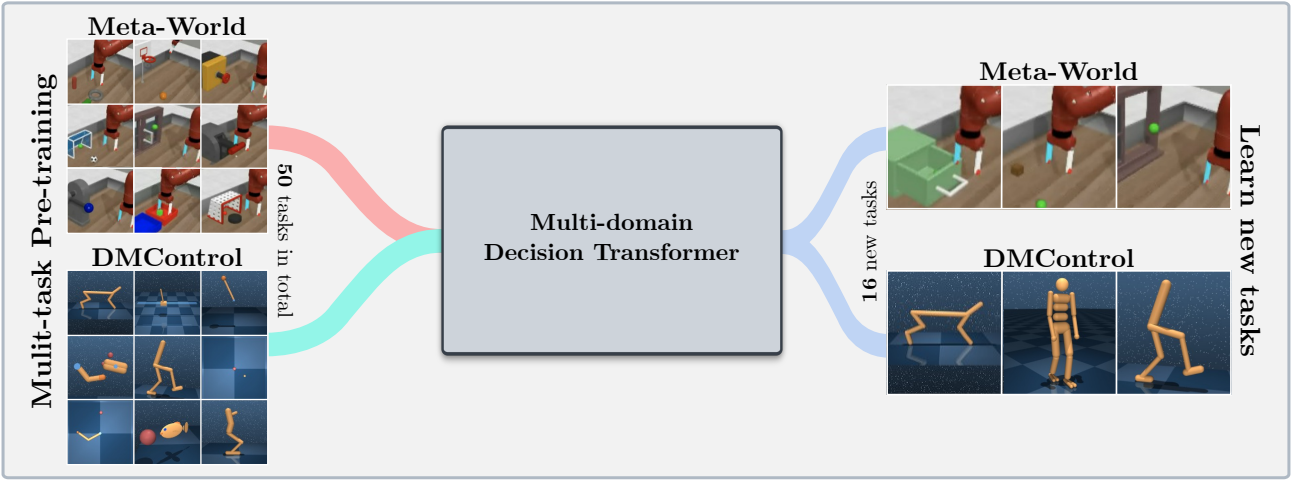
該代碼庫支持培訓決策變壓器(DT)模型在線或在以下域上的離線數據集:
該代碼庫依賴開源框架,包括:
這個存儲庫是什麼?
.
├── configs # Contains all .yaml config files for Hydra to configure agents, envs, etc.
│ ├── agent_params
│ ├── wandb_callback_params
│ ├── env_params
│ ├── eval_params
│ ├── run_params
│ └── config.yaml # Main config file for Hydra - specifies log/data/model directories.
├── continual_world # Submodule for Continual-World.
├── dmc2gym_custom # Custom wrapper for DMControl.
├── figures
├── scripts # Scrips for running experiments on Slurm/PBS in multi-gpu/node setups.
├── src # Main source directory.
│ ├── algos # Contains agent/model/prompt classes.
│ ├── augmentations # Image augmentations.
│ ├── buffers # Contains replay trajectory buffers.
│ ├── callbacks # Contains callbacks for training (e.g., WandB, evaluation, etc.).
│ ├── data # Contains data utilities (e.g., for downloading Atari)
│ ├── envs # Contains functionality for creating environments.
│ ├── exploration # Contains exploration strategies.
│ ├── optimizers # Contains (custom) optimizers.
│ ├── schedulers # Contains learning rate schedulers.
│ ├── tokenizers_custom # Contains custom tokenizers for discretizing states/actions.
│ ├── utils
│ └── __init__.py
├── LICENSE
├── README.md
├── environment.yaml
├── requirements.txt
└── main.py # Main entry point for training/evaluating agents.
環境配置和requirements.txt項可在environment.yaml中可用。
首先,創建Conda環境。
conda env create -f environment.yaml
conda activate mddt
然後安裝剩餘的要求(如果沒有在此處查看,則已經下載了Mujoco):
pip install -r requirements.txt
init the continualworld subsodule並安裝:
git submodule init
git submodule update
cd continualworld
pip install .
安裝meta-world :
pip install git+https://github.com/rlworkgroup/metaworld.git@18118a28c06893da0f363786696cc792457b062b
安裝DMC2GYM的自定義版本。我們的版本使flatten_obs可選,因此使我們能夠構建所有DMCONTROL ENV的完整觀察空間。
cd dmc2gym_custom
pip install -e .
