L2M
1.0.0
Thomas Schmied 1 , Markus Hofmaler 2 , Fabian Paisscher 1 , Razvan Pacscanu 3,4 , Sepp Hochreiter 1,5
1 Ellis Unit Linz und Lit AI Lab, Institut für maschinelles Lernen, Johannes Kepler University Linz, Österreich
2 JKU Lit Sal ESPML Lab, Institut für maschinelles Lernen, Johannes Kepler University Linz, Österreich
3 Google DeepMind
4 UCL
5 Institut für fortgeschrittene Forschung in künstlicher Intelligenz (IARII), Wien, Österreich
Dieses Repository enthält den Quellcode für "Lernen für die Modulation vor ausgebildeter Modelle in RL", die bei Neurips 2023 akzeptiert wird. Das Papier ist hier verfügbar.
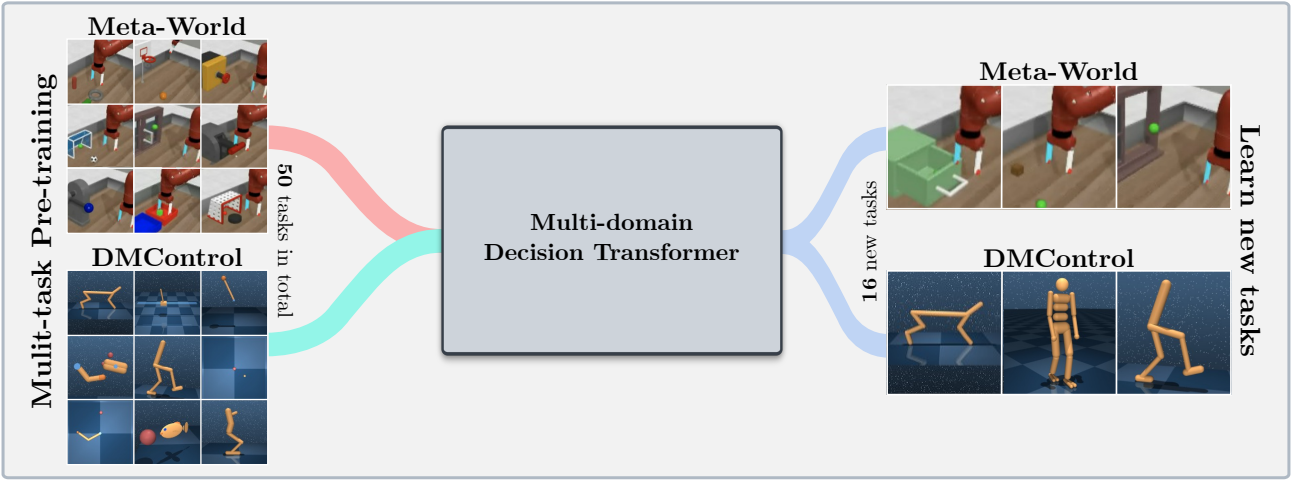
Diese Codebasis unterstützt die Schulungsentscheidungstransformatormodelle (DT) online oder aus Offline -Datensätzen in den folgenden Domänen:
Diese Codebasis stützt sich auf Open-Source-Frameworks, darunter:
Was ist in diesem Repository?
.
├── configs # Contains all .yaml config files for Hydra to configure agents, envs, etc.
│ ├── agent_params
│ ├── wandb_callback_params
│ ├── env_params
│ ├── eval_params
│ ├── run_params
│ └── config.yaml # Main config file for Hydra - specifies log/data/model directories.
├── continual_world # Submodule for Continual-World.
├── dmc2gym_custom # Custom wrapper for DMControl.
├── figures
├── scripts # Scrips for running experiments on Slurm/PBS in multi-gpu/node setups.
├── src # Main source directory.
│ ├── algos # Contains agent/model/prompt classes.
│ ├── augmentations # Image augmentations.
│ ├── buffers # Contains replay trajectory buffers.
│ ├── callbacks # Contains callbacks for training (e.g., WandB, evaluation, etc.).
