L2M
1.0.0
Thomas Schmied 1 , Markus Hofmarcher 2 , Fabian Paischer 1 , Razvan Pacscanu 3,4 , Sepp Hochreiter 1,5
1 Ellis Unit Linz e Lit AI Lab, Instituto de Machine Learning, Johannes Kepler University Linz, Áustria
2 JKU Lit Sal SPML Lab, Instituto de Aprendizado de Máquina, Johannes Kepler University Linz, Áustria
3 Google Deepmind
4 UCL
5 Instituto de Pesquisa Avançada em Inteligência Artificial (IARAI), Viena, Áustria
Este repositório contém o código-fonte para "aprender a modular modelos pré-treinados no RL" aceito no Neurips 2023. O artigo está disponível aqui.
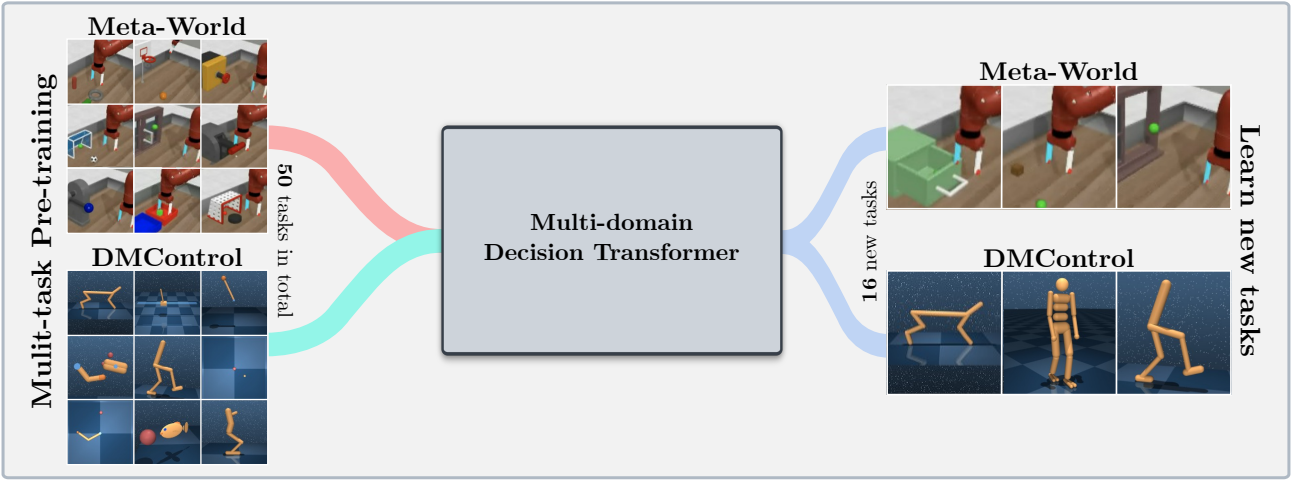
Esta Base CodeBase suporta modelos de Transformador de Decisão de Treinamento (TD) on -line ou de conjuntos de dados offline nos seguintes domínios:
Esta base de código depende de estruturas de código aberto, incluindo:
O que há neste repositório?
.
├── configs # Contains all .yaml config files for Hydra to configure agents, envs, etc.
│ ├── agent_params
│ ├── wandb_callback_params
│ ├── env_params
│ ├── eval_params
│ ├── run_params
│ └── config.yaml # Main config file for Hydra - specifies log/data/model directories.
├── continual_world # Submodule for Continual-World.
├── dmc2gym_custom # Custom wrapper for DMControl.
├── figures
├── scripts # Scrips for running experiments on Slurm/PBS in multi-gpu/node setups.
├── src # Main source directory.
│ ├── algos # Contains agent/model/prompt classes.
│ ├── augmentations # Image augmentations.
│ ├── buffers # Contains replay trajectory buffers.
│ ├── callbacks # Contains callbacks for training (e.g., WandB, evaluation, etc.).
│ ├── data # Contains data utilities (e.g., for downloading Atari)
│ ├── envs # Contains functionality for creating environments.
│ ├── exploration # Contains exploration strategies.
│ ├── optimizers # Contains (custom) optimizers.
│ ├── schedulers # Contains learning rate schedulers.
│ ├── tokenizers_custom # Contains custom tokenizers for discretizing states/actions.
│ ├── utils
│ └── __init__.py
├── LICENSE
├── README.md
├── environment.yaml
├── requirements.txt
└── main.py # Main entry point for training/evaluating agents.
Configuração e dependências do ambiente estão disponíveis no environment.yaml e requirements.txt .
Primeiro, crie o ambiente do CONDA.
conda env create -f environment.yaml
conda activate mddt
Em seguida, instale os requisitos restantes (com Mujoco já baixado, se não veja aqui):
pip install -r requirements.txt
Init o submódulo continualworld e instalação:
git submodule init
git submodule update
cd continualworld
pip install .
Instale meta-world :
pip install git+https://github.com/rlworkgroup/metaworld.git@18118a28c06893da0f363786696cc792457b062b
Instale a versão personalizada do DMC2GYM. Nossa versão torna flatten_obs opcional e, portanto, nos permite construir o espaço de observação completo de todos os DMControl Envs.
cd dmc2gym_custom
pip install -e .