下載Mujoco:
mkdir ~/.mujoco
cd ~/.mujoco
wget https://www.roboti.us/download/mujoco200_linux.zip
unzip mujoco200_linux.zip
mv mujoco200_linux mujoco200
wget https://www.roboti.us/file/mjkey.txt
然後將以下行添加到.bashrc :
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mujoco200/bin
以下問題很有幫助:
首先,安裝以下軟件包:
conda install -c conda-forge glew mesalib
conda install -c menpo glfw3 osmesa
pip install patchelf
手動創建符號鏈接:
cp /usr/lib64/libGL.so.1 $CONDA_PREFIX/lib
ln -s $CONDA_PREFIX/lib/libGL.so.1 $CONDA_PREFIX/lib/libGL.so
然後做:
mkdir ~/rpm
cd ~/rpm
curl -o libgcrypt11.rpm ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/bosconovic:/branches:/home:/elimat:/lsi/openSUSE_Leap_15.1/x86_64/libgcrypt11-1.5.4-lp151.23.29.x86_64.rpm
rpm2cpio libgcrypt11.rpm | cpio -id
最後,導出通往rpm dir的路徑(添加到~/.bashrc ):
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/rpm/usr/lib64
export LDFLAGS="-L/~/rpm/usr/lib64"
該代碼庫依賴於HYDRA,該密碼通過.yaml文件配置實驗。 Hydra會自動為給定運行創建日誌文件夾結構,如相應的config.yaml文件中指定。
config.yaml是主要配置入口點,包含默認參數。文件引用塊defaults下的相應默認參數文件。此外, config.yaml包含4個配置目錄路徑的重要常數:
LOG_DIR: ../logs
DATA_DIR: ../data
SSD_DATA_DIR: ../data
MODELS_DIR: ../models
當前通過我們的Web服務器託管了已有的數據集。將元世界和DMCONTROL數據集下載到指定的DATA_DIR :
# Meta-World
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/metaworld
# DMControl
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/dm_control_1M
該數據集也可以在HuggingFace Hub上找到。使用huggingface-cli下載:
# Meta-World
huggingface-cli download ml-jku/meta-world --local-dir=./meta-world --repo-type dataset
# DMControl
huggingface-cli download ml-jku/dm_control --local-dir=./dm_control --repo-type dataset
該框架還支持Atari,D4RL和Visual DMControl數據集。對於Atari和Visual DMControl,我們指的是各自的READMES。
在下文中,我們提供了一些說明性的例子,說明瞭如何在論文中運行實驗。
在MT40 + DMC10上訓練40m多域決策變壓器(MDDT)模型,在一個GPU上使用3個種子,運行:
python main.py -m experiment_name=pretrain seed=42,43,44 env_params=multi_domain_mtdmc run_params=pretrain eval_params=pretrain_disc agent_params=cdt_pretrain_disc agent_params.kind=MDDT agent_params/model_kwargs=multi_domain_mtdmc agent_params/data_paths=mt40v2_dmc10 +agent_params/replay_buffer_kwargs=multi_domain_mtdmc +agent_params.accumulation_steps=2
要使用LORA在帶有3個種子的單個CW10任務上微調預訓練的模型,請運行:
python main.py -m experiment_name=cw10_lora seed=42,43,44 env_params=mt50_pretrain run_params=finetune eval_params=finetune agent_params=cdt_mpdt_disc agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft agent_params/model_kwargs/prompt_kwargs=lora env_params.envid=hammer-v2 agent_params.data_paths.names='${env_params.envid}.pkl' env_params.eval_env_names=
要以3種種子的順序方式使用L2M在所有CW10任務上微調預訓練的模型,請運行:
python main.py -m experiment_name=cw10_cl_l2m seed=42,43,44 env_params=multi_domain_ft env_params.eval_env_names=cw10_v2 run_params=finetune_coff eval_params=finetune_md_cl agent_params=cdt_mpdt_disc +agent_params.steps_per_task=100000 agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft +agent_params.replay_buffer_kwargs.kind=continual agent_params/model_kwargs/prompt_kwargs=l2m_lora
對於多GPU培訓,我們使用torchrun 。該工具與hydra發生衝突。因此,創建了啟動器插件hydra_torchrun_launcher。
要啟用插件,請克隆hydra repo,CD contrib/hydra_torchrun_launcher ,然後安裝插件:
git clone https://github.com/facebookresearch/hydra.git
cd hydra/contrib/hydra_torchrun_launcher
pip install -e .
該插件可以從命令行中使用:
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
可以通過CUDA_VISIBLE_DEVICES在單個節點上的本地群集上運行實驗,以指定要使用的GPU:
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
在Slurm上,在單個節點上執行torchrun都一樣。例如,在一個節點上以2個GPU運行:
#!/bin/bash
#SBATCH --account=X
#SBATCH --qos=X
#SBATCH --partition=X
#SBATCH --nodes=1
#SBATCH --gpus=2
#SBATCH --cpus-per-task=32
source activate mddt
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=2 [...]
scripts中提供了用於Slurm或PBS的多GPU培訓的示例腳本。
在多節點設置中在slurm/pbs上運行需要更多的護理。 scripts中提供示例腳本。
如果您覺得這有用,請考慮引用我們的工作:
@article{schmied2024learning,
title={Learning to Modulate pre-trained Models in RL},
author={Schmied, Thomas and Hofmarcher, Markus and Paischer, Fabian and Pascanu, Razvan and Hochreiter, Sepp},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}


