L2M
1.0.0
Thomas Schmied 1 , Markus Hofmarcher 2 , Fabian Paischer 1 , Razvan Pacscanu 3,4 , Sepp Hochreiter 1,5
1 Ellis Unit Linz and Lit Ai Lab, Институт машинного обучения, Университет Йоханнеса Кеплер Линц, Австрия
2 JKU LIT SAL ESPML LAB, Институт машинного обучения, Университет Йоханнеса Кеплер Линц, Австрия
3 Google DeepMind
4 UCL
5 Институт передовых исследований в области искусственного интеллекта (IARAI), Вена, Австрия
Этот репозиторий содержит исходный код для «Learning для модуляции предварительно обученных моделей в RL», принятых в Neurips 2023. Документ доступен здесь.
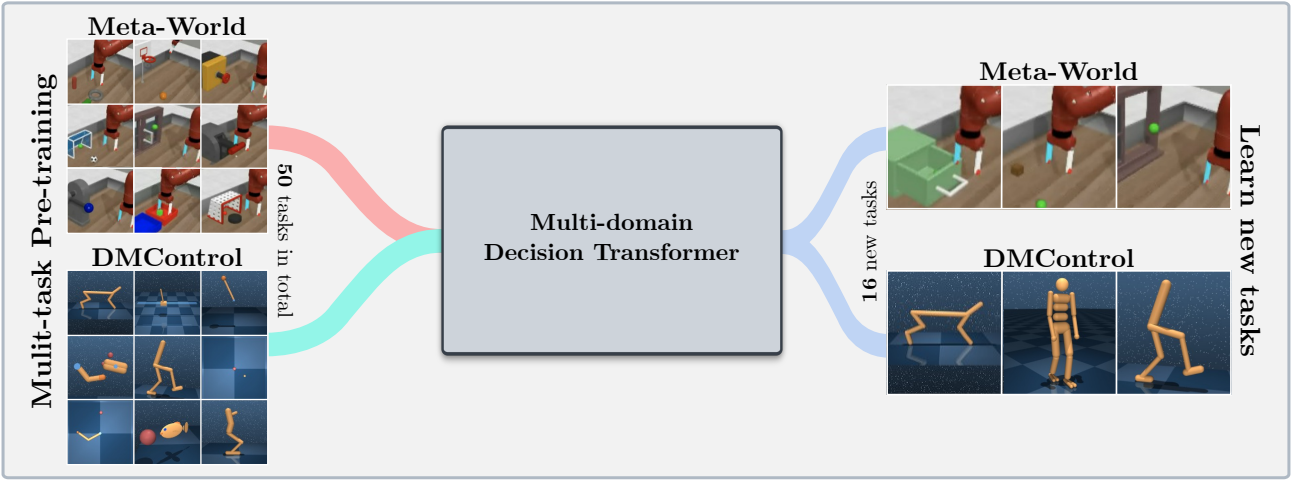
Эта кодовая база поддерживает модели Transing Transformer (DT) онлайн или из автономных наборов данных в следующих доменах:
Эта кодовая база опирается на фреймворки с открытым исходным кодом, в том числе:
Что в этом репозитории?
.
├── configs # Contains all .yaml config files for Hydra to configure agents, envs, etc.
│ ├── agent_params
│ ├── wandb_callback_params
│ ├── env_params
│ ├── eval_params
│ ├── run_params
│ └── config.yaml # Main config file for Hydra - specifies log/data/model directories.
├── continual_world # Submodule for Continual-World.
├── dmc2gym_custom # Custom wrapper for DMControl.
├── figures
├── scripts # Scrips for running experiments on Slurm/PBS in multi-gpu/node setups.
├── src # Main source directory.
│ ├── algos # Contains agent/model/prompt classes.
│ ├── augmentations # Image augmentations.
│ ├── buffers # Contains replay trajectory buffers.
│ ├── callbacks # Contains callbacks for training (e.g., WandB, evaluation, etc.).
│ ├── data # Contains data utilities (e.g., for downloading Atari)
│ ├── envs # Contains functionality for creating environments.
│ ├── exploration # Contains exploration strategies.
│ ├── optimizers # Contains (custom) optimizers.
│ ├── schedulers # Contains learning rate schedulers.
│ ├── tokenizers_custom # Contains custom tokenizers for discretizing states/actions.
│ ├── utils
│ └── __init__.py
├── LICENSE
├── README.md
├── environment.yaml
├── requirements.txt
└── main.py # Main entry point for training/evaluating agents.
Конфигурация среды и зависимости доступны в environment.yaml и requirements.txt .
Во -первых, создайте среду Conda.
conda env create -f environment.yaml
conda activate mddt
Затем установите оставшиеся требования (с уже загруженным Mujoco, если не увидеть здесь):
pip install -r requirements.txt
Init The continualworld подмодуль и установить:
git submodule init
git submodule update
cd continualworld
pip install .
Установите meta-world :
pip install git+https://github.com/rlworkgroup/metaworld.git@18118a28c06893da0f363786696cc792457b062b
Установите пользовательскую версию DMC2GYM. Наша версия делает flatten_obs необязательным и, таким образом, позволяет нам построить полное пространство наблюдения всех ENVS DMControl.
cd dmc2gym_custom
pip install -e .