│ ├── data # Contains data utilities (e.g., for downloading Atari)
│ ├── envs # Contains functionality for creating environments.
│ ├── exploration # Contains exploration strategies.
│ ├── optimizers # Contains (custom) optimizers.
│ ├── schedulers # Contains learning rate schedulers.
│ ├── tokenizers_custom # Contains custom tokenizers for discretizing states/actions.
│ ├── utils
│ └── __init__.py
├── LICENSE
├── README.md
├── environment.yaml
├── requirements.txt
└── main.py # Main entry point for training/evaluating agents.
Umgebungskonfiguration und Abhängigkeiten sind in environment.yaml verfügbar. Yaml und requirements.txt .
Erstellen Sie zunächst die Conda -Umgebung.
conda env create -f environment.yaml
conda activate mddt
Installieren Sie dann die verbleibenden Anforderungen (mit bereits heruntergeladenem Mujoco, falls dies nicht hier angezeigt wird):
pip install -r requirements.txt
Initieren Sie die continualworld -Submodule und installieren Sie:
git submodule init
git submodule update
cd continualworld
pip install .
Installieren Sie meta-world :
pip install git+https://github.com/rlworkgroup/metaworld.git@18118a28c06893da0f363786696cc792457b062b
Installieren Sie die benutzerdefinierte Version von DMC2GYM. Unsere Version macht flatten_obs optional und ermöglicht es uns daher, den vollständigen Beobachtungsraum aller DMControl Envs zu konstruieren.
cd dmc2gym_custom
pip install -e .
Laden Sie Mujoco herunter:
mkdir ~/.mujoco
cd ~/.mujoco
wget https://www.roboti.us/download/mujoco200_linux.zip
unzip mujoco200_linux.zip
mv mujoco200_linux mujoco200
wget https://www.roboti.us/file/mjkey.txt
Fügen Sie dann die folgende Zeile zu .bashrc hinzu:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mujoco200/bin
Die folgenden Probleme waren hilfreich:
Installieren Sie zunächst die folgenden Pakete:
conda install -c conda-forge glew mesalib
conda install -c menpo glfw3 osmesa
pip install patchelf
Erstellen Sie den Symlink manuell:
cp /usr/lib64/libGL.so.1 $CONDA_PREFIX/lib
ln -s $CONDA_PREFIX/lib/libGL.so.1 $CONDA_PREFIX/lib/libGL.so
Dann tun:
mkdir ~/rpm
cd ~/rpm
curl -o libgcrypt11.rpm ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/bosconovic:/branches:/home:/elimat:/lsi/openSUSE_Leap_15.1/x86_64/libgcrypt11-1.5.4-lp151.23.29.x86_64.rpm
rpm2cpio libgcrypt11.rpm | cpio -id
Exportieren Sie schließlich den Pfad in rpm Dir (Hinzufügen zu ~/.bashrc ):
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/rpm/usr/lib64
export LDFLAGS="-L/~/rpm/usr/lib64"
Diese Codebasis stützt sich auf Hydra, die Experimente über .yaml -Dateien konfiguriert. Hydra erstellt automatisch die Struktur der Protokollordner für einen bestimmten Lauf, wie in der jeweiligen config.yaml angegeben.
Die config.yaml ist der Hauptkonfigurationseintragspunkt und enthält die Standardparameter. Die Datei verweist auf die jeweiligen Standardparameterdateien unter den Block defaults . Darüber hinaus enthält config.yaml 4 wichtige Konstanten, die die Verzeichnispfade konfigurieren:
LOG_DIR: ../logs
DATA_DIR: ../data
SSD_DATA_DIR: ../data
MODELS_DIR: ../models
Die generierten Datensätze werden derzeit über unseren Webserver gehostet. Laden Sie Meta-World- und DMControl-Datensätze in den angegebenen DATA_DIR herunter:
# Meta-World
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/metaworld
# DMControl
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/dm_control_1M
Die Datensätze sind auch im Huggingface -Hub verfügbar. Laden Sie mit dem huggingface-cli herunter:
# Meta-World
huggingface-cli download ml-jku/meta-world --local-dir=./meta-world --repo-type dataset
# DMControl
huggingface-cli download ml-jku/dm_control --local-dir=./dm_control --repo-type dataset
Das Framework unterstützt auch Atari-, D4RL- und visuelle DMControl -Datensätze. Für Atari und visuelle DMControl beziehen wir uns auf die jeweiligen Readmes.