Baixe Mujoco:
mkdir ~/.mujoco
cd ~/.mujoco
wget https://www.roboti.us/download/mujoco200_linux.zip
unzip mujoco200_linux.zip
mv mujoco200_linux mujoco200
wget https://www.roboti.us/file/mjkey.txt
Em seguida, adicione a seguinte linha ao .bashrc :
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mujoco200/bin
As questões a seguir foram úteis:
Primeiro, instale os seguintes pacotes:
conda install -c conda-forge glew mesalib
conda install -c menpo glfw3 osmesa
pip install patchelf
Crie o symlink manualmente:
cp /usr/lib64/libGL.so.1 $CONDA_PREFIX/lib
ln -s $CONDA_PREFIX/lib/libGL.so.1 $CONDA_PREFIX/lib/libGL.so
Então faça:
mkdir ~/rpm
cd ~/rpm
curl -o libgcrypt11.rpm ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/bosconovic:/branches:/home:/elimat:/lsi/openSUSE_Leap_15.1/x86_64/libgcrypt11-1.5.4-lp151.23.29.x86_64.rpm
rpm2cpio libgcrypt11.rpm | cpio -id
Finalmente, exporte o caminho para rpm Dir (adicione a ~/.bashrc ):
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/rpm/usr/lib64
export LDFLAGS="-L/~/rpm/usr/lib64"
Esta base de código depende da Hydra, que configura experimentos via arquivos .yaml . A Hydra cria automaticamente a estrutura da pasta de log para uma determinada execução, conforme especificado no respectivo arquivo config.yaml .
O config.yaml é o principal ponto de entrada da configuração e contém os parâmetros padrão. O arquivo faz referência aos respectivos arquivos de parâmetros padrão sob os defaults de bloco. Além disso, config.yaml contém 4 constantes importantes que configuram os caminhos do diretório:
LOG_DIR: ../logs
DATA_DIR: ../data
SSD_DATA_DIR: ../data
MODELS_DIR: ../models
Atualmente, os conjuntos de dados generosos estão hospedados através do nosso servidor da Web. Faça o download dos conjuntos de dados meta-mundial e dmControl para o DATA_DIR especificado:
# Meta-World
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/metaworld
# DMControl
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/dm_control_1M
Os conjuntos de dados também estão disponíveis no HUGGINGFACE HUB. Baixe usando o huggingface-cli :
# Meta-World
huggingface-cli download ml-jku/meta-world --local-dir=./meta-world --repo-type dataset
# DMControl
huggingface-cli download ml-jku/dm_control --local-dir=./dm_control --repo-type dataset
A estrutura também suporta conjuntos de dados Atari, D4RL e Visual DMControl. Para Atari e Visual DMControl, nos referimos aos respectivos ReadMes.
A seguir, fornecemos alguns exemplos ilustrativos de como executar os experimentos no artigo.
Para treinar um modelo de Decisão de Multi-Domínio de 40m (MDDT) no MT40 + DMC10 com 3 sementes em uma única GPU, Run:
python main.py -m experiment_name=pretrain seed=42,43,44 env_params=multi_domain_mtdmc run_params=pretrain eval_params=pretrain_disc agent_params=cdt_pretrain_disc agent_params.kind=MDDT agent_params/model_kwargs=multi_domain_mtdmc agent_params/data_paths=mt40v2_dmc10 +agent_params/replay_buffer_kwargs=multi_domain_mtdmc +agent_params.accumulation_steps=2
Para ajustar o modelo pré-treinado usando o LORA em uma única tarefa CW10 com 3 sementes, execute:
python main.py -m experiment_name=cw10_lora seed=42,43,44 env_params=mt50_pretrain run_params=finetune eval_params=finetune agent_params=cdt_mpdt_disc agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft agent_params/model_kwargs/prompt_kwargs=lora env_params.envid=hammer-v2 agent_params.data_paths.names='${env_params.envid}.pkl' env_params.eval_env_names=
Para ajustar o modelo pré-treinado usando L2M em todas as tarefas CW10 de maneira seqüencial com 3 sementes, execute:
python main.py -m experiment_name=cw10_cl_l2m seed=42,43,44 env_params=multi_domain_ft env_params.eval_env_names=cw10_v2 run_params=finetune_coff eval_params=finetune_md_cl agent_params=cdt_mpdt_disc +agent_params.steps_per_task=100000 agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft +agent_params.replay_buffer_kwargs.kind=continual agent_params/model_kwargs/prompt_kwargs=l2m_lora
Para treinamento multi-GPU, usamos torchrun . A ferramenta entra em conflito com hydra . Portanto, foi criado um plugin do lançador HYDRA_TORCHRUN_LAUNCHER.
Para ativar o plug -in, clone o repositório hydra , CD para contrib/hydra_torchrun_launcher e pip instalar o plug -in:
git clone https://github.com/facebookresearch/hydra.git
cd hydra/contrib/hydra_torchrun_launcher
pip install -e .
O plug -in pode ser usado na linha de comando:
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
Experimentos em execução em um cluster local em um único nó podem ser feitos via CUDA_VISIBLE_DEVICES para especificar as GPUs para usar:
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
Em Slurm, executando torchrun em um único nó funciona. Por exemplo, para executar 2 GPUs em um único nó:
#!/bin/bash
#SBATCH --account=X
#SBATCH --qos=X
#SBATCH --partition=X
#SBATCH --nodes=1
#SBATCH --gpus=2
#SBATCH --cpus-per-task=32
source activate mddt
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=2 [...]
Exemplo de scripts para treinamento multi-GPU em SLURM ou PBS estão disponíveis em scripts .
A execução do SLURM/PBS em uma configuração de vários nós requer um pouco mais de cuidado. Exemplo de scripts são fornecidos nos scripts .
Se você achar isso útil, considere citar nosso trabalho:
@article{schmied2024learning,
title={Learning to Modulate pre-trained Models in RL},
author={Schmied, Thomas and Hofmarcher, Markus and Paischer, Fabian and Pascanu, Razvan and Hochreiter, Sepp},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}