Скачать Mujoco:
mkdir ~/.mujoco
cd ~/.mujoco
wget https://www.roboti.us/download/mujoco200_linux.zip
unzip mujoco200_linux.zip
mv mujoco200_linux mujoco200
wget https://www.roboti.us/file/mjkey.txt
Затем добавьте следующую строку в .bashrc :
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mujoco200/bin
Следующие проблемы были полезны:
Сначала установите следующие пакеты:
conda install -c conda-forge glew mesalib
conda install -c menpo glfw3 osmesa
pip install patchelf
Создайте символическую ссылку вручную:
cp /usr/lib64/libGL.so.1 $CONDA_PREFIX/lib
ln -s $CONDA_PREFIX/lib/libGL.so.1 $CONDA_PREFIX/lib/libGL.so
Тогда делай:
mkdir ~/rpm
cd ~/rpm
curl -o libgcrypt11.rpm ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/bosconovic:/branches:/home:/elimat:/lsi/openSUSE_Leap_15.1/x86_64/libgcrypt11-1.5.4-lp151.23.29.x86_64.rpm
rpm2cpio libgcrypt11.rpm | cpio -id
Наконец, экспортируйте путь в rpm Dir (добавьте в ~/.bashrc ):
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/rpm/usr/lib64
export LDFLAGS="-L/~/rpm/usr/lib64"
Эта кодовая база зависит от Hydra, которая настраивает эксперименты через файлы .yaml . Hydra автоматически создает структуру папки журнала для данного выполнения, как указано в соответствующем файле config.yaml .
config.yaml является основной точкой входа конфигурации и содержит параметры по умолчанию. Файл ссылается на соответствующие файлы параметров по умолчанию под defaults блоков. Кроме того, config.yaml содержит 4 важных константа, которые настраивают пути каталога:
LOG_DIR: ../logs
DATA_DIR: ../data
SSD_DATA_DIR: ../data
MODELS_DIR: ../models
Наборы данных в настоящее время размещены через наш веб-сервер. Загрузите наборы данных Meta-World и DMControl в указанный DATA_DIR :
# Meta-World
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/metaworld
# DMControl
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/dm_control_1M
Наборы данных также доступны в центре Huggingface. Скачать с помощью huggingface-cli :
# Meta-World
huggingface-cli download ml-jku/meta-world --local-dir=./meta-world --repo-type dataset
# DMControl
huggingface-cli download ml-jku/dm_control --local-dir=./dm_control --repo-type dataset
Структура также поддерживает наборы данных Atari, D4RL и Visual DMControl. Для Atari и Visual DmControl мы ссылаемся на соответствующие чтения.
Далее мы приводим несколько иллюстративных примеров того, как запустить эксперименты в статье.
Чтобы обучить модель Multi-Domain Transformer (MDDT) на 40 м на MT40 + DMC10 с 3 семенами на одном графическом процессоре, запустите:
python main.py -m experiment_name=pretrain seed=42,43,44 env_params=multi_domain_mtdmc run_params=pretrain eval_params=pretrain_disc agent_params=cdt_pretrain_disc agent_params.kind=MDDT agent_params/model_kwargs=multi_domain_mtdmc agent_params/data_paths=mt40v2_dmc10 +agent_params/replay_buffer_kwargs=multi_domain_mtdmc +agent_params.accumulation_steps=2
Чтобы точно настроить предварительно обученную модель, используя LORA на одной задаче CW10 с 3 семенами, запустите:
python main.py -m experiment_name=cw10_lora seed=42,43,44 env_params=mt50_pretrain run_params=finetune eval_params=finetune agent_params=cdt_mpdt_disc agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft agent_params/model_kwargs/prompt_kwargs=lora env_params.envid=hammer-v2 agent_params.data_paths.names='${env_params.envid}.pkl' env_params.eval_env_names=
Чтобы точно настроить предварительно обученную модель, используя L2M на всех задачах CW10 последовательным образом с 3 семенами, запустите:
python main.py -m experiment_name=cw10_cl_l2m seed=42,43,44 env_params=multi_domain_ft env_params.eval_env_names=cw10_v2 run_params=finetune_coff eval_params=finetune_md_cl agent_params=cdt_mpdt_disc +agent_params.steps_per_task=100000 agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft +agent_params.replay_buffer_kwargs.kind=continual agent_params/model_kwargs/prompt_kwargs=l2m_lora
Для обучения мульти-GPU мы используем torchrun . Инструмент конфликтует с hydra . Таким образом, был создан плагин пускового установки Hydra_torchrun_launcher.
Чтобы включить плагин, клонируйте hydra Repo, CD в contrib/hydra_torchrun_launcher и PIP установите плагин:
git clone https://github.com/facebookresearch/hydra.git
cd hydra/contrib/hydra_torchrun_launcher
pip install -e .
Плагин можно использовать из командной линии:
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
Запуск экспериментов на локальном кластере на одном узле может быть проведен с помощью CUDA_VISIBLE_DEVICES , чтобы указать графические процессоры для использования:
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
На Slurm выполнение torchrun на одном узле работает. Например, запустить 2 графические процессоры на одном узле:
#!/bin/bash
#SBATCH --account=X
#SBATCH --qos=X
#SBATCH --partition=X
#SBATCH --nodes=1
#SBATCH --gpus=2
#SBATCH --cpus-per-task=32
source activate mddt
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=2 [...]
Примеры сценариев для обучения мульти-GPU на Slurm или PBS доступны в scripts .
Работа на Slurm/PBS в мультизлевой настройке требует немного большей помощи. Примеры сценариев приведены в scripts .
Если вы найдете это полезным, пожалуйста, рассмотрите возможность ссылаться на нашу работу:
@article{schmied2024learning,
title={Learning to Modulate pre-trained Models in RL},
author={Schmied, Thomas and Hofmarcher, Markus and Paischer, Fabian and Pascanu, Razvan and Hochreiter, Sepp},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}