Im Folgenden geben wir einige veranschaulichende Beispiele für die Ausführung der Experimente im Papier an.
So trainieren Sie ein 40m Multi-Domain-Entscheidungstransformator (MDDT) -Modell auf MT40 + DMC10 mit 3 Samen auf einer einzelnen GPU: Rennen Sie:
python main.py -m experiment_name=pretrain seed=42,43,44 env_params=multi_domain_mtdmc run_params=pretrain eval_params=pretrain_disc agent_params=cdt_pretrain_disc agent_params.kind=MDDT agent_params/model_kwargs=multi_domain_mtdmc agent_params/data_paths=mt40v2_dmc10 +agent_params/replay_buffer_kwargs=multi_domain_mtdmc +agent_params.accumulation_steps=2
Um das vorgebildete Modell mit LORA auf einer einzelnen CW10-Aufgabe mit 3 Samen zu optimieren, laufen Sie:
python main.py -m experiment_name=cw10_lora seed=42,43,44 env_params=mt50_pretrain run_params=finetune eval_params=finetune agent_params=cdt_mpdt_disc agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft agent_params/model_kwargs/prompt_kwargs=lora env_params.envid=hammer-v2 agent_params.data_paths.names='${env_params.envid}.pkl' env_params.eval_env_names=
Um das vorgebildete Modell mit L2M bei allen CW10-Aufgaben auf sequentielle Weise mit 3 Samen zu optimieren, laufen Sie:
python main.py -m experiment_name=cw10_cl_l2m seed=42,43,44 env_params=multi_domain_ft env_params.eval_env_names=cw10_v2 run_params=finetune_coff eval_params=finetune_md_cl agent_params=cdt_mpdt_disc +agent_params.steps_per_task=100000 agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft +agent_params.replay_buffer_kwargs.kind=continual agent_params/model_kwargs/prompt_kwargs=l2m_lora
Für das Multi-GPU-Training verwenden wir torchrun . Das Werkzeug widerspricht mit hydra . Daher wurde ein Launcher -Plugin hydra_torchrun_launcherer erstellt.
Um das Plugin zu aktivieren, klonen Sie das hydra -Repo, CD, um contrib/hydra_torchrun_launcher und das Plugin zu installieren:
git clone https://github.com/facebookresearch/hydra.git
cd hydra/contrib/hydra_torchrun_launcher
pip install -e .
Das Plugin kann aus der Befehlszeile verwendet werden:
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
Ausführen von Experimenten an einem lokalen Cluster auf einem einzelnen Knoten kann über CUDA_VISIBLE_DEVICES durchgeführt werden, um die zu verwendende GPUs anzugeben:
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
Auf Slurm funktioniert die Ausführung torchrun auf einem einzelnen Knoten gleichermaßen. ZB auf 2 gpus auf einem einzelnen Knoten:
#!/bin/bash
#SBATCH --account=X
#SBATCH --qos=X
#SBATCH --partition=X
#SBATCH --nodes=1
#SBATCH --gpus=2
#SBATCH --cpus-per-task=32
source activate mddt
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=2 [...]
Beispiel-Skripte für Multi-GPU-Schulungen auf Slurm oder PBS sind in scripts verfügbar.
Das Ausführen von Slurm/PBS in einem Multi-Knoten-Setup erfordert etwas mehr Sorgfalt. Beispielskripte werden in scripts bereitgestellt.
Wenn Sie dies nützlich finden, sollten Sie unsere Arbeit zitieren:
@article{schmied2024learning,
title={Learning to Modulate pre-trained Models in RL},
author={Schmied, Thomas and Hofmarcher, Markus and Paischer, Fabian and Pascanu, Razvan and Hochreiter, Sepp},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}


